すべての人に挨拶!
このブログはとても面白いです! 今日は、CUBRID 8.4.0の最新バージョンの非常に興味深い機能について説明します。通常はマニュアルにはないものです。 クエリとインデックスを最適化するための非常に重要な推奨事項、テスト結果、および実際のWebサービスでの使用例を示します。
前に、新バージョンの変更、2倍高速なデータベースエンジン、MySQL構文のサポートの拡張など
について表面的に
話しました。 今日は、CUBRIDのパフォーマンスを2倍にする方法に焦点を当てて、それらとその他のことについて詳しく説明します。
CUBRIDのパフォーマンスに影響を与えた主な分野は次のとおりです。
- データベースボリュームのサイズを縮小する
- Windowsバージョンでの並列コンピューティングの改善
- インデックスの最適化
- LIMITでの条件処理の最適化
- GROUP BYでの条件処理の最適化
データベースボリュームのサイズを縮小する
CUBRID 8.4.0では、データベースボリュームのサイズが218%減少しました。 この理由は、インデックスを格納するための構造が完全に変更されたためであり、同時にシステム全体のパフォーマンスに影響を与えました。
次の図では、以前のバージョン8.3.1と新しい8.4.0のデータベースボリュームのサイズの比較を見ることができます。 この場合、両方のデータベースは、64,000,000のレコードを主キーとともに保存しました。 データはギガバイト単位です。

Windowsバージョンでの並列コンピューティングの改善
CUBRID 8.4.0では、高度なミューテックスを使用して、Windowsプラットフォームバージョンの並列コンピューティングが改善されました。 次のグラフは、以前のバージョンと新しいバージョンのパフォーマンスの比較結果を示しています。
インデックスの最適化
ここでは、すべてを詳細に説明します。
CUBRID 8.4.0は、2倍の速度のデータベースエンジンで以前のバージョンと異なります。 次のようないくつかの非常に重要なインデックス最適化を実装しました。
- カバリングインデックス
- LIMITでの条件処理の最適化
-キー制限
-マルチレンジスキャン(マルチレンジ)
- GROUP BYでの条件処理の最適化
- インデックススキャン降順
- LIKEステートメントでのインデックススキャンのサポート
次に、CUBRID 8.4.0でインデックス構造がどのように編成されているかを見てみましょう。 CUBRIDでは、
インデックスは B +ツリー [Wikipediaの記事へのリンク]として実装され、インデックスキーの値はツリーリーフに格納されます。
実際の例として、次のテーブル構造(STRING = VARCHAR(1,073,741,823))を確認することをお勧めします。
CREATE TABLE tbl (a INT, b STRING, c BIGINT);データを入力してください:
INSERT INTO tbl VALUES (1, 'AAA, 123), (2, 'AAA', 12), …;そして、複数列のインデックスを作成します。 ところで、データを入力した後にインデックスを作成していることに注意してください。 これは、初期段階でデータを入力する場合、またはデータを復元する場合に推奨される方法です。 このようにして、各入力でのインデックス作成の時間と費用を回避できます。 ビッグデータの入力に関する推奨事項については、
こちらをご覧ください 。
CREATE INDEX idx ON tbl (a, b);次の図は、このインデックスの構造を示しています。
リーフには 、ディスク上のヒープファイルにあるデータ自体へのポインター(
OID )があります。
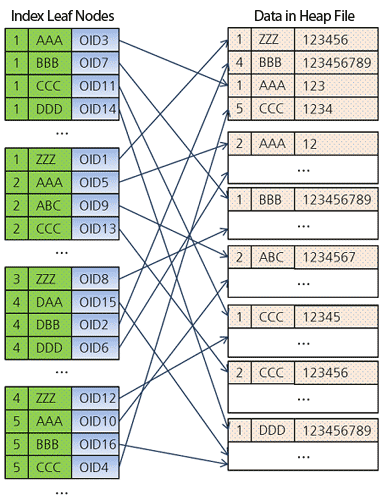
- したがって、インデックスキーの値( aおよびb )は増加順にソートされます(デフォルト)。
- 各シートには、ディスクヒープにある対応するデータ(テーブル内のエントリ)へのポインター(矢印で示されています)があります。
- 図に示すように、ヒープ内のデータはランダムに配置されます。
インデックススキャン
次に、インデックス検索が通常どのように行われるかを見てみましょう。 上記で作成したテーブルを指定して、次のクエリを実行します。
SELECT * FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K'
AND c > 10000
ORDER BY b;- 最初に、CUBRIDはa> 1およびa <5のすべての葉を見つけます。
- 次に、この結果の中から、 b <'K'である葉を選択します。
- 列cにはインデックスが付けられていないため、値を取得するには、ディスク上のヒープに移動する必要があります。
- インデックスツリーの各シートには、特定のテーブルレコードのデータがディスク上のどこに保存されているかを正確に示すOID(オブジェクト識別子)値が含まれています。
- これらのOIDに基づいて、サーバーはヒープに移動して列cの値を取得します。
- CUBRIDは、 c> 10000のすべてのレコードを検索します。
- 結果として、これらのすべてのレコードは、クエリでの必要に応じて、列bでソートされます。
- 次に、結果がクライアントに送信されます。
カバリングインデックス
次に、カバリングインデックスがCUBRIDのパフォーマンスを大幅に向上させる方法を見てみましょう。 つまり、カバリングインデックスを使用すると、ディスク上のヒープにアクセスすることなくクエリ結果を取得できるため、I / O操作の数が減り、これが費やされる時間の面で最も高価な操作になります。
ただし、Cover Indexの魔法は
、クエリで値が要求され
たすべての列が同じ複合インデックスにある場合にのみ適用でき
ます 。 つまり、それらの値はインデックスツリーの同じリーフにある必要があります。 たとえば、次のクエリを見てください。
SELECT a, b FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K'
ORDER BY b;- ご覧のとおり、このクエリで使用されるすべての列は、最初に作成した同じ複数列インデックスにあります。
- WHERE句では、同じマルチカラムインデックスにあるベルのみが指定されます。
- また、同じ複数列インデックスにある列のみが、ORDER BY演算子の条件で指定されます。
したがって、このクエリを実行すると:
- 通常のインデックススキャンプロセスの一部として、CUBRIDは最初にa> 1およびa <5のインデックスツリー内のすべてのリーフを検出します。
- 次に、この結果の中から、 b <'K'である葉を選択します。
- 列aとbの値はインデックススキャン中に既に取得されているため、これらの値を取得するためにディスク上のヒープを調べる必要はありません。 したがって、2番目のステップの後、サーバーはすぐに結果を列bでソートし始めます。
- 次に、値を返します。

次に、カバリングインデックスによってサーバーのパフォーマンスがどのように改善されるかを見てみましょう。 上記の同じ例では、非常に大量のデータがデータベースに保存されていると想定しています。
Q1。 以下は、単一の複合インデックスで指定された列を使用するクエリです。
SELECT a, b FROM tbl WHERE a BETWEEN ? AND ?Q2。 そして、列
aにインデックス
が付けられ、列
cにはインデックス
が付けられていないクエリ。
SELECT a, c FROM tbl WHERE a BETWEEN ? AND ?次のグラフは、クエリがカバリングインデックスを使用している場合にクエリを処理する速度を示しています。

LIMITでの条件処理の最適化
キー制限
CUBRID 8.4.0には、LIMITステートメントの非常に「スマートな」アナライザーがあります。 このアナライザーは非常に最適化されており、LIMITオペレーターの条件で必要な数のレコードのみを処理でき、サーバーはすぐに結果を返します。 たとえば、次のクエリを見てください。
SELECT * FROM tbl
WHERE a = 2
AND b < 'K'
ORDER BY b
LIMIT 3;- CUBRIDは、最初にインデックスツリーの最初のシートを見つけます。ここで、a = 2です。
- インデックスにはすでにソートされている列bの値が含まれているため、結果を個別にソートする必要はありません。
- サーバーは、インデックスの最初の3つのキーのみを渡し、3つ以上の結果を返す必要がないため、これで停止します。
- その後、サーバーはすでに他のすべての列の値を取得するためにヒープにヒープします。 したがって、ディスク上で影響を受けるのは3つのエントリのみです。

マルチレンジスキャン
マルチレンジスキャンの最適化は、新しいCUBRID 8.4.0のもう1つの大きな改善点です。 ユーザーが特定の範囲(たとえば、
a> 0 AND a <5 )にあるデータを入力すると、ほとんどのDBMSでタスクは非常に簡単になります。 ただし、散在する範囲が条件に含まれる場合、たとえば
a> 0 AND a <5 AND a = 7 AND a> 10 AND a <15など 、すべてがはるかに複雑になります。 ここで、CUBRIDは異なります。 新しい最適化機能の
インプレースソート (オンザフライでのソート)を使用すると、2つの問題を一度に解決できます。
- キー制限
- その場でレコードを並べ替えるだけでなく
たとえば、次のクエリを考えます。
SELECT * FROM tbl
WHERE a IN (2, 4, 5)
AND b < 'K'
ORDER BY b
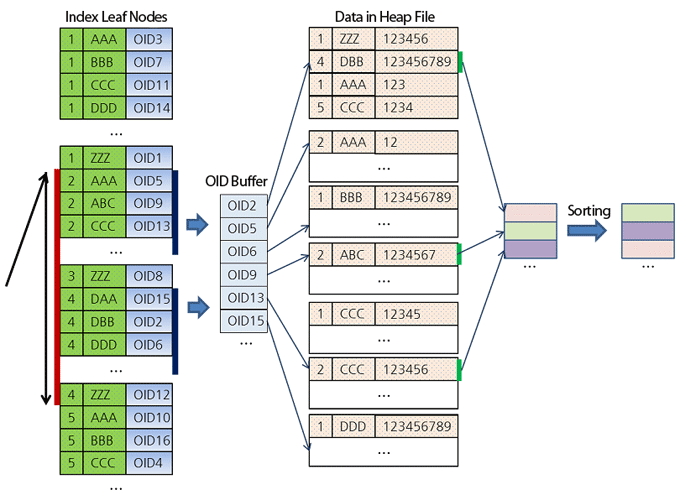
LIMIT 3;- インデックスツリー内のすべてのキーがソートされているため、サーバーは最初のシートからスキャンを開始します(a = 2)(下図を参照)。
- 列bでソートされたテーブルの3行のみを取得する必要があるため、サーバーは条件a IN(2、4、5)AND b <'K'を満たす結果をその場でソートします。
1.最初に、サーバーはレコード(2、AAA)を検出し、最初の結果が得られます。
2.次に、レコード(2、ABC)を見つけ、2番目の結果を返します。
3.次に、3番目の結果を与えるエントリ(2、CCC)を見つけます。
4.サーバーはすでに3つのレコードを検出しているため、列bの値がすでに検出されている値よりも小さくなるレコードを検索するために、次の範囲にジャンプします。
- 最初に、サーバーはレコード(4、DAA)を見つけます。これは 、既に見つかったレコードの列bの最後の値よりも大きくなります。 したがって、この範囲はすぐに消え、サーバーは次の範囲にジャンプします。
- ABCおよびCCCよりも小さいレコード(5、AAA)を検索します。 したがって、最後のレコードを削除し、このレコードを適切な場所に挿入します。
- 次のレコード(5、BBB)は、予備結果の最後のレコードよりもすでに大きくなっています。 したがって、この範囲のスキャンは完了します。 スキャンに必要な他の範囲がないため、検索全体も終了します。
- すべての結果は既にソートされているため、ヒープを調べて残りの列の値を取得するだけです。
オンザフライソートでこのマルチレンジスキャンオプションを使用すると、CUBRIDは大量のデータ間で非常に高速な検索を実行できます。

試験結果
韓国では、Twitterに類似した非常に人気のあるMe2Day Webサービスがあります。 このサービスの実際のデータに基づいて、次のテスト結果が得られました。
Twitterと同様に、Me2Dayにはすべての「ツイート」が保存される
投稿テーブルがあります。 ユーザーとその関係の統計は、次のことを示しています。
- ユーザーの50%が1〜50人のユーザーをフォローしています。
- ユーザーの40%は51-2000ユーザーをフォローしています。
- ユーザーの10%は2001人以上のユーザーをフォローしています。
このテーブル用に次のインデックスが作成されました。
INDEX (author_id, registered DESC)最も重要なリクエストは、TwitterとMe2Dayの両方で最も頻繁にリクエストされ、「フォローしている
すべてのユーザーの最新のランダムな投稿を20個表示する」
ことです 。 以下はまさにこのリクエストです。
SELECT * FROM posts
WHERE author_id IN (?, ?, ..., ?) AND registered < :from ORDER BY reg_date DESC
LIMIT 20;テストは10分間実行され、その間、この要求は継続的に処理されました。 以下は、
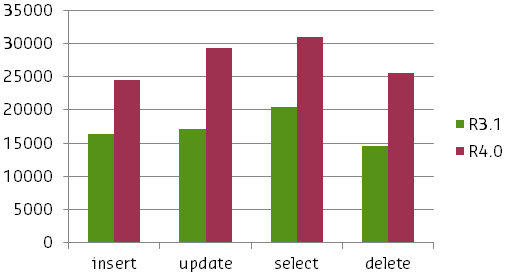
MySQLの
INON演算子よりも平均で4倍速い
MySQLの
UNION演算子
とCUBRIDのIN演算子を比較するテスト結果のグラフです。 1つは、以前のバージョンと比較して、マルチバンドスキャンを実装した後、CUBRID 8.4.0のパフォーマンスがどれだけ向上したかを確認できます。

このような好結果が出た後、サービスの毎日の運用を担当するMySQL Me2DayサーバーをCUBRIDサーバーに置き換えました。 次回、このテストについてさらに詳しく説明します。 それまでの間、
メインサイトで英語
でそれについて読むこともでき
ます 。
GROUP BYでの条件処理の最適化
CUBRID 8.4.0の新しいバージョンは、ORDER BYおよびGROUP BYステートメントを含むクエリの処理を大幅に高速化しました。 複数列インデックスに含まれる列がORDER BYおよびGROUP BY条件で使用される場合、値は既にインデックスツリーでソートされているため、値をソートする必要はありません。 このような最適化により、リクエスト全体の処理パフォーマンスが大幅に向上します。 次のリクエストを見ることができます。
SELECT COUNT(*) FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K' AND c > 10000
GROUP BY a;- 通常のインデックススキャンプロセスの一部として、CUBRIDは最初にa> 1およびa <5のインデックスツリー内のすべてのリーフを検出します。
- サーバーはOID値を使用してヒープに移動し、列cの値を取得します。
- CUBRIDは、 c> 10000のすべてのレコードを検索します。
- 必要な値はすべて既にソートされているため、GROUP BY操作は事前のソートなしですぐに実行されます。
- その後、サーバーは結果を返します。

開発者の生産性の向上
システム全体のパフォーマンスの向上に加えて、CUBRID 8.4.0の新しいバージョンは、MySQL DBMSのSQL構文の90%以上をサポートします。 また、暗黙的な型変換のサポートを強化して、開発者がアプリケーションの機能の改善に集中できるようにしましたが、CUBRIDはすべての内部変換を行います。 以下に、新しい構文の例をいくつか示します。
- 暗黙的な型変換
CREATE TABLE x (a INT);
INSERT INTO x VALUES ('1');
- クエリを表示
SHOW TABLES; SHOW COLUMNS; SHOW INDEX; …
- ALTER TABLE ...列の変更/変更...
CREATE TABLE t1 (a INTEGER);
ALTER TABLE t1 CHANGE ab DOUBLE;
ALTER TABLE t2 MODIFY col1 BIGINT DEFAULT 1;
- UPDATE ... ORDER BY
UPDATE t
SET i = i + 1
WHERE 1 = 1
ORDER BY i
LIMIT 10;
- 存在する場合のドロップテーブル...
DROP TABLE IF EXISTS history;
合計で、新しいバージョンには23個の新しいDATE / TIME構文があり、5個は文字列に関連付けられ、5個の新しい集約関数があります。 新しい構文の全リストは、
ブログオフにあります。 サイト。
高可用性の信頼性の向上
次のキーロックの改善
また、バージョンCUBRID 8.4.0では、停滞の発生を最小限に抑えるためにロックメカニズムが大幅に改善されました。 たとえば、高可用性環境では、同じテーブルに同時にデータを入力するトランザクション間で停滞は発生しません。
おわりに
おそらく既に理解しているように、CUBRID 8.4.0の新しいバージョンは、パフォーマンス、信頼性、開発の容易さにおいて、以前のすべてのバージョンを明らかに上回っています。 CUBRIDは、Webアプリケーションおよびサービスで使用するために開発されているため、すべての主要な開発、改善、最適化は、Webアプリケーションでよく使用される機能の分野で実行されます(たとえば、INステートメント、LIMIT制限、グループ化と並べ替え、高可用性など)、卓越性その性能は、比較テストの結果によって証明されています。
特定の質問がある場合は、コメントを記入してください。 私はすべてを明確にすることを非常に嬉しく思います!