現在、habrは引き続きエンティティ(レコード、投稿、コメント)の並べ替えと評価について議論しているので、私自身がそれに興味を持ち、redditに興味を持ち、並べ替えがどのように機能するかを調べることにし、優れた短い記事に出会いました。
この投稿は、ソートアルゴリズムの分析の続きです(前回は
Hacker Newsでした)。 今回は、
Redditでの投稿とコメントの並べ替えの仕組みを見ていきます。 Redditのアルゴリズムは、理解して実装するのに十分簡単です。
この投稿の最初の部分は投稿の並べ替えに焦点を当て、2番目はコメントの並べ替えに焦点を当てます。 それらはかなり異なり、Randall Munroe(xkcd)はコメントをソートする方法のアイデアの背後にあります。
投稿の並べ替えを並べ替えます
Redditはオープンソースプロジェクトであり、そのコードはgithubで完全にアクセス可能です。 これはpythonで書かれてい
ます 。ソースコードは
こちらで確認でき
ます 。 ソートアルゴリズムは、Cコードへのコンパイル(翻訳)のためにPyrexで記述されています。 Pyrexはパフォーマンスのために選択されました。 読みやすくするために、純粋なpythonで実装を書き直しました。
「ホットランキング」と呼ばれるデフォルトのソートアルゴリズムは、次のように実装されます。
数学表記では、このアルゴリズムは次のようになります。

老化記録
並べ替えの評価(以下、単に評価)と並べ替えに関する陳腐化について説明します。
- 記事の年齢は、彼女の評価に大きな影響を与えます。新しいほど、彼女の評価は高くなります。
- 古くなった記事では評価は下がりませんが、新しい記事で評価は上がります
以下は、同じ数のプラスとマイナスで記事の評価がどのように見えるかを視覚化したものですが、公開時間は異なります。

対数目盛
ホットランキングでは対数を使用するため、最初のn票は将来のn + r票よりも重くなります。 その結果、最初の10個のプラスは次の100個と同じ重みを持ち、次の1000個と同じ重みを持つことがわかります。
これは次のようなものです。

そして、これは対数なしのようになります:

「短所」の影響
Redditは、マイナスにできるサイトの1つです。 コードで見たように、投稿の「スコア」は長所と短所の差に等しくなります。
最終的には、次のようになります。

これは、賛否両論の多い投稿(いわゆる物議を醸す投稿)に大きな影響を与え、プラスのみの投稿よりも低い評価を得ます。 これがおそらく、子猫がメインの子猫に頻繁にいる理由です:)(おおよそ。-実際、これはあなたが/ r / awwから退会しなかったからです)
ソート後の結論
- 時間を追加することは非常に重要なパラメーターです。新しい投稿は高い評価を得ます
- 評価曲線は、10の対数に基づいて作成されます。 最初の10個のプラスは次の100個に等しい
- 長所と短所の両方を受け取った物議を醸す投稿は、単なる「プラス」投稿よりも低くなります
コメントの並べ替えの仕組み
XkcdのRandall Munroeは、Redditの最高ランキングのアイデアの背後にあります。 彼はこれについて素晴らしい記事を書いた:
redditの新しいコメント分類システムこの記事を読んでください。アルゴリズムの原理を非常に明確に説明しています。 要約すると、次のように言えます。
- ホットランキングアルゴリズムは、投稿の年齢に大きく依存しているため、コメントの評価には適していません。
- コメントには、送信されたタイミングに関係なく、上記の最高のコメントを入力する必要があります
- この解決策は1927年にエドウィンウィルソンによって発見され、「ウィルソンスコア間隔」と呼ばれました。ウィルソン間隔は「信頼によるソート」に使用できます。
- 信頼でソートされた場合、総投票数は、意見投票のように、それぞれからの仮想の完全投票の統計サンプルとして提示されます
- 平均評価でソートしない方法 -信頼性評価アルゴリズムについてよく説明しています。読むことを強くお勧めします。 (約。- habrに関する良い記事もあります )
コメントソートコードを調べる
信頼ソートアルゴリズムは
_sorts.pyxに実装されて
おり 、純粋なpythonに書き直しました(そしていくつかのキャッシュ最適化を削除しました)。
信頼ソートはウィルソン区間を使用し、数学表記は次のようになります。
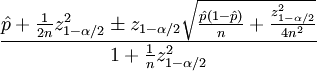
この式のパラメーターのリスト:
- p-肯定的な評価のシェア
- n-投票総数
- zα / 2は、標準正規分布の(1-α/ 2)分位数です。
上記を要約しましょう:
- 信頼性ソートは、投票数を、それぞれの仮想の完全投票の統計サンプルとして表します
- 機密性のソートにより、コメントの予測可能な評価が得られ、85%の確率で受け取ることができます
- 投票数が多いほど、推定評価は実際の評価に近づきます
- ウィルソンの間隔は、少数の票および極端な確率の場合にも適しています
Randallには、コメントの評価方法の優れた例があります。
コメントにプラスマイナス1つとマイナス0つがある場合、100%の評価が付けられますが、データが少なすぎるため、システムはそれを抑えます。 しかし、彼が10プラスと1マイナスしかない場合、システムは40プラスと20マイナスのコメントの上に置くために十分な信頼(自信)を持つことができます。 20短所 そして、最良の部分は、これが間違っていても(ケースの15%で発生する)、システムはすぐに多くのデータを取得し(悪いコメントが一番上にあり、それが表示され、zinnushenyになるため)、コメントはどこに行くべきかです
ご覧のとおり、このアルゴリズムは、レコードの陳腐化による影響を受けません。
それがどのように見えるか見てみましょう:

ご覧のように、このソートはコメントが投票数を受け取ったのではなく、投票の総数とサンプルのサイズに関連してプラスがいくつあったかを心配します。
エヴァンミラーが指摘したように、ウィルソン区間は評価だけでなく使用できます。
彼が与えた3つの例を次に示します。
- スパムを検出する:これを見る人の何パーセントがこれをスパムとしてマークしますか?
- 「ベスト」リストの作成:これを見る人の何パーセントが「ベスト」とマークされていますか?
- 「最も電子メールで送信された」リストの作成:このページを見た人の何パーセントが「電子メール」をクリックしますか?