こんにちはHabracheloveki!
しばらく待ってから、Javaでのデータ構造の視覚化を続けます。 以前の記事で気付いたのは、
ArrayList 、
LinkedList 、
HashMapです。 今日は、LinkedHashMapをご覧ください。
 名前から、この構造はリンクリストとハッシュマップの共生であると推測できます。 実際、LinkedHashMapはHashMapクラスを拡張し、Mapインターフェイスを実装していますが、リンクリストについてはどうですか? 正しくしましょう。
名前から、この構造はリンクリストとハッシュマップの共生であると推測できます。 実際、LinkedHashMapはHashMapクラスを拡張し、Mapインターフェイスを実装していますが、リンクリストについてはどうですか? 正しくしましょう。オブジェクト作成
Map<Integer, String> linkedHashMap = new LinkedHashMap<Integer, String>();
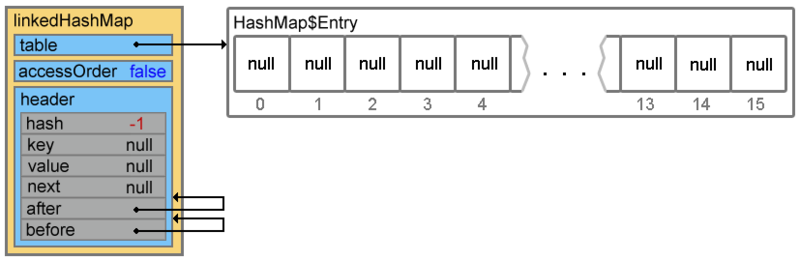
Footprint{Objects=3, References=26, Primitives=[int x 4, float, boolean]}size: 160 bytesHashMapから継承されたプロパティ(テーブル、loadFactor、しきい値、サイズ、entrySetなど)に加えて、
新しく作成された
linkedHashMapオブジェクトにも2つの追加要素が含まれています。 プロパティ:
- header-二重にリンクされたリストのヘッド。 初期化時に、それ自体を示します。
- accessOrder-イテレーターの使用時に要素にアクセスする方法を示します。 trueの場合、最後のアクセス順に(これについては記事の最後で詳しく説明します)。 falseの場合、アクセスは要素が挿入された順序になります。
LinkedHashMapクラスのコンストラクター
は非常に退屈です;そのすべての作業は、親クラスのコンストラクターを呼び出し、
accessOrderプロパティの値を設定することになります。 ただし、
ヘッダープロパティの初期化は、オーバーライドされた
init()メソッドで行われ
ます( HashMapクラスのコンストラクターが何もしないこの関数の呼び出しを持っている理由が明らかになりました )。
void init() { header = new Entry<K,V>(-1, null, null, null); header.before = header.after = header; }
新しいオブジェクトが作成され、プロパティが初期化され、要素の追加に進むことができます。
アイテムを追加する
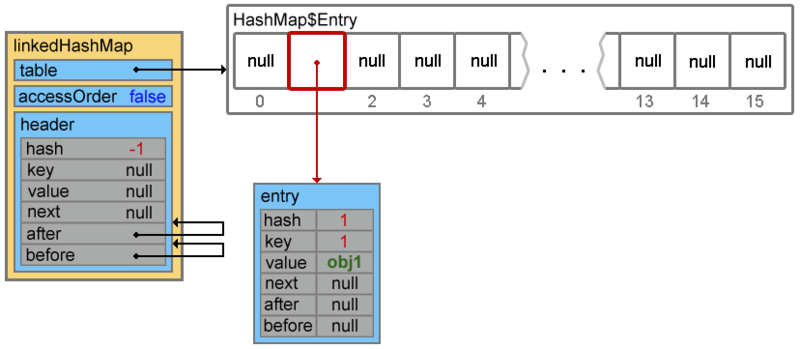
linkedHashMap.put(1, "obj1");
Footprint{Objects=7, References=32, Primitives=[char x 4, int x 9, float, boolean]}size: 256 bytes要素を追加するとき、
createEntryメソッド
(hash、key、value、bucketIndex)が最初に呼び出され ます(チェーン
put() ->
addEntry() ->
createEntry() )
void createEntry(int hash, K key, V value, int bucketIndex) { HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<K,V>(hash, key, value, old); table[bucketIndex] = e; e.addBefore(header); size++; }
最初の3行は要素を追加します(衝突の場合、追加はチェーンの最初に行われます。後で見る)
4行目は、二重リンクリストリンクを再定義します
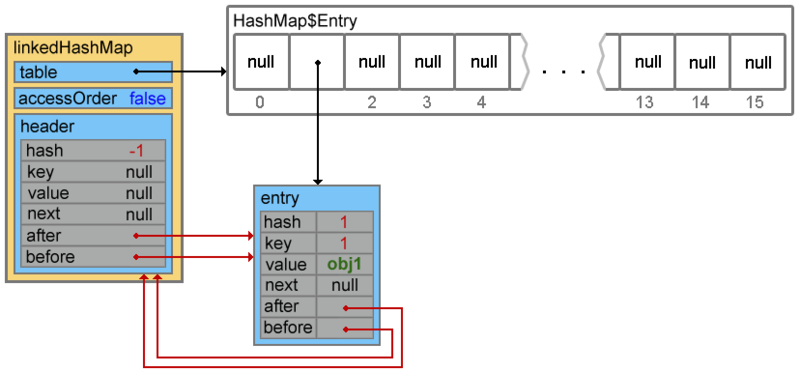
addEntry()メソッドで次に発生するすべてのことは、「機能的関心」
1を表さないか、親クラスの機能を繰り返します。
さらにいくつかの要素を追加します。
linkedHashMap.put(15, "obj15");
Footprint{Objects=11, References=38, Primitives=[float, boolean, char x 9, int x 14]}size: 352 bytes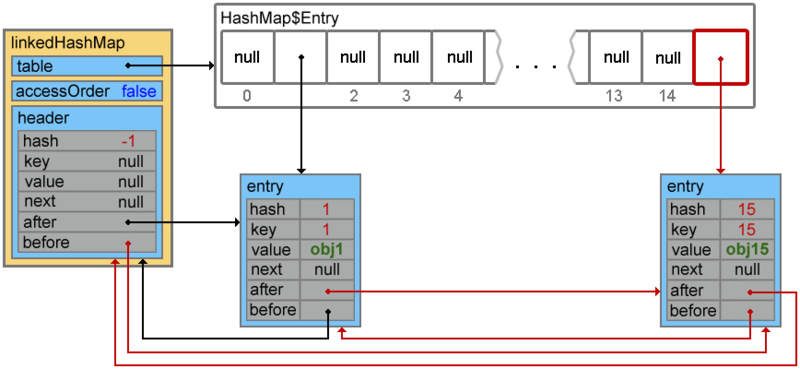
linkedHashMap.put(4, "obj4");
Footprint{Objects=11, References=38, Primitives=[float, boolean, char x 9, int x 14]}size: 448 bytes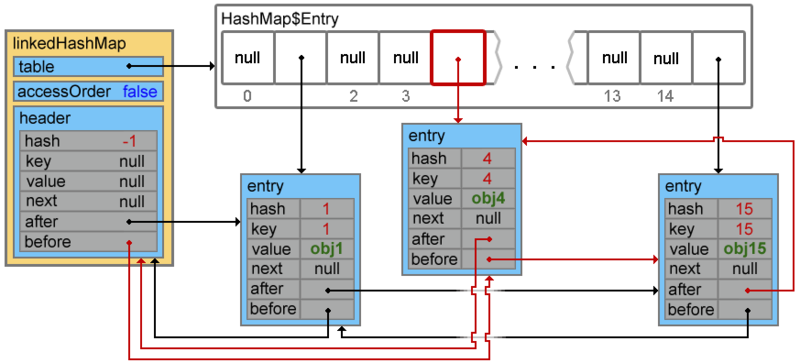
次の要素を追加すると、衝突が発生し、キー4と38の要素がチェーンを形成します
linkedHashMap.put(38, "obj38");
Footprint{Objects=20, References=51, Primitives=[float, boolean, char x 18, int x 24]}size: 560 bytes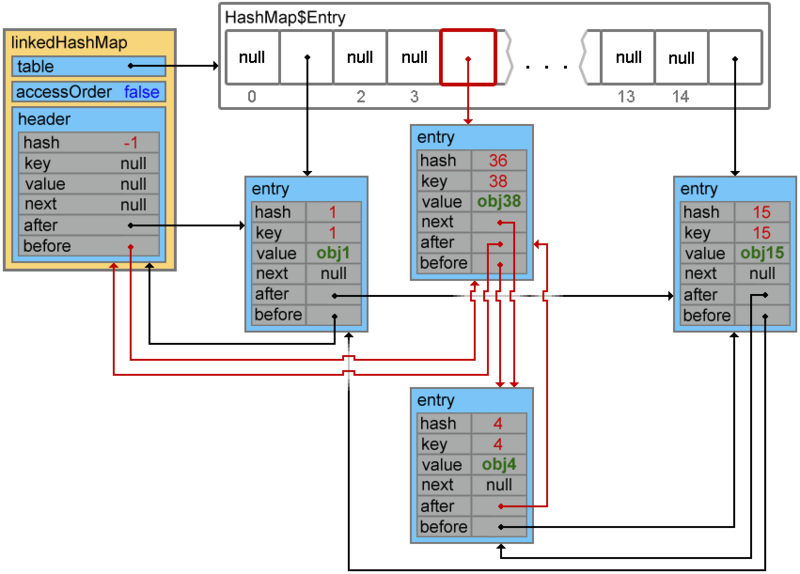
要素(同じキーを持つ要素が既に存在する)を繰り返し挿入する場合、要素へのアクセス順序は変わらないという事実に注目します。
accessOrder == true
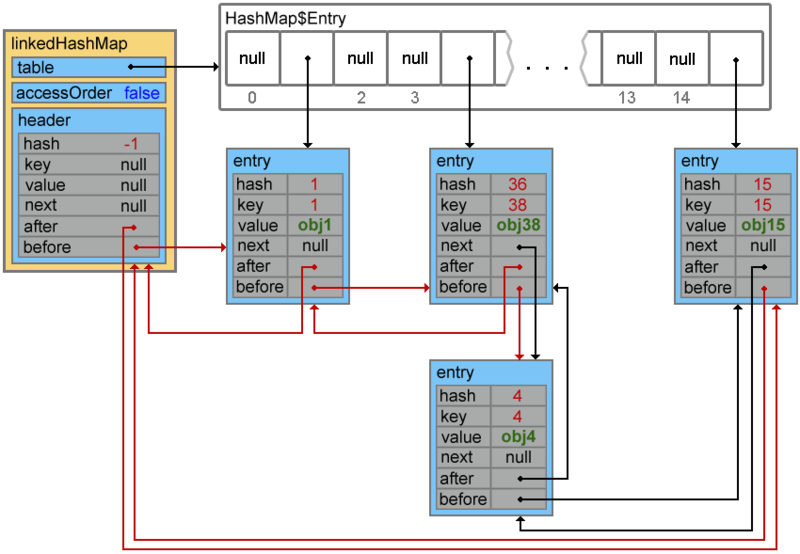
ここで、
accessOrderプロパティが
trueの場合の例を見てみましょう。 この状況では、
LinkedHashMapの動作が変わり、
get()および
put()メソッドを呼び出すと、要素の順序が変更されます-参照する要素は最後に配置されます。
Map<Integer, String> linkedHashMap = new LinkedHashMap<Integer, String>(15, 0.75f, true) {{ put(1, "obj1"); put(15, "obj15"); put(4, "obj4"); put(38, "obj38"); }};
イテレータ
すべてがかなり平凡です:
まあ、フェイルファーストを忘れないでください。 すでに要素の列挙を開始している場合-内容を変更したり、事前に同期を処理したりしないでください。
合計ではなく
この構造は、親
HashMapに比べてパフォーマンスがわずかに劣る場合がありますが、
add()、contains()、remove()操作の実行時間は一定のままです-O(1)。 要素とその接続を保存するには、メモリ内にもう少しスペースが必要になりますが、これは追加のチップのごくわずかな料金です。
一般に、親クラスが主な仕事を引き継ぐという事実のために、
HashMapと
LinkedHashMapの実装に多くの重大な違い
はありません。 いくつかの小さなものに言及できます。
- transfer()およびcontainsValue()メソッドは、要素間の双方向通信が存在するため、少し単純です。
- LinkedHashMap.Entryクラスは、 recordRemoval()およびrecordAccess()メソッド( accessOrder = trueで要素を最後に配置するメソッド)を実装します 。 HashMapでは 、これらのメソッドは両方とも空です。
参照資料
LinkedHashMapソースJDKが
OpenJDKとTrade 6のソースリリースをソース-ビルドb23測定ツール-
メモリ測定器と
グアバ (Googleコアライブラリ)。
1 -
removeEldestEntryメソッド
(Map.Entry eldest)を呼び出すと、常に
falseが返され
ます 。 このメソッドは、たとえば
Mapに基づいてキャッシュ構造を実装するなど、あらゆるニーズに対してオーバーライドできると想定されています(
ExpiringCacheを参照)。
removeEldestEntry()が
trueを返した後、最大値を超えると最も古いアイテムが削除されます。 アイテムの数。