Xpathは、ドキュメント内のxmlまたはxhtml要素のリクエストの言語です。 SQLと同様に、xpathは宣言型クエリ言語です。 目的のデータを取得するには、このデータを記述するクエリを作成するだけです。 あなたのためのすべての「黒」作業は、xpathインタプリタによって行われます。
とても便利ですね。 Webページのノードにアクセスするためにxpathが提供する機能を見てみましょう。
Webページサイトへのリクエストを作成する
小さなラボに注目します。このラボでは、Webページのxpathリクエストの作成について説明します。 あなたは私のリクエストを繰り返すことができ、そして最も重要なことは、あなたのリクエストを満たそうとすることです。 これにより、xmlのxpathに精通している初心者とプログラマーにとって、記事が等しく興味深いものになることを願っています。
実験室には、次のものが必要です。
-xhtml Webページ。
-アドオンを備えた
Mozilla Firefoxブラウザ。
-
ファイアバグ ;
-firePath ;
(視覚的なxpathサポートを備えた他のブラウザを使用できます)
-少し時間。
実験用のWebページとして、World Wide Web Consortium Webサイトのメインページ( '
http://w3.org ')を提案します。 xquery(xpath)言語、xhtml仕様、および他の多くのインターネット標準を開発するのはこの組織です。
挑戦する
w3.orgメインページのxhtmlコードからxpathリクエストを使用して、コンソーシアム会議に関する情報を取得します。
xpathリクエストの作成を始めましょう。
最初のxpathリクエスト
FireBugで[Firepath]タブを開き、セレクターで分析する要素を選択して、クリックします。Firepathは、選択した要素へのxpathリクエストを作成しました。
最初のイベントのヘッダーを選択すると、リクエストは次のようになります。
.//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/a冗長なインデックスを削除すると、クエリは「ヘッダー」タイプのすべての要素に対応します。
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p/aFirepathは、クエリに一致する要素を強調表示します。 ドキュメントのどのノードがクエリに一致するかをリアルタイムで確認できます。
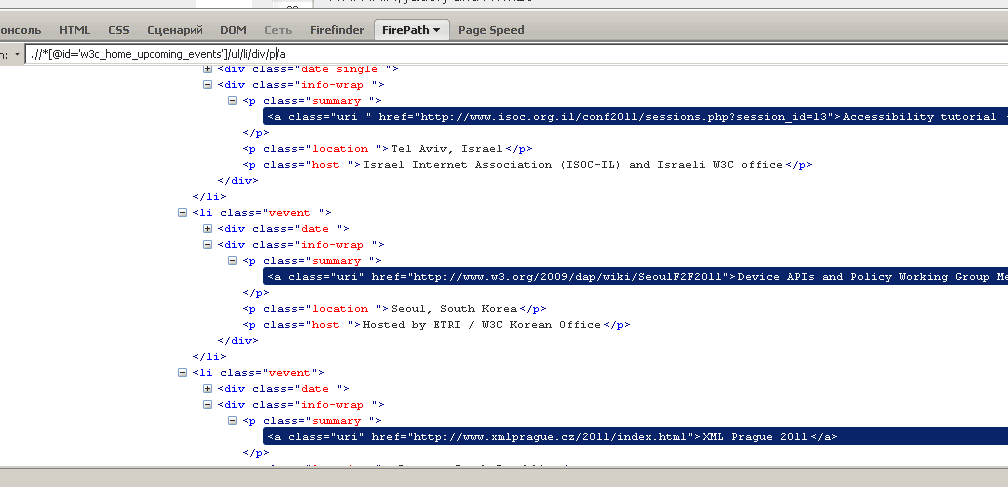
どうぞ セレクタを使用するか、最初のクエリを変更することにより、会議会場とスポンサーを検索するクエリを作成します。
会議会場に関する情報のリクエスト:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]そこで、スポンサーのリストを取得します。
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]Xpath構文
作成されたクエリに戻って、それらがどのように機能するかを見てみましょう。
最初のリクエストを詳細に検討しましょう

このクエリでは、xpathの機能を示すために3つの部分を強調しました。 (パーツへの分割はキャッチーです)
前編
.//-現在のコンテキストからのゼロ以上の階層レベルへの再帰下降。 この場合、現在のコンテキストはドキュメントのルートです。
第二部
* -任意の要素
[@ id = 'w3c_home_upcoming_events'] -'w3c_home_upcoming_events'に等しいid属性を持つノードを検索するための述語。 XHTML要素識別子は一意でなければなりません。 したがって、クエリ「特定のIDを持つ任意の要素」は、探している唯一のノードを返す必要があります。
このクエリで
*を
divノードの正確な名前に置き換えることができます
div[@id='w3c_home_upcoming_events']したがって、ドキュメントツリーを下ってdivノード[@ id = 'w3c_home_upcoming_events']に移動します。 DOMツリーがどのノードで構成されているか、その上にいくつの階層レベルが残っているかについてはまったく心配していません。
第三部
/ ul / li / div / p / a特定の要素への-xpath-path。 パスは、アドレス指定手順とノード(ul、liなど)をチェックするための条件で構成されます。 ステップは「/」(スラッシュ)で区切られます。
Xpathコレクション
述語またはアドレス指定の手順を使用して、目的のノードにアクセスできるとは限りません。 非常に多くの場合、同じレベルの階層には同じタイプのノードがいくつあり、「最初のノードのみ」または「2番目のノードのみ」を選択する必要があります。 そのような場合、コレクションが提供されます。
xpathコレクションを使用すると、インデックスによって要素にアクセスできます。 インデックスは、元のドキュメントで要素が表示された順序に対応しています。 コレクション内のシリアル番号は1からカウントされます。
「場所」は常に「会議名」の後の2番目の段落であるという事実に基づいて、次のクエリを取得します。
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]p [2]は、リスト/ ul / li / divの各ノードのセットの2番目の要素です。
同様に、リクエストによりスポンサーのリストを取得できます。
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]一部のxpath関数
xpathには、コレクション内の要素を操作するための多くの関数があります。 そのうちのいくつかだけをあげます。
最後():コレクションの最後のアイテムを返します。
ul/li/div/p[last()]クエリ
ul/li/div/p[last()]リストの各ノードの最後の段落を返します。
最初の()関数は提供されていません。 最初のアイテムにアクセスするには、インデックス「1」を使用します。
テキスト():要素のテストコンテンツを返します。
.//a[text() = 'Archive'] -テキスト「Archive」を含むすべてのリンクを取得します。
位置()およびmod:position()-セット内の要素の位置を返します。
mod-除算の剰余。
これらの機能の組み合わせにより、次のことが得られます。
-奇数要素
ul/li[position() mod 2 = 1]-偶数要素:
ul/li[position() mod 2 = 0]比較操作- <-論理的な「少ない」
- >-論理的な「もっと」
- <=-論理的な「以下」
- > =-論理的な「以上」
ul/li[position() > 2] , ul/li[position() <= 2] -3番目の番号から始まるアイテム、およびその逆のアイテムをリストします。
全機能リスト独立して
取得しよう:
-左側のメニュー「標準」からのURLリンクも。
-メインページw3c.orgの最初のニュースを除くすべてのニュースの見出し。
PHP5のXpath
$dom = new DomDocument(); $dom->loadHTML( $HTMLCode ); $xpath = new DomXPath( $dom ); $_res = $xpath->query(".//*[@id='w3c_home_upcoming_events']/ul/li/div/p/a"); foreach( $_res => $obj ) { echo 'URL: '.$obj->getAttribute('href'); echo $obj->nodeValue; }
結論として
簡単な例では、Webページのノードにアクセスするためのxpathの機能を見ました。
Xpathは、xmlおよびxhtml、xslt変換要素にアクセスするための業界標準です。
htmlページの解析に使用できます。 ソースhtml-codeに重大なマークアップエラーが含まれている場合は、
tidyを介して渡します。 エラーは修正されます。
xpathを優先してWebページを解析するときは、正規表現を拒否してください。
これにより、コードが簡単になり、理解しやすくなります。 間違いを少なくします。 デバッグ時間を短縮します。
資源
FirepathアドオンMozzilla Firefoxウィキペディアの言語の簡単な要約適切なXpathリファレンス。 NET Framework用であるという事実に注意を払ってはいけません。 Xpathは、いくつかの特定の機能を除き、すべての環境で同じように機能します
Xpath 1.0仕様ロシア語のXpath 1.0仕様XQuery 1.0およびXPath 2.0きちんとしたPHP5 Tidy :: repairFile