私は、このフレームワークのプラットフォームの明るい代表として、Ruby-on-Rails(RoR)とTwitterに常に興味を持っています。 今年の4月6日、Twitterチームに、RoRからJavaへの検索プラットフォームの完全な変更に関するブログ投稿が掲載されました。 それがいかにあったかのカット翻訳の下で。
「2010年の春に、Twitter検索チームは、増え続けるトラフィックに対応し、エンドユーザーの待ち時間を短縮し、サービスの可用性を高め、新しい検索機能を迅速に開発するために、検索エンジンの書き換えを開始しました。 仕事の一環として、新しい
リアルタイム検索エンジンを立ち上げ、バックエンドをMySQLから
Luceneバージョンに変更しました。 先週、Ruby-on-Railsフロントエンドの代替品をリリースしました。これは、Blenderと呼ばれるJavaサーバーです。 この変更により、検索時間が3倍に短縮され、今後数か月で検索機能を一貫して向上させる機会が得られることをお知らせいたします。
パフォーマンスの向上
Twitter Searchは、世界で最も忙しい検索エンジンの1つであり、1日あたり10億を超える検索クエリを処理します。 今週、Blenderを展開する前に、日本での
#tsunamiは、検索クエリとそれに関連する検索遅延のピークの大幅な増加に貢献しました。 Blenderを起動した後、95%の遅延が800ミリ秒から250ミリ秒に3倍減少し、フロントエンドサーバーのCPU負荷が半分になりました。 これで、マシンごとに10倍のリクエストを処理できるようになりました。 これは、より少ないサーバーで同じ数のリクエストを維持でき、フロントエンドサービスのコストを大幅に削減できることを意味します。
 Blenderを起動する前後の検索APIの95%の遅延。
Blenderを起動する前後の検索APIの95%の遅延。改善されたTwitter検索アーキテクチャ
パフォーマンスの向上をよりよく理解するには、最初に以前のRuby-on-Railsフロントエンドサーバーの弱点を理解する必要があります。 固定数のシングルスレッドワークフローを開始し、それぞれが次のことを行いました。
- 検索クエリを解析しました。
- 同期的に要求された検索エンジン。
- 結果を集約して形成しました。
私たちは、同期リクエスト処理モデルがCPUを非効率的に使用していることを長い間認識してきました。 時間が経つにつれて、メインのRubyコードにかなりの技術的負債が蓄積され、機能の追加と検索エンジンの信頼性の向上が困難になりました。 Blenderはこれらの問題を次の方法で解決します。
- 完全に非同期の集約サービスを作成します。 ネットワークI / Oの完了を待機するスレッドはありません。
- リアルタイムサービス、トップツイートサービス、地理インデックスサービスなどのバックエンドサービスからの結果を集約します。
- サービス間の依存関係をより正確に解決します。 ワークフローは、バックエンドサービス間の推移的な依存関係を自動的に処理します。
次の図は、Twitter検索エンジンのアーキテクチャを示しています。 ウェブサイト、API、またはTwitterの外部クライアントからのリクエストは、ハードウェアロードバランサーを介してBlenderに送信されます。 Blenderは検索リクエストを解析し、ワークフローを使用してサービス間の依存関係を処理し、バックエンドサービスに渡します。 最後に、サービスの結果が結合され、クライアントの適切な言語で形成されます。
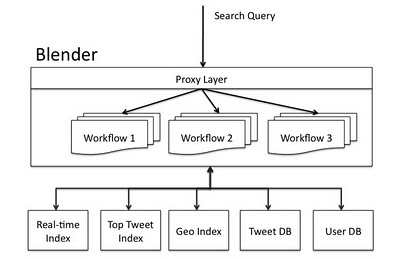 BlenderによるTwitter検索アーキテクチャ。
BlenderによるTwitter検索アーキテクチャ。ブレンダーレビュー
Blenderは、Javaで記述された広くスケーラブルなNIOクライアント/サーバーライブラリである
Netty上に構築されたThriftおよびHTTPサービスであり、さまざまなサーバーおよびクライアント向けに迅速かつ簡単に開発できます。 Netaを選択したのは、MinaやJettyなどのいくつかの競合他社からNettyを選択したためです。これは、より透明なAPI、優れたドキュメント、そして最も重要なことは、他のいくつかのTwitterプロジェクトがこのフレームワークを使用しているためです NettyがThriftで動作するために、ソケットから読み取られたときにNettyチャネルバッファーからの着信Thrift要求をデコードし、ソケットに書き込まれたときに発信Thrift応答をエンコードする単純なThriftコーデックを作成しました。 Nettyは、ネットワークソケットへの接続をカプセル化するチャネルと呼ばれるキー抽象化を導入します。これは、読み取り、書き込み、接続、バインドなど、多くのI / O操作を実行するためのインターフェイスを提供します。 すべてのチャネルI / O操作は本質的に非同期です。 これは、要求されたI / O操作が成功、失敗、またはキャンセルされたときにレポートするChannelFutureのインスタンスで、I / O呼び出しが直ちに返されることを意味します。 Nettyサーバーは、新しい接続を受け入れると、接続を処理するための新しいチャネルパイプラインを作成します。 チャネルパイプラインは、要求の処理に必要なビジネスロジックを実装する一連のチャネルハンドラです。 次のセクションでは、Blenderがこれらのパイプラインをクエリ処理ワークフローに移行する方法を示します。
ワークフローライブラリ
Blenderでは、ワークフローとは、着信リクエストを処理するために処理する必要がある依存関係を持つバックエンドサービスのセットです。 Blenderはそれらの間の依存関係を自動的に決定します。たとえば、サービスAがサービスBに依存している場合、Aが最初に要求され、その作業の結果がBに送信されます。
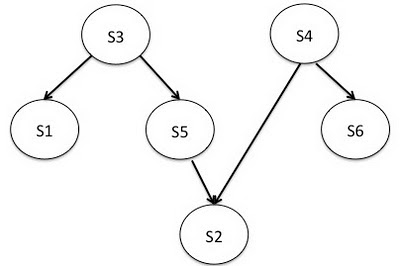 6つのバックエンドサービスを使用したサンプルBlenderワークフロー。
6つのバックエンドサービスを使用したサンプルBlenderワークフロー。ワークフローの例では、6つのサービス{s1、s2、s3、s4、s5、s6}があり、それらの間に依存関係があります。 s3からs1への直線は、s1がs3の結果を必要とするため、s1が呼び出される前にs3を呼び出す必要があることを意味します。 このような作業プロジェクトの場合、Blenderライブラリは
DAGで トポロジカルソートを実行して、サービスの最終順序を決定します。これは、サービスが呼び出される順序でもあります。 上記のワークフローの実行順序は{(s3、s4)、(s1、s5、s6)、(s2)}になります。 つまり、最初のステップでs3とs4を並行して呼び出すことができます。 結果が返されると、次のステップでもs1、s5、およびs6が並行して呼び出されます。 最後の呼び出しs2に。 Blenderが実行順序を決定すると、Nettyパイプラインにマッピングされます。 このパイプラインは、処理のリクエストを渡す必要がある一連のハンドラです。
インバウンド要求の多重化
ワークフローはBlenderのNettyパイプラインにマップされるため、着信クライアントリクエストを適切なパイプラインに送る必要がありました。 これを行うために、次のルールに従ってクライアント要求を多重化してルーティングするプロキシレイヤーを構築しました。
- リモートのThriftクライアントがBlenderへの永続的な接続を開くと、プロキシ層はローカルクライアント用のマップを作成します。ワークフローは、ローカルサーバーごとに1つずつ作成されます。 これらのサーバーはすべて、JVM環境のBlenderプロセスで起動され、Blenderプロセスの起動時に作成されることに注意してください。
- 要求がソケットに到着すると、プロキシ層はそれを読み取り、どのワークフローが要求されたかを判断し、対応するワークフローサーバーに送信します。
- 同様に、ワークフローを処理するローカルサーバーから応答が来ると、プロキシはそれを読み取り、リモートクライアントの応答を書き込みます。
イベント駆動のNettyモデルを使用して、上記のすべてのタスクを非同期に実行したため、I / Oを待機するスレッドはもうありません。
バックエンドリクエストのディスパッチ
検索要求がワークフローのパイプラインに到着するとすぐに、ワークフローによって決定された順序で一連のサービスハンドラーを通過します。 各サービスハンドラーは、この検索要求に対応するバックエンド要求を作成し、リモートサーバーに渡します。 たとえば、リアルタイムサービスハンドラーはリアルタイムリクエストを作成し、1つ以上のリアルタイムインデックスに非同期で送信します。
twitter commonsライブラリ(最近オープンソースになりました!)を使用して、接続プール管理、負荷分散、およびデッドホストの特定を提供します。 検索要求を処理するI / Oスレッドは、すべてのバックエンド応答が処理されると解放されます。 タイマースレッドは、数ミリ秒ごとにバックエンドの応答がリモートサーバーから返されたかどうかを確認し、要求が成功したか、タイムアウトを超えたか、失敗したかを示すフラグを設定します。 このデータ型を管理するために、検索クエリのライフサイクル全体で単一のオブジェクトを維持します。 成功した応答は集約され、ワークフローパイプラインのサービスハンドラーによる処理のために次のステップに送信されます。 最初のステップからのすべての応答が到着すると、非同期要求の2番目のステップが完了します。 このプロセスは、ワークフローが完了するか、待機時間が許容限度を超えるまで繰り返されます。 ご覧のとおり、ワークフローの実行中、I / Oを待機している単一のスレッドはありません。 これにより、BlenderマシンでCPUを効率的に使用し、多数の競合するリクエストを処理できます。 また、バックエンドサービスに対するほとんどのリクエストを並行して実行するため、遅延も節約できます。
Blenderの展開と今後の作業
Blenderをシステムに統合する際に高品質のサービスを確保するために、古いRuby-on-Railsフロントエンドサーバーをプロキシとして使用して、Blenderクラスターのスリフトリクエストをリダイレクトします。 古いフロントエンドサーバーをプロキシとして使用することで、ユーザーエクスペリエンスの整合性を確保し、基盤となるテクノロジに大幅な変更を加えることができます。 展開の次の段階では、検索スタックからRuby-on-Railsを完全に削除し、ユーザーをBlenderに直接接続し、潜在的なレイテンシーをさらに削減します。