音声アルゴリズムは、同じコードで発音が似ている2つの単語を照合します。これにより、音声の類似性に基づいて、そのような単語のセットを比較およびインデックス付けできます。
データベースで非定型の姓を見つけるのは非常に難しいことがよくあります。次に例を示します。
-レッヒ、アドルフ・シュワルツェネッガーの拠点を見て、
- シュヴォルツィネギラ ? そんなことない!
この場合、音声アルゴリズムを使用すると(特にファジーマッチングアルゴリズムと組み合わせて)、タスクが大幅に簡素化されます。
このようなアルゴリズムは、スペルチェックプログラムで人のリストをデータベースで検索するときに非常に便利です。 多くの場合、それらはファジー検索アルゴリズム(間違いなく別の記事に値する)と組み合わせて使用され、さまざまなデータベースや従業員リストなどの姓と名による便利な検索をユーザーに提供します。
この記事では、
Soundex 、
Daitch-Mokotoff Soundex 、
NYSIIS 、
Metaphone 、
Double Metaphone 、
Russian Metaphone 、
Caverphoneなどの最も有名なアルゴリズムについて検討します。
Soundex
最初の1つは、前世紀の10世紀にRobert Russellによって発明された
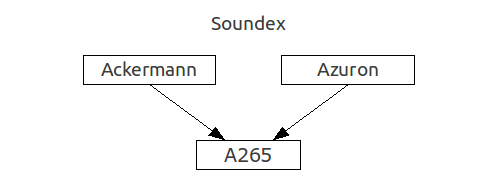
Soundexアルゴリズムでした。 このアルゴリズム(というよりは、そのアメリカ版)は、単語
A126の数値インデックスを持つ単語と一致します。 その動作の原理は、子音をシリアル番号を持つグループに分割し、そこから結果の値をコンパイルすることに基づいています。 後に多くの改善も提案されました。
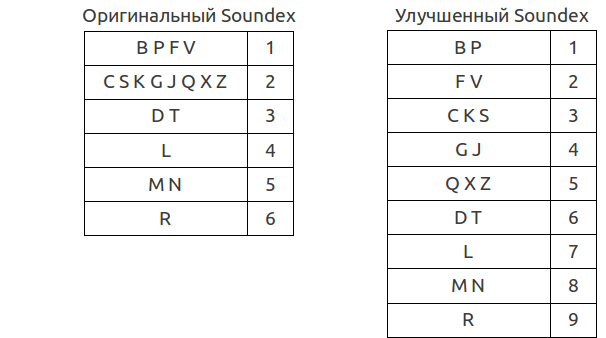
最初の文字が保存され、後続の文字がテーブル内の数字と比較されます。 表に示されていない文字(すべて母音と一部の子音)は無視されます。 隣接する文字、または同じグループに含まれる文字
Hまたは
Wで区切られた文字は、1つとして記録されます。 結果は4文字に切り捨てられます。 不足している位置はゼロで埋められます。 これらのすべての手順の後、このようなコードのバリエーションはわずか
7000であり、同じSoundexコードを持つ多くのまったく異なる単語が必要であることに気付くのは簡単です。 したがって、ほとんどの場合、結果には多数の「誤検出」値が含まれます。
改良版では、ご覧のとおり、文字はより多くのグループに分割されています。 さらに、文字HとWには特別な注意は払われず、単に無視されます。 さらに、結果の長さで操作は実行されません-コードには固定長がなく、切り捨てられません。
例
オリジナルSoundex:D341 →デドロフスキー、デドロフスキー、ディディレフ、ディテレフ、ドゥダレフ、ドゥドレフ、ドゥトロフ、ディダレフ、ディアトロフ、ディアトロフ。
N251 →Nagimov、Nagmbetov、Nazimov、Nasimov、Nassonov、Nezhnov、Neznaev、Nesmeev、Nizhnevsky、Nikonov、Nikonovich、Nisenblat、Nisenbaum、Nissenbaum、Noginov、Nozhnov。
優れたSoundex:N8030802 →ナシモフ、ナッソノフ、ニコノフ。
N80308108 →ニーセンバウム、ニッセンバウム。
N8040802 →ナギモフ、ナゴノフ、ネガノフ、ノギノフ。
N804810602 →ナグメトフ。
N8050802 →ナジモフ、ネジノフ、鞘。
平均して、Soundexコード値ごとに21の姓があります。 Soundexの改良バージョンの場合、2〜3個の姓のみが同じコードに変換されます。
NYSIIS
1970年にNew York State Identification and Intelligence Systemの一部として開発されたこのアルゴリズムは、ソースワードを結果のコードに変換するためのより複雑なルールを使用して、元のSoundexよりもわずかに優れた結果を生成します。 このアルゴリズムは、特にアメリカの姓で動作するように設計されています。
NYSIISコード計算アルゴリズム
- 次の規則に従って単語の開始を変換します。
MAC→MCC
KN→N
K→C
PH、PF→FF
SCH→SSS - 次の規則に従って単語の終わりを変換します。
EE→Y
IE→Y
DT、RT、RD、NT、ND→D - 次に、最初の文字を除くすべての文字が、次の規則に従って変換されます。
EV→AF
A、E、I、O、U→A
Q→G
Z→S
M→N
KN→N
K→C
SCH→SSS
PH→FF
母音の後:Hを削除し、W→Aに変換します - 最後にSを削除
- 最後にAYを変換→Y
- 最後にAを削除
- 6文字にトリミングします(オプションのステップ)。
例
CASPARAVAS →Kasparavichus、Kasperovich、Kaspirovich。
CATNACAV →カトニコフ、ツィトニコフ、ツィトニコフ。
LANSANC →レンチェンコ、レオンチェンコ、リンチェンコ、ルンチェンコ、リアムゼンコ。
PRADSC →パリッシュ、プロホドスキー、プルスキー、プルスキー、プルスキー。
STADNACAV →
スタドニコフ 。
NYSIISは、同じコードに2つ以上の名前を変換します。
ダイッチ・モコトフSoundex
このアルゴリズムは、1985年に2つの系譜-Harry MokotoffとRandy Deutschによって開発されました。東ヨーロッパ(ロシア語を含む)の姓で作業する場合、比較的オリジナルのSoundexの最高の結果を達成しようとしています。
このアルゴリズムは、元のSoundexとほとんど共通点がありませんが、結果は依然として数字のシーケンスですが、最初の文字もエンコードされます。
非常に複雑な変換ルールがあります-現在、単一の文字だけでなく、いくつかの文字のシーケンスも結果のコードの形成に関与しています。 さらに、フォーム
023689の結果は、約
60万の異なるコードバリエーションを提供します。これは、複雑なルールと相まって、「余分な」ルールの数を減らします。 結果セットの「False positive」ワード。
変換は、次の表に従って実行されます(変換の順序は、表内の文字の組み合わせの順序に対応しています)。
| ソースの組み合わせ | はじめに | 母音の後ろ | 残り |
| AI、AJ、AY、EI、EY、EJ、OI、OJ、OY、UI、UJ、UY | 0 | 1 | |
| Au | 0 | 7 | |
| IA、IE、IO、IU | 1 | | |
| EU | 1 | 1 | |
| A、UE、E、I、O、U、Y | 0 | | |
| J | 1 | 1 | 1 |
| SCHTSCH、SCHTSH、SCHTCH、SHTCH、SHCH、SHTSH、STCH、STSCH、STRZ、STRS、STSH、SZCZ、SZCS | 2 | 4 | 4 |
| SHT、SCHT、SCHD、ST、SZT、SHD、SZD、SD | 2 | 43 | 43 |
| CSZ、CZS、CS、CZ、DRZ、DRS、DSH、DS、DZH、DZS、DZ、TRZ、TRS、TRCH、TSH、TTSZ、TTZ、TZS、TSZ、SZ、TTCH、TCH、TTSCH、ZSCH、ZHSH、 SCH、SH、TTS、TC、TS、TZ、ZH、ZS | 4 | 4 | 4 |
| SC | 2 | 4 | 4 |
| DT、D、TH、T | 3 | 3 | 3 |
| CHS、KS、X | 5 | 54 | 54 |
| S、z | 4 | 4 | 4 |
| CH、CK、C、G、KH、K、Q | 5 | 5 | 5 |
| MN、NM | | 66 | 66 |
| M、N | 6 | 6 | 6 |
| FB、B、PH、PF、F、P、V、W | 7 | 7 | 7 |
| H | 5 | 5 | |
| L | 8 | 8 | 8 |
| R | 9 | 9 | 9 |
「代替」文字の組み合わせ(ソースワードから複数の代替コードを生成するために使用):
CH→TCH
CK→TSK
C→TZ
J→DZH
例
095747 →
アルヒプツェフ 、
アルヒプツォフ 、アルヒピチェフ、アルティバソフ、アルティバショフ、アルキバソフ
095757 →アルヒプコフ、
アルヒプツェフ 、
アルヒプツフ 、アルヒピチェフ
584360 →
ガルスティアン 、ガルスティアン、ギルスタイン、グリスティン、グルズダン、ホルスタイン、ゴールドスタイン、ゴールドスタイン、カルスティアン、クリストゥン、クリストゥン、クリスタイン。
このアルゴリズムは、平均5つの姓を同じコードに変換します。
その後、Alexander BaderとStephen Morseは、ユダヤ人(アシュケナージ)の姓を扱う際に、Daitch-Mokotoff Soundexと比較して「偽陽性」値の数を減らすことを目的とした
Beider-Morse Name Matching Algorithmを開発し
ました 。
メタフォン
Metaphoneアルゴリズム(1990)の特性はわずかに優れており、エンコードプロセスへのアプローチが若干異なる点で以前のアルゴリズムと異なります。英語の規則を考慮して、かなり複雑な規則を使用して元の単語を変換します。グループに分けられます。 結果のコードは、セット
0BFHJKLMNPRSTWXYからの文字のセット
です 。単語の先頭には、セット
AEIOUからの母音もあります。
Metaphoneコード計算アルゴリズム
- 文字Cを除き、重複する隣接する文字をすべて削除します。
- 次の規則に従って単語の先頭を変換します。
KN→N
GN→N
PN→N
AE→E
WR→R - Mの後にある場合は、末尾の文字Bを削除します。
- 次の規則に従ってCを置き換えます
X:CIA→XIA、SCH→SKH、CH→XH
Sの場合:CI→SI、CE→SE、CY→SY
Kで:C→K - 次の規則に従ってDを置き換えます
J:DGE→JGE、DGY→JGY、DGI→JGY
T:D→T - この文字の組み合わせが母音の前でも最後でもない場合は、GH→Hを置き換えます。
- これらの文字の組み合わせが最後にある場合は、GN→NとGNED→NEDを置き換えます。
- 次の規則に従ってGを置き換えます
J:GI→JI、GE→JE、GY→JY
K上:G→K - 母音の前ではなく、母音の後に来るすべてのHを削除します。
- 規則に従って次の変換を実行します。
CK→K
PH→F
Q→K
V→F
Z→S - SをXに置き換えます。
SH→XH
SIO→XIO
SIA→XIA - 次の規則に従ってTを置き換えます
Xの場合:TIA→XIA、TIO→XIO
0の場合:TH→0
削除:TCH→CH
- 単語の先頭で、WH→Wに変換します。Wの後に母音がない場合は、Wを削除します。
- Xが単語の先頭にある場合、X→Sに変換し、そうでない場合はX→KS
- 母音の前にないすべてのYを削除します。
- 最初の母音を除くすべての母音を削除します。
例
AKXN →アガシン、アカチェノク、アキシン、アクショネンコ、アクショノフ、アクチュナエフ、アクシャノフ、アクシェンツェフ、アクシンスキー、アクシンツェフ、アクショノフ。
FSLX →ヴァシリシン、ヴァシルチャク、ヴァシルチェンコ、ヴァシルチク、ヴァシルチコフ、ヴァシルチェンコ、ヴァシルチュク、ヴァシリュシュチェンコ。
SRFM →セラフィモフ、セラフィムスキー、セラフィムチュク、ツェレイフマン。
平均して、6つの名前のMetaphoneコード値は同じです。
ダブルメタフォン
Double Metaphone(2000)は他の音声アルゴリズムとは多少異なり、ソースワード(最大4文字)から1つではなく2つのコードを生成します。1つは単語の主な発音を反映し、もう1つは代替バージョンを反映します。 東ヨーロッパ、イタリア語、中国語の単語などに注意を払いながら、言葉の異なる起源を考慮して、多数の異なるルールを持っています。 変換規則は非常に多く、私はそれらを公開しません。希望する人は
ドブス博士の
記事でそれらを読むことができます。
例
JXRF →
ギチャロフ 。
KKRF →ガガロフ、カガロフ、カチャロフスキー、カチェロ
フスキー 、カチュリフスキー、カチュロフ、カチュロフスキー、キチェロフ、コカレフ、コクロフ、コクロフ、コチャロフ、コチュロフ、クカレフ、ツァキロフ、ツクロフ、ツグロフ
KXRF →
ギシャロフ 、ゴシャロフ、カチェロフ、
カチェロフスキー、
カシャレフスキー 、コチャロフ、コチェフ、コチェリャエフ、コチュラエフ、コシャレフ、コーシャ。
PNFS →
バノフスキー 、バフノフスキー、ビネフスキー、ビニャフスキー、ブイノフスキー、ブヤノフスキー、パネフスキー、パノフスキー、パノフスキー、ペネフスキー、ピネフスキー、ピノフスキー、ピクノフスキー。
Double Metaphoneは、平均8〜9個の姓を同じコードに一致させます。
ロシアのメタフォン
2002年、Programmer誌の第8号は、
Peter Kankowskiによる Metaphoneアルゴリズムの英語版の厳しいシベリアの霜、熊、バラライカへの適応についての
記事を掲載しまし
た 。 このアルゴリズムは、発音されていない母音の発音音と発音中の子音の「マージ」の可能性を考慮して、ロシア語の規則と規範に従ってソースワードを変換します。 かなり単純なルールに基づいているという事実にもかかわらず、実際には非常に良い結果を示しています。 すべての文字は、音声グループ(
母音と
子音 (英語の用語ではそれぞれ
母音と
子音 )、聴覚障害者、および有声者)に分けられます。 有声子音は、対応する聴覚障害者のペアに変換され、一連の文字を発音するときに結合され、他のいくつかの操作が実行されます。 以下に、Peter Kankowskiによるオリジナルとは異なり、
TSと
TSまたは
DSの音声等価性に関連する規則を導入し、エンディングを圧縮しない、わずかに変更されたバージョンを示します-バイトの節約は私たちのタスクではありません。
ロシアのメタフォンコード計算アルゴリズム
- すべての母音について、次の操作を実行します。
YO、IO、YE、IE→AND
ああ、私、私→A
E、E、E→I
U→U - L 、 M 、 H、またはPを除くすべての子音が続くすべての子音、または単語の末尾にある子音の場合、スタン:
B→P
S→S
D→T
B→F
G→K - Cで TSとDSを接着します:
TS→Ts
その結果、アルゴリズムは非常にうまく機能します-結果セットには、音声学的に類似した単語が含まれています。 同時に、母音は無視されず、変換されて最終コードで使用されるため、かなりの数の余分な単語が残ります。 ただし、音声の類似性にもかかわらず、「厳格な」アルゴリズム規則のために結果セットに分類されない単語がいくつかあります。
Adolf Schwarzeneggerの場合、ロシアの
Metaphoneアルゴリズムの結果は次のようになります。
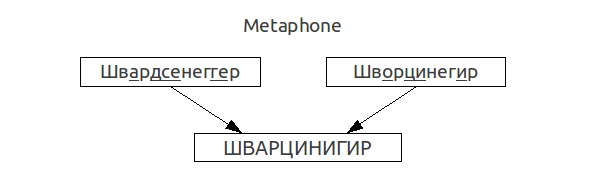
したがって、この場合のアルゴリズムは、これら2つの姓の実際の音声の類似性を反映しています。
例
VITAFSKY →Vitavsky、Vitovsky。
VITINBIRK →ヴィッテンベルク、ヴィッテンベルク。
NASANAF →ナサノフ、ナソノフ、ナッソノフ、ノソノフ。
PIRMAKAF →ペルマコフ、ペルミャコフ、ペルミャコフ。
このアルゴリズムは、平均で1〜2名の姓を同じコードに変換します。
カベルフォン
Caverphoneアルゴリズムは、古い選挙リストと新しい選挙リストのデータを比較するためのニュージーランドプロジェクトの一部として2002年に開発されたため、ロシア語の姓にはかなり受け入れられる結果が得られますが、地元の発音に最も焦点を当てています。
Caverphoneコード計算アルゴリズム
- 姓または名を小文字に変換します(アルゴリズムでは大文字と小文字が区別されます)。
- 最後の文字eを削除します。
- 単語の先頭を次の表に変換します(ニュージーランドのローカル名と姓に関連)。 この場合、数字2は子音文字のタイムスタンプを意味し、その後削除されます。
| せき | ラフ | 厳しい | 十分な | gn | mb |
| cou2f | rou2f | tou2f | enou2f | 2n | m2 |
- 次の表の文字を置き換えます。
| cq | ci | ce | cy | tch | c | q | x | v | dg | ティオ | ティア | d | ph | b | sh | z |
| 2q | si | se | sy | 2ch | k | k | k | f | 2g | シオ | シア | t | fh | p | s2 | s |
- 単語の先頭のすべての母音をAに置き換えます。それ以外の場合は3に置き換えます。 したがって、数字3は母音文字のタイムスタンプとして機能し、その後の変換で使用されてから削除されます。 その後、次の表に従って置換を行う必要があります(慣習: s +は複数の連続した文字、 ^ hは行頭の文字、 w $は行末の文字です)。
| j | ^ y3 | ^ y | y | 3gh3 | gh | g | s + | t + | p + | k + | f + | m + |
| y | Y3 | A | 3 | 3kh3 | 22 | k | S | T | P | K | F | M |
| n + | w3 | wh3 | w $ | w | ^ h | h | r3 | r $ | r | l3 | l $ | l |
| N | W3 | Wh3 | 3 | 2 | A | 2 | R3 | 3 | 2 | L3 | 3 | 2 |
- すべての数字を削除します2 。 単語の末尾に数字の3が残っている場合は、 Aに置き換えます。 次に、 3桁すべてを削除します。
- 単語を10文字にトリミングするか、単位付きで10文字に追加します。
例
KPRLN11111 →ガブレリャン、ガブリリャン、ガブリリャン、カパルリン、カプラリン、カプレリャン。
MSRFK11111 →マイセロビッチ、ミサロビッチ、ミシュレビッチ。
PLLF111111 →バララエフ、バラリエフ、バラルーエフ、ビラリエフ、ビラロフ、ビリヤロフ、ボレロフ、パリロフ、ポリロフ、ポルリャホフ。
Caverphoneは、約4〜5個の姓を同じコードに一致させます。
合計
これらのアルゴリズムのほとんどは、C、C ++、Java、C#、PHPなどの多くの言語で実装されています。 SoundexやMetaphoneなどの一部は、多くの一般的なDBMSのプラグインとして統合または実装されており、
Apache Luceneなどの本格的な検索エンジンの一部としても使用されます。 ユーザーの利便性の大幅な向上は名前を検索することによってのみ達成できるため、アプリケーションの範囲は非常に具体的ですが、それでも検索エンジンの場合、その有能な使用はプラスです。
参照資料
- 記事のJavaコード。 Yandex.Disk
- JavaでのSoundex、洗練されたSoundex、Metaphone、Double Metaphone、Caverphoneの実装。
Apache Commonsコーデック - JavaでのNYSIISの実装。 エゴトールプロジェクト
- JavaでのDaitch-Mokotoff Soundexの実装。 http://joshualevy.tripod.com/genealogy/dmsoundex/dmsoundex.zip
- 説明Soundex。 http://en.wikipedia.org/wiki/Soundex
- Daitch-Mokotoff Soundexの説明。 http://www.jewishgen.org/infofiles/soundex.html
- NYSIISの説明。
http://en.wikipedia.org/wiki/New_York_State_Identification_and_Intelligence_System - 説明Metaphone。 http://en.wikipedia.org/wiki/Metaphone
- ダブルメタフォンの説明。 http://www.drdobbs.com/article/184401251
- ロシアのメタフォンの説明。 http://forum.aeroion.ru/topic461.html
- Caverphoneの説明。 http://en.wikipedia.org/wiki/Caverphone
- Soundexオンラインデモ。 http://www.gedpage.com/soundex.html
- NYSIISオンラインデモ。 http://www.dropby.com/NYSIIS.html
- Daitch-Mokotoff Soundexのオンラインデモ。 http://stevemorse.org/census/soundex.html
- Metaphoneオンラインデモ。 http://www.searchforancestors.com/utility/metaphone.php