SqlBulkCopyは、Microsoft SQL Serverテーブルにデータを大量にロードするための効果的なソリューションです。 データソースは、xmlファイル、csvファイル、またはMySQLなどの別のDBMSのいずれでもかまいません。 DataTableの形式でソースからデータを取得するか、データアクセスメソッドの上にIDataReaderインターフェイスを実装するだけで十分です。
BCPユーティリティを使用してさらにダウンロードするためにディスク上にファイルを作成する必要はありません。複数の
INSERT要求を生成するコードを記述する必要はありません。 データを読み込むとき、SqlBulkCopyは低レベルで動作するため、最短時間で何百万ものレコードを挿入できます。
問題
すべてが順調です
。SqlBulkCopyは非常に高速でクレイジーなので、データを挿入するときにトリガー、外部キー、その他の制限やイベントを無視します(必要に応じて有効にできます)。 また、複数のブロックのトランザクションにデータを挿入する方法も知っています。
ただし、
SqlBulkCopyは 、データのインポート時に発生する例外を処理できません。 少なくとも1つのエラー(キーの重複、NULL値の許容不能、キャスト不能)が発生した場合、彼は何も追加せずにジョブをすばやく終了します。
2つのタスクとその解決策を検討します。
1)SqlBulkCopyを任意のデータソースで使用する方法。
2)SqlBulkCopyを使用するときに発生する例外を回避する方法。
どこから始めますか?
DestinationTableNameプロパティに加えて、SqlBulkCopyクラスのオブジェクトには、重要な
BatchSizeプロパティ(サーバーに一度に読み込まれる行の数、デフォルトでは0で、すべてのデータが1つのパッケージに読み込まれます)があります。詳細については、
こちらを参照して
ください 。
2番目のパラメーターとして、SqlBulkCopyコンストラクターは
SqlBulkCopyOptions型の変数を受け入れることができます。挿入時にトリガー、制限を有効にする、またはNULL値を強制する必要がある場合はこれに注意してください。 デフォルトでは、これは存在しません。 このパラメータの可能な値については、
こちらをご覧ください 。
IDataReaderインターフェイスの実装
次に、任意のデータソースに
IDataReaderインターフェイスを実装する方法のより実用的な例を検討します。 この例では、csvファイルがデータソースとして機能します。 ここでのタスクは、データをSQL Serverテーブルにコピーすることです。
csvファイルから顧客をインポートするため、SQL Serverのテーブルは次のようになります。
T-SQLの顧客テーブルの構造。 CREATE TABLE [Customers]( [ID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [SecondName] [nvarchar](50) NOT NULL, [Birthday] [smalldatetime] NULL, [PromoCode] [int] NULL ) ON [PRIMARY]
csvファイルは次のようになります。 ;;04.10.1974;65125 ;;12.12.1962;54671 ;; ; ;;10.12.1981;4FS2FGA
データをインポートするときに、次の問題を解決する必要があることが明らかになりました。
- 正しいデータマッピングを確認します。 そのため、たとえば、SQL Serverテーブルとは異なり、CSVドキュメントの姓が最初にリストされます。 また、csvデータには、IDの値がありません。これは、自動的に更新される主要なキーです。
- データをSQL Server形式にし、無効なレコードを処理します。 csvドキュメントの最後の行を見てください。名前は含まれていませんが、SQLテーブルではこのフィールドは必須です。または、3番目の行で値が指定されていないため、smalldatetime型になりません。
SqlBulkCopyの仕組み
- SQL Serverデータベースに接続し、指定されたテーブルのメタデータを要求します。
- IDadaReaderインターフェイスのFieldCountプロパティを使用して列の数を取得します。
- ロード元(データソースのどの列からSQL Serverテーブルのどの列へ)をロードするかを計算します。
- Read()メソッドを呼び出し、 GetValue(int i)メソッドを使用してオブジェクトの形式で値を順番に取得します-これもIDadaReaderインターフェースです。
- Convert.ToInt32(オブジェクト値) 、 Convert.ToDateTime(オブジェクト)などのいずれかの変換メソッドを呼び出します 。 呼び出すメソッド-SqlBulkCopyは、テーブルメタデータによって決定されます。 変換メソッドが例外をスローした場合、ソースデータタイプはまったく興味がありません。ダウンロードは中断されます。
したがって、インポートするデータが理想からほど遠い場合(この例のように)、少なくとも正しいデータの一部を読み込むためにもう少し作業を行う必要があります。
働くために!
SqlBulkCopyのIDataReaderインターフェイスの実装は非常に簡単です。3つのメソッドと1つのプロパティを実装するだけで、残りはSqlBulkCopyオブジェクトによって呼び出されないため、必要ありません。 そしてそれは:
public int FieldCountデータソース(csvファイル)の列数を返します。 Read()を呼び出す前に、最初に呼び出されます。
パブリックbool読み取り()次の行を読み取ります。 ファイル/ソースの最後に到達していない場合はtrue-それ以外の場合はfalseを返します。
パブリックオブジェクトGetValue(int i)現在の行の指定されたインデックスを持つ値を返します。 Read()メソッドの後に常に呼び出されます。
public void Dispose()リソースを解放すると、SqlBulkCopyはこのメソッドを呼び出しませんが、常に便利です。
IDataReaderインターフェイスをサポートするcsvファイルを読み取るためのクラスの単純な実装。 using System.Data; using System.IO; namespace SqlBulkCopyExample { public class CSVReader : IDataReader { readonly StreamReader _streamReader; readonly Func<string, object>[] _convertTable; readonly Func<string, bool>[] _constraintsTable; string[] _currentLineValues; string _currentLine;
ConstraintsTable制約テーブル
2番目のパラメーター
constraintTableをコンストラクターに渡し、SqlBulkCopyがレコードを正しく処理できるかどうかを事前にすばやく判断するために使用されるメソッドへの参照の配列を渡しました。 各メソッドは対応する列の値を取得し、trueまたはfalseの結論を生成します。 少なくとも1つのメソッドがfalseを返す場合、行はスキップされます。 同様の関数の配列を作成する方法を考えてみましょう。
var constraintsTable = new Func<string, bool>[4]; constraintsTable[0] = x => !string.IsNullOrEmpty(x); constraintsTable[1] = constraintsTable[0]; constraintsTable[2] = x => true; constraintsTable[3] = x => true;
4つの列があるため、4つのメソッドがあります。 ラムダ式を使用して設定すると、より便利です。 最初のメソッドは、姓が有効かどうか(空またはNULLであってはならない)をチェックし、2番目のメソッドは同じことを行います。 SQlサーバーのテーブルのスキーマを覚えておいてください。姓と名をNULLにすることはできません。 他のメソッドはオプションフィールドであるため、常にtrueを返します。
ご注意 制約テーブルの使用を回避できますが、代わりに、SQL Serverテーブルのすべての列にNULL値を格納できるようにします。 これにより、データの挿入が高速になります。
ConvertTable変換テーブル
convertTableの3番目のパラメーターであるコンストラクターに、csvから受け取った値をSQL Serverが理解できる値に変換するために使用されるメソッドへの参照の配列を渡しました。 私たちの場合、SqlBulkCopy自体は同じ作業を実行できますが、例外を処理せず、変換が失敗した場合はNULL値を挿入できません。 彼の仕事を促進します。
var convertTable = new Func<object, object>[4];
姓と名は変換する必要はありません。 とにかくそれらは文字列値であり、それらの正確性は制約テーブルでチェックされます。 日付と数値を変換しようとしています。 例外が発生すると、
GetValue()メソッドでキャッチされます。
データマッピング
詳細が1つ残っています。 既定では、SqlBulkInsertはデータをそのまま、つまりソースの最初の列からSQL Serverテーブルの最初の列に挿入します。 この動作は必要ないため、
ColumnMappingsプロパティを使用して挿入順序を設定します。
次に、プログラムの課題が完全にどのように見えるかを見てみましょう。
using System; using System.Data; using System.Data.SqlClient; using System.Globalization; namespace SqlBulkCopyExample { class Program { static void Main(string[] args) {
その結果、Customersテーブルで次の結果が得られました。
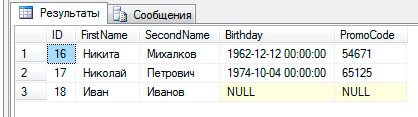
無効なエントリは追加されず、必要なタイプにキャストできない値はNULLとして挿入されました。
おわりに
データを挿入するときに発生する問題を処理する
IDataReaderインターフェイスでデコレータを実装することにより、csvファイルの例を使用してSQL Serverテーブルにデータをすばやく挿入できる
SqlBulkCopyをプログラムで使用する方法を検討しました。 実際のタスクでは、データ量は確かに多くなりますが、これらの場合、SqlBulkCopyも同様に機能します。
追加資料
マイクロソフトから大量のデータをダウンロード
するための
マイクロソフトの
ベストプラクティスについて説明します。
完全なコードは、 ここの 1つのリストで確認できます 。