こんにちは。
本番環境からほとんど中断することなく、負荷下で
MySQL 5.0から
Percona Server 5.5に戦闘データベースを移行した経験を共有したいと
思います 。
基地の現在の状態への進化を簡単に説明します
私たちのベースは古く、いくつかの
MySQLアップグレードを生き延びました。
MySQL 3.xで開始しました
。 既に
MySQL 5.0で負荷が増加したため、レプリケーションを構成し、読み取り用に別のサーバーを接続しました。 次に、
xtrabackupを使用せずに標準の
MySQLツールを使用してこれを行いました。サイトでマスターダンプとポストスタブを作成するときにサーバーを完全にブロックしました。
その後、次の問題が発生しました-データボリューム上で場所が不足し始めました。 さらに、
InnoDBストレージは従来、単一のファイルに配置されていました。 多くのオプションが検討されています。 データベースを
iSCSIボリュームに配置してから、より容量の大きいディスクをRAIDにドラッグし、
ボリュームグループ/論理ボリュームでそれらを拡張してからファイルシステムを拡張することで終わります。
一時的なオプションとして、
VMWare vCloudの下で仮想マシンから
iSCSIボリュームを接続することにしました(
正直に言って、広告ではありません! )。
vCloudはすぐ隣にあります。
奴隷の実験から始めました。 この実験は成功し、しばらくの間、2番目の
読み取り専用 MySQLが
iSCSIボリューム上のストレージを保持しました。
彼らは基地を完全にクラウドに移行することを真剣に考え始めました
実験として、
vCloudのサーバーを2番目の読み取りスレーブに接続しました。 すべての負荷を最初のスレーブからそれに転送しました。 パフォーマンスの面では、仮想サーバーがかなりのマージンで勝ちました。
vCloudホストのより強力なハードウェアの影響を受けます。 負荷を元に戻します。 彼らは考え始めました。
この瞬間、奇妙な神秘的な出来事が起こりました。 仮想サーバーへの負荷の実験が完了してから数時間後、データセンターで厄介な事故が発生し、その結果、物理スレーブを含む複数のサーバーの電源が切れました。 物理スレーブの
iSCSIボリュームにあるリレーログがガベージを取得しました。 レプリケーションが停止しました。
この状況で最も論理的なアクションは、クラウドスレーブへの切り替えでした。
したがって、
vCloudではすでに1つの
読み取り専用の足でした。
masterをドラッグする必要がありました。
彼らは、
Percona 5.5に
移行し、
InnoDBストレージの表形式パーティションを使用して、2台のサーバーにも
移行することにしました。
移動中の主な制限は、任意の時間ベースを停止できないことでした。
InnoDBストレージをテーブルにパーティション化することについて話しているため、単にデータをコピーするだけでは機能しません。 ダンプから新しいベースを注入する必要があります。
マスターダンプを取得するには、
125ギガバイトのベースを1時間以上ロックする必要があります。 これは戦闘基地では受け入れられません。
xtrabackupを使用してマスターをバックアップし、結果のキャストでサーバーを上げ、そこからマスターダンプを削除することにしました。
だから、成分
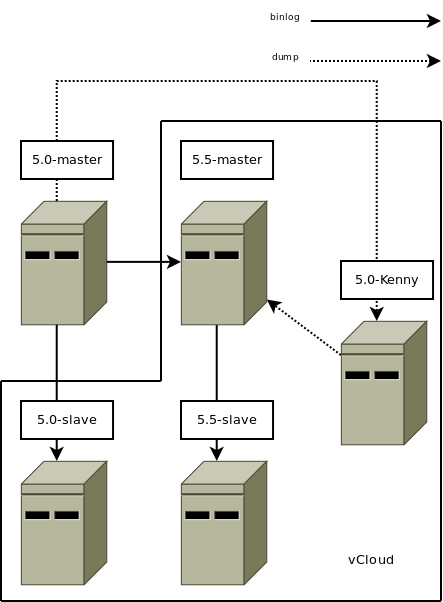
- 負荷がかかっている2つの古いMySQL-5.0戦闘サーバー。 5.0-masterおよび5.0-slaveと呼びます。
- これまでの2つの新しい戦闘Percona-5.5サーバーは、負荷、データ、複製なしでこれまでにありません。 それらを5.5-masterおよび5.5-slaveと呼びます。
- ダンプダンプ用の1つの中間MySQL-5.0サーバー。 5.0-Kennyと呼びましょう。
InnoDBストレージを新しいサーバー上のテーブルに分割するには、オプション「
innodb_file_per_table = 1 」を設定する必要があります。
これはクラウドであるため、5分間で3台のサーバーが不足していることをふざけて確認します。
ダウンタイムを最小限に抑えるプログラムの一環として、新しいマスターで動作するようにアプリケーションを再構成せずに、新しいサーバーで古いマスターの
IPを単純に上げることにしました。 これを行うに
は、古いサーバーの
IPがすべてのクライアントの新しいウィザードで表示される必要があります。 この例では、5つのサーバーすべてが同じサブネット上にあるため、これに問題はありません。
そして今-アクションのシーケンス
- マスターベース( 5.0-master )から、 xtrabackupを使用してダンプを削除します 。
innobackupex --user=root --password=Yoo0edae ___
MyISAMテーブルはデータベースのデータ量が多いほど、最終データベースロック中にMyISAMテーブルが完全にコピーされるため、 xtrabackupのファイナライズ中にデータベースがロックされる時間が長くなることに注意してください 。 この場合、 MyISAMデータは実質的に存在しないため、データベースは数秒間だけロックされた状態になります。 - 結果のデータディレクトリには、ファイル「 xtrabackup_binlog_info 」があります。 これから 、binlog内の位置を覚えています。
- 結果の印象は5.0-Kennyにコピーされます( 5.0-Masterの NFSを介してKennyドライブをマウントし、 xtrabackupがデータを取り出したときに宛先ディレクトリに示したため、 xtrabackupの作業中に5.0-Kennyのデータが表示されました )。 そこで準備します 。
innobackupex --apply-log ____
- MySQLを停止します 。 MySQLデータでディレクトリをクリーンアップし、ナゲットをコピーします:
innobackupex --copy-back ____
手動でコピーできます。 その後、 MySQLストレージにバックアッププロセスからのゴミが残ります。 必要に応じて、適切な所有者をデータディレクトリに配置します。 - MySQLを起動します 。 エラーがないことを確認します。
- 5.0-Kennyでは、ダンプを削除します。
mysqldump --all-databases > mysql.dump
- 結果のダンプを5.5-masterにコピーします。 注ぐ:
mysql < mysql.dump
- MySQLを再起動します 。 ログのエラーの山を賞賛します。 回路をバージョン5.5にアップグレードします。
mysql_upgrade --force
- MySQLを再起動します 。 ログはきれいなはずです。
- レプリケーションを有効にし、 5.5マスターを5.0マスター binlogに接続します。 これを行うには、まず5.0マスターでレプリケーション用のユーザーを追加します(誰でもserver-idを覚えていますか?):
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_master_55' IDENTIFIED BY 'slavepass'; mysql> FLUSH PRIVILEGES;
その後、 5.5-masterでリクエストを実行します。
mysql> CHANGE MASTER TO MASTER_HOST='master_host_name', MASTER_USER='repl_master_55', MASTER_PASSWORD='slavepass', MASTER_LOG_FILE='recorded_log_file_name', MASTER_LOG_POS=recorded_log_position; mysql> START SLAVE;
値MASTER_LOG_FILEおよびMASTER_LOG_POSは 、ファイル「 xtrabackup_binlog_info 」から取得されます。 - 複製がなくなったことを確認します。
mysql> SHOW SLAVE STATUS\G
5.5マスターは、しばらくの間5.0マスターのスレーブになります。 5.0-masterからのリクエストが5.5-masterの binlogに到達するには、オプション " log-slave-updates = 1 "を5.5-masterに設定する必要があります。 デフォルトではゼロです。つまり、ローカルの変更のみがbinlogに入ります。 - xtrabackupを使用して5.5-masterダンプから削除します。 ダンプを5.5-slaveにコピーします。
- 5.5-slaveを上げて、 5.5-master binlogにフックします。
合計で、4台のサーバーを取得します。2台は古いが、まだ
MySQL 5.0と戦ってい
ます 。2台の新しい
Percona 5.5は現在のデータを使用しています。
- 読み取り専用のロード全体を古い5.0スレーブから新しい5.5 スレーブに切り替えます。 5.5-slaveは 5.5-masterで複製され、さらに5.0-masterで複製されるため、誰も気付かないでしょう。 仕事の半分は完了しました-すでに新しい束にかかっている負荷の一部です。
楽しみが始まります。
マスターを切り替えます。 ここに戻りのないポイントがあります。 この瞬間から、マスターベースのダウンタイムに注目します。
- 5.0-masterで MySQLを停止します 。
- binlogのすべてのデータが5.5マスター上にあることを確認します
- binlogからの5.5マスターの離脱:
mysql> RESET SLAVE ALL;
- 5.5-masterで MySQLを停止します
- 5.0-masterでは、アプリケーションがデータベースと通信するためのネットワークインターフェイスを配置し、 5.5-masterがあるサーバーでこのIPを上げます。
- arpテーブルが更新されていることを確認します。
- 5.5-masterを上げます。 MySQLが新しいIPでリッスンしていることを確認してください。
- データベースへの永続的な接続を使用してアプリケーションを再起動します。
全部
私たちの場合、ダウンタイムは約1分半でした。 この時間のほとんどは
5.0-masterでした。 原則として、データベースを停止する前に
InnoDBキャッシュをドロップすることで、ダウンタイムをさらに削減できました。
vCloudは良い仕事をしました。 仮想ディスクは多数の物理メディアによって「スミア」されるため、より強力なハードウェアとはるかに高速なディスクサブシステムにより、移動時のパフォーマンスが大幅に向上しました。