この記事では、VHDLでプロセッサを自分で作成する方法を説明します。 多くのコードはありません(少なくともそうすることを望みます)。 完全なコードはgithubに投稿されており、そこにはいくつかの繰り返しの記述があります。
プロセッサは、
ソフトプロセッサのクラスに分類され
ます 。
建築
まず、プロセッサアーキテクチャを選択する必要があります。 プロセッサには
RISCアーキテクチャ、
ハーバードメモリ
アーキテクチャを使用します。
プロセッサには、2つの状態のパイプラインがありません。
- コマンドとオペランドの選択
- コマンドを実行して結果を保存する
4番目のプロセッサを記述しているため、スタックされます。 これにより、チームのビット深度が削減されます。 計算が実行されるレジスタのインデックスを保存する必要はありません。 操作のために、プロセッサーには2つの上位スタック番号があります。
データスタックとリターンスタックは分離されます。
FPGAには、18ビット* 1024セルの構成のブロックメモリがあります。 それに注目して、コマンドのビット容量を9ビットに選択します(2048個のコマンドが1つのメモリブロックに収まります)。
データメモリの容量は32ビットで「標準」である必要があります。
バスを使用して周辺機器との「通信」を実装します。
このすべての不名誉のスキームは、およそ次のようになります。

コマンドシステム
私たちはアーキテクチャーを決定しました。今度は「これらすべてで離陸してみてください」。 ここで、コマンドシステムを考え出す必要があります。
すべてのプロセッサコマンドは、いくつかのグループに分けることができます。
- スタックへのリテラル(数値)のロード
- 遷移(条件分岐、サブルーチン呼び出し、戻り)
- データメモリへのアクセス(読み取りおよび書き込み)
- バスへの呼び出し(意味はメモリへの呼び出しと同じです)。
- ALUチーム。
- 他のチーム。
したがって、チームには9つのカテゴリがあり、それらを満たす必要があります。
リテラルをダウンロードする
コマンドのビット深度はデータのビット深度よりも小さいため、数値をロードするメカニズムを考え出す必要があります。
リテラルをスタックにロードするために、次のコマンド形式を選択しました。
シニア、コマンドの8ビットは、数値ロードの兆候です。 残りの8ビットは、スタックに直接ロードされた数値です。
ただし、データ容量は32ビットであり、これまでにダウンロードできるのは8ビットのみです。
行に複数のLITコマンドがある場合、これは単一の数値をロードしていると見なされることに同意しましょう。 最初のコマンドは数値をスタックにロードし(展開して)、後続の各数値はスタックの最上位の数値を変更し、8ビットを左にシフトし、コマンドの値を下位部分に刻みます。 したがって、いくつかのLITコマンドのシーケンスにより、任意のビット数をロードできます。
任意のコマンド(NOPなど)を使用して、複数の数字を区切ることができます。
チームのグループ化
他のすべてのコマンドを簡単にデコードできるようにグループに分けることにしました。 スタックに影響する方法でグループ化します。
| ニーモニック | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|
| 点灯 | 0 | グループ | チーム |
|---|
チームのグループ:
| グループ | スタックから取得 | スタックをプッシュします | 例 |
|---|
| 0 | 0 | 0 | いや |
|---|
| 1 | 0 | 1 | 深さ |
|---|
| 2 | 1 | 0 | 落とす |
|---|
| 3 | 1 | 1 | DUP @ |
|---|
| 4 | 2 | 0 | !、OUTPORT |
|---|
| 5 | 2 | 1 | 算術(+、-、AND) |
|---|
遷移:
| ニーモニック | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|
| Jmp | 0 | 2 | 0 |
|---|
| 電話する | 0 | 2 | 1 |
|---|
| IF | 0 | 4 | 0 |
|---|
| レット | 0 | 0 | 1 |
|---|
JMPおよびCALLコマンドは、スタックからアドレスを取得し、それを超えます(呼び出しにより、対応するスタックに戻りアドレスが追加されます)。
IFコマンドは、遷移アドレス(スタックの一番上の番号)と遷移フラグ(次の番号)を取ります。 符号がゼロに等しい場合、アドレスへの移行が実行されます。
RETチームはリターンスタックを操作し、一番上の数字を選んでそれを調べます。
コマンドが遷移ではない場合、コマンドカウンターは1ずつ増加します。
コマンド表
コマンドを説明するには、次のような
スタック表記を使用しました。
<単語実行前のスタック状態>-<実行後のスタック状態
言葉>スタックの一番上は右側、つまり 2 3-5と書くと、単語が完成する前に
スタックの一番上は3番で、その下は2番でした。 これらの番号を実行した後
削除されたことが判明し、それらの上に番号5がありました。
例:
DUP(a-aa)
ドロップ(ab-a)
少なくとも何かを実行できる最小限のコマンドセットを使用してください。
| H \ l | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| 0 | いや | レット | | | | | | | | |
|---|
| 1 | TEMP> | 深さ | RDEPTH | デュプ | 以上 | | | | | |
|---|
| 2 | Jmp | 電話する | 落とす | | | | | | | |
|---|
| 3 | @ | 輸入 | ない | SHL | SHR | シュラ | | | | |
|---|
| 4 | IF | ! | アウトポート | | | | | | | |
|---|
| 5 | ニップ | + | - | そして | または | Xor | = | > | < | * |
|---|
| チーム | スタック表記 | 説明 |
|---|
| いや | | 操作なし。 1つのプロセッサレイテンシ |
| 深さ | -D | この単語を実行する前にデータスタックに数字の数を積み重ねる |
| RDEPTH | -D | この単語を実行する前に、リターンスタックに数字の数を積み重ねる |
| デュプ | A-AA | 重複したトップ番号 |
| 以上 | AB-ABA | 上の2番目の数値の先頭にコピーします |
| 落とす | A- | トップ番号を削除 |
| @ | A-d | アドレスAのデータメモリの読み取り |
| 輸入 | A-d | アドレスAのバスからデータを読み取る |
| ない | A-0 | -1 | 論理否定のトップ番号(0は-1に置き換えられ、他の番号は0に置き換えられます) |
| SHL | A-B | 最上位の数値を1ビット左にシフトします |
| SHR | A-B | 上の数字を1桁右にシフトします |
| シュラ | A-B | 最上位の数値を1桁右に算術シフトします(数値の符号は保持されます) |
| ! | DA- | アドレスAのデータDをデータメモリに書き込む |
| アウトポート | DA- | アドレスAのデータDを「バス」に書き込む(iowr信号は1クロックサイクルに設定され、周辺機器はこの信号の高レベルでアドレスを「キャッチ」する必要があります) |
| ニップ | AB-B | スタックの先頭から2番目の番号を削除します(番号はTempRegレジスタに保存されます) |
| TEMP> | -A | TempReg Registerコンテンツの取得 |
| + | AB-A + B | スタックのトップ番号 |
| - | AB-AB | 上から2番目の数字からの減算 |
| そして | AB-AおよびB | ビット単位のAND高さ |
| または | AB-AまたはB | 上位の数値のビット単位のOR |
| Xor | AB-A xor B | 上位の数値のビットごとのXOR |
| = | AB-0 | -1 | 上位の数値の等価性の検証。 数値が等しい場合、スタックに-1を残し、そうでない場合は0 |
| > | AB-0 | -1 | 上位の数値の比較。 A> Bの場合、スタックに-1を残し、そうでない場合は0を残します。符号を考慮した比較 |
| < | AB-0 | -1 | 上位の数値の比較。 A <Bの場合、スタックに-1を残し、そうでない場合は0を残します。符号を考慮した比較 |
| * | AB-A * B | 上限数の乗算 |
1つのプロセッサクロックサイクルでスタックに1つの数字を書き込むことができます。 スタックの上位2つの数字を交換する
SWAPコマンドがフォートにあります。 実装するには、2つのチームが必要です。 最初のコマンド
NIP (ab-b)は、2番目の数字「a」を先頭から削除して一時レジスタに保存し、2番目のコマンド
TEMP> (-a)はこの番号を一時レジスタから抽出してスタックの先頭に置きます。
コーディングを始める
メモリの実装。
コードおよびデータメモリは、テンプレートを介して実装されます。
process(clk) if rising_edge(clk) then if WeA = '1' then Ram(AddrA) <= DinA; end if; DoutA <= Ram(AddrA); DoutB <= Ram(AddrB); end if; end process;
Ramは、次のように宣言されたシグナルです。
subtype RamSignal is std_logic_vector(RamWidth-1 downto 0); type TRam is array(0 to RamSize-1) of RamSignal; signal Ram: TRam;
メモリは次のように初期化できます。
signal Ram: TRam := (0 => conv_std_logic_vector(0, RamWidth), 1 => conv_std_logic_vector(1, RamWidth), 2 => conv_std_logic_vector(2, RamWidth),
同様のテンプレートを介して実装されたスタック
process(clk) if rising_edge(clk) then if WeA = '1' then Stack(AddrA) <= DinA; DoutA <= DinA; else DoutA <= Stack(AddrA); end if; DoutB <= Stack(AddrB); end if; end process;
メモリテンプレートとの唯一の違いは、記録された値を出力に「転送」することです。 前のテンプレートでは、記録された値は、記録後の次の測定で取得されます。
シンセサイザはこれらのパターンを自動的に認識し、対応するメモリブロックを生成します。 これはレポートに表示されます。 たとえば、データスタックの場合、次のようになります。
----------------------------------------------------------------------- | ram_type | Distributed | | ----------------------------------------------------------------------- | Port A | | aspect ratio | 16-word x 32-bit | | | clkA | connected to signal <clk> | rise | | weA | connected to signal <DSWeA> | high | | addrA | connected to signal <DSAddrA> | | | diA | connected to signal <DSDinA> | | | doA | connected to internal node | | ----------------------------------------------------------------------- | Port B | | aspect ratio | 16-word x 32-bit | | | addrB | connected to signal <DSAddrB> | | | doB | connected to internal node | | -----------------------------------------------------------------------
完全なメモリ実装コードを提供するのは理にかなっていないと思います。実際、定型的なものです。
プロセッサのメインサイクル-最初のクロックサイクルでチームがサンプリングされ、2番目で実行されます。 プロセッサのクロックを決定するために、フェッチ信号が作成されます。
process(clk) begin if rising_edge(clk) then if reset = '1' then
コマンドをデコードおよび実行するための最も簡単なオプションは、すべてのオプションの大きな「ケース」です。 記述しやすいように、複数のコンポーネントに分割することをお勧めします。
このプロジェクトでは、3つの部分に分けました。
- データスタックのアドレスを生成し、書き込み信号を生成するケース。
- チームのパフォーマンスの場合;
- 新しいコマンドカウンター(ip)を形成する場合。
サンプルはチームの一部であり、下位4ビットは使用されません。
宣言されたすべてのチームグループがペイントされます。 このケースは、チームの新しいグループが表示された場合にのみ変更する必要があります。
次のケースは、チームの実行を担当します。 データスタックのデータ(トートロジーについては申し訳ありません)、OUTPORTコマンドのiowr信号などを形成します。
これまでに実装されたチームは2つだけです。 スタックに数値をロードし、スタックの上位2つの数値を追加します。 これは「アイデアをテスト」するのに十分であり、これら2つのチームが機能する場合、残りのほとんどは「テンプレートに従って」問題なく実装されます。
最後のケースは、コマンドカウンターの次のアドレスの形成です。
基本的な移行コマンドを実装しました。 遷移アドレスはスタックから取得されます。
テスト中
先に進む前に、すでに記述されたコードをテストすることをお勧めします。 最初の100 nsでプロセッサにリセット信号のみを入力するTestBenchを作成しました。
コードメモリは次のように初期化されました。
signal CodeMemory: TCodeMemory := ( 0 => "000000000",
最初に、いくつかの数字が入力され、追加操作がテストされ、DROPコマンドでスタックがクリアされます。 次に、遷移、サブルーチン呼び出し、および戻り値がテストされます。
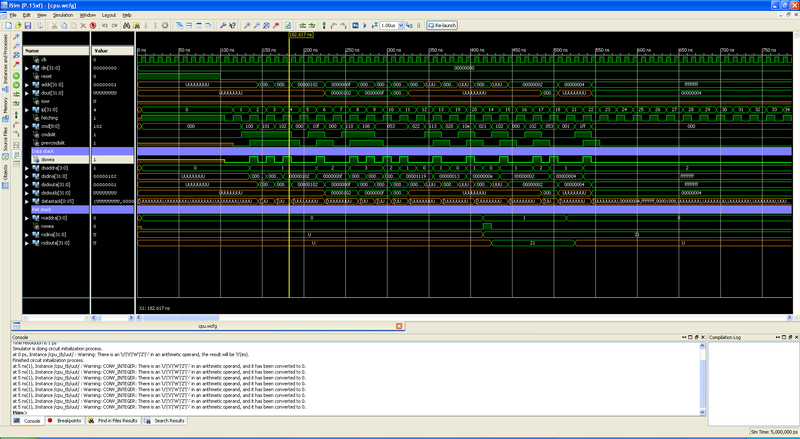
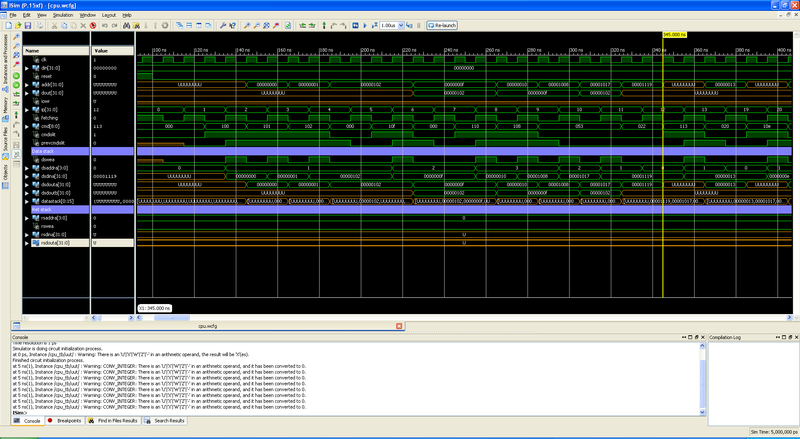
シミュレーション結果は、次の図に示されています(クリック可能)。
テスト全体:
数値ロードテスト:
ロード数の解析
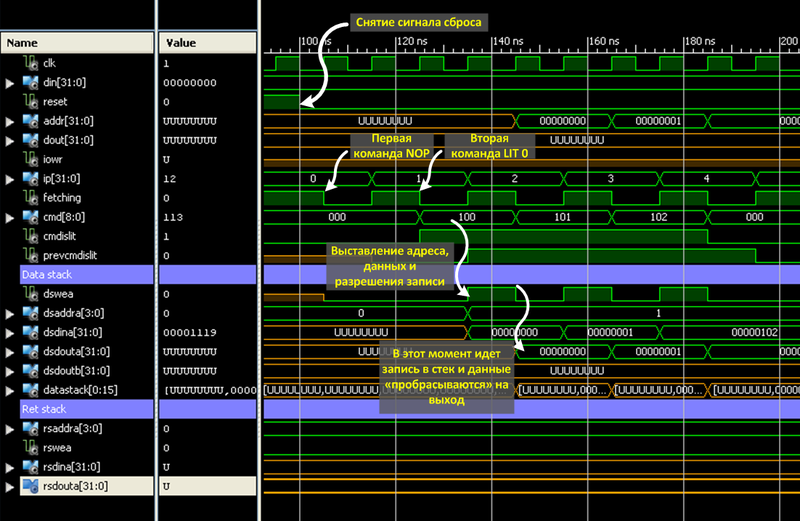
図は、Lit 0コマンドの実行を示していますリセット信号を削除すると、コマンドカウンターはゼロ(ip = 0)になり、コマンドフェッチフェーズ(fetching = '1')にあることがプロセッサに通知されます。 最初の測定では、サンプリングが実行されます。 最初のNOPコマンドは、コマンドカウンターを増やすだけです(ただし、不明なコマンドはコマンドカウンターを増やします。また、配置されているグループによっては、データスタックで何かを行うこともできます)。
コマンド#1は、数値0をスタックにロードしています。 実行ステップで3つの信号が設定されます。データスタックのアドレスが1増加し、データが設定され、書き込み許可信号が設定されます。
次のサンプリングサイクルで、値「0」がアドレス「1」のスタックに書き込まれます。 また、値はすぐに出力に「転送」されます(次のコマンドが新しい値で動作するように)。 書き込みイネーブル信号が削除されます。
コマンド#2は、スタックに数値をロードするコマンドでもあります。 なぜなら LITコマンドに続き、新しい番号はスタックにロードされませんが、一番上の番号は変更されます。 8ビット左にシフトされ、下部にはコマンドの値(0x01)が書き込まれます。
コマンド#3は、コマンド#2と同じ操作を実行します。 操作後のスタック上の番号は0x0102です。
おわりに
最初のチームがテストされます。 残りのほとんどすべてのコマンドは、ステレオタイプの方法で記述されています(「円を描く、フクロウの残りを描く」)。
この記事の目的は、プロセッサーを自分で作成できることを示すことであり、少なくともある程度はそれをしたことを願っています。 次のステップは、この記事がhabrasocietyにとって興味深いものである場合、ブートローダーとクロスコンパイラーを作成することです。
Githubプロジェクト:
github.com/whiteTigr/vhdl_cpuCPUコード:
github.com/whiteTigr/vhdl_cpu/blob/master/cpu.vhdテストベンチコード(実際には何もありませんが):
github.com/whiteTigr/vhdl_cpu/blob/master/cpu_tb.vhd