クラスターのノードは、物理接続に大きく依存しています。 実践が示すように、ほとんどのフェイルオーバーリソース移行ケースは、ネットワーク接続の障害が原因で発生します。 したがって、ノード間の接続方法とリソース割り当ての構成方法に大きく依存します。
例として、2つのノードで構成されるクラスターを考えます。 一方のノードはアクティブ状態になり、もう一方のノードはホットスペア状態になります。 このクラスターは、内部プライベートネットワークを提供し、MysqlサーバーとMysql VIPのクラスターリソースを含みます。 2つのMysqlノードで、サーバーはマスターマスタレプリケーションで起動されます。 ただし、すべての作業は、仮想IPアドレスを介して1つのインスタンスのみで実行されます。 このスキームにより、最速のフェイルオーバーを実現できます。 この特定の構成、その長所と短所の選択は省略します。ネットワークリンクがドロップした場合のこれらのリソースの可用性に関心があります。

図 1クラスター図
クラスターを設計するときに注意すべき主なことは、クラスターのノード間のネットワーク接続の冗長性です。 つまり、ノード間に少なくとも2つの相互接続が必要です。 これらは、1つのインターフェースでボンディングを使用して結合することも、ハートビートまたはコロシンの構成で2つの異なるインターフェースを使用することもできます。 新しいクラスターを設計するときは、ハートビートの開発がペースメーカーとコロシンクに徐々に減っているだけでなく、複数のインターフェイスを操作するためのより柔軟な設定があり、パラレルまたは「アクティブおよびスタンバイ」モードで使用できるため、コロシンクを使用することをお勧めします」
個別のネットワークインターフェイスのバックアップまたは割り当てのルールに従わない場合、スプリットブレイン状態が発生する可能性があります。 原則として、これは前兆ではありません。 また、異なるネットワークカードを使用していることを確認してください。そうしないと、ハードウェア障害であまり役に立ちません。
なぜなら クラスターは2つのノードで構成されています。その後、クォーラムに問題があります。 より正確には、その完全な不在は、ノード間の冗長接続の必要性を示唆しています。
これで十分な理論です。実践に移ります。
クォーラムがない場合のノードの動作を公開します。
crm configureプロパティno-quorum-policy = "ignore"
また、2つのノードのクラスターの場合、クラスターを非対称にすることをお勧めします。 これにより、より正確に設定し、奇妙な動作をキャッチできます。
crm設定プロパティsymmetric-cluster = "false"
非対称クラスターは、各ノードで起動のコストを明示的に指定しない限り、リソースを開始しません。 たとえば、これは、first.localノードの特定のP_RESOURCEリソースの値を100に、second.localノードの値を10に設定する方法です。
場所L_RESOURCE_01 P_RESOURCE 100:first.local
ロケーションL_RESOURCE_02 P_RESOURCE 10:second.local
この構成は、リソースがfirst.localノードで開始されることを示しています。 このノードの総コストは、second.localノードよりも大きいことが判明しました。
ノードの初期設定を意図的に省略し、結合を構成し(オプション)、pacemakerとcorosyncをインストールし、Master-Masterレプリケーションを構成します。 これはインターネット上で十分であり、簡単に見つけることができます。 次に、ネットワークの詳細に基づいてクラスターリソースを適切に構成する方法を示します。
プライベートネットワーク192.168.56.0/24、Mysql VIP-192.168.56.133、およびネットワーク接続の妥当性を評価するために使用するネットワーク内の2つのノード192.168.56.1と192.168.56.100があることに同意しましょう。
小さな余談:Mysqlがペースメーカーと連携して正しく動作するためには、自動起動を無効にする必要があります:
chkconfig mysql --list
mysql 0:オフ1:オフ2:オフ3:オフ4:オフ5:オフ6:オフ
なぜなら Musqlサーバーはプライベートネットワークでのみ使用されます-アクティブノードでのプライベート接続の失敗は、接続が存在する別のノードへのリソースの移行につながるはずです。 この動作を実現します。
プライベートネットワーク上のホストのステータスを確認する必要があります。 このために、pingクラスターリソースを使用します。 現在、ネットワークの状態を監視できる次のリソースがあります。
ocf:heartbeat:pingd(非推奨)
ocf:pacemaker:pingd(非推奨)
ocf:ペースメーカー:ping
そのうち2つは廃止されました。
これらのリソースに基づいて、ノード上のリソースの割り当てを制御できます。 これは、locationパラメーターを使用して行われます。
たとえば、最初に、図に示すペースメーカークラスターの構成について説明します(図1)。
crm configure
プリミティブP_MYSQL lsb:mysql
プリミティブP_MYSQL_IP ocf:heartbeat:IPaddr2 params \
ip = "192.168.56.133" nic = "eth0"
clone CL_MYSQL P_MYSQL clone-max = "2" clone-node-max = "1" \
globally-unique = "false"
この構成は、2つのMysqlマスター(クローン)を持つ2つのノードのクラスターを記述しています。 データベースの操作は、VIPアドレスを介して実行されます。
非対称クラスターの場合、場所の値を明示的に設定する必要があります。
場所L_MYSQL_01 CL_MYSQL 100:first.local
場所L_MYSQL_02 CL_MYSQL 100:second.local
このレコードは、「クローン」タイプのリソースをクラスターの2つのノードで実行する必要があることを示しています。
VIPでも同じです:
ロケーションL_MYSQL_IP_01 P_MYSQL_IP 100:first.local
場所L_MYSQL_IP_02 P_MYSQL_IP 10:second.local
ここでは、first.localノードでVIPを実行することを好みます
そして、セットアップを終了します。
コミットする
フェイルオーバーの仕組みを確認すると、VIPを起動するとfirst.localが落ちたときに起動します(kill -9 corosync)-second.localに移動します。 ただし、first.localノードが返されると、返されます。 これは、first.localのスコアがsecon.local(100> 10)よりも大きいためです。 不要なダウンタイムにつながる可能性のある、負荷の高いクラスターでこのような交差を防ぐには、resource-stickinessパラメーターを設定する必要があります。
crm設定プロパティrsc_defaults resource-stickiness = "110"
同じ操作を繰り返すと、スコア値は110 + 10 = 120対100になり、移動できなくなります。
クラスタは機能し、ハードウェア/電源に問題がある場合に自動的にバックアップノードに切り替えることができます。
次に、内部ネットワークの監視を設定しましょう。 192.168.56.1と192.168.56.100に対してpingを実行します。
crm configure
プリミティブP_INTRANET ocf:ペースメーカー:ping \
params host_list = "192.168.56.1 192.168.56.100" \
乗数= "111"名前= "ping_intranet" \
opモニター間隔= "5秒"タイムアウト= "20秒"
clone CL_INTRANET P_INTRANET globally-unique = "false"
場所L_INTRANET_01 CL_INTRANET 100:first.local
場所L_INTRANET_02 CL_INTRANET 100:second.local
コミットする
この構成では、2つのホストにpingを実行します。 各ホストの評価は111ポイントです。 各ノードの合計値は、ping_intranet変数に保存されます。 これらの値は、リソースの場所を決定する際に使用でき、使用する必要があります。 次に、VIPを示して、これらのポイントを使用して自分がどこにいるかを決定します。
crm configure
場所L_MYSQL_IP_PING_INTRANET P_MYSQL_IPルール\
ping_intranet:定義済みイントラネット
コミットする
これらの余分なポイントは、私たちが与えたおならで要約されます。 そして、合計金額に基づいて、リソースの位置が決定されます。
スコア値を示すクラスターステータスの監視は、ptestとcrm_monの2つのユーティリティによって実行されます。
- ptest -sL-各ノードの現在の割り当て値を表示します。
- crm_mon -A-各ノードのping_intranet変数のステータスを表示します。
合計すると、さまざまな状況に対して次の計算が行われます。
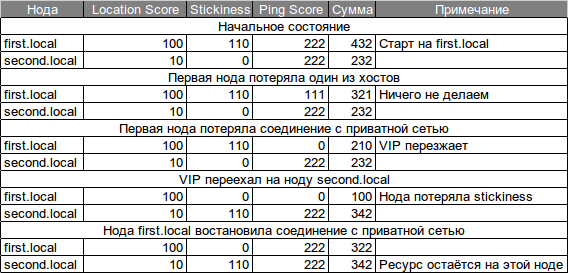
クラスターを元の位置に転送するには、リソースをfirst.localノードに転送する必要があります。
crmリソースの移動P_MYSQL_IP first.local
その後、リソースは1,000,000ポイント(これはペースメーカーのINF)を持つ場所を受け取り、first.localに移動します。 このリソースの移動を続行することは非常に重要です。これにより、ロケートインポイントが所定の位置に戻されますが、リソースの場所は変更されません 彼はすでにより多くのポイントを持っています(初期状況を参照):
crmリソースの移動P_MYSQL_IP
場所とpingで他にできること
pingリソースが実行されているかどうか、およびその値を確認できます。
ロケーションL_RESOURCE P_RESOURCEルール-inf:not_defined ping_intranetまたはping_intranet lte 0
この場所は、pingが0以下(lte-less than or equal)またはpingリソースが実行されていないノードにP_RESOURCEリソースを配置することを禁止します。
このルールをノードの名前と組み合わせることもできます。
ロケーションL_RESOURCE P_RESOURCEルール-inf:#host eq first.localおよびping_intranet lte 0
first.localノードでping = <0の場合、このリソースはここに存在できないことを示します。