すべては、単純なタスクから始まりました
rsyncを使用して、100メガバイトのネットワークを介して大量のデータをダウンロードします。 このプロセスを加速できるかどうかという疑問が生じました。 一番上のユーティリティは、暗号化がソースサーバーのプロセッサの10%を超えないことを示したため、データ圧縮を試みることができると判断されました。 その後、プロセッサに必要な速度でデータをパックするのに十分なパフォーマンスがあるかどうかが明確ではなかったため、最小の圧縮率が設定されました。つまり、
rsync --compress-level=1フラグ
rsync 。 プロセッサの負荷は65%を超えない、つまり、プロセッサのパフォーマンスは十分であり、データのダウンロード速度はわずかに増加することが判明しました。
その後、一般的な圧縮プログラムの適用性を分析するという疑問が生じました
ネットワーク経由でデータを転送します。
ソースデータの収集
最初のタスクは、分析のために初期データを収集することでした。 選択は、* nixの世界で広く普及している圧縮プログラムにかかっています。 すべてのプログラムは、標準のUbuntu 11.10リポジトリからインストールされました。
プログラムバージョンテストキーデフォルト
lzop 1.03 1、3、7-9 3
gzip 1.3.12 1-9 6
bzip2 1.0.5 1-9 9
xz 5.0.0 0-9 7
公式サイト:
lzop 、
gzip 、
bzip2 、
xzbzip2は
BWTアルゴリズムに基づいており、残りは
LZ77アルゴリズムとその修正に基づいています。
lzopの場合、2〜6の圧縮率は同じであるため、テストされていません。
テストシステムはIntel P8600ラップトップ(Core 2 Duo、2.4 GHz)でした
c Ubuntu 11.10 64ビットで実行される4 GBのRAM。
テストには、いくつかの異なるデータセットが使用されました。
- tarにパッケージ化された大規模なC ++プロジェクトopenfoam.comのソースコード。 これには、ソースコード、pdfドキュメント、および圧縮率の低い科学データが含まれています。
非圧縮容量:127641600バイト= 122 MiB
- tarにパッケージ化された大規模なparaview.orgプロジェクトのバイナリ配布。 主に.soライブラリファイルで構成されています。
非圧縮容量:392028160バイト= 374 MiB
- バイナリ科学データのセット。
非圧縮サイズ:151367680バイト= 145 MiB
さて、より「古典的な」セット:
- tarにパックされたLinuxカーネルヘッダー。
非圧縮容量:56657920バイト= 55 MiB
- tarにパッケージ化されたgccコンパイラのソースコード。
非圧縮容量:490035200バイト= 468 MiB
測定手順は次のとおりです。各プログラム、圧縮率、およびソースファイルについて、時間測定で圧縮が中間ファイルに行われ、圧縮ファイルのサイズが記憶され、
その後、開梱は時間測定で行われました。 念のため、解凍したファイルを元のファイルと比較し、中間ファイルと解凍したファイルを削除しました。
結果に対するディスクI / Oの影響を排除するために、すべてのファイルは
/run/shm配置されました(これはLinuxの共有メモリであり、ファイルシステムと同様に操作できます)。
各測定は3回実行されました。 その結果、最小時間の3が使用されました。
測定結果
結果は、パッキング時間-パックされたファイルのサイズの座標でグラフに表示されます。
図 1:gccコンパイラーソースの結果のグラフ:

図 2:ParaViewのバイナリ分布の結果のグラフ:
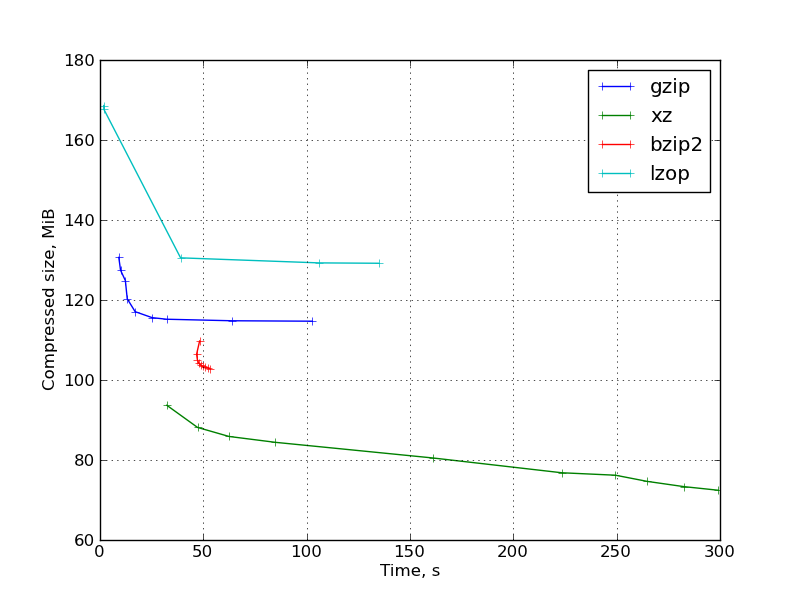
図 3:一連のバイナリ科学データの結果のグラフ:
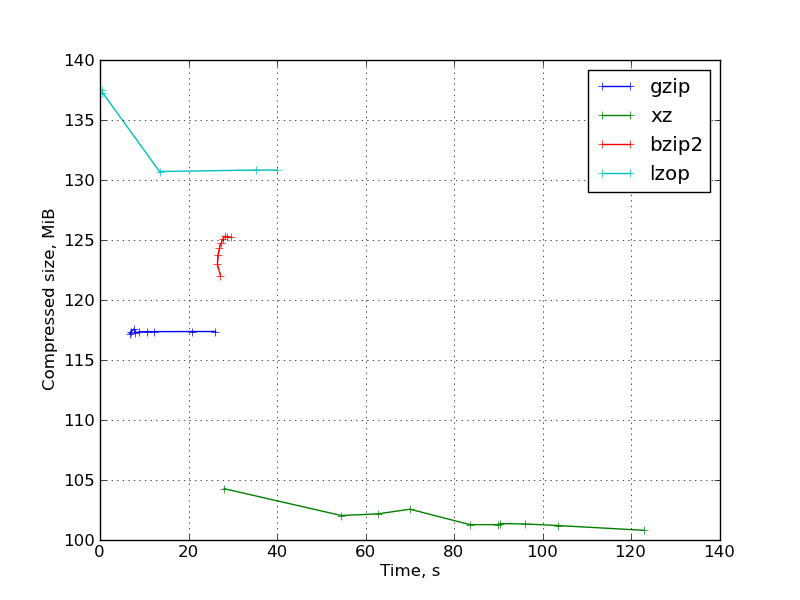
グラフ:
カーネルヘッダーと
OpenFoamソースコード 。
観察:
- 7〜9の圧縮率でのlzopは、ファイルサイズを大幅に削減することなく非常に遅くなり、gzipと比較して大幅に失われます。 これらのlzop圧縮率はまったく役に立ちません。
デフォルトの圧縮率では、lzopは予想どおり非常に高速です。 -1の圧縮率では、時間の増加はあまりなく、ファイルサイズが大きくなります。
- gzipは期待どおりに動作します。 圧縮率を変更するときのグラフの「正しい」形式。
- bzip2はそれほど競争力がありませんでした。 ほとんどの場合、圧縮率と低圧縮率xzの速度が低下します。 例外は、カーネルヘッダーと、それらが競合するgccソースコード(つまり、純粋なテキスト情報)です。 この観点から、bzip2がインターネット上でxzよりもはるかに人気があるのはかなり奇妙です。 これはおそらく、2番目のものが非常に若く、まだ「標準」になることができていないという事実によるものです。
また、さまざまなキーが圧縮率を変更し、bzip2ランタイムが非常に重要でないことも注目に値します。
- パラメータ値が高い場合のxzは高い圧縮率を示しますが、動作が非常に遅く、圧縮に非常に大量のメモリが必要です(-9で約690 MB、必要なメモリサイズはマナで示されます)。 展開するためのメモリのサイズははるかに小さいですが、それでも
一部のアプリケーションの制限。
実行時の圧縮率が小さいとgzip -9に近くなり、圧縮率が向上します。
一般的に、xzは圧縮率と時間の比率のかなり大きな選択を提供することがわかります。
- LZ-77に基づくプログラムの解凍はかなり迅速に行われ、圧縮率が上がると(同じプログラム内で)、解凍時間はわずかに減少します。
bzip2では、圧縮解除が遅くなり、圧縮率が高くなると圧縮解除時間が長くなります。
分析:シナリオ1-順次操作
ネットワークを介したデータ伝送のこのシナリオを検討してください。最初にデータをパックし、次にネットワークを介して伝送し、次にアンパックします。 合計時間は次のようになります。
t = t_c + s / bw + t_d
ここで、
t_cはパッキング時間、
sはパックされたファイルのサイズ(バイト)、
bwはネットワーク帯域幅(バイト/ s)、
t_dはアンパック時間です。
この式は、グラフの一定時間曲線を決定し、その勾配はネットワーク帯域幅によって決定されます。 特定の帯域幅に最適なパッキングアルゴリズムを決定するには、グラフ上の任意の点を通過する、目的の勾配を持つ最も低いラインを見つける必要があります。
つまり、最適な圧縮方法とその「切り替え」速度は、グラフ上の一連の点に接する直線によって決定されます。 それらを決定するだけです。
探しているのは、
凸包 (
eng。Convex hull)にすぎません。 多くのポイントの凸包を構築するために、多くの
アルゴリズムが開発されました。
ここから python実装を使用
しました 。
凸包の構築後、それに属する点は最適なアルゴリズムになり、それらを接続するエッジの勾配は境界帯域幅になります。
したがって、ファイルに最適なアルゴリズムを取得します。
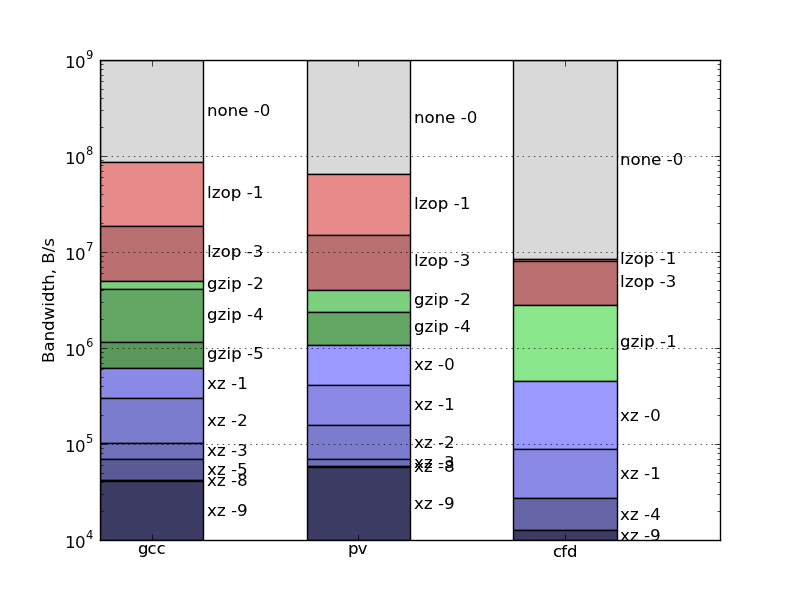
分析:シナリオ2-ストリーム圧縮
ここで別のシナリオを考えてみましょう。データはパッケージ化され、パッケージ化されるとすぐにネットワーク経由で送信され、受信側ではすぐにアンパックされます。
次に、合計データ転送時間は合計ではなく、最大3回(パッケージ化、展開、およびネットワーク経由の送信)によって決定されます。
選択したネットワーク帯域幅の一定時間曲線は、直線上の頂点を持つ角度のように見えます
t = s / bw
2本の光線が下から上に向かって左に向かっています。
この場合、最適な圧縮方法と境界帯域幅をすべて見つけることができるアルゴリズムがはるかに簡単です。 まず、ポイントを時間で並べ替えてから、最初の最適なポイントを選択します(これは、ゼロ時間の圧縮なしのポイントです。圧縮の不足は、帯域幅が無限のネットワークに最適です)。圧縮時間の昇順でポイントを並べ替えます。 ファイルサイズが以前の最良の方法のファイルサイズよりも小さい場合、現在の方法が新しい最良の方法になります。 この場合、境界帯域幅は、前の方法のファイルサイズを新しい方法の圧縮時間で割った値に等しくなります。
そのようなユースケースの結果は次のとおりです。

最終コメント
- 書かれたものはすべて、大量のデータを転送するシナリオにのみ適用され、他のシナリオ、たとえば多くの小さなメッセージを転送するシナリオには適用されません。
- この研究はモデル的な性質のものであり、実際の生活で発生するすべての特徴を完全に説明することを意図したものではありません。 それらのいくつかを次に示します。
- ディスクI / Oは考慮されません。
- 複数のプロセッサコアを使用することの存在と可能性は考慮されていません。
- サーバーアプリケーションの実行中に、別のプロセッサの負荷が同時に存在する可能性があり、圧縮のためのリソースが少なくなることは考慮されていません。
- Google snappyはこの調査には含まれていません。 これはいくつかの理由で起こりました。
- まず、ネイティブコマンドラインユーティリティがありません(実際、サードパーティのsnzipがありますが、標準と見なせるとは思いません)。
- 第二に、他のアプリケーションを対象としています。
- 第三に、lzopよりもさらに高速であることが約束されます。つまり、操作の時間を正確に測定することは非常に困難です。
実用例
短距離で大量の情報を配信するための最速のチャネルの1つは、ハードドライブを備えた自転車宅配便であることが知られています。
カウント。 距離を10キロメートルにします。 自転車宅配便は、1時間半で往復飛行を行います(通常のペースで、あらゆる種類の遅延、荷積みおよび荷降ろしを考慮に入れます)。 彼は、それぞれ1 TBのディスクを10個持っていきます。 その後、1日で60 TBを転送します。 これは、スループットが60 TB /(24 * 3600)s = 662 MiB / s(約5 Gb / s)の24時間ライン操作に相当します。 悪くない。結果は、ラップトップのコアと同様に、1つのコアでこのような通信回線のデータを圧縮しようとすると、圧縮しないことが最適であることを示しています。
ただし、1つのUSB 2.0ハードドライブにデータを転送する場合を考えると、転送側のみで費やされた時間を考慮すると、これは約30 MB /秒の速度のシナリオ2と似ています。
チャートを見ると、
lzop -3はテストデータセットの外部USBハードドライブにデータを転送するのに最適です。
最初に圧縮してから外部ドライブにコピーした場合、これはシナリオ1であり、
lzop -1は、ソースコードとバイナリ配布に費やされた合計時間の点で最適であり、圧縮率の低いバイナリデータ-圧縮なしです。
サイトリンク
- 同様の比較: http : //stephane.lesimple.fr/wiki/blog/lzop_vs_compress_vs_gzip_vs_bzip2_vs_lzma_vs_lzma2-xz_benchmark_reloaded
- 別の比較: http : //www.linuxjournal.com/node/8051/