Vladimir Klimontovichが
Application Developer Daysカンファレンスで作成したレポートで、
非常に大きなデータボリュームの処理とNOSQLアプローチ(特に
Apache Hadoop )の使用に関する経験を共有しました。

以下は、レポート+ビデオ+オーディオおよびプレゼンテーションスライドのテキストバージョンです。 レポートのプレゼンテーションに取り組んでくれた
belonesoxに感謝します。
問題の歴史 。
- より多くのデータを処理する問題がより重要になっているのはなぜですか(異なる領域でのデータ量の増加の例)。
- MapReduceパラダイムに関するGoogleの記事。 パラダイムの簡単な説明。
- 隣接領域の簡単な説明(分散ファイルシステム、bigtableのようなストレージ)。
- Apache Hadoopプラットフォームの歴史と簡単な説明。
使用例- last.fm(構築チャート)、オンライン広告(構築統計)、Yahoo(構築検索インデックス)の3つの別々の領域でhadoopプラットフォームを使用します。
- 従来のアプローチ(SQLデータベース)および上記の各問題に対してHadoopを使用するアプローチの説明。 SQL / Hadoopアプローチの長所と短所
- SQLクエリの一部のサブタイプをMapReduceジョブに変換する一般的な原則。
Hadoopの上に構築されたプラットフォーム 。
- Hadoopの上に構築されたHiveおよびPig ETLフレームワークの簡単な説明。
- 使用例(facebook.comやYahooなど); 標準SQLアプローチとの比較
Apache Hadoopを使用する場合のリアルタイムデータアクセスの問題 。
- リアルタイムが必要な場合とそうでない場合の説明。
- リアルタイムでの単純な問題の解決の説明:メモリへのキャッシュ(memcached)、SQLとの共生
- 例としてHBaseを使用したbigtableのようなデータベースとの共生。 HBaseの短い説明。
トレンドとしてのHadoop 。
- Hadoopを使用した技術およびビジネスの問題の概要
- HadoopおよびNoSQLアプローチに関する誇大広告。 SQLが便利な場合の説明。
映像表示に問題がある場合は、
リンクを使用できます。
音声レポートの音声版は
こちらから入手でき
ます 。
レポート発表レポートのプレゼンテーションは
こちらから入手でき
ます 。
データ量
そのため、それが何であるか、どのようなデータ量であるかを想像することができます。 たとえば、誰もが知っている
Facebookの会社、おそらく誰もがそこにプロファイルを持っています。このソーシャルネットワークに
は1日に 40テラバイトの新しいデータ
(写真、投稿、コメント)があります。
次に
、ニューヨーク証券取引所 -1日あたり
1テラバイトの取引、取引、株式の売買などに関するデータがあります。
大型のアンドロンコライダー :これは、1日に約
40テラバイトの実験データ、粒子の速度と位置に関する情報などです。
たとえば、小さな会社で何が起こっているかを想像してみてください
。ContextWebは実際に働いているアメリカの小さな会社です。オンライン広告に従事し、市場の割合が非常に小さいにもかかわらず、
115ギガバイトのログがあります 1日あたりのコンテンツ広告を表示します。 さらに、これらは単なるテキストファイルではなく、115ギガバイトの圧縮データです。 実際、おそらくもっと多くのデータがあります。
DFS / MapReduce
質問が発生します、実際にそれらをどうするか? どういうわけかそれらを処理する必要があるため。 それだけでは、そのような量のデータは誰にとっても興味がなく、ほとんど役に立たない。
この量のデータを処理する1つの方法は、Googleによって考案されました。 2003年に、Googleは分散ファイルシステム、データとインデックスの保存方法、ユーザーデータなどの内部に関するかなり有名な記事をリリースしました。
2004年にも、GoogleはMapReduceと呼ばれるこのような大量のデータを処理するパラダイムを説明する記事をリリースしました。
実際、これはまさにこれから説明する内容であり、一般的にどのように配置され、Apache Hadoopプラットフォームにどのように実装されるかです。
分散FS
分散ファイルシステム-それは何ですか? 分散ファイルシステムにはどのタスクが割り当てられていますか?
- まず、それは大量のデータのストレージです-任意のサイズのファイル...
- 第二に、これは単なる透明性です。このファイルシステムを通常のファイルシステムとして使用します。ファイルを開いて、そこに何かを書き込み、ファイルを閉じて、バラバラで大きなものではないと考えます。
- また、他にも必要なのはスケーラビリティです。 クラスターにファイルを保存し、非常に簡単にスケーリングしたいのです。 たとえば、ビジネスが2倍になり、データ量が2倍になりました。アーキテクチャを修正することなく、データを2倍保存し、マシンを2倍追加するだけです。
- また、信頼性。 つまり クラスターがあります。100台のマシンのうち、5台などが故障しています。これに気付かないようにする必要があります。ファイルにアクセスしたり、読み書きしたりするためです。これらの5台の車に気付くまで。
DFS:アーキテクチャ
厳密に言えば、これがどのように実装されているか。 小さなスケジュールがあり、おそらく表示されませんが、一般的には表示されます、はい。
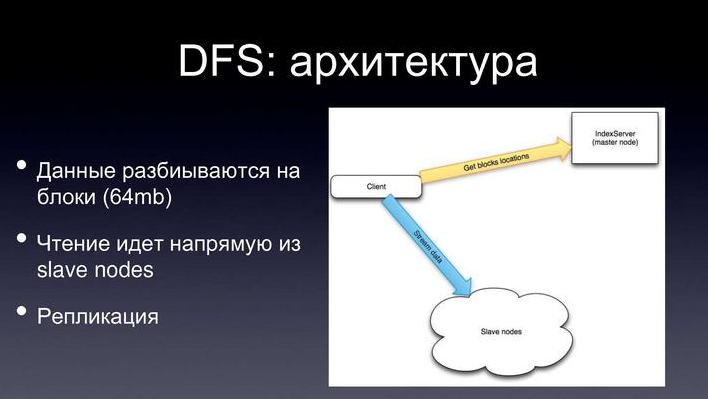
マシンのクラスターがあり、その中には多くのデータが保存されています。 マスターノードと呼ばれる1つのマシンがあり、すべてを調整します。
マスターノードには何が保存されますか? マスターノードは単にファイルテーブルを保存します。 ファイルシステムの構造。各ファイルはブロックに分割され、特定のクラスターマシン上にファイルのブロックが保存されます。
読み書きはどうですか? ある種のファイルを読みたいので、そのようなファイルのブロックが保存されているマスターノードに尋ね、特定のブロックを保存しているマシンを教えてくれます。すでにクラスターマシンから直接読み込んでいます。
記録についても同じことを行います。マスターノードに、どこに、どの特定のブロックに、どの特定のマシンに書き込みを行うかを尋ね、そこに直接記録します。
また、信頼性を確保するために、各ユニットは複数のマシンの複数のコピーに保存されます。 これにより、たとえばクラスター内のマシンの10%に障害が発生した場合でも、おそらく何も失われない信頼性が確保されます。 つまり はい、いくつかのブロックが失われますが、これらのブロックは複数のコピーに格納されているため、再び読み書きできます
構成
たとえば、当社で使用されている典型的な構成。 たとえば、当社では大量のデータを保存するために70テラバイトであり、定期的に分析し、それを使って何かを行います。約40台のマシンで、各マシンは弱いサーバーです。業界を見ると、 16ギガバイトのRAMまたは8ギガバイト、テラバイトのドライブ、RAIDなし、単なる通常のドライブ。
いくつかのIntel Xeon、一般に、ある種の安価なサーバー。 また、このようなサーバーは40台あり、これにより、数百テラバイトなどのデータ量を保存できます。
Mapreduce
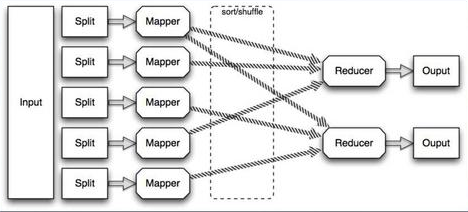
すべてのファイルが分散ファイルシステムに保存されたら、問題はそれらの処理方法です。 このため、GoogleはMapReduceと呼ばれるパラダイムを発明しました。 彼女はかなり奇妙に見えます。 これは、3つの操作でのデータ処理です。
最初の操作...、いくつかの入力データ、たとえばいくつかの入力レコードがあります。
Mapと呼ばれる最初の操作は、各入力レコードに対して「キー→値」のペアを提供します。 その後、内部では、これらのキーと値のペアがグループ化されます。各キーは、すべての入力レコードを処理するときに、いくつかの値を持つことができます。 これらはグループ化され、Reduceプロシージャに発行されます。Reduceプロシージャはキーを受け取り、それに応じて値のセットを受け取り、最終的に最終結果を返します。
したがって、入力レコードのセットがすでにあります。たとえば、これらはログファイルの行であり、出力レコードのセットを取得します。
関数プログラミングのような高度に特殊化されたもののように、これはすべて奇妙に見えますが、これがどのように広く実践に適用されるかはすぐにはわかりません。
例
実際、一般的な慣行では非常にうまく適用できます。
最も単純な例。 私たちがFacebookの会社であり、多くのデータがあるとします。...まあ、ログはFacebookのページを表示します。 そして、使用するブラウザを計算する必要があります。
MapReduceパラダイムを使用すると、これを行うのは非常に簡単です。
Map操作を定義します。これは、アクセスログの行によって、キーと値を定義します。ここで、キーはブラウザーであり、値は1のみです。
その後、Reduce操作を行う必要があります。Reduce操作は、ブラウザーのセットとそのセットに基づいて、単純に合計を行い、出力で各ブラウザーに対して受け取った合計を出力します。
このMapReduceタスクをクラスターで実行します。最初は非常に多くのログファイルがあり、最後にはブラウザーがあり、それに応じてインプレッションの数が少ない小さなファイルがあります。 この方法で統計を取得します。
平行度
MapReduceが良いのはなぜですか?
このようなプログラムは、Mapを設定し、Reduceを設定すると、非常によく並列します。
何らかの種類の入力があるとします。これは大きなファイルまたはファイルのセットです。このファイルは、たとえばクラスター内のマシンの数などによって、多数の小さな断片に分割できます。 したがって、Map関数を実行する各ピースで、これは並行して実行でき、クラスターですべて開始され、静かに計算され、各マップの結果が内部でソートされ、Reduceに送信されます。
同じこと、ある種のマップの結果、大量のデータがある場合、このデータを再び断片に分割し、再びクラスター上で、多くのマシン上で実行できます。
これにより、スケーラビリティが実現します。 2倍の速度でデータを処理する必要がある場合、2倍のマシンを追加するだけで、鉄は比較的安価になりました。 アーキテクチャを変更することなく、2倍の生産性が得られます。
Apache Hadoop
Apache Hadoop-それは何ですか? Googleがこれらの記事を公開した後、誰もが非常に便利なパラダイムであると判断しました。特に、Apache Hadoopプロジェクトが発生しました。 彼らは、分散ファイルシステムとMapReduceパラダイムに関するこれらの記事に書かれていることを、オープンソースのJavaプロジェクトとして実装することを決定しました。
2004年に始まり、人々がオープンな検索エンジンであるNutchを作成したいと考えていました。その後、2005年頃、Apache Hadoopは分散ファイルシステムとMapReduceパラダイムの実装として、別のプロジェクトとして際立っていました。 当初は非常に安定していない小さなプロジェクトでしたが、2006年のどこかでYahooがプロジェクトでHadoopを使用しようとし始め、2008〜2009年にYahooは検索、または検索ではなくインデックス作成を開始しました。 Apache Hadoopプラットフォーム、そして現在YahooはApache Hadoopプラットフォームを使用してインターネットのインデックスを作成しています。 インデックスは分散ファイルシステムに保存され、インデックス自体の構築は一連のMap-Reduceタスクとして実行されます。
はい、繰り返しますが、Hadoopは最近データソーティングコンペで優勝しました。一部の人々が1テラバイトのデータをより速くソートしようとすると、「1TBソートコンテスト」があります。 Yahooクラスターで実行されるApache Hadoopに基づいて構築されたシステムが定期的に勝ちます。
Hadoopモジュール
Hadoopは2つのモジュールで構成されています。 これは、HDFSおよびMapReduceと呼ばれる分散ファイルシステムパラダイムの実装です。 MapReduceフレームワークの実装。
Yahoo:Webグラフ
YahooがHadoopをどのように使用しているかの例をいくつか示します。 たとえば、Yahooはインターネット全体のグラフを作成する必要があります。 ページを頂点として使用します。あるページから別のページへのリンクがある場合、これはグラフのエッジになり、このエッジはリンクテキストでマークされます。
たとえば、Yahooがそれを行う方法。 これは、Map-Reduceシリーズのタスクからでもあります。 まず、Yahooはインデックス作成に関心のあるすべてのページをダウンロードし、再びHDFSに保存します。 そのようなグラフを作成するには、map-reduceタスクが起動されます。
それで、マップ、私たちはページを取得し、リンク先を見て、キー、ターゲットURL、つまり ページが参照する場所、値→SourceURL、つまり リンク先とリンクテキスト。
Reduceは、これらすべてのペアを取得するだけです。 キーを取得します。これはTargetURLと値のセット、つまり SourceURLとテキストのセットは何らかのフィルター処理を行います。明らかに、インデックスに登録したくないスパムリンクがいくつかあり、それらはすべてTargetURL、SourceURL、テキストの形式で返されます。

このようなテーブルは、インターネット全体のグラフです。
Last.fm
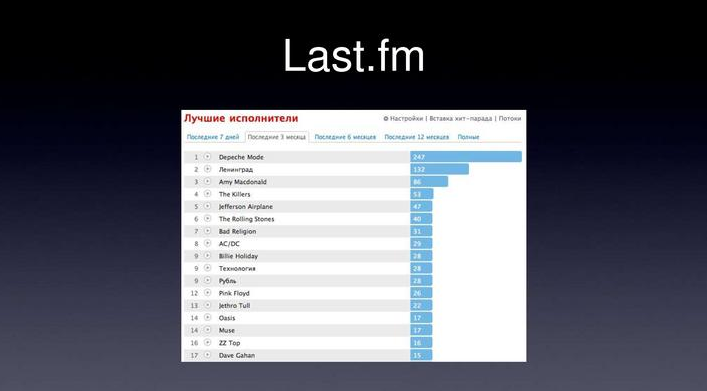
繰り返しますが、Last.fmでは、おそらく多くの人が使用しますが、使用しない人は少し説明します。 これはこのようなサービスです。iTunesまたはWinAmpにプラグインを配置し、リアルタイムでlast.fmに聞いたものを送信します。その後、Last.fmは2つのことを行います。たとえば、美しいチャートを作成します、つまり 過去7日間または3か月間、どのバンドを聴いたか、あなたの歌は何であるか、last.fmはある種の??? あなたが聞いた曲の統計に基づいたラジオ、彼らはあなたに他の何か、あなたにとって新しくて面白いもの、あなたが興味を持っていることになっているものをお勧めします。 誰かが気付いた場合、これらのチャートは、リアルタイムで更新されず、1日に1回、一般的に、まれに覚えていません。
実際、これらのチャートは、Apache Hadoopプラットフォームで再構築されています。 構成を聞くと、「そのような識別子を持つユーザーがそのようなグループの構成を聞いた」という行がログファイルに書き込まれます。 その後、Map-Reduceタスクは1日に1回起動されます。 彼女はどのように見えますか?
- 入力は、これらのリスニングのまさにログファイルです。
- マップは次のようになります-このログファイルとそのparsimから1行を取得し、キーとして「ユーザーとグループ」のペアを、値として-1を指定します。
- したがって、これはすべて「ユーザーとグループ」のペアの形で、ユニットの形の値でReduceになり、すべての最後に「ユーザーグループと再生回数」としてファイルに書き込まれます。
その後、ページにアクセスすると、このファイルが解析され、ユーザーに関連するレコードがあり、最後のスライドにそのようなチャートが描かれます。
SQL
実際、多数のSQLクエリは...として簡単に並列化でき、Map-Reduceタスクとして簡単に表現できます。 たとえば、標準SQL、多くの記述、多くはそれを使用します-フィールドのセット、f1、f2、sum、where、何らかの条件、およびグループ化。
つまり これは標準のSQLクエリであり、レポートや統計情報を作成する場所で多く使用されます。
そのため、このような要求はmap-reduceとして簡単に並列化されます。 テーブルの代わりに、データストレージとしてテキストファイルがあるとします。 SQLの代わりに、map-reduceがあります。 クエリ結果の代わりに、テキストファイルがあります。
実際、どのように機能するか。
マッププロセス。 入力として、ログファイルに行があり、出力としてこの行をキーとして解析します。この場合、グループ化する対象のフィールド、値として集約するフィールドを解析します。 aの量を考慮します。
Reduceは、実際にはこれらのフィールドをキーとして、値として、集計する一連のフィールド、つまり いくつかのA1、.... An、および単に合計を行います。
実際、これですべてです。このようなmap-reduceプロシージャをクラスターに設定し、このリクエストの結果を得ました。
SQL:原則
実際、多くのSQLクエリを並列化することができます...、map-reduceジョブの観点から表現できます。
GROUP BYがある場合、GROUP BYをMapプロセスのキーとして使用するフィールドを定義します。
WHEREは、Mapプロセスでフィルタリングしているだけです。
繰り返しますが、Reduceステージですべての金額、AVG、およびその他の集計関数を考慮します。
HAVING、JOINなどの条件は非常に簡単に実装できます。
SQL:パーティショニング
パーティショニングについて少し。 このようにデータを処理するとき、たとえば、同じlast.fmでこれらの統計を作成し、データをファイルに保存します。すべてのファイルでmap-reduceジョブを実行すると、長くて間違っています。
通常、データのパーティション分割は、たとえば日付ごとに使用されます。 つまり 1つのログファイルにすべてを保存するのではなく、時間または日ごとに分割します。 次に、MapReduceジョブのSQLクエリをマップするとき、最初に入力データのセットを...実際にはファイルごとに制限します。 最終日のデータに興味がある場合、最終日のデータのみを取得してから、map-reduce-jobsを実行するとします。
Apacheハイブ
実際、この原則は
Apache Hiveプロジェクトに実装されており、Hadoopに基づいて構築されたフレームワークです。
ユーザーの観点から見ると、どのように見えますか? SQLクエリを要求し、データの場所を特定します。その後、このフレームワークは、このSQLクエリをmap-reduceタスクの形式で、1つまたは全体のシーケンスの形式で表現し、それらを起動します。
つまり 入力データのセットを決定し、SQLクエリを設定し、何らかの種類のテーブルも取得しました。
アパッチ豚
2番目のフレームワークである
Apache Pigは同じであり、おおよそ、同じ問題を解決します。 コードを記述することなく、ユーザーフレンドリーなmap-reduceジョブの作成。
このETL言語で、必要なシーケンス、ロード元、データのフィルタリング方法、関心のある列を要求し、これらすべてがmap-reduceジョブに変換されます。

適用分野
厳密に言えば、スコープ、このHadoopなどすべてのものです。
Hadoopは、統計モデルの構築、および一般的なデータ分析に非常によく使用されます。
多くのログファイルがある場合、何らかの相関関係、ユーザーがどのように動作するか、Hadoopの助けを借りてそのようなタスクがそれぞれ非常によく解決されることを見つけたいと思います。レポートは再び同じLast.fmです。 大量のデータがあり、何らかのレポートを作成する必要がある場合、リアルタイムは必要ありません。1日1回、または数時間以内にすべてを更新する準備も整っています。
長所
このアプローチ、このプラットフォームの利点。 非常に優れたスムーズなスケーラビリティ。 つまり 2倍のデータを処理する必要がある場合、または2倍のデータを保存する必要がある場合は、クラスターに2倍のマシンを追加するだけです。 つまり 正確に2回ではなく、ほぼ2回です。
ゼロコストのソフトウェア。 そこには大量のデータがあり、OracleにアクセスしてOracleのクラスターを数百万ドルで購入できます。多くのコンサルタントがそうであるように、これはすべての企業、特にスタートアップには適していません。 ある種の新しいソーシャルネットワークはわかりませんが、数百万をOracleに費やす余裕がないだけです。 Hadoopを購入する余裕があり、クラスターを使用して、データを分析および保存するためのシステムとしてオープンソースのHadoopを使用できます。
Hadoopは、研究タスクにも便利です。 たとえば、あなたは研究者であり、ユーザーの行動とFacebook上の何か、ソーシャルネットワーク上の他の場所、多くのファイルがあり、hadoopはAmazonのオンデマンドサービスとして利用可能です。
つまり 自宅で何かを書いて、ローカルでデバッグして、「OK」と言います。今、100台のマシンのクラスターが2時間必要です。すぐにAmazonが100台のマシンのクラスターを提示します。になります。
Amazonで1時間に100台の車は比較的安く、自宅にクラスターを保管するよりも安くなっています。 研究には、これは十分に便利です。週に一度これをすべて必要とするという意味で、クラスターを自分で保存する必要はなく、Amazonに注文できます。
聴衆から:数字の順序はいくらですか?1時間...まあ、それは約100ドルです。 正直なところ、Amazonの価格は覚えていませんが、かなり安く、手頃な価格です。
聴衆から:1時間あたり50セント...はい。ただし、Hadoopにはより多くのインスタンスが必要であり、おそらくより大きなクラスターが必要です。 これはそのような注文であり、大きなタスクであれば、これは1時間ではなく10時間ですが、それでも数百ドル、つまり あまり大きくないものについて
短所
そして、Hadoopの欠陥は何ですか?
まず、これはかなり高いサポートコストです。 多くのマシンからHadoopクラスターを使用している場合、Hadoopアーキテクチャ、その仕組み、およびこれらすべてをサポートするスマートシステム管理者を見つける必要があります。 つまり それは本当に簡単ではありません、本当に時間がかかります。
これは、産業用の高価なストレージ施設とは異なり、新しいデータ処理プロセスのコストが非常に高くなります。 つまり 何らかのOracleまたはこのスタイルの類似品を購入する場合、原則として、SQLクエリのみを記述して結果を得るビジネスアナリストを雇うだけで十分です。 この場合、これはHadoopでは機能しません。ビジネスの部分を考え出す人々、必要なデータの種類、およびこれらのmap-reduceジョブを作成するJava開発者のチームが必要になります。
チームはそれほど大きくはありませんが、それでもなお費用がかかり、開発者は非常に高価です。
繰り返しますが、問題はリアルタイムにあります。 Hadoopはリアルタイムシステムではありません。 一部のデータを受信したい場合、ユーザーがサイトにアクセスしたときにmap-reduceジョブを実行できるようにデータが機能しません。 バックグラウンドで少なくとも1時間に1回データを更新し、ユーザーが既に計算されたデータを表示するようにする必要があります。
リアルタイム?
real-timでは、問題は比較的解決可能です。 たとえば、当社での決定方法。 保有している全データにリアルタイムでアクセスする必要はありません。map-reduceジョブを実行し、非常に価値がありながら妥当なサイズの結果を取得し、SQLデータベースに保存します。ただし、メモリ内のMemCacheでは、このデータが大量にある場合は機能しません。
だから今...まだ時間が残っていますか?
残り10分なので、列指向のデータベースについて説明します。これは、リアルタイムアクセスが必要な大量のデータを保存する方法でもあります。
列指向データベース
どのように機能しますか? SQLの一般的な問題は何ですか? SQLでは、MySQLでは、たとえば数テラバイトでボリュームを保存することはできません。そのようなテーブルは単に機能せず、データを受信できません。
SQLに関するその他の問題、たとえばALTER TABLEなどのスキーマを変更する場合、大きなテーブルにいくつかの列を追加するのは長くて問題があります。 それは非常に問題が多く、必要ないとき、構造化データを保存する必要がないとき、制限を削除するとき... SQL機能を構造化データリポジトリとして使用しないで、リレーショナルを使用しないで、わずかに効率的な構造でデータを保存できます。素晴らしいパフォーマンスを得ています。
これは、列指向データベースと呼ばれるわずかに異なるアプローチです。
ビッグテーブル
これはGoogleによって導入されたもので、今でも使用されています。私の記憶が役立った場合、これは2004年に公開された記事「BigTable」です。
実際、BigTableとは何ですか?
いくつかの原則に基づいています。
テーブルのフィールドによるインデックス付けから、リレーショナルを拒否する最初の原則は、検索するフィールドが1つだけで、rowkeyと呼ばれるもので、アナログはテーブルの主キーです。
他のすべてのフィールドにインデックスを付けたり、検索したり、構造化したりすることはありません。2番目の原則は、テーブルが広いことです。 どんなデータ型でも、いつでも列を追加できます。それは安くて良いはずです。
BigTableの例
これを使用する場合の例を挙げましょう。 サイトのユーザーに関するデータを保存したい。 Googleの場合、サイトにアクセスして、いくつかのアクションを実行しました。いくつかのリクエストを行い、何かを見て、いくつかの広告を見て、これは匿名ユーザーです。 この問題はどのように解決されますか? 多くの人々は、ユーザーに関する情報、彼がしたこと、彼が見たページ、彼が見た広告、彼がクリックしたものにクッキーに関する情報を保存します。 このアプローチには大きな問題があります-Cookieのサイズは非常に限られているため、先月のユーザーアクションの履歴を書き留めることはできません。機能しません。場所がありません。 この問題はBigTableでどのように解決できますか?
BigTableのようなストアがある場合、Cookieにパラメーター(一意のユーザーID)のみを保存できます。 BigTableでは、UserUIDをテーブルのメインキーとして保存し、訪問履歴、広告のクリック、リンクのクリックなど、興味のある多くのフィールドを保存します。
それはどうですか? 残りのフィールドで何かを探す必要がないことは明らかです。 適切な広告を表示するためにユーザーに関する情報を知りたい場合は、UserIDで情報を検索するだけで済みます。
また、ビジネスは変化する可能性があるため、多くの異なるフィールドを追加でき、安価で優れていることも良いことです。 実際には、rowkeyのようなBigTable、userID、およびテーブルのような他のすべてのデータを使用すると非常に便利です。
BigTable:デザイン
どのように機能しますか? BigTableのようなアプローチであり、多数のコンピューターに非常にうまく対応します。 つまり 前の例で引用したように、行キーがあり、ユーザーIDなどの行キーのみで検索する場合、このユーザーですべてのデータを並べ替え、このデータの異なる範囲を異なるサーバーに保存できます。 つまり リクエストはどのように「このユーザーIDに関するすべての情報を取得しますか?」 マスターノードは、どの範囲がどのサーバーに保存されているかに関する情報を保存します。まず、興味のあるデータが保存されているマスターノードで、次にこのノードに直接アクセスして、そこからデータを読み取ります。
繰り返しますが、2倍のデータ→2倍のマシンを購入し、ストレージをわずかに再構築しましたが、再構築はしませんでしたが、アクセスを可能にするシステム、つまり、2倍のデータを保存できます。
Hbase
Apache Hadoopの一部として開発されているこのBigTableパラダイムは、
HBaseと呼ばれるプロジェクトを実装しています。
Hadoop Distributed File System, , Hadoop-, , - map-reduce job, - , , .. Reduce . Reduce , , HBase, , Hadoop, .
HBase:
, . , , — 16 8 , , 10 RPM, - Intel Xeon, .
, , 3-5 … 300 , - 18 , —— , - 10 . - MySQL .
HBase .
HBase:
HBase, , BigTable ?
, .. . , , join-, WHERE, , , , .
,
HBase , , , , , , , .
Hadoop:
, , map-reduce , research, , , HBase BigTable…, , HBase-, , , , - , , , , , , , .
HBase , , , , . , , .… … ( ).
, — , (. )
.