多くの大規模で負荷の大きいWebプロジェクトでは、データベースの速度が生産性のボトルネックになることがよくあります。 メモリを追加し、特定のパラメータを調整することができます...しかし、最終的には、ほとんどすべてがディスクに依存します。

私たち自身のプロジェクトでは、iostatで100%に近いディスク使用率を定期的に観察する同様の「ボトルネック」(ボトルネック)に遭遇しました。
この投稿でこの問題を解決した経験をお伝えしたい...
最初の(そして一見明らかな)ソリューションは、
より高速なディスクを
使用することです。
現時点で最速-おそらくSSD。
SSDドライブは非常に高速に動作します! しかし...
- サーバー(コントローラー、ドライバー)のSSDサポートが必要です。
- SSDは高価です。
最近のHighload ++ 2011カンファレンスで話したDomas Mituzas(Facebookデータベースパフォーマンスエンジニア)でさえ、最近このようなことを言いました。「
SSDをどこでも使用できれば、パフォーマンスに関して何も発明する必要はありません。仕事はあまり意味がないでしょう 。 "
別のアプローチは、
1つではなく複数のディスクを
使用することです。 RAID、言い換えれば 。
私たちはすでに、Amazonクラウドに独自のプロジェクトを配置することを書きました。 そして
、Amazon EBSドライブからアセンブルされたソフトウェアRAIDで正常に
動作します 。
多くの
異なるRAID構成があります 。
確かに、あなたの多くはすでに
MySQL Performance Blogで公開されているAmazonのEBSディスクでテスト結果を見て読ん
でいます 。
彼らは非常に好奇心and盛で興味深いですが、彼らは私たちに本当に合っていませんでした。 基本的に、非常に異なる結果が正しく比較されないという事実(たとえば、1つのディスクから1つのストリームへの読み取り、RAID 0から8スレッド、RAID 10から4など)。
そのため、独自のテストを実施することにしました。 同じツールがsysbenchです。
RAID 10を使用することにしました。高速で信頼性の高いのは彼です。 そして、ここでは、そのさまざまな構成-非常に多く。
少し余談。 テストプロセス中に、「クラウド」のもう1つの非常に重要な利点を評価し
ました。「クラウド」では、さまざまなテストを実行し、テストスタンドを収集して分解することが非常に便利です。 そして、支払い中-実際の使用時のみ!だから。 5つのスタンドを収集しました。1.シングルディスク-100 Gb2. RAID 10-50 Gbの4台のドライブAmazon管理パネルに4つのディスクを追加し、対応する名前を割り当ててそれらを接続し、次のようなRAIDを作成しました。
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/xvd[gj]3. RAID 10-2つのRAID 1のRAID 0(それぞれ50 Gbの2つのドライブ)同じ手順ですが、最終的なRAIDは3つのステップで作成されます。
# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/xvd[gh]
# mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/xvd[ij]
# mdadm --create /dev/md2 --level=0 --raid-devices=2 /dev/md[0-1]4. RAID 10-25 Gbの8ドライブパラグラフ2と同様ですが、4ではなく8つのドライブのみを接続します。
# mdadm --create /dev/md0 --level=10 --raid-devices=8 /dev/xvd[gn]5. RAID 10-4つのRAID 1のRAID 0(それぞれ25 Gbの2つのディスク)# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/xvd[gh]
# mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/xvd[ij]
# mdadm --create /dev/md2 --level=1 --raid-devices=2 /dev/xvd[kl]
# mdadm --create /dev/md3 --level=1 --raid-devices=2 /dev/xvd[mn]
# mdadm --create /dev/md4 --level=0 --raid-devices=4 /dev/md[0-3]すべてのテストベッドはext4ファイルシステムを使用しました。 マウントオプション:
noatime,nodiratime,data=writeback,barrier=0テストでは、sysbenchが使用されました-256 MBファイル。 モード-ランダム読み取り、ランダム書き込み、ランダム読み取り/書き込み。 異なるスレッド数-1〜16
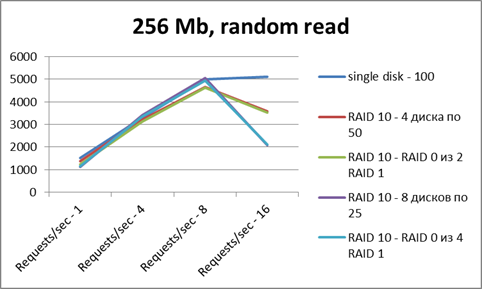

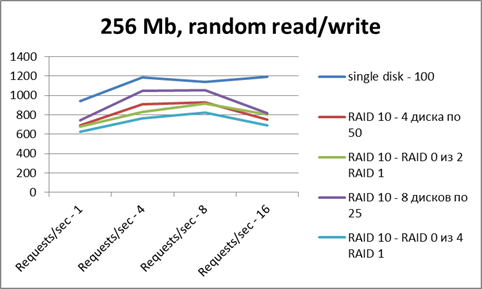
X軸-スレッド数
Y軸-1秒あたりの操作数。
読書-結果はすべて同等です。 レイドは特に利点はありません。
しかし、ファイルキャッシュは結果に大きな影響を与えるため、この図は非常に歪んでいます(テストファイルは完全にRAMに配置されます)。
記録によると、襲撃は少し失われます(オーバーヘッドが影響します)。
* * *
「どちらが良いですか...」という言葉で始まる質問は、それ自体では意味がありません。
どのCMSが優れていますか?
どのデータベースを選択しますか?
RAID'aとして選択する方が良いものは何ですか?
どの選択においても、設定および解決されるタスクは常に重要です!ベースのディスクシステムを選択します。 データストレージ形式はInnoDBです。
つまり、基本的に、大きなファイル(数GB)のibdataを使用します。
典型的な負荷プロファイルは、ランダムな読み取り/書き込み(より多くの読み取り)です。
そして今、より理解しやすい実際のタスクから進んで、16 GBファイルで新しい一連のテストを作成しています。



- 読書-1枚のディスクがすぐに天井に置かれます。 スレッド数を増やしても、パフォーマンスは向上しません。
- 複数のスレッドで4つのディスクをレイドすると、パフォーマンスが3〜4倍向上します。 8枚のディスクの襲撃-6-7回。
- 記録上-1枚のディスクとほぼ同じ画像。
* * *
まとめます。MySQLデータベースの典型的な操作はランダムな読み取り/書き込みであり、書き込みよりも読み取りの方が多くなります。 このタスクで最も生産的なのは、多数のディスクを備えたRAID 10です。
このソリューションの欠点は、ディスクのコストが2倍になることです(現在のコストでは重要ではありません)。
主なプラス-ディスクシステムのパフォーマンスを拡張するための簡単なソリューション(物理サーバーと「クラウド」の両方でソフトウェアRAIDを組み立てることができます)があります。