それは
バルト海の科学技術コンペティションで私が発表した作品の名前であり、ローマの統一感のある魅力的な紙と、新しいラップトップをもたらしました。
作業は、SMSを送信するという形で大規模なモバイルオペレータが使用するCAPTCHAを認識し、そのアプローチの有効性が不十分であることを実証することにありました。 誰かのプライドを傷つけないために、これらのオペレーターをall意的に赤、黄、緑、青と呼びます。
このプロジェクトは正式に
Captchureと非公式の
Breaking Defective Security Measuresと名付けられ
ました 。 一致するものはすべてランダムです。
奇妙なことに、これらのCAPTCHAのすべて(まあ、ほとんどすべて)はかなり弱かったです。 最小の結果-20%-は黄色の演算子に属し、最大-86%-は青色の演算子に属します。 したがって、「非効率性を実証する」という課題はうまく解決されたと思います。
携帯電話事業者を選ぶ理由は簡単です。 著名な科学審査員に、私は自転車に「携帯電話会社はあらゆるスキルのプログラマーを雇うのに十分なお金を持っているが、同時にスパムの量を最小限に抑える必要がある」と語った。 したがって、彼らのCAPTCHAは非常に強力であるはずであり、私の研究が示すように、それはまったくそのようなものではありません。」 実際、すべてがはるかに簡単でした。 単純なCAPTCHA
を認識するために
ハッキングして経験を得たいと思い、CAPTCHAの犠牲者として赤い演算子を選択しました。 そしてその後、前述の物語がさかのぼって生まれました。
だから、体に近い。 4種類すべてのCAPTCHAを認識するための高度なアルゴリズムはありません。 代わりに、CAPTCHAの種類ごとに別々に4つの異なるアルゴリズムを作成しました。 ただし、アルゴリズムは詳細が異なるという事実にもかかわらず、一般的に非常に類似していることが判明しました。
私の前の多くの著者と同様に、CAPTCHA認識タスクを3つのサブタスク(前処理(前処理)、セグメンテーション、および
認識 )に分割し
ました。 前処理段階では、元の画像からさまざまなノイズ、歪みなどが除去され、セグメンテーションでは、元の画像から個々の文字が抽出され、後処理(逆回転など)から生成されます。 認識中、文字は事前に訓練されたニューラルネットワークによって1つずつ処理されます。
前処理のみが大きく異なっていました。 これは、異なるCAPTCHAがそれぞれ異なる画像歪み方法を使用し、これらの歪みを除去するアルゴリズムが非常に異なるという事実によるものです。 セグメンテーションは、わずかなねじれのある接続コンポーネントを見つけるという重要なアイデアを活用しました(それらは黄色の
縞模様でのみ重要でした)。 認識は4つの演算子のうち3つでまったく同じでした-繰り返しますが、黄色の演算子だけが異なっていました。
コードは、
OpenCVおよび
FANNライブラリを使用して
Pythonで記述されてい
ます。OpenCVおよび
FANNライブラリは 、適切なファイルサイズと追加のタンバリンなしでは
インストールできません。 したがって、少なくとも上記のライブラリの作成者がPythonの通常のバインディングを作成するまで、私の結果を再現するのは簡単ではありません。
赤
私が言ったように、私が最初に選んだウサギはこのCAPTCHAでした。 いくつかの例が状況を明らかにすると思います。


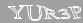
それだけで、最初は非常にシンプルであるように思えました...しかし、この印象はゼロからではありませんでした。 だから:
- 色はグレースケールに制限され、シンボルは明るい、背景は暗い
- 余分なノイズはありません
- 永続的な歪み(つまり、画像ごとに変化しない)
- 常に正確に5文字あります
- 文字サイズはほぼ同じです
- シンボルはほとんど常に接続されています
これはすべて、このCAPTCHAの美徳を無効にしているように見えました。
- 付箋
- Vile Holeyフォント
- 非常に小さいサイズ(83x23 px)
当然のことながら、これらの「利点」は、自動認識の複雑さという点でのみです。 前述の3段階のスキームに従って、画像の予備処理、つまり2倍の増加から始めます。


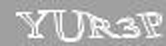
既に述べたように、歪みは一定であり、線形ではありませんが、取り除くことは難しくありません。 パラメータは経験的に選択されました。




次に、t = 200でしきい値変換(一般的にはThreshold)を適用し、画像を反転します。


最後に、小さな(10ピクセル未満)黒の接続領域が白で塗りつぶされます。



これに続いてセグメンテーションが行われます。 先ほど言ったように、接続コンポーネントの検索はここに適用されます。



時々(まれですが、実際に)文字がいくつかの部分に分割されることがあります。 この厄介な誤解を修正するために、いくつかの接続されたコンポーネントが同じシンボルに属していることを評価する比較的単純なヒューリスティックを使用します。 この推定値は、各シンボルの境界ボックスの水平位置とサイズのみに依存します。

多くのシンボルが1つの接続されたコンポーネントに結合されていることがわかりやすいため、それらを分離する必要があります。 ここでは、画像が常に正確に5文字であるという事実が助けになります。 これにより、見つかった各コンポーネントに含まれる文字数を正確に計算できます。
そのようなアルゴリズムの動作原理を説明するには、ハードウェアをもう少し詳しく調べる必要があります。 nで見つかったセグメントの数
と、すべてのセグメントの幅の配列(
正確にはい? )を幅[n]で示します。 上記のステップn> 5の後、画像が認識できなかったと仮定します。 整数の正の項への数値5の可能なすべての分解を考慮します。 それらの多くはありません-たったの16です。そのような分解はそれぞれ、見つかった接続されたコンポーネント上の文字のいくつかの可能な配置に対応します。 結果のセグメントが広くなるほど、含まれる文字が多くなると想定するのは論理的です。 5つの分解すべてのうち、項の数がnであるもののみを選択します。 各要素を幅から幅[0]に分割します-それらを正規化するかのように。 残りのすべての分解についても同じことを行います。それらの各数値を最初の項で除算します。 そして今(注意、クライマックス!)、結果の順序付けられたn-kiはn次元空間の点と考えることができることに注意してください。 これを念頭に置いて、5つの正規化された幅の最も近いユークリッド分解を見つけます。 これは望ましい結果です。
ちなみに、このアルゴリズムに関連して、数字から項へのすべての分解を探す別の興味深い方法が思い浮かびましたが、Pythonデータ構造を掘り下げて実装しませんでした。 要するに、特定の長さの拡張の数がパスカルの三角形の対応するレベルと一致することに気づいた場合、それは非常に明らかに忍び寄る。 しかし、私はこのアルゴリズムが長い間知られていると確信しています。
したがって、各コンポーネントの文字数を決定すると、次のヒューリスティックが発生します。文字間の区切り文字は文字自体よりも薄いと考えられます。 この最も内側の知識を使用するために、セグメントにn-1個のセパレーターを配置します(nはセグメント内の文字数です)。その後、各セパレーターの小さな近傍で画像を下方に計算します。 この投影の結果、シンボルに属する各列のピクセル数に関する情報を取得します。 最後に、各プロジェクションで最小値を見つけてそこにセパレータを移動し、その後、これらのセパレータで画像を細断します。




最後に、認識。 私が言ったように、彼のために私はニューラルネットワークを使用しています。 彼女を訓練するために、最初に一般的な見出し
trainsetの下で200枚の画像を実行して、既に作成およびデバッグされた最初の2段階を実行します。 次に、手でガベージをクリーンアップし(不適切なセグメンテーションの結果など)、その後、結果を同じサイズにしてFANNに渡します。 出力では、認識に使用される訓練されたニューラルネットワークを取得します。 この回路は1回だけ故障しましたが、後でさらに故障しました。
その結果、テストセットで100枚中
45枚の画像が正しく認識されました(トレーニングには使用されず、コード名は
testsetです )。それほど高い結果ではありません。これを台無しにするのは面倒でした。
さらに、アルゴリズムのパフォーマンスを評価するための別の基準、平均誤差を使用しました。 次のように計算されました。 各画像について、この画像に関するアルゴリズムの意見と正解の間でレーベンシュタイン距離が見つかりました。その後、すべての画像の算術平均が取られました。 このタイプのCAPTCHAでは、平均エラーは0.75文字/イメージでした。 これは単なる認識の割合よりも正確な基準であるように思えます。
ちなみに、ほぼすべての場所(黄色の演算子を除く)で、このようなスキームを使用しました-トレインセットで200枚、テストセットで100枚。
緑色
緑を選んだ次の目標は、ディストーションマトリックスを選択することよりももっと深刻なことをしたかったことです。
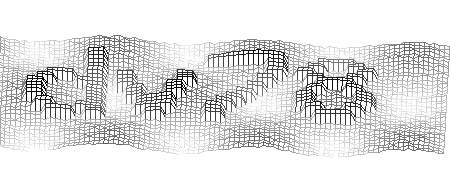

利点:
短所:
- シンボルは背景よりも著しく暗い
- 長方形の上側がはっきりと見える-逆回転に使用できます
これらの短所は取るに足らないように思えますが、それらの操作によりすべての利点を非常に効果的に処理できることが判明しました。
繰り返しますが、前処理から始めましょう。 最初に、シンボルが置かれている長方形の回転角度を推定します。 これを行うには、元の画像にErode演算子(ローカルミニマムの検索)を適用し、次にしきい値を使用して長方形の残りの部分、最後に反転を選択します。 黒い背景に素敵な白い斑点を付けます。
その後、深い思考を開始します。 最初のもの。 長方形全体の回転角度を推定するには、上側の回転角度を推定するだけで十分です。 二番目。 この辺に平行な直線を検索することにより、上側の回転角度を推定できます。 三番目。 厳密に垂直を除く任意の直線を記述するには、座標の中心からの垂直変位と傾斜角の2つのパラメーターで十分です。2番目のパラメーターのみに関心があります。 4番目。 直線を見つける作業は、あまり徹底的な検索では解決できません。回転角が大きすぎず、超高精度は必要ありません。 5番目。 必要な行を検索するには、各行を目的の行にどれだけ近いかの推定値と比較し、最大値を選択します。 6番目。 最も重要なこと。 直線の特定の傾斜角を推定するために、この傾斜角の直線が画像に上から触れていると想像してみましょう。 画像のサイズと傾斜角から、直線の垂直方向の変位を明確に計算できるため、一意に設定できます。 次に、この行を徐々に下に移動します。 ある時点で、白い点に触れます。 この瞬間と、線とスポットの交点の面積を覚えておいてください。 直線には平面上で8連結表現があるため、直線には1つの次元があり、面積は2次元の概念であるという怒りの声はここでは不適切です。 次に、この直線をもう少し下に移動し、各ステップで交差領域を覚えてから、結果をまとめます。 この量は、この回転角の推定値になります。


上記を要約すると、画像を下に移動すると、この線上にあるピクセルの輝度が最も急激に増加するような線を探します。
したがって、回転角度が見つかりました。 しかし、得られた知識をすぐに適用するために急いではいけません。 事実、これにより画像の一貫性が損なわれますが、それでも必要です。
次のステップは、文字を背景から分離することです。 ここで、キャラクターが背景よりもはるかに暗いという事実は、私たちを大いに助けます。 それは開発者側の論理的なステップです-そうでなければ、絵を読むのは非常に難しいでしょう。 信じられない人は、自分でイメージを二値化して、自分で見ることができます。
ただし、ここでは、「額」アプローチ(しきい値変換によって文字を切り捨てる試み)は機能しません。 達成できた最高の結果(t = 140)は非常に嘆かわしいものです。 ゴミが多すぎます。 したがって、回避策を適用する必要がありました。 ここでの考え方は次のとおりです。 通常、シンボルは接続されています。 さらに、それらはしばしば画像の最も暗い点に属します。 しかし、これらの最も暗いポイントから塗りつぶしを適用して、非常に小さな浸水領域を捨てようとするとどうなりますか?
率直に言って、その結果は驚くべきものです。 ほとんどの画像では、背景を完全に取り除くことができます。 ただし、シンボルが複数の部分に分割されることがあります-この場合、1つの松葉杖はセグメンテーションに役立ちますが、それについては後で詳しく説明します。

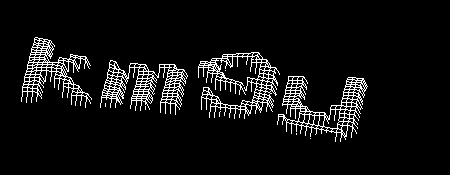
次に、前に見つけた角度に向きを変えます。


最後に、膨張演算子と収縮演算子の組み合わせにより、文字に残っている小さな穴がなくなり、認識が簡単になります。


ここでのセグメンテーションは、前処理よりもはるかに簡単です。 まず、接続されたコンポーネントを探しています。


次に、水平方向に近いコンポーネントを結合します(手順は以前とまったく同じです)。


実際には、それだけです。 認識は続きますが、上記と違いはありません。
このアルゴリズムにより、認識された画像の69%で結果を達成し、0.3文字/画像の平均誤差を得ることができました。
青
そのため、青のオペレーターは3番目に「敗北」状態になりました。 いわば、本当に大きな魚の前での休息でした...



価値あるものを書き留めるのは難しいですが、私はまだやっています:
- シンボルを回すことは多かれ少なかれ唯一の深刻な障害です
- 文字の形の背景ノイズ
- シンボルは時々互いに接触します。
これとは対照的に:
- 背景は文字よりもかなり明るい
- シンボルが長方形にうまく収まる
- キャラクターの色が異なるため、キャラクターを簡単に分離できます
だから、前処理。 背景をクリップすることから始めましょう。 画像は3色なので、チャンネルに切り取り、すべてのチャンネルで116より明るいすべてのポイントを破棄します。 このようなかわいいマスクを取得します。



次に、画像をHSV色空間(
Wikipedia )に変換します。 これにより、文字の色に関する情報が保存されると同時に、エッジからグラデーションが削除されます。



前に取得したマスクを結果に適用します。



この前処理は終了します。 セグメンテーションも非常に簡単です。 いつものように、接続コンポーネントから始めましょう。




これで停止することは可能ですが、私にはまったく合わない73%だけです。明らかに複雑なCAPTCHAの結果よりも4%だけ優れています。 したがって、次のステップはキャラクターの逆回転です。 ここで、ローカル文字が長方形にうまく適合することをすでに述べたという事実は、私たちにとって有用です。 アイデアは、各文字の説明的な長方形を見つけ、その傾きを使用して文字自体の傾きを計算することです。 ここで、長方形の記述とは、第1に、指定されたシンボルのすべてのピクセルを含み、第2に、可能な限り最小の領域を持つことを意味すると理解されます。 OpenCV(
MinAreaRect2 )からのこのような長方形に対して、既成の検索アルゴリズムの実装を使用します。

さらに、いつものように、認識が続きます。
このアルゴリズムは、画像の86%を0.16文字/画像の平均誤差で正常に認識します。これは、このCAPTCHAが実際に最も単純であるという仮定を裏付けています。 しかし、演算子は最大ではありません...
黄色
最も興味深い部分が来ています。 いわば、私の創造的活動の神格化:)このCAPTCHAは、コンピュータにとって、そして残念なことに、人にとっては本当に難しいものです。



利点:
- スポットとラインの形のノイズ
- 文字を回転および拡大縮小する
- キャラクターの近接
短所:
- 非常に限られたパレット
- すべての線が非常に細い
- 多くの場合、スポットはシンボルと重ならない
- すべてのキャラクターの回転角度はほぼ同じです
私は長い間、最初のステップについて考えました。 最初に思いついたのは、浅いノイズを除去するためにローカルの高音(拡張)をいじることでした。 しかし、このアプローチは、文字のほとんどが残されていないという事実につながりました-破れた輪郭のみ。 この問題は、キャラクター自体のテクスチャーが不均一であるという事実によって悪化しました-これは高倍率ではっきりと見えます。 それを取り除くために、私は最も愚かな方法を選択することにしました-私はペイントを開き、画像にあるすべての色のコードを書き留めました。 これらすべての画像には4つの異なるテクスチャがあり、そのうちの3つは4つの異なる色を持ち、最後の3つは-3です。 さらに、これらの色のすべてのコンポーネントは51の倍数であることが判明しました。次に、カラーテーブルをコンパイルしました。これにより、テクスチャを取り除くことができました。 ただし、この「リマップ」の前に、通常は文字の端にある明るすぎるピクセルをすべて上書きします。そうでない場合は、多くの情報はありませんが、ノイズとしてマークしてから対処する必要があります。
したがって、この変換後、画像には6色以下が含まれます-4文字の色(グレー、ブルー、ライトグリーン、ダークグリーンと任意に呼ばれます)、白(背景色)、および「不明」は、ピクセルの色がその場所は有名な花のどれとも特定できませんでした。 条件付きと呼ばれます-この瞬間までに3つのチャネルを取り除き、使い慣れた便利なモノクロ画像に移行するからです。



次のステップは、線から画像を消去することでした。 ここでは、これらの線が非常に細いという事実(1ピクセルのみ)によって状況が保存されます。
シンプルなフィルターは、画像全体を調べて、各ピクセルの色をその隣のピクセルの色と比較します(ペアで-垂直および水平)。隣人が同じ色であるが、ピクセル自体の色と一致しない場合、隣人と同じ色にします。同じフィルターのもう少し洗練されたバージョンを使用します。これは2段階で機能します。最初は、距離2、2番目、距離1で近隣を推定します。これにより、この効果を得ることができ
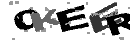
 ます。次に、ほとんどのスポットと「不明な」色を取り除きます。これを行うには、まず、接続されているすべての小さなエリア(正確には15未満のエリア)を探し、それらを白黒のマスクに配置してから、その結果を「不明な」色が占めるエリアと組み合わせます。
ます。次に、ほとんどのスポットと「不明な」色を取り除きます。これを行うには、まず、接続されているすべての小さなエリア(正確には15未満のエリア)を探し、それらを白黒のマスクに配置してから、その結果を「不明な」色が占めるエリアと組み合わせます。

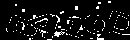 これらのマスクを使用して、画像にアルゴリズムを設定しますInpaint(または、OpenCVでの実装)。これにより、イメージからほとんどのゴミを非常に効率的にクリーニングできます。
これらのマスクを使用して、画像にアルゴリズムを設定しますInpaint(または、OpenCVでの実装)。これにより、イメージからほとんどのゴミを非常に効率的にクリーニングできます。

 ただし、OpenCVでのこのアルゴリズムの実装は、ノイズの多いテキストを使用して人為的に作成された画像の認識ではなく、写真やビデオで動作するように作成されました。適用後、グラデーションが表示されます。これは、セグメンテーションを簡素化するために回避したいものです。したがって、追加の処理、つまりシャープニングを実行する必要があります。各ピクセルの色については、上の表から最も近いピクセルを計算します(5つの色があります-各キャラクターテクスチャと白に1つあります)。
ただし、OpenCVでのこのアルゴリズムの実装は、ノイズの多いテキストを使用して人為的に作成された画像の認識ではなく、写真やビデオで動作するように作成されました。適用後、グラデーションが表示されます。これは、セグメンテーションを簡素化するために回避したいものです。したがって、追加の処理、つまりシャープニングを実行する必要があります。各ピクセルの色については、上の表から最も近いピクセルを計算します(5つの色があります-各キャラクターテクスチャと白に1つあります)。

 最後に、前処理の最後のステップは、残っている小さな接続領域をすべて削除することです。 Inpaintを適用すると表示されるため、ここでは繰り返しはありません。
最後に、前処理の最後のステップは、残っている小さな接続領域をすべて削除することです。 Inpaintを適用すると表示されるため、ここでは繰り返しはありません。

 セグメンテーションに進みます。文字が互いに非常に近いという事実により、非常に複雑になります。このような状況では、一方のシンボルの後ろに他方の半分が見えないことがあります。これらのシンボルが同じ色の場合、非常に悪くなります。さらに、残骸も役割を果たします-元の画像では、線が1か所で多数交差していることがあります。この場合、前に説明したアルゴリズムではそれらを取り除くことはできません。1週間前のケースと同じ方法でセグメンテーションを作成する無駄な試みに費やした後、私はこの問題を採点し、戦術を変更しました。私の新しい戦略は、セグメンテーションプロセス全体を2つの部分に分割することでした。最初に、シンボルの回転角度が推定され、逆回転が実行されます。既に展開されている画像の2番目では、文字が再び強調表示されます。それでは始めましょう。いつものように、接続されたコンポーネントの検索から始めます。
セグメンテーションに進みます。文字が互いに非常に近いという事実により、非常に複雑になります。このような状況では、一方のシンボルの後ろに他方の半分が見えないことがあります。これらのシンボルが同じ色の場合、非常に悪くなります。さらに、残骸も役割を果たします-元の画像では、線が1か所で多数交差していることがあります。この場合、前に説明したアルゴリズムではそれらを取り除くことはできません。1週間前のケースと同じ方法でセグメンテーションを作成する無駄な試みに費やした後、私はこの問題を採点し、戦術を変更しました。私の新しい戦略は、セグメンテーションプロセス全体を2つの部分に分割することでした。最初に、シンボルの回転角度が推定され、逆回転が実行されます。既に展開されている画像の2番目では、文字が再び強調表示されます。それでは始めましょう。いつものように、接続されたコンポーネントの検索から始めます。

 次に、各キャラクターの回転角度を評価する必要があります。 Greenpeaceのオペレーターファンと一緒に仕事をしているときでさえ、このためのアルゴリズムを思いつきましたが、ここでのみそれを書いて適用しました。彼の作品を説明するために、類推をします。シンボルの白黒画像上で上下に動くピストンを想像してください。押すピストンのハンドルは垂直に配置され、押す作業プラットフォームは水平で、画像の底部に平行で、ハンドルに垂直です。ハンドルはプラットフォームの中央に取り付けられ、可動ジョイントが取り付け点に配置されているため、プラットフォームを回転させることができます。専門用語を許してください。物理学の法則に従って、ペンを上に動かして、ペンの前の地面を押します。シンボルの白い画像のみがマテリアルであり、ピストンが黒い背景を簡単に通過すると仮定します。その後、ピストンは白に到達し、それと相互作用し始めます。つまり、ハンドルに力がまだ加えられている場合、回転します。彼は次の2つの場合に停止できます。力の作用点の両側にあるシンボルの上に置いた場合、または力の作用点の近くにシンボルの上に置いた場合。他のすべての場合、彼は動き続けることができます。注意、クライマックス:シンボルの回転角度は、ピストンが停止した瞬間のピストンの傾斜角度であると想定しています。
次に、各キャラクターの回転角度を評価する必要があります。 Greenpeaceのオペレーターファンと一緒に仕事をしているときでさえ、このためのアルゴリズムを思いつきましたが、ここでのみそれを書いて適用しました。彼の作品を説明するために、類推をします。シンボルの白黒画像上で上下に動くピストンを想像してください。押すピストンのハンドルは垂直に配置され、押す作業プラットフォームは水平で、画像の底部に平行で、ハンドルに垂直です。ハンドルはプラットフォームの中央に取り付けられ、可動ジョイントが取り付け点に配置されているため、プラットフォームを回転させることができます。専門用語を許してください。物理学の法則に従って、ペンを上に動かして、ペンの前の地面を押します。シンボルの白い画像のみがマテリアルであり、ピストンが黒い背景を簡単に通過すると仮定します。その後、ピストンは白に到達し、それと相互作用し始めます。つまり、ハンドルに力がまだ加えられている場合、回転します。彼は次の2つの場合に停止できます。力の作用点の両側にあるシンボルの上に置いた場合、または力の作用点の近くにシンボルの上に置いた場合。他のすべての場合、彼は動き続けることができます。注意、クライマックス:シンボルの回転角度は、ピストンが停止した瞬間のピストンの傾斜角度であると想定しています。 このアルゴリズムはかなり正確ですが、結果が明らかに大きすぎる(27度以上)ので考慮していません。残りのもののうち、算術平均を見つけます。その後、画像全体がマイナスこの角度だけ回転します。次に、接続コンポーネントを再度検索します。
このアルゴリズムはかなり正確ですが、結果が明らかに大きすぎる(27度以上)ので考慮していません。残りのもののうち、算術平均を見つけます。その後、画像全体がマイナスこの角度だけ回転します。次に、接続コンポーネントを再度検索します。

 さらに、それはますます興味深いものになります。前の例では、受信したセグメントでさまざまな詐欺を開始し、その後、それらをニューラルネットワークに転送しました。ここではすべてが異なります。まず、画像を接続されたコンポーネントに分割した後に失われた情報を少なくとも部分的に復元するために、各セグメントにダークグレー(96)で「グレー」を描画します。 、その後、ラインの前処理と同じ手順を使用して文字のアウトラインを滑らかにします(隣人までの距離は1に等しい)。
さらに、それはますます興味深いものになります。前の例では、受信したセグメントでさまざまな詐欺を開始し、その後、それらをニューラルネットワークに転送しました。ここではすべてが異なります。まず、画像を接続されたコンポーネントに分割した後に失われた情報を少なくとも部分的に復元するために、各セグメントにダークグレー(96)で「グレー」を描画します。 、その後、ラインの前処理と同じ手順を使用して文字のアウトラインを滑らかにします(隣人までの距離は1に等しい)。 正式には(プログラムモジュールの観点から)、セグメンテーションはここで終了します。注意深い読者は、粘着性のあるキャラクターの分離がどこにも言及されていないことに気付いたに違いありません。はい、これはそうです-認識のために、私はこのフォームでそれらを渡し、その場で仕上げます。その理由は、先に説明した(最小の投影で)スタックされた文字を分離する方法がここでは機能しないためです-フォントは作成者によって非常に適切に選択されました。したがって、別のより複雑なアプローチを適用する必要があります。このアプローチは、セグメンテーションにニューラルネットワークを使用できるという考えに基づいています。最初に、このセグメントの幅がわかっているセグメント内の文字数と文字の総数を見つけることができるアルゴリズムについて説明しました。ここでも同じアルゴリズムが使用されます。各セグメントについて、その中の文字数が計算されます。彼が一人でいる場合は、何もする必要はありません。このセグメントはすぐにニューラルネットワークに到達します
正式には(プログラムモジュールの観点から)、セグメンテーションはここで終了します。注意深い読者は、粘着性のあるキャラクターの分離がどこにも言及されていないことに気付いたに違いありません。はい、これはそうです-認識のために、私はこのフォームでそれらを渡し、その場で仕上げます。その理由は、先に説明した(最小の投影で)スタックされた文字を分離する方法がここでは機能しないためです-フォントは作成者によって非常に適切に選択されました。したがって、別のより複雑なアプローチを適用する必要があります。このアプローチは、セグメンテーションにニューラルネットワークを使用できるという考えに基づいています。最初に、このセグメントの幅がわかっているセグメント内の文字数と文字の総数を見つけることができるアルゴリズムについて説明しました。ここでも同じアルゴリズムが使用されます。各セグメントについて、その中の文字数が計算されます。彼が一人でいる場合は、何もする必要はありません。このセグメントはすぐにニューラルネットワークに到達します>> =。複数のシンボルがある場合、潜在的な区切り線はセグメントに沿って等距離に配置されます。その後、各セパレーターはそれぞれの小さな近傍を移動し、途中でこのセパレーターの近くのキャラクターに対するニューラルネットワークの反応が計算されます。その後、最大値を選択するためだけに残ります(実際、これはかなりばかげたアルゴリズムを作成しますが、原則としてすべてが本当にそのようになります)。当然、セグメンテーション(または必要に応じて事前セグメンテーション)のプロセスにニューラルネットワークが参加することで、既に説明したニューラルネットワークのトレーニングスキームを使用する可能性が除外されます。より正確には、最初のニューラルネットワークを取得することはできません-他の人に教えるために使用できます。したがって、私は非常に簡単に行動します-セグメンテーション(投影)の通常の方法を使用してニューラルネットワークをトレーニングしますが、それを使用すると上記のアルゴリズムが動作します。このアルゴリズムでのニューラルネットワークの使用には、別の微妙な点があります。前の例では、ニューラルネットワークは前処理とセグメンテーションのほぼ生の結果でトレーニングされていました。ここでは、12%を超える成功した認識を得ることができました。これは私には不向きでした。したがって、次のニューラルネットワークトレーニングの時代を始める前に、元の画像にさまざまな歪みを導入し、実際の画像を大まかにモデリングしました:白/グレー/黒のドット、灰色の線/円/長方形の追加、回転。また、トレインセットを200個の画像から300個に増やし、いわゆる有効セットを追加しました100枚の画像のトレーニング中にトレーニングの品質を確認する。これにより、生産性が約5%向上し、ニューラルネットワークのセグメンテーションと相まって、記事の冒頭で述べた結果が得られました。統計を提供することは、2つのニューラルネットワークで終わったという事実によって複雑になります。1つは認識率が高く、もう1つは誤差が小さいことです。ここで最初に結果を示します。合計で、複数回言ったように、テストセットには100枚の画像がありました。これらのうち、20が正常に認識され、80が失敗し、エラーは画像あたり1.91文字でした。他のすべての演算子よりも著しく悪いが、対応するCAPTCHA。結論の代わりに
この作業に関連するすべてのもの
は 、特に
ソースコード 、
ニューラルネットワークのファイル 、
画像など、
自分のサイトの特別なフォーラムスレッドに投稿し
ました 。私は来年何かに参加したいと思います-少なくとも同じ
バルト海の大会 (そしてその後、できれば
Intel ISEFで )に参加したいのですが、創造的な危機が感じられます-プロジェクトの健全なトピックを思い付くことができませんが、続けますキャプチャを台無しにしたいという欲求はありません。 多分habrasocietyは私を助けることができる...
私が持っていたアイデアは、機能するOSと分散(および/または匿名)ネットワークではありませんでしたが、どれも好きではありませんでした。 残念ながら、1つ目はおそらく私にとって複雑すぎます(そして、これらの
機能 軸が必要なのは
誰ですか? )、そして2つ目はすでに十分に実行されています(
I2P 、
Netsukuku )。 同時に、私は、第一に、1年以内に(少なくとも一緒に)できること、そして第二に、同じISEFで高い地位にあると真剣に主張することを望んでいます。 たぶん、あなたは私がどの方向に動くべきかを知ることができますか?
UPD 2015-04-09: Githubのリポジトリ 。