この投稿は
前の投稿の続きです。 予測監視は標準の監視方法ではありません。 したがって、通知は非常に標準的ではなく使用する必要があります。 これがどのように行われ、なぜそうなのかを検討してください。
通知はどうあるべきか
誰もが誰が毎日の仕事でどの監視システムを使用しているかに興味があると思います。 たとえば、
Dudeを使用します。 私たちは、最も重要なトランジットVoIPを除き、インフラストラクチャ全体を監視する方法を彼に教えました。 Dudeはデフォルトで、クライアントアプリケーションの実行時にメールとポップアップでアラートを送信する方法を知っています。 また、外部アプリケーションを使用してSMSを送信するように彼に教えました。 しかし、これはそれについてではありません。
監視システムからアラートが送信されると、アラート自体はどのノードで障害が発生したか、および監視されている値の最後の測定結果を示す必要があります。 たとえば、Router1のプロセッサの負荷が95%であるという通知を受け取る場合があります。 このようなアラート自体は、応答する必要がある速さを理解するのに十分な情報を提供します。 もう1つは、予測方法を使用して監視すると同時に、数千のパラメーターの状態を確認する場合です。
はい、アラートで最後の測定結果を報告できます。また、いくつかの最近の測定値の平均結果、またはちょうど1日前の測定値を表示することもできます。 しかし、これでは十分でない場合がよくあります。 この場合の最も効果的な通知方法は通知です。これは、一定期間の測定値のグラフを表示します。 チャートを一目見れば、潜在的な障害が重大であるかどうか、障害が実際に発生したかどうか、または誤検知であるかどうかを理解するのに十分です。
rrdtoolでの実装の詳細
以前の投稿で書いたように、rrdtoolが潜在的な障害(異常)の予測と識別を開始するには、rrdデータベースを正しく作成し、単に現在の値を入力する必要があります。 この構成では、測定値自体に加えて、ベースに別の値-FAILURESが自動的に入力されます。 FAILURESは、そのインデックスが測定が行われた時間(unixtime)である単純なハッシュです。 指標値は、測定値の異常の存在を示します。 簡単です。異常があり、FAILURESの値は1でしたが、ありませんでした-0。
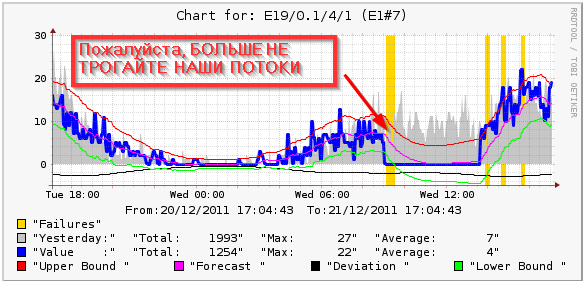
ただし、最後の測定後にFAILURES値を確認するだけでは不十分です。 実際には、異常は十分長く続く可能性があるため、グラフを見てください。
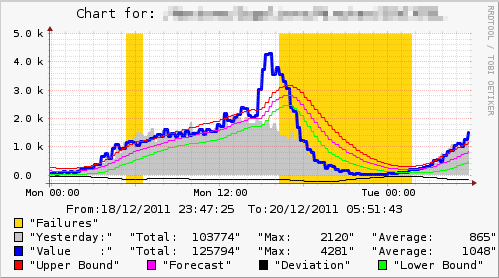
ほとんどの場合、監視システムは、異常が存在する間、値を測定するたびに警告を発すべきではありません。 ただし、場合によっては、これも実行する必要があります。 さらに、異常が解消した場合、これは問題が解決したことを意味するものではなく、システムが予測を新しい値に単純に調整する可能性があります。 実際の例は次の図にありますが、ストリームの問題は解決されておらず、異常はすでに終了しています。
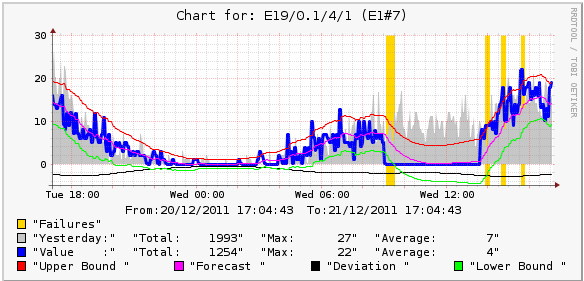
監視時の最も正確なIMHO予測は、異常が始まったときと終わったときに、スケジュールとともにアラートを送信することです。
どうやって
実際、スクリプトは:
これは前回の投稿で説明したスクリプトの修正であり、異常をチェックしてメールを送信する手順を追加しただけです。
PS私は、Pythonのソリューションの容量と美しさに驚かされるのに飽きていません。