
かつて、友人が論文の支援を求め、Kohonenの自己組織化マップを使用して画像を復元することについて話して
いる記事へ
のリンクを提供しまし
た 。 記事を読んだ後、最初はこれはなんらかのナンセンスであり、ニューラルネットワークは回復に横向きではないと判断しました。 しかし、私は少し間違えました、この方法は非常に魅力的であることがわかりました、そして、私がそれをしたとき、私は甘やかされることができませんでした。
どのように機能しますか?
Kohonenマップは、ニューロンで構成される2次元グリッドNXxNYです。 グリッド内の各ニューロンはSxSの正方形で表されます。この正方形は重みベクトルと呼ばれ、その値は対応するピクセルの色に等しくなります。
トレーニングのために、SxSイメージフラグメントがネットワークに供給された後、ネットワークはこのフラグメントに最も類似するニューロン、いわゆるBMU(ベストマッチングユニット)を検索し、供給されたフラグメントにさらに似るように重み係数を調整します。 そして、彼は隣人を訓練しますが、強度は低くなります。 ニューロンがBMUから遠いほど、送信されたフラグメントによるニューロンへの寄与は少なくなります。 そのため、各フラグメントのBMUの偏差が特定の最小値に達するまで、ネットワークがトレーニングされます。
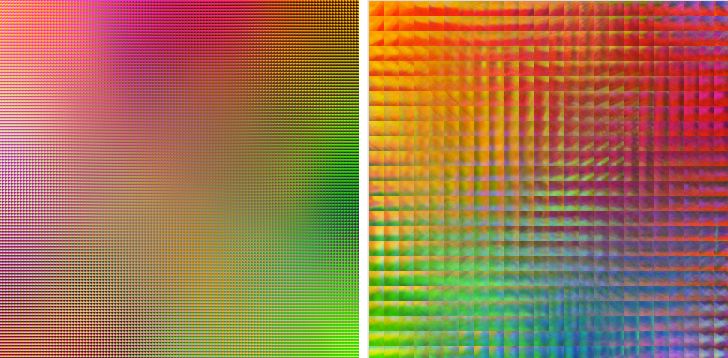
最初の写真は3x3ニューロンの120x120ネットワークを示し、2番目の写真は15x15ニューロンの24x24ネットワークを示しています。 美人!
復元は同様の方法で行われ、破損した画像のSxSフラグメントが取得され、破損していないピクセルからBMUが検索されます。その後、破損したピクセルがニューロンの重みベクトルの対応する値に置き換えられます。
ニューラルネットワークはどのように写真を「見る」のでしょうか?
ニューラルネットワークがどのように写真を「見る」かを見るために、次の方法を思いつきました。 訓練されたニューラルネットワークを使用し、画像内の各ピクセルに対してSxSフラグメントを作成し、それをニューラルネットワークにフィードし、そこから中心ピクセルの色を抽出し、同じ色で新しい画像にこの色を書き込みます。 結果の画像は、特定のニューラルネットワークの画像回復の可能性を反映しています。 実験のために私はこの写真を使用しました

この方法のおかげで、私はいくつかの興味深い特性を特定しました。
- サイズSが大きいほど、画像は鮮明になりません。
図は、3x3および15x15ニューロンで作成された画像を示しています。 ご覧のとおり、一般的に3x3は元のものとそれほど違いはありません。 15x15では、すでにぼやけています。


- ネットワーク内のニューロンが多いほど、カラーパレットが大きくなります。
最初の図では、4x4グリッドが使用され、2番目では120x120が使用されました。 ご覧のように、4x4ネットワークでは、色の間の遷移がシャープです。

- トレーニングの反復回数が多いほど、復元された色は実際の画像の色により正確に対応し、細部がよりよく見えます。 最初の図では、10個のフラグメントでトレーニングされた10x10のニューラルネットワークが使用され、2番目では10,000個のフラグメントが使用されました。


ちなみに、10x10と120x120の十分に訓練されたネットワークを視覚的に非常にわずかに異なるように復元することに注意してください。詳細をよく見ると、小さな違いが見つかります。
ジェネレーターを小さな
アプリケーションの形で設計したので、自分で楽しむことができます(webkitとFFで確認)。
軽微な偶発的な損傷を復元します。
小さなランダムな損傷は、小さなニューロンを含むネットワークによって簡単に修復されます。たとえば、3x3または5x5で十分です。 彼らは迅速かつ効率的に動作します。 25%のピクセル、10x10ネットワーク、5x5ニューロンが損傷した画像復元の例を次に示します


偶発的な損傷を復元するには、別の
アプリケーションを作成しました 。
大面積の回復
大きな損傷領域を修復するには、ニューロンSのサイズが損傷領域のサイズを超える必要があります。 したがって、損傷のサイズが大きければ大きいほど、復元された領域はより不鮮明になります。
この図は、15x10ニューロンを持つネットワークによる10x10フラグメントの復元を示しています


既知のピクセルの20%未満での回復
残念ながら、そのような画像から地図を作成することは不可能なので、残念ながら、それらを直接復元することはできませんが、すでに訓練されたネットワークを利用すれば復元できます。 図は、既知のピクセルの12%からの画像回復の例を示しています。 ネットワークは元の画像でトレーニングされました。


私の意見では、そのような大量の損害のため、それはかなりうまくいった。
UPD:私が開発した実用的なアプリケーション、アプリケーションについて:
私の研究の目的は、コンセプトを確認することであり、すべての機会に実用的なアプリケーションを提供することではないため、今日存在するバージョンの深刻な実用的アプリケーションに関するすべての話は意味をなしません。