先週、成功した実験が開始され、ダウンロードサービスの新しいソリューションが開始されました。 独自のJavaアプリケーションを実行するかなり控えめなサーバー(2 x Intel Xeon E5620、64 GB RAM)は8つのTomcatの負荷を引き継ぎ、3000 Mbpsの合計スループットで毎秒7万以上のHTTP要求を処理しました。 したがって、ユーザー絵文字に関連付けられているすべてのOdnoklassnikiトラフィックは、単一のサーバーによって処理されました。
当然、高負荷には非標準のソリューションが必要でした。 Javaでの高負荷サーバーの開発に関する一連の記事で、対処しなければならなかった問題と、それらをどのように克服したかについて説明します。 今日は、Javaヒープ以外の画像のキャッシュとJavaでの共有メモリの使用について説明します。
キャッシング
ストレージから各リクエストにイメージをプルするオプションではなく、イメージをディスクに保存することは問題ないため(ディスクキューがサーバーのボトルネックになる可能性がはるかに高くなります)、アプリケーションメモリに高速キャッシュが必要です。
キャッシュの要件は次のとおりです。
- 64ビットキー、バイト配列値:イメージ識別子はlong型の整数で、データは平均サイズ4 KBのPNG、GIF、またはJPGイメージです。
- インプロセス、インメモリ:アクセス速度を最大にするため、すべてのデータはプロセスメモリにあります。
- RAM使用率:使用可能なすべてのRAMはキャッシュの下に割り当てられます。
- ヒープ外: Javaヒープに50 GBのデータを配置することには問題があります。
- LRUまたはFIFO:廃止されたキーは、新しいキーに置き換えられる場合があります。
- 並行性: 100スレッドでのキャッシュの同時使用。
- 永続性:アプリケーションは、すでにキャッシュされているデータを保持しながら再起動できます。
Javaからヒープ外のメモリにアクセスする最も速い方法は、
sun.misc.Unsafeクラスを使用することです。 その
getLong/putLongメソッドはJVM組み込み関数です。つまり、それらの呼び出しは1つの機械語命令で文字通りJITコンパイラーに置き換えられます。 アプリケーションの起動間のキャッシュの永続性は、
メモリマップファイルを使用して実現
されます 。 ただし、キャッシュをディスク上の実際のファイルに関連付けたくありませんでした(ディスクにアクセスすることでパフォーマンスに深刻な影響を与えます)。したがって、アプリケーションのアドレススペースには実際のファイルは表示されず、
共有メモリオブジェクトが表示されます。 この場合、もちろんキャッシュは不揮発性ではなくなりますが、最も重要なことは、データを失うことなくアプリケーションを再起動できるようにすることです。
共有メモリ
Linuxでは、共有メモリオブジェクトは、
/dev/shmマウントされた特別なファイルシステムを介して実装されます。 したがって、たとえば、POSIX関数
shm_open("name", ...) 、
open("/dev/shm/name", ...)システムコール
open("/dev/shm/name", ...) shm_open("name", ...)同等
open("/dev/shm/name", ...) 。 したがって、Javaでは、通常のファイルのようにLinux共有メモリを操作できます。 次のコードスニペットは、サイズが1 GBのimage-cacheという名前の共有メモリオブジェクトを開きます。 同じ名前のオブジェクトが存在しない場合、新しいオブジェクトが作成されます。 アプリケーションが完了した後、オブジェクトがメモリに残り、次の起動時に利用可能になることが重要です。
RandomAccessFile f = new RandomAccessFile("/dev/shm/image-cache", "rw"); f.setLength(1024*1024*1024L);
ここで、作成されたファイルオブジェクトをプロセスのアドレススペースにマップし、このメモリロケーションのアドレスを取得する必要があります。
方法1.法的ですが、欠陥がある
Java NIO APIを使用します。
RandomAccessFile f = ... MappedByteBuffer buffer = f.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, f.length());
このメソッドの主な欠点は、2 GBを超えるファイルを表示できないことです。これは、Javadocマップメソッドで説明
されています。マップされる領域のサイズ。 負ではなく、Integer.MAX_VALUE以下でなければなりません。標準のByteBufferメソッドによって、またはリフレクションを使用してメモリアドレスを引き出すUnsafeを介して直接、受信したメモリを操作できます。
public static long getByteBufferAddress(ByteBuffer buffer) throws Exception { Field f = Buffer.class.getDeclaredField("address"); f.setAccessible(true); return f.getLong(buffer); }
このようなMappedByteBufferに
は、一般にアクセス可能なunmapメソッド
はありませんが、 GCを呼び出さずにメモリを解放するための準合法的な方法があります。
((sun.nio.ch.DirectBuffer) buffer).cleaner().clean();
方法2.完全にJavaで、ただし「秘密の知識」を使用する
Oracle JDKには、プライベートメソッド
map0および
sun.nio.ch.FileChannelImplを備えたクラス
sun.nio.ch.FileChannelImplがあり、2 GBの制限はあり
unmap0 。
map0は、「あふれた」サイトのアドレスを直接返します。これは、Unsafeを使用する場合にさらに便利です。
Method map0 = FileChannelImpl.class.getDeclaredMethod( "map0", int.class, long.class, long.class); map0.setAccessible(true); long addr = (Long) map0.invoke(f.getChannel(), 1, 0L, f.length()); Method unmap0 = FileChannelImpl.class.getDeclaredMethod( "unmap0", long.class, long.class); unmap0.setAccessible(true); unmap0.invoke(null, addr, length);
このようなメカニズムは、LinuxとWindowsの両方で機能します。 唯一の欠点は、ファイルが「マッピング」される特定のアドレスを選択できないことです。 キャッシュに同じキャッシュ内のメモリアドレスへの絶対リンクが含まれている場合、これが必要になる可能性があります。ファイルが別のアドレスに表示されると、そのようなリンクは無効になります。 2つの方法があります。ファイルの先頭からの相対位置に相対リンクを保存するか、JNIまたはJNAを介してネイティブコードを呼び出す方法です。 Linuxでは
mmapシステムコールを、Windowsでは
MapViewOfFileExを使用して、ファイルを「マップ」する優先アドレスを指定できます。
キャッシングアルゴリズム
キャッシュパフォーマンス、およびダウンロードサーバー全体の鍵は、キャッシュ検索アルゴリズムです。
getメソッド。 スクリプトの
putメソッドはそれほど頻繁に呼び出されませんが、遅すぎてもいけません。 連続した固定サイズのメモリ領域に高速のスレッドセーフFIFOキャッシュのソリューションを導入したいと思います。
すべてのメモリは同じサイズのセグメント-ハッシュテーブルバスケットに分割され、それに沿ってキーが均等に分散されます。 最も単純な形で
Segment s = segments[key % segments.length];
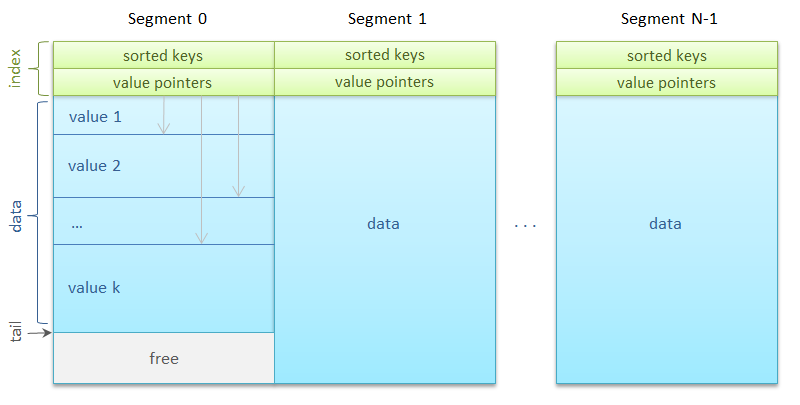
多くのセグメントが存在する可能性があります-数千。 それらはそれぞれ
ReadWriteLockマッピングされます。 同時に、無制限の数のリーダーまたは1人のライターのみがセグメントを操作できます。
興味深い詳細:標準の
ReentrantReadWriteLock'使用すると、Javaヒープで2 GBの損失が発生しました。 判明したように、JDK 6には
エラーがあり、
ReentrantReadWriteLockの実装で
ThreadLocalテーブルによる過剰なメモリ消費につながります。 バグはすでにJDK 7で修正されていますが、今回のケースでは、貪欲な
Lockを
Semaphore置き換えました。 ちなみに、ここに少し練習があります:
セマフォを使用してReadWriteLockを実装する方法は?セグメント。 インデックス領域とデータ領域で構成されています。 インデックスは、256キーの順序付き配列で、直後に同じ長さの256個の参照の配列が続きます。 リンクは、セグメント内のオフセットをデータブロックの先頭に設定し、このブロックの長さをバイト単位で設定します。

データブロック、つまり実際の画像自体は、最適なコピーのために8バイト境界に配置されます。 セグメントには、キーの数と
putメソッドの次のデータブロックのアドレスも格納されます。 循環バッファの原理に従って、新しいブロックが次々に書き込まれます。 セグメント内の場所がなくなるとすぐに、以前のデータの上にあるセグメントの先頭から記録が行われます。
getメソッドのアルゴリズムは非常に高速でシンプルです。
- キーハッシュは、検索が実行されるセグメントを計算します。
- インデックス領域では、バイナリ検索がキーを検索します。
- キーが見つかった場合、データが配置されているオフセットはリンクの配列から取得されます。
理由のキーは、選択した1つの領域の行に書き込まれます。これにより、インデックスをプロセッサキャッシュに配置し、バイナリキー検索の最大速度を実現できます。
putメソッドも簡単です。
- キーハッシュはセグメントの計算に使用されます。
- 次のデータブロックのアドレスが読み取られ、アライメントを考慮して記録されたオブジェクトのサイズを追加することにより、次のブロックのアドレスが計算されます。
- セグメントがいっぱいの場合、リンクの配列を介した線形検索は、次のブロックによってデータが上書きされるインデックスのキーを見つけて削除します。
- バイト配列で表される値がデータ領域にコピーされます。
- バイナリ検索は、新しいキーが挿入されるインデックス内の場所です。
作業速度
もちろん、私たちのものに加えて、Javaヒープの外部にデータをキャッシュするための無料および有料の両方のソリューションが他にもたくさんあります。 最も有名なのは、
Terracota Ehcache (インメモリオフヒープストレージ)と
Apache Java Caching Systemです。 独自のアルゴリズムを比較したのは、彼らと一緒でした。 実験はLinux JDK 7u4 64ビットで行われ、3つのシナリオで構成されました。
- put:各サイズが0〜8 KBの100万個の値を書き込みます。
- get:キーで100万の値を検索します。
- 90%get + 10%put:実際のキャッシュ使用シナリオと同様の比率でget / putを組み合わせます。
測定結果を表に示します。 ご覧のとおり、EhcacheとJCSの両方は、説明されているアルゴリズムよりもパフォーマンスが劣っている場合があります。

ただし、画像キャッシングの問題を解決するために設計された説明されたアルゴリズムは、他の多くのシナリオをカバーしないことに注意する価値があります。 たとえば、
removeおよび
replace操作は、簡単に実装できますが、以前の値で占有されていたメモリを解放しません。
どこを見ますか?
githubで共有メモリを使用するキャッシュアルゴリズムのソース:
https://github.com/odnoklassniki/shared-memory-cacheどこで聞きますか?
2012年7月25日に開催されるサンクトペテルブルクでの
JUG.RUミーティングで、
apanginはJavaで高負荷のサーバーを開発した経験を共有し、典型的な問題と型破りなテクニックについて話します。
次は?
次の記事では、1秒あたり何万ものリクエストを処理する
RPCサーバーの作成方法と、パフォーマンスとトラフィック量の点で標準のJavaメカニズムよりも数倍速い代替のシリアル化方法を説明します。 私たちと一緒にいてください!