 記事の2番目の部分。
記事の2番目の部分。最新のコンピューターは、
富士通Kスーパーコンピューター、通常のパーソナルコンピューター、または計算機であっても、共通の動作原理、つまり
制御フロー (Controlflow)に基づく計算モデルを組み合わせています。 ただし、可能なのはこのモデルだけではありません。 ある意味では、その反対は
データストリーム 、または単にデータフロー
によって駆動さ
れる計算モデルです。 私は今彼女について話したいです。
制御フローアーキテクチャは、しばしばフォンノイマン(ジョンフォンノイマンに敬意を表して)と呼ばれます。 フォンノイマンアーキテクチャは制御フローアーキテクチャのサブセットにすぎないため、これは完全に正しいとは限りません。 ハーバードなど、制御フローの非ノイマンアーキテクチャがありますが、これは現在、マイクロコントローラでのみ使用できます。
制御フロー(controlflow)のアーキテクチャの一部として、コンピューターは2つの主要ノードで構成されています:プロセッサーとメモリー。 プログラムとは、実行順にメモリに格納された一連の命令です。 プログラムが動作するデータは、変数のセットとしてメモリに保存されます。 現在実行中の命令のアドレスは、x86では命令ポインター(IP)と呼ばれる特別なレジスターに格納されます。 命令の実行の開始の瞬間は、前の命令の完了の瞬間によって決定されます(現在、
Out-of-Orderのない単純化されたモデルを検討しています)。 このシステムは非常にシンプルで理解しやすく、ほとんどの読者に馴染みがあります。 それでは、なぜ他の何かを思いつくのでしょうか?
先天性制御流の問題
事実、制御フローアーキテクチャには多くの固有の欠陥がありますが、これらは完全に除去することはできません。それらは計算プロセス自体の組織に起因するため、技術的ソリューションのさまざまな
松葉杖の助けを借りてしか悪影響を減らすことができません。 主な問題をリストします。
- 命令を実行する前に、そのオペランドをメモリからプロセッサレジスタにロードし、実行後、結果をメモリにアンロードして戻す必要があります。 プロセッサメモリバスがボトルネックになりつつあります。プロセッサは、一部の時間アイドル状態で、データの読み込みを待機しています。 変数の成功は、プロアクティブなサンプリングと複数のキャッシュレベルを使用して解決されます。
- マルチプロセッサシステムの構築には多くの困難が伴います。 このようなシステムには、共有メモリと分散メモリの2つの主要な概念があります。 最初のケースでは、1つのRAMに多数のプロセッサの共有アクセスを物理的に提供することは困難です。 2番目のケースでは、データの一貫性と同期の問題が発生します。 システム内のプロセッサの数が増加するにつれて、同期を確保するためにより多くのリソースが費やされ、コンピューティング自体にますます少なくなります[03] 。
- 命令の実行時に、そのオペランドが指定されたアドレスのメモリにあることを保証するものはありません。 このデータを記録する命令はまだ実装されていない可能性があります。 マルチスレッドアプリケーションでは、
プログラマのリソースと神経の大部分がスレッドの同期を確保するために費やされます。
会う-データフロー
Dataflowアーキテクチャという用語に対する確立されたロシア語の翻訳はありません。 「ストリーミングアーキテクチャ」、「データフローアーキテクチャ」、「データフロー制御を備えたアーキテクチャ」などのオプションがあります。
データフロー制御(データフロー)
[01]を備えたアーキテクチャで
は 、「命令のシーケンス」という概念はなく、命令ポインタはなく、通常の意味でアドレス可能なメモリすらありません。 ストリーミングシステムのプログラムは、命令のセットではなく、計算グラフです。 グラフの各ノードは演算子または演算子のセットを表し、ブランチはデータに応じたノードの依存関係を反映します。 次のノードは、入力データがすべて使用可能になるとすぐに実行を開始します。 これは、データフローの基本原則の1つです。データ準備命令の実行です。
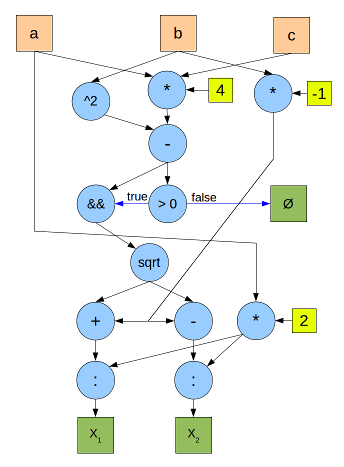
以下は、二次方程式の根を計算するためのグラフの例です。 青い円は演算子、オレンジ色の四角は入力データ、緑の四角は出力データ、黄色の四角は定数です。 黒い矢印は数値データの送信を示し、青い矢印はブールデータを示します。
ハードウェア実装
ストリーミングマシンでは、データはいわゆるデータとして送信および保存されます。
トークン (トークン)。 トークンは送信された実際の値を含む構造であり、
ラベルは宛先ノードのポインターです。 最も単純なストリーミングコンピューティングシステムは、実行ユニットとマッチングユニットの2つのデバイスで構成されています
[11] 。
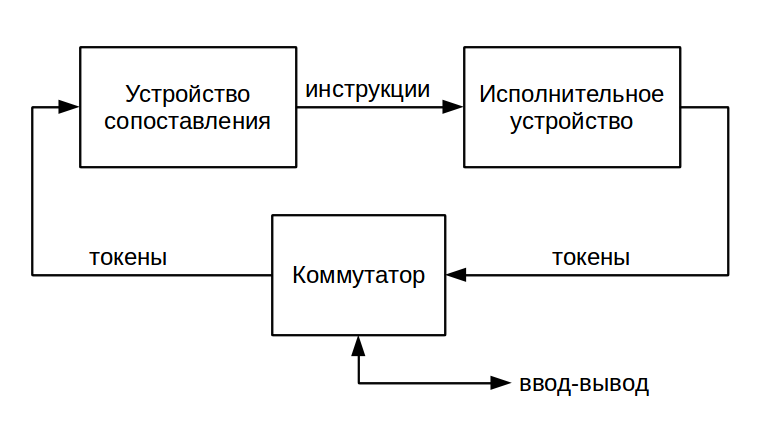
アクチュエータは、命令を実行し、操作の結果を使用してトークンを生成します。 通常、読み取り専用の命令メモリが含まれています。 ノードの入力データの準備は、同じラベルを持つトークンのセットの存在によって決定されます。 そのようなセットを検索し、一致するデバイスとして機能します。 通常、連想メモリに基づいて実装されます。 「実際の」ハードウェア連想メモリ(CAM-連想メモリ)が使用されるか、
ハッシュテーブルなど、同様に機能する構造が使用されます。
データフローアーキテクチャの主な利点の1つはスケーラビリティです。多くのマッチングデバイスとアクチュエータを含むシステムを組み立てることは難しくありません。 デバイスは単純なスイッチで結合され、そのラベルはトークンのアドレス指定に使用されます。 ノード番号の全範囲は、単にデバイス間で均等に分散されます。 マルチプロセッサ制御フローアーキテクチャとは異なり、コンピューティングプロセスの同期のための追加の手段は必要ありません。
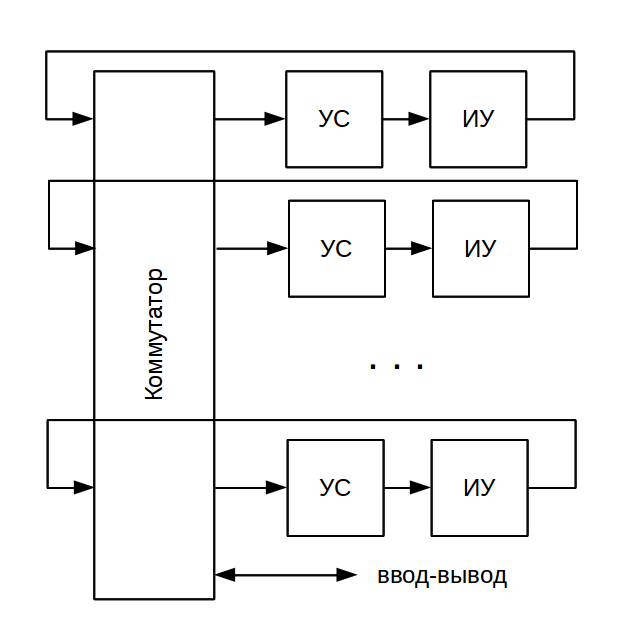
静的データフローアーキテクチャ
上記のスキームは、静的(静的データフロー)と呼ばれます。 その中で、各コンピューティングノードは単一のコピーで提示され、ノードの数は事前に知られており、システム内で循環しているトークンの数も事前に知られています。 静的アーキテクチャの実装の例としては、MIT Static Dataflow Machine
[12]があります。これは、1974年にマサチューセッツ工科大学で作成されたストリーミングコンピューターです。 マシンは、通信ネットワークで接続された多くの
処理要素で構成されていました。 1つの要素の回路を図に示します。
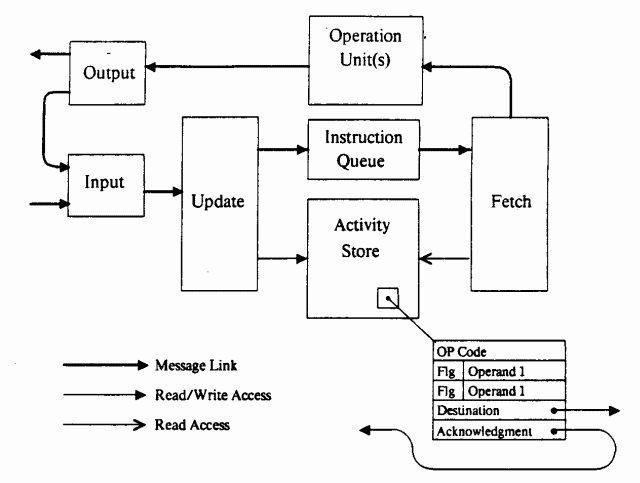
ここでのマッピングデバイスの役割は、アクティビティストアによって果たされました。 これには、宛先ノードのアドレス、準備フラグ、および操作コードとともに、トークンのペアが含まれていました。 このアーキテクチャのコンピューティングノードには、2つの入力しかなく、1人のオペレーターで構成されていました。 両方のオペランドの準備ができたことを検出すると、フェッチユニットはオペレーションコードを読み取り、データは処理のためにオペレーションユニットに送信されました。
動的データフローアーキテクチャ
動的データフローアーキテクチャでは、各ノードに複数のインスタンスを含めることができます。 同じノードの異なるインスタンスに宛てられたトークンを区別するために、追加のフィールドがトークン構造(
コンテキスト)に導入され
ます 。 トークンマッピングは、ラベルだけでなく、コンテキスト値によっても実行されるようになりました。 静的アーキテクチャと比較して、多くの新機能があります。
- 再帰。 ノードはデータをそのコピーに送ることができます。コピーはコンテキストが異なります(同時に同じラベルを持ちます)。
- サポート手順。 この計算モデル内の手順は、相互接続され、入力と出力を持つノードのシーケンスになります。 コンテキストが異なる同じプロシージャの複数のインスタンスを同時に呼び出すことができます。
- サイクルの並列化。 ループの反復間にデータ依存性がない場合、すべての反復を同時に処理できます。 おそらく既に推測したとおり、反復番号はコンテキストフィールドに含まれます。
動的ストリーミングアーキテクチャの最初の実装の1つは、Manchester Dataflow Machine(1980)
[13]でした。 マシンには、再帰の整理、プロシージャの呼び出し、ループの拡張、計算グラフのブランチのコピーと結合のためのハードウェアが含まれていました。 命令ストアユニットも別のモジュールに持ち出されました。 この図は、マシンの1つの要素の図を示しています。
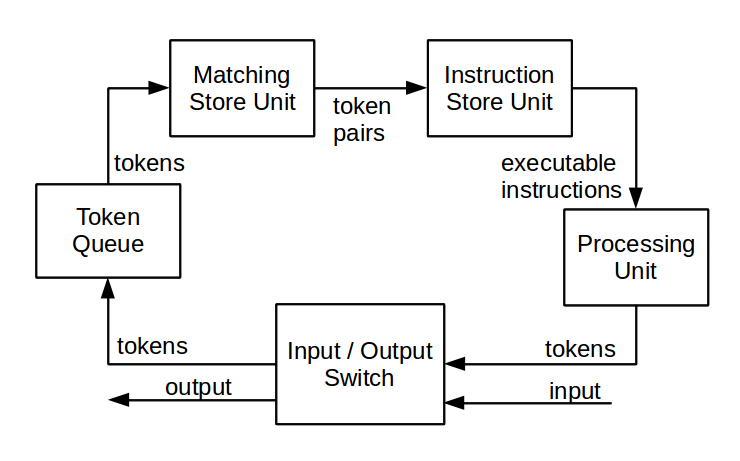
動的データフローアーキテクチャは、静的と比較して、計算の並列性が向上しているため、パフォーマンスが向上しています。 さらに、プログラマーにより多くの機会を提供します。 一方、動的システムは、ハードウェアの実装、特にデバイスとトークンコンテキスト生成ブロックのマッチングにおいてより複雑です。
続く
記事の次の部分では、データフローアーキテクチャがここで説明されているほど良くないのはなぜですか? クラシックで
ハリネズミとストリーミングシステムを横断する方法は? どのように、そして最も重要なこととして、データフローシステムのプログラムはどのように書かれていますか?
しばらくお待ちください...
文学
一般的なデータフローに関する質問
[01] -データフローアーキテクチャ、Jurij Silc
[02] -バカノフV.M. ストリーミング(データフロー)コンピューター:データ処理の強度を制御します
[03] -ストリーム(データフロー)アーキテクチャのコンピューターでのデータ処理の並列化。 雑誌「Top50 Supercomputers」。
ハードウェア実装
[11] -データフローアーキテクチャ、Arvind David E. Culler
[12] -基本的なデータフロープロセッサ、ジャックB.デニスおよびデビッドP.ミスナスの予備アーキテクチャ
[13] -多層データフローコンピューターアーキテクチャ、JRガード、I。ワトソン。