最適化は、明らかにMySQLサーバーのバックボーンではありません。 この記事の目的は、データベースと緊密に連携せず、MySQLの他のDBMSで正常に処理されるクエリがMySQL構築の最適化方法を恥知らずに遅くする理由を理解できない開発者に説明することです。
MySQLはルールベースのオプティマイザーを使用します。 コストベースの最適化の初歩は確かに存在しますが、私がそれらを見たいほどではありません。 このため、多くの場合、フィルターの適用後に取得されたセットのべき乗が誤って計算されます。 これは、オプティマイザーエラーと誤った実行計画の選択につながります。 さらに、最適化の間に取得された最適化を明示的に変更することはできません。クエリ実行のインデックスとテーブルの結合順序です。
バグの本質を理解するために、1億2500万件のレコードのテストデータセットを作成します。
drop table if exists pivot; drop table if exists big_table; drop table if exists attributes; create table pivot ( row_number int(4) unsigned auto_increment, primary key pk_pivot (row_number) ) engine = innodb; insert into pivot(row_number) select null from information_schema.global_status g1, information_schema.global_status g2 limit 500; create table attributes(attr_id int(10) unsigned auto_increment, attribute_name varchar(32) not null, start_date datetime, end_date datetime, constraint pk_attributes primary key(attr_id) ) engine = innodb; create table big_table(btbl_id int(10) unsigned auto_increment, attr_attr_id int(10) unsigned, record_date datetime, record_value varchar(128) not null, constraint pk_big_table primary key(btbl_id) ) engine = innodb; insert into attributes(attribute_name, start_date, end_date) select row_number, str_to_date("20000101", "%Y%m%d"), str_to_date("20000201", "%Y%m%d") from pivot; insert into big_table(attr_attr_id, record_date, record_value) select p1.row_number, date_add(str_to_date("20000101", "%Y%m%d"), interval p2.row_number + p3.row_number day), p2.row_number * 1000 + p3.row_number from pivot p1, pivot p2, pivot p3; create index idx_big_table_attr_date on big_table(attr_attr_id, record_date);
属性テーブルは、本質的には
big_tableの参照であり、日付範囲を1か月に制限する2つの列も含まれています。
| attr_id | 属性名 | 開始日 | 終了日 |
| 1 | 1 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
| 2 | 2 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
| 3 | 3 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
attr_idごとに、大きなテーブルには250,000エントリが含まれます。 属性1の
属性テーブルで指定された日付を考慮して、
big_tableに含まれるレコードの数を調べてみましょう。
select attr_attr_id, max(record_date), min(record_date), max(record_value), count(1) from big_table where attr_attr_id = 1 and record_date between str_to_date("20000101", "%Y%m%d") and str_to_date("20000201", "%Y%m%d") group by attr_attr_id;
| attr_attr_id | 最大(記録日) | 分(記録日) | カウント(1) |
| 1 | 2/1/2000 12:00:00 AM | 1/3/2000 12:00:00 AM | 465 |
約500レコードを取得します(クエリの実行時間は無視でき、00.050秒になります)。 データはすべての属性値に対して同じように分散されるため、バインド変数を指定する代わりに
属性テーブルに接続するとき、クエリ時間はわずかに増加し、25秒を超えてはならないと想定するのが論理的です。 よく確認してください:
select b.attr_attr_id, max(b.record_date), min(b.record_date), max(b.record_value), count(1) from attributes a join big_table b on b.attr_attr_id = a.attr_id and b.record_date between a.start_date and a.end_date group by b.attr_attr_id;
実行時間:15分以上(この時点でリクエストを中断しました)。 これはなぜですか? 問題は、MySQLは動的ランキングをサポートしていないことです。これについては、2004年に作成されたバグ
#5982について述べています。 実行計画を見てみましょう。
| id | select_type | テーブル | タイプ | possible_keys | 鍵 | key_len | ref | 行 | 追加 |
| 1 | シンプル | b | すべて | idx_big_table_attr_date | | | | 125443538 | 一時的な使用; ファイルソートの使用 |
| 1 | シンプル | a | eq_ref | プライマリ | プライマリ | 4 | test.b.attr_attr_id | 1 | どこを使うか |
この計画は、1億2500万件のレコードの全テーブルスキャンが進行中であることを明確に示しています。 奇妙な決定。 状況を修正しても、
straight_joinが結合の順序を変更したり、
インデックスの使用を明示的に示す
ようにインデックスを
強制したりすることはできません。 問題は、せいぜい次の形式の計画を取得することです。
| プライマリ | b | ref | idx_big_table_attr_date | idx_big_table_attr_date | 5 | a.attr_id | 6949780 | どこを使うか |
これにより、
big_tableは目的のインデックスでスキャンされますが、インデックスは完全には関与しません。つまり、そこから最初の列のみが使用されます 。 一部の縮退したケースでは、必要な計画を達成し、インデックスを最大限に活用できますが、オプティマイザーの一貫性がなく、このソリューションを適用できないため(ここではコードを示しません。90%のケースでは機能しません)、すべてのケースで、別のアプローチ。
このハイキングはMySQL自体を提供します。
バインド変数を明示的に指定
します。 もちろん、これは多くのタスクに対して常に効果的ではありません。フルスキャンはインデックススキャンよりも高速であるためですが、250,000から500エントリを選択する必要がある場合は明らかにそうではありません。問題を解決するには、次の手順を作成する必要があります。
drop procedure if exists get_big_table_data;
delimiter $$
create procedure get_big_table_data(i_attr_from int (10))
main_sql:
begin
declare v_attr_id int (10);
declare v_start_date datetime;
declare v_end_date datetime;
declare ex_no_records_found int (10) default 0;
declare
attr cursor for
select attr_id, start_date, end_date
from attributes
where attr_id > i_attr_from;
declare continue handler for not found set ex_no_records_found = 1;
declare continue handler for sqlstate '42S01' begin
end ;
create temporary table if not exists temp_big_table_results(
attr_attr_id int (10) unsigned,
max_record_date datetime,
min_record_date datetime,
max_record_value varchar (128),
cnt int (10)
)
engine = innodb;
truncate table temp_big_table_results;
open attr;
repeat
fetch attr
into v_attr_id, v_start_date, v_end_date;
if not ex_no_records_found then
insert into temp_big_table_results(attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
)
select attr_attr_id,
max (record_date) max_record_date,
min (record_date) min_record_date,
max (record_value) max_record_value,
count (1) cnt
from big_table b
where attr_attr_id = v_attr_id and record_date between v_start_date and v_end_date
group by attr_attr_id;
end if ;
until ex_no_records_found
end repeat;
close attr;
select attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
from temp_big_table_results;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter .
つまり 最初に、属性テーブルの500件のレコードでカーソルを開き、このテーブルの各行に対して
big_tableからリクエストを
作成します。 結果を見てみましょう:
call get_big_table_data(0);
* This source code was highlighted with Source Code Highlighter .
ランタイム:
0:00:05.017私見では結果はずっと良くなっています。 完璧ではありませんが、機能します。
ここで、「トランザクション」テーブルではなく、ファクトテーブルで検索が実行される場合の反対の例を検討できます。
このバグは次の場合に表示されます。
-GeoIPデータベースを操作する
-スケジュールを分析しようとしています
-外国為替の通貨レートを修正
-オペレーターの番号付け能力によって都市を計算します
など
最初に、2500万行のテストデータセットを作成します。
drop table if exists big_range_table; create table big_range_table(rtbl_id int(10) unsigned auto_increment, value_from int(10) unsigned, value_to int(10) unsigned, range_value varchar(128), constraint pk_big_range_table primary key(rtbl_id) ) engine = innodb; insert into big_range_table(value_from, value_to, range_value) select @row_number := @row_number + 1, @row_number + 1, p1.row_number + p2.row_number + p3.row_number from (select * from pivot where row_number <= 100) p1, pivot p2, pivot p3, (select @row_number := 0) counter; create index idx_big_range_table_from_to on big_range_table(value_from, value_to); create index idx_big_range_table_from on big_range_table(value_from);
フォームの表を取得する
| rtbl_id | value_from | value_to | range_value |
| 1 | 1 | 2 | 3 |
| 2 | 2 | 3 | 4 |
| 3 | 3 | 4 | 5 |
そして移動中に、MySQLを除くすべてのDBMSによって正常に最適化されたクエリを実行してみましょう。
select range_value from big_range_table where 10000000.5 >= value_from and 10000000.5 < value_to;
リードタイム:
0:00:22.412 。 一般に、このようなリクエストは1つの一意の行を返すことがわかっているため、これはオプションではありません。 また、選択した変数の値が高いほど、より多くのレコードがスキャンされるため、クエリの実行時間が指数関数的に増加します。
MySQL自体は、この問題を解決するために次の回避策を提供します。
select range_value from big_range_table where value_from <= 25000000 order by value_from desc limit 1;
リードタイム:
0:00:00.350 。 悪くない。 ただし、このソリューションには多くの欠点があります。特に、他のテーブルと結合することはできません。 つまり この要求は、アトミックにのみ存在できます。 結合の可能性のために、標準ソリューションのRTreeインデックスを使用します(もちろん、ディレクトリにトランザクションが必要な場合、またはこのタイプのインデックスはMyISAMに対してのみ機能するため、トリガーで整合性を確保する場合を除きます)。 MySQLの幾何オブジェクトが何であるかを知らない人のために、そのような場合に通常何をするのかを説明します。
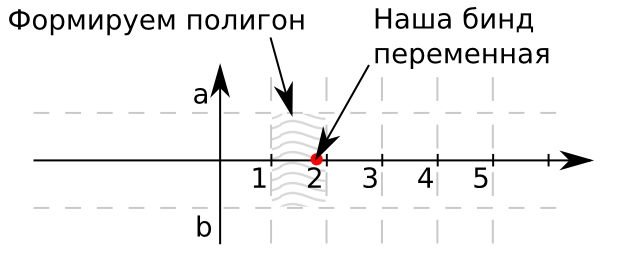
飛行機を想像してください。 横軸は検索の値です。 この特定のケースでは、単純化のために、1つの基準のみを検索するため、ポイントの縦座標はゼロです。 多次元オブジェクトを使用するために基準がさらに必要な場合。 長方形aとbの境界は、通常それぞれ1と-1です。 したがって、リファレンスブックの値は、0から出る光線をカバーします。また、影付きの四角形のセットによって制限されます。 ポイントがこの長方形に属する場合、この長方形の識別子は、テーブル内のレコードの目的の識別子を提供します。 変換を開始します。
alter table big_range_table engine = myisam, add column polygon_value polygon not null; update big_range_table set polygon_value = geomfromwkb(polygon(linestring( point(value_from, -1), point(value_to, -1), point(value_to, 1), point(value_from, 1), point(value_from, -1) )));
私と一緒にこの操作を敢行した人のために、
更新の終了時刻を監視します。
select (select @first_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated, sleep(10) lets_sleep, (select @second_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated_in_a_ten_second, @second_value - @first_value myisam_updated_records, 25000000 / (@second_value - @first_value) / 6 estimate_for_update_in_minutes, (select 25000000 / (@second_value - @first_value) / 6 - time / 60 from information_schema.processlist where info like 'update big_range_table%') estimate_time_left_in_minutes;
このステップに到達した場合、データベース設定が正しくない場合、このインデックスの作成には1週間かかる可能性があるため、実行しないことをお勧めします。
create spatial index idx_big_range_table_polygon_value on big_range_table(polygon_value);
さて、作業の速度を比較できます。 最初に、リクエストの初期バージョンと「ジオメトリ」バージョンの実行速度を見てみましょう。
制限値を10から100に徐々に増やします。
select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where mbrcontains(polygon_value, pointfromwkb(point(row_number, 0))) and row_number < value_to; select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where value_from <= row_number and row_number < value_to;

左側が時間、下が制限値です。 図からわかるように、バインド変数の次の値ごとに、より多くの行をスキャンする必要があるため、(青)の間の時間は、先頭にあるか末尾に近いかに応じて指数関数的に長くなります。 このような小さな値での「幾何学的」解(ピンク色)は、単に定数です。
制限1による順序と、より大きい値の
ジオメトリを比較してみましょう。 これを行うには、手順を使用して、平等な競技場を作成し、ランダムサンプリングを実行します。
drop procedure if exists pbenchmark_mbrcontains;
delimiter $$
create procedure pbenchmark_mbrcontains(i_repeat_count int (10))
main_sql:
begin
declare v_random int (10);
declare v_range_value int (10);
declare v_loop_counter int (10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where mbrcontains(polygon_value, pointfromwkb(point(v_random, 0))) and v_random < value_to;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
drop procedure if exists pbenchmark_limit;
delimiter $$
create procedure pbenchmark_limit(i_repeat_count int (10))
main_sql:
begin
declare v_random int (10);
declare v_range_value int (10);
declare v_loop_counter int (10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where value_from <= v_random order by value_from desc limit 1;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter .
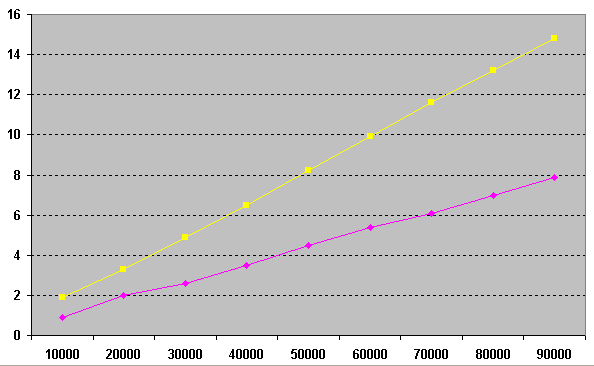
グラフでは、手順の開始数が10,000から90,000に順次増加した結果と、対応する操作に費やされた秒数を確認できます。 ご覧のとおり、「幾何」ソリューション(ピンク)は
、制限1 (黄色)
による順序を使用したソリューションよりも2倍速く、さらに、このソリューションは標準SQLに適用できます。
データジャムが少量のデータで表示されないためだけにこのトピックを取り上げましたが、データベースが大きくなり、10人を超えるユーザーがそこに住み始めると、パフォーマンスの低下は単純に巨大になり、これらの種類のクエリはほとんどすべてで見つかります産業用データベース。
最適化の成功をお祈りします。 次回この記事がおもしろければ、人生に干渉しないだけでなく、逆もまた同様であるバグについて説明します-正しく使用するとクエリのパフォーマンスが向上します。
Z.Y.
MySQLバージョン5.5.11
キャッシュが結果を取得しないように、すべてのクエリはMySQLの再起動後に実行されました。
MySQL設定は標準からはほど遠いですが、innodbバッファーのサイズは300 Mbを超えず、MyISAMバッファーのサイズは(インデックスが作成された瞬間を除いて)100Mbを超えません。
使用されるファイルサイズ:
big_range_table.ibd 1740M
big_table.ibd 5520M-インデックスなし
big_table.ibd 8268M-インデックス付き
つまり クエリの開始が完全に除外される前にオブジェクトをデータベースキャッシュに入れる。