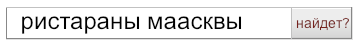
Webプロジェクトが何らかの方法でユーザーへのデータの検索と提供に関連している場合、おそらく検索文字列を実装するタスクに直面するでしょう。 同時に、何らかの理由でプロジェクトでGoogleやYandexなどのスマートサービステクノロジーを使用できない場合、部分的にまたは完全に独立して検索を実装する必要があります。 サブタスクの1つは、おそらくファジー検索の実装でしょう。これは、ユーザーがしばしば間違えて、正確な用語、名前、または名前を知らないことがあるためです。
この記事では、サイト
edatuda.ruでの検索に使用されたファジー検索の可能な実装について説明します。
挑戦するレストラン、カフェ、バー検索サービスの作成の一環として、ユーザーが施設の名前を表示できる検索バーを実装するタスクが発生しました。
タスクは次のように設定されました。
- 検索結果は、ドロップダウンリストの選択プロセスで表示されます。
- 検索では、ユーザーの考えられるエラーとタイプミスを考慮する必要があります(たとえば、マクドナルドはマクドナルドのように入力したいだけです)。
- 各機関に対して、多くの同義語を設定できる必要があります(たとえば、mcdonalds => makdak)。
アイテム1〜3の視覚表示:
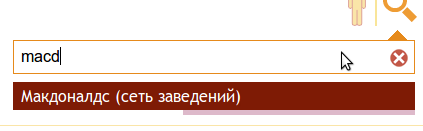

したがって、おそらくクロップされたクエリフレーズを受け取ったら、事前にコンパイルされた辞書から書面で最も近いエントリを選択する必要があります。 実際、タスクは、最新の検索エンジンが実行できるタイプミスを修正することでした。 それを解決するための一般的な方法の1つ:
- n-gramインデックスの構築に基づく方法。
素晴らしく、迅速かつ簡単な方法。 - 距離ベースの編集方法。
おそらく、コンテキストを考慮しない最も正確な方法の1つです。 - 請求項1と請求項2の結合。
大規模な辞書での検索を高速化するには、最初にセクション2の後続のアプリケーションでn-gramインデックスに基づいて単語のグループを選択するのが理にかなっています( ZobelおよびDarthの「大規模な辞書での近似一致の検索」を参照)
habrには、テキストと辞書のあいまい検索
に関する記事がありました。 パラグラフ1と2、特に、レーベンシュタインとダメラウ-レーベンシュタインの距離を素敵な写真で説明しています。 したがって、この記事ではこれらの方法の詳細な説明は提供しません。
検索の実装私たちの場合、辞書は(たとえば検索エンジンのように)数千エントリほどの大きさではないため、n-gramインデックスを作成せずに編集距離に基づいた方法を使用することにしました。
編集距離を計算するための従来のアルゴリズムは、行の近接度を十分に評価しますが、キーボード上の文字に対応するキー間の距離や音への近接度など、文字に関する情報(等値または不等式を除く)は使用しません。
キー間の距離を考慮することは便利です。なぜなら、すばやく入力する場合、ミスのために多数のエラーが発生する一方で、ユーザーが誤って次のキーを押した可能性がより遠くのキーよりも高いからです。
音声規則を考慮することも重要です。 たとえば、外国の名前や肩書きの場合、ユーザーは単語の正確なスペルを知らないことが多いのですが、音を覚えています。
ZobelとDarthの研究では、「音声文字列照合:情報検索からの教訓」は、編集距離の計算と一連の音声規則(フレーズ「音声規則」は完全に正確ではない)を組み合わせた文字列比較方法を説明しています。 著者は、編集距離を計算するときに1つのグループの文字を置き換える「コスト」が、1つのグループに属さない文字を置き換える「コスト」よりも低いような文字で構成される複数の音声グループを特定しました。 このアイデアを使用しました。
基本アルゴリズムとして、Wagner-Fischerアルゴリズムを採用し、いくつかの修正を加えてDamerau-Levenshtein距離を検出しました。
- 基本的なアルゴリズムでは、すべての操作の「コスト」は1です。挿入および削除操作の「コスト」を2に設定し、交換操作を1に設定し、1つの文字を別の文字に置き換える操作は次のように計算されます:比較された文字に対応するキーが互いに隣接している場合キーボードまたは比較文字が1つの音声グループに属している場合、置換の「コスト」は1、それ以外の場合は2です。
- その結果、プレフィックス距離が返されます。 クエリ単語と辞書の単語のすべての接頭辞との間の最小距離。 これが必要な理由は 辞書形式と比較するクエリ単語は通常、切り捨てられます。 つまり ユーザーが「mcd」とディクショナリ「mcdonalds」を入力して比較することができます。この場合の「mcdonalds」はクエリと非常に正確に一致しますが、長い距離(7回の挿入操作)を取得できます。
上記の作業から音声グループを取りましたが、少し変更しました。

元の作品では、グループは元の英語の単語の音に基づいて構成されていたため、音訳されたロシア語のテキストで良い結果が得られるという保証はありません。 独自の観察に基づいて、小さな変更を加えました(たとえば、元の「fpv」グループから「p」を削除しました)。
C ++での実装の結果:
{{{ class EditDistance { public: int DamerauLevenshtein(const std::string& user_str, const std::string& dict_str) { size_t user_sz = user_str.size(); size_t dict_sz = dict_str.size(); for (size_t i = 0; i <= user_sz; ++i) { trace_[i][0] = i << 1; } for (size_t j = 1; j <= dict_sz; ++j) { trace_[0][j] = j << 1; } for (size_t j = 1; j <= dict_sz; ++j) { for (size_t i = 1; i <= user_sz; ++i) {
短い言葉で言えば、ユーザーは、原則として、長いもののような失敗をしないことに注意してください。 これを行うために、クエリ単語の長さに比例する単語間の最大許容距離のしきい値を作成します。
{{{ const double kMaxDistGrad = 1 / 3.0; ... uint32_t dist = distance_.DamerauLevenshtein(word, dict_form); if (dist <= (word.size() * kMaxDistGrad)) {
索引機関のソースレコードを次の形式にします。
<メタデータ:ID、...> <機関名> <名前の同義語形式>
次に、インデックスは次のように表すことができます。

- places-検索の結果である施設のメタデータ。
- places_index-特定の機関を指す名前とその同義語。 基本的には場所へのリンクの配列にすぎません。
- words_index-すべてのフォームから抽出された単語。 次の形式の逆インデックスのようなものです:<word> <places_index0、places_index1、...>; 小さな辞書の場合、配列の配列として編成できます。
検索中に、各ユーザークエリワードのwords_index配列全体を調べる必要があります。 辞書が大きすぎる場合、最初の文字のエラーが非常にまれであると仮定して、クエリワードと同じ文字で始まるフォームに制限することができます。
完全性のために戦う
見つかった機関の完全性を高めるために、さらにいくつかのアイデアを適用しました。
- 入力時に、ユーザーはキーボードレイアウトの切り替えを忘れることがよくあります(「ghfqv」、「vfrljy」、..などのクエリがよく表示されます)。 したがって、通常の検索中にサイトが見つからなかった場合、基本クエリの反対のレイアウトの文字から形成されたクエリで同じ検索を実行するというアイデアが浮上しました。
- 多くの機関にはロシア語の名前はありませんが、ユーザーはキリル文字でそれらを入力することに慣れています。 マクドナルド、スターバックスなどの機関の場合、名前のキリル文字形式は、明らかに、同義語として辞書に入力できます。 ただし、GQ Barなどの一部の場合は、「GQ bar」などの同義語を生成することはお勧めできませんが、同時に、機関がクエリ「bar」と一致する必要があります。 したがって、通常のキリル文字クエリに加えて、追加の音訳されたクエリが生成されます。
{{{
一般的な実装
すべてのインデックス付けおよび検索ロジックは、c ++デーモンに実装されました。 機関に関するデータは定期的にデータベースから再読み込みされますが、インデックスは完全に再構築されます。 フロントエンドスクリプトとの通信は、GETリクエストを介してHTTP経由で実行され、結果はjson形式で応答本文で送信されます。 次のスキームが判明しました。

その結果、約2.5千の一意の単語で、平均検索時間は約8ミリ秒でした。
参照資料
- プロジェクトサイト。 edatuda.ru
- レーベンシュタイン距離。 en.wikipedia.org/wiki/Levenshtein_Distance
- 距離Damerau-Levenshtein。 en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance
- ゾベルとダースの作品。 「大きなレキシコンでの近似一致の検索。」 citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.14.3856&rep=rep1&type=pdf
- ゾベルとダースの作品。 「音声文字列照合:情報検索からの教訓」 citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.18.2138&rep=rep1&type=pdf