10月、
HashMapの作業に関するすばらしい
記事がハブに掲載さ
れました 。 このトピックを続けて、java.util.concurrent.ConcurrentHashMapの実装について説明します。
それで、ConcurrentHashMapはどのように生まれ、その利点は何で、どのように実装されたのでしょうか。
ConcurrentHashMapを作成するための前提条件
JDK 1.5でConcurrentHashMapが導入される前は、ハッシュテーブルを記述する方法がいくつかありました。
もともとJDK 1.0には、Hashtableクラスがありました。 Hashtableは、スレッドセーフで使いやすいハッシュテーブル実装です。 HashTableの問題は、まず、テーブルの要素にアクセスするときに完全にロックされることでした。 すべてのHashtableメソッドが同期されました。 これは、テーブル全体をロックするための料金が非常に高かったため、マルチスレッド環境にとって深刻な制限でした。
JDK 1.2では、HashtableはHashtableとそのスレッドセーフなプレゼンテーション、Collections.synchronizedMapの助けになりました。 この分離にはいくつかの理由がありました。
- すべてのプログラマーまたはすべてのソリューションがスレッドセーフハッシュテーブルを必要としたわけではありません
- プログラマは、自分にとって使いやすいオプションを選択する必要がありました。
したがって、JDK 1.2では、Javaでハッシュマップを実装するためのオプションのリストが、さらに2つの方法で補完されました。 ただし、これらのメソッドは、開発者をコード内の競合状態の出現から救いませんでした。これにより、ConcurrentModificationExceptionが出現する可能性がありました。
この記事では、コード内で発生する可能性のある理由
について詳しく説明します。
そのため、JDK 1.5には最終的に生産性と拡張性の高いオプションがあります。
並行ハッシュマップ
ConcurrentHashMapが登場するまでに、Java開発者は次のハッシュマップの実装を必要としていました。
- スレッドセーフ
- アクセス中にテーブル全体にロックが存在しない
- 読み取り操作を実行するときにテーブルロックがないことが望ましい
Doug Leaは、そのようなデータ構造の実装オプションを提示します。これは、JDK 1.5に含まれています。
ConcurrentHashMapを実装するための主なアイデアは何ですか?
1.マップ要素
HashMap要素とは異なり、ConcurrentHashMapのエントリはvolatile宣言されています。 これは重要な機能であり、JMMの変更にも関連しています。 揮発性の可能性のある競合状態を使用する必要性に関するDoug Leaの回答は、
ここで読むことができ
ます 。
静的最終クラスHashEntry <K、V> {
最後のKキー。
最終的なintハッシュ。
揮発性V値;
最後のHashEntry <K、V>次に;
HashEntry(Kキー、intハッシュ、HashEntry <K、V> next、V値){
this .key = key;
this .hash = hash;
this .next = next;
this .value = value;
}
@SuppressWarnings( "未チェック")
static final <K、V> HashEntry <K、V> [] newArray(int i){
新しいHashEntry [i]を返します。
}
}
2.ハッシュ関数
ConcurrentHashMapは、改良されたハッシュ関数も使用します。
JDK 1.2のHashMapの様子を思い出させてください。
静的intハッシュ(int h){
h ^ =(h >>> 20)^(h >>> 12);
return h ^(h >>> 7)^(h >>> 4);
}
ConcurrentHashMap JDK 1.5のバージョン:
private static int hash(int h){
h + =(h << 15)^ 0xffffcd7d;
h ^ =(h >>> 10);
h + =(h << 3);
h ^ =(h >>> 6);
h + =(h << 2)+(h << 14);
return h ^(h >>> 16);
}
ハッシュ関数を複雑にする必要は何ですか? ハッシュマップのテーブルの長さは、2の累乗によって決まります。 バイナリの表現がジュニアとシニアの位置で異ならないハッシュコードの場合、衝突が発生します。 ハッシュ関数の複雑さはこの問題を解決するだけであり、マップ内での衝突の可能性を減らします。
3.セグメント
カードはN個の異なるセグメントに分割されます(デフォルトでは16、最大値は16ビットで、2のべき乗を表します)。 各セグメントは、マップ要素のスレッドセーフテーブルです。
上位ビットへのビットマスクハッシュコードの適用に基づいて、キーハッシュコードと対応するセグメントの間に依存関係が確立されます。
マップに要素を保存する方法は次のとおりです。
最終セグメント<K、V> []セグメント。
一時的なSet <K> keySet;
transient Set <Map.Entry <K、V >> entrySet;
一時的なコレクション<V>値。
セグメントクラスとは何かを考えます。
static final class Segment <K、V>はReentrantLock実装を拡張します
シリアライズ可能{
private static final long serialVersionUID = 2249069246763182397L;
一時的な揮発性整数カウント。
transient int modCount;
一時的なintしきい値。
一時的な揮発性HashEntry <K、V> []テーブル。
最終フロートloadFactor;
セグメント(int initialCapacity、float lf){
loadFactor = lf;
setTable(HashEntry。<K、V> newArray(initialCapacity));
}
...
}
テーブル内のキーハッシュの擬似ランダム分布を考えると、セグメントの数を増やすと、変更操作が異なるセグメントに影響し、実行時のロックの可能性が低くなることが理解できます。
4. ConcurrencyLevel
このパラメータは、メモリカードの使用とカード内のセグメント数に影響します。
マップの作成と、パラメーターとして指定されたconcurrencyLevelコンストラクターがどのように影響するかを見てみましょう。
public ConcurrentHashMap(int initialCapacity、float loadFactor、int concurrencyLevel){
if(!(loadFactor> 0)|| initialCapacity <0
|| concurrencyLevel <= 0)
新しいIllegalArgumentException()をスローします。
if(concurrencyLevel> MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
//最もよく一致する引数の2のべき乗のサイズを見つける
int sshift = 0;
int ssize = 1;
while(ssize <concurrencyLevel){
++ sshift;
ssize << = 1;
}
segmentShift = 32-sshift;
segmentMask = ssize-1;
this .segments = Segment.newArray(ssize);
if(initialCapacity> MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if(c * ssize <initialCapacity)
++ c;
int cap = 1;
while(cap <c)
cap << = 1;
for(int i = 0; i <this .segments.length; ++ i)
this .segments [i] =新しいセグメント<K、V>(cap、loadFactor);
}
セグメントの数は、concurrencyLevelよりも大きい2のべき乗として選択されます。 各セグメントの容量は、それぞれ、取得されたセグメントの数に対して、2に最も近い程度に丸められたデフォルトのカード容量の比率として決定されます。
次の2つのことを理解することが非常に重要です。 concurrencyLevelを過小評価すると、マップセグメントのストリームが書き込み中にロックされる可能性が高くなります。 過剰な状態は、メモリの非効率的な使用につながります。
concurrencyLevelを選択する方法は?
1つのスレッドのみがマップを変更し、残りが読み取る場合は、値1を使用することをお勧めします。
マップ内のストレージ用のテーブルのサイズ変更は、追加の時間を必要とする(そして、多くの場合、高速ではない)操作であることを覚えておく必要があります。 したがって、マップを作成するとき、可能な読み取りおよび書き込み操作のパフォーマンスの統計の大まかな見積もりが必要です。
スケーラビリティの見積もり
javamexでは、synchronizedMapとConcurrentHashMapのスケーラビリティの比較
に関する記事を見つけることができます。
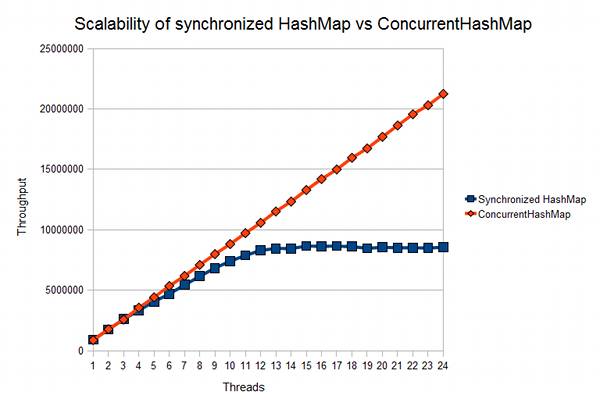
グラフからわかるように、カードへの500万から1000万のアクセス操作では、顕著な重大な不一致があります。
合計
したがって、ConcurrentHashMap実装の主な利点と機能:
- マップにはハッシュマップのような相互作用インターフェースがあります
- 読み取り操作はロックを必要とせず、並行して実行されます
- 多くの場合、書き込み操作はロックなしで並行して実行することもできます。
- 作成時に、読み取りおよび書き込み統計によって決定される、必要なconcurrencyLevelが指定されます
- マップ要素にvolatileとして宣言された値があります
結論として、ConcurrentHashMapは、カードへの読み取りと書き込みの比率の予備評価とともに、正しく適用されるべきだと言いたいと思います。 また、複数のストリームから保存されたマップへの複数のアクセスがないプログラムでHashMapを使用することも意味があります。
ご清聴ありがとうございました!
Javaの並列コレクション、特にConcurrentHashMapの作業に関する有用なリソース:
- www.ibm.com/developerworks/en/library/j-jtp07233/index.html
- stas-blogspot.blogspot.com/2010/08/concurrenthashmap-revealed.html
- www.codercorp.com/blog/java/why-concurrenthashmap-is-better-than-hashtable-and-just-as-good-hashmap.html