「Lift mi Up」ネットワークは、そのスタッフと一緒に、全体にわたって成長しています。 ITインフラストラクチャのメンテナンスは、特別に作成された別の組織「Link mi Up」で実施されました。
先日、さまざまな都市でさらに4つの支店が購入され、投資家はエレベーターの動きの新しい次元を発見しました。 また、ネットワークは4つのルーターから一度に10に成長しました。 サブネットの数が9から20に増えました。ルーター間のポイントツーポイントリンクはカウントされません。 そして、このすべての経済の完全な管理が高まります。 各ノードで手動ですべてのネットワークにルートを追加するのは面白くないことに同意する必要があります。
カリーニングラードのネットワークには既に独自のアドレス指定があり、EIGRP動的ルーティングプロトコルが起動されているため、状況は複雑です。
今日は:
-動的ルーティングプロトコルの理論を理解する。
-ネットワークにOSPFプロトコルを導入する「Lift mi Up」
-OSPFとEIGRP間のルートの転送(再配布)を構成します
-この問題では、「タスク」セクションを追加します。 次のアイコンは、記事中にそれらを識別します。
難易度は異なります。 サイクルWebサイトで表示できるすべてのタスクに対する回答があります。 それらのいくつかでは、あなたは考える必要があり、他の人はドキュメントを読むために、3番目の人はトポロジーを理解し、おそらくデバッグ情報を見さえする必要があります。 RTでタスクが実行可能でない場合、特別なメモを作成します。
動的ルーティングプロトコルの理論
まず、「動的ルーティング」の概念を扱います。 これまで、いわゆる静的ルーティングを使用していました。つまり、各ルーターのルーティングテーブルを手で作成しました。 ルーティングプロトコルを使用すると、この単調な単調なプロセスと人的要因に関連するエラーを回避できます。 名前が示すように、これらのプロトコルは、現在のネットワーク構成に基づいて、ルーティングテーブル自体を
自動的に構築するように設計されています。 一般的に、特にネットワークが3つのルーターではなく、30である場合、このことが必要です。
利便性に加えて、他の側面があります。 たとえば、
フォールトトレランス 。 静的ルーティングを備えたネットワークでは、バックアップチャネルを整理することは非常に困難です。特定のセグメントの可用性を監視する人はいません。

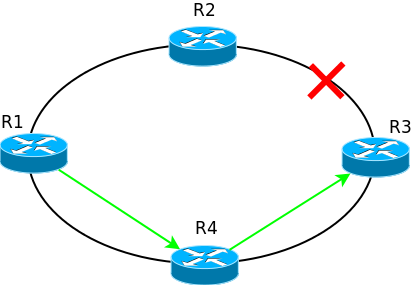
たとえば、このようなネットワークでR2とR3の間のリンクを切断すると、R1からのパケットは以前と同様にR2に送信され、送信先がないため破棄されます。

数秒(または数ミリ秒)以内の動的ルーティングプロトコルがネットワーク上の問題を検出し、ルーティングテーブルを再構築します。上記の場合、パケットは現在のルートに沿って送信されます
もう1つの重要なポイントは、
トラフィックバランシングです。 すぐに使用できる動的ルーティングプロトコルがこの機能を実際にサポートしているため、冗長ルートを手動で追加して計算する必要はありません。
動的ルーティングの導入
により、ネットワークのスケーリングが大幅に促進され
ます 。 既存のルーターのネットワークまたはサブネットに新しい要素を追加する場合、いくつかの手順を実行するだけで機能し、エラーの可能性は最小限に抑えられますが、変更に関する情報はすべてのデバイスに即座に分散されます。 トポロジのグローバルな変更についてもまったく同じことが言えます。
すべてのルーティングプロトコルは、外部(
EGP-外部ゲートウェイプロトコル)と内部(
IGP-内部ゲートウェイプロトコル)の2つの大きなグループに分けることができます。 それらの違いを説明するには、「自律システム」という用語が必要です。 一般的な意味では、自律システム(ルーティングドメイン)は、共通の制御下にあるルーターのグループです。
更新されたネットワークの場合、ASは次のようになります。

そのため、内部ルーティングプロトコルは自律システム内で使用され、外部プロトコルは自律システムを相互に接続するために使用されます。 次に、内部ルーティングプロトコルは、
距離ベクトル (RIP、EIGRP)と
リンク状態 (OSPF、IS-IS)に分けられます。 この記事では、PIPに存在しないためにIS-ISと同様に、RIPおよびIGRPプロトコルに影響を与える
死体を、その古き良き時代のために
蹴りません。
2つの種の基本的な違いは次のとおりです。
1)ルーター間で交換される情報のタイプ:Distance-VectorのルーティングテーブルとLink Stateのトポロジテーブル
2)最適なルートを選択するプロセス、
3)各ルーターが「念頭に置いている」ネットワークに関する情報の量:Distance-Vectorは隣接ノードのみを知っており、リンク状態はネットワーク全体を把握しています。
ご覧のとおり、ルーティングプロトコルの数は少ないですが、まだ1つまたは2つではありません。 そして、ルーターで複数のプロトコルを同時に実行するとどうなりますか? 特定のネットワークに到達する最善の方法について、各プロトコルに独自の意見があることが判明する場合があります。 また、静的ルートも構成されている場合はどうなりますか? ルーターは誰に優先権を与え、誰のルートをルーティングテーブルに追加しますか? この質問に対する答えは、新しい用語であるアドミニストレーティブディスタンスに関連しています(私たちの趣味では、英語のアドミニストレーティブレンジからのかなり平凡なトレーシングペーパーですが、より良い発明はできませんでした)。 アドミニストレーティブディスタンスは、0〜255の整数で、このルートに対するルーターの「信頼性測定値」を表します。 ADが低いほど、信頼が高まります。 シスコの観点から見たこのような信頼の兆候は次のとおりです。
| プロトコル | アドミニストレーティブディスタンス |
|---|
| 接続されたインターフェース | 0 |
| 静的ルート | 1 |
| Enhanced Interior Gateway Routing Protocol(EIGRP)サマリールート | 5 |
| 外部ボーダーゲートウェイプロトコル(BGP) | 20 |
| 内部EIGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| 中間システムから中間システム(IS-IS) | 115 |
| ルーティング情報プロトコル(RIP) | 120 |
| Exterior Gateway Protocol(EGP) | 140 |
| オンデマンドルーティング(ODR) | 160 |
| 外部EIGRP | 170 |
| 内部BGP | 200 |
| 不明 | 255 |
今日の記事では、OSPFとEIGRPを分析します。 1つ目はどこにでも常に存在し、2つ目はシスコの機器のみが存在するネットワークで非常に適しています。
それぞれに長所と短所があります。 EIGRPはOSPFよりも優れていると言えますが、その利点によってすべての利点が相殺されます。 EIGRPはシスコ独自のプロトコルであり、他の誰もサポートしていません。
実際、EIGRPには多くの欠点がありますが、これは人気のある記事では特に一般的ではありません。 問題の1つを次に示します
。SIAそれでは始めましょう。
OSPF
OSPF山の設定方法に関する記事とビデオ。 仕事の原則の説明がはるかに少ない。 一般に、SPFアルゴリズムや不可解なLSAについても知らなくても、マニュアルに従ってOSPFを簡単に構成できるようなことがあります。 そして、すべてが機能し、ほとんどの場合、完全に機能します-それが設計されたものです。 つまり、Vlanの場合とは異なり、ヘッダー形式まで理論を知る必要がありました。
しかし、エンジニアはenikeyschikとは異なり、ネットワークがこのように機能する理由を理解し、それ以外の場合はそうではなく、OSPFがプロトコルによってどのルートが選択されるかを知っているという点で異なります。
この時点で8,000文字である記事の枠組みでは、理論の深みに突入することはできませんが、基本的な点を検討します。
ちなみに、
xgu.ruまたは英語版
ウィキペディアで OSPFについて書かれています。
したがって、OSPFv2はIP上で動作します。具体的には、IPv4専用です(OSPFv3はレイヤー3プロトコルに依存しないため、IPv6で動作できます)。
このような単純化されたネットワークの例での作業を検討してください。

そもそも、ルーター間の隣接関係(隣接関係)を確立するには、次の条件を満たしている必要があります。
1)OSPFでは、互いに接続されているルーターで同じ
Hello間隔を構成する必要があります。 デフォルトでは、イーサネットなどのブロードキャストネットワークでは10秒です。 これは一種のKeepAliveメッセージです。 つまり、各ルーターは10秒ごとにHelloパケットをネイバーに送信して、「Hey、I'm alive」と言います。
2)それらの
デッドインターバルは同じである必要があります。 通常、これらは4つのHello間隔-40秒です。 この時間中にHelloがネイバーから受信されない場合、それは利用できないと見なされ、
PANICはローカルデータベースを再構築し、すべてのネイバーに更新を送信するプロセスを開始します。
3)相互に接続されたインターフェースは
同じサブネット上になければなりません。
4)OSPFは、自律システムをゾーンに分割することにより、ルータールーターの負荷を軽減できます。 したがって、
ゾーン番号も一致する必要があります。
5)OSPFプロセスに参加している各ルーターには、
固有の識別子-
ルーターIDがあります 。 気にしない場合、ルーターは接続されたインターフェイスに関する情報に基づいて自動的に選択します(OSPFプロセスの開始時にアクティブだったインターフェイスから最高のアドレスが選択されます)。 しかし、ここでも優れたエンジニアがすべてを管理しているため、通常、ループバックインターフェイスが作成され、/ 32マスクのアドレスが割り当てられ、ルーターIDに割り当てられます。 これは、サービスとトラブルシューティングを行うときに便利です。
6)MTUサイズは一致する必要があります
さらに、劇は8つのパートに分かれています。
1)穏やか OSPFステータス-
ダウンこの短い瞬間、ネット上では何も起こりません。誰もが黙っています。

2)風が吹く:ルータは、OSPFが実行されているすべてのインターフェイスからマルチキャストアドレス
224.0.0.5に Helloパケットを送信します。 このようなメッセージの
TTLは 1に等しいため、同じネットワークセグメントにあるルーターのみがそれらを受信します。 R1は
INIT状態になります。

次の情報がパッケージに埋め込まれています。
- ルーターID
- こんにちは間隔
- デッドインターバル
- 隣人
- サブネットマスク
- エリアID
- ルーターの優先順位
- DRおよびBDRルーターアドレス
- 認証パスワード
これまでのところ、最初の4つ以上、正確には一般にルーターIDと近隣ノードのみに関心があります。
R1からのHelloメッセージにはルーターIDが含まれており、ネイバーはまだ含まれていないため、ネイバーは含まれていません。
このマルチキャストメッセージを受信した後、ルーターR2はR1をネイバーテーブルに追加します(必要なパラメーターがすべて一致する場合)。

そして、このルーターのルーターIDを含む新しいHelloメッセージをすでにユニキャストでR1に送信します。Neigborsリストには、そのすべてのネイバーがリストされています。 このリストの他の近隣には、ルーターID R1があります。つまり、R2は既に近隣IDであると見なしています。

3)友情。 R1はR2からこのHelloメッセージを受信すると、ネイバーのリストをスクロールし、独自のルーターIDを見つけて、R2をネイバーのリストに追加します。
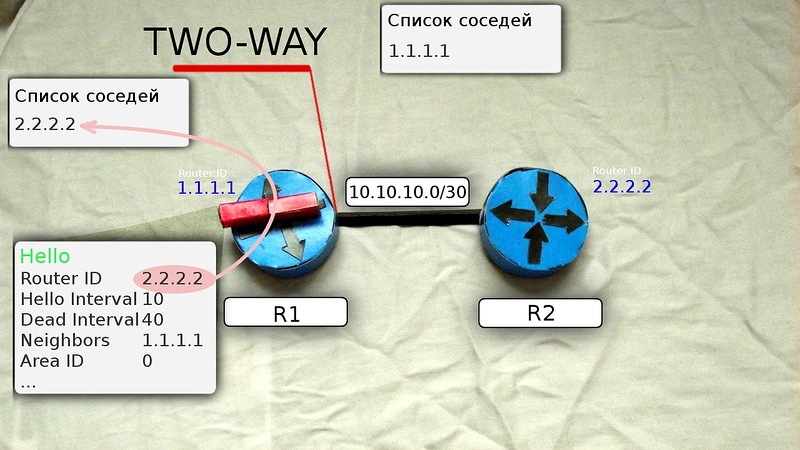
これで、R1とR2は互いの相互隣接にあります-これは、それらの間に隣接関係が確立され、ルーターR1が
TWO WAY状態になることを意味します。

次に
DRとBDRを選択しますが、これについては詳しく説明しませんが、これらは非常に重要なことです。
4)嵐の前の静けさ。 次に、全員が
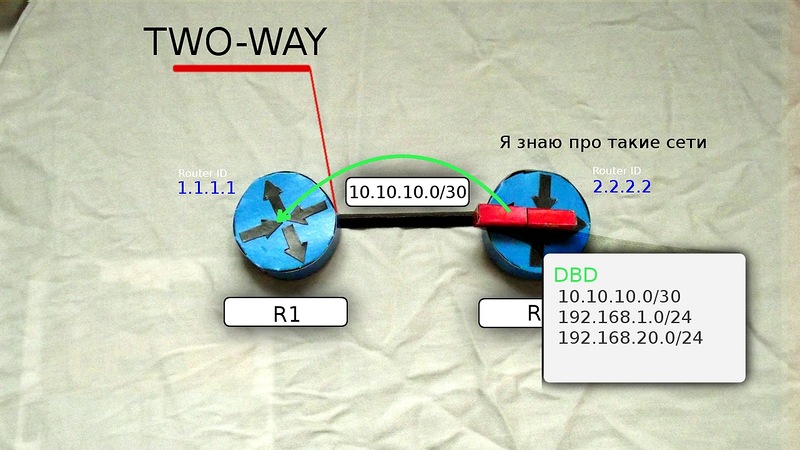
EXSTART状態になります。 ここでは、すべての隣人が上司を自分の中から決定します。 最大のルーターIDを持つルーターになります-R2。
5)Old Manが選択されると、ネイバーは
Exchange状態になり、DBDメッセージ(またはDD)-LSDB(Link State Data Base)の説明を含むデータベース記述を交換します、彼らは私がこれらのサブネットについて知っていると言います。
ここで、LSDBとは何かを説明する必要があります。 文字通りロシア語に翻訳する場合:リンクのステータスのデータベース。 初期状態では、ルーターはOSPFプロセスが実行されているリンク(インターフェイス)のみを認識しています。 プレイの過程で、各ルーターはネットワークに関するすべての情報を収集し、トポロジをコンパイルします。 それがLSDBになり、ゾーンのすべてのメンバーで同じになります。
DBDルーターを最初に送信するものが、このインターフェースの主要なものとして選択されます-2.2.2.2。 彼に続いて、1.1.1.1は同じことをします。
6)メッセージを受信すると、ルーターR1とR2はDBD(LSAck)の確認を送信し、LSDBに含まれる情報と新しい情報を比較し、違いがある場合は、LSR(Link State Request)を互いに送信します。新しい状態
LOADINGに移動します。 LSRでは、「このネットワークについて何も知りません。 詳細を教えてください。」
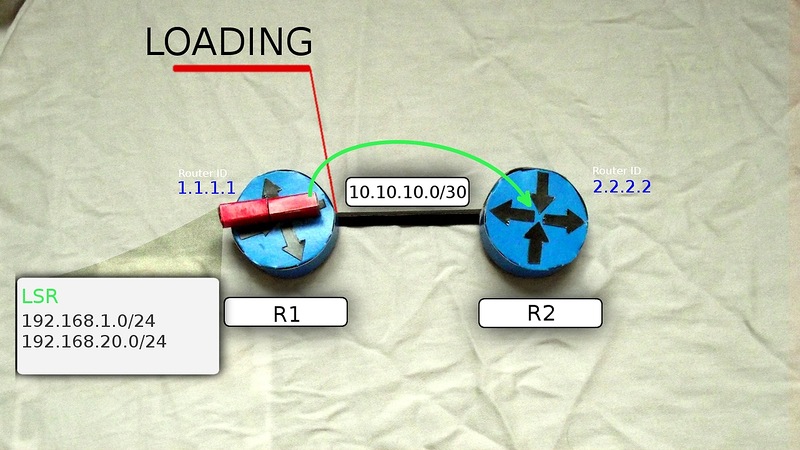
7)R1からLSRを受信したR2は、LSU(Link State Update)を送信します。LSUには、必要なサブネットに関する詳細情報を含むLSA(Link State Advertisement)が含まれています。
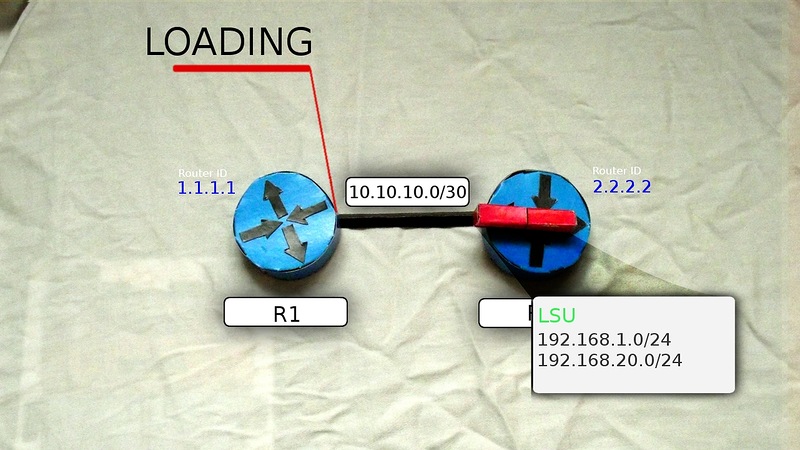
したがって、R1はすべてのサブネットで最後のデータを受信し、LSDBを形成するとすぐに、最終状態
FULL STATEになります。
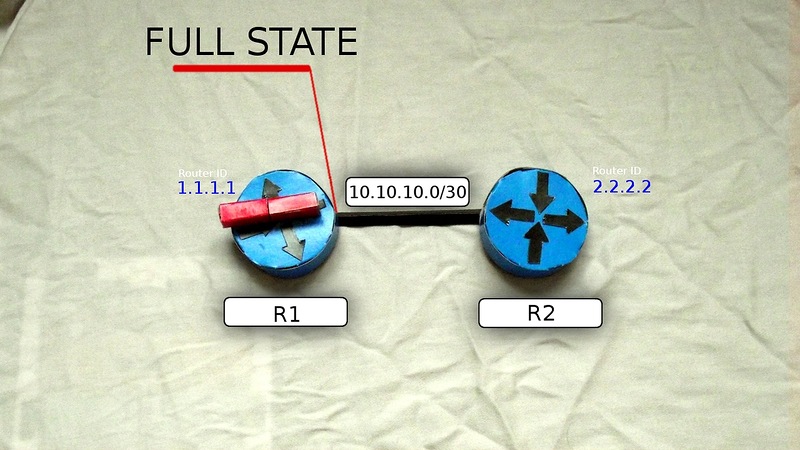
ゾーン内のすべてのルーターがFull State状態に達するまでに、すべてのルーターが同じLSDBを持つ必要があります-彼らは同じネットワークを調べました。 つまり、実際には、これはルーターがネットワーク全体、何、どのように、どこに接続されているかを知っていることを意味します。
著者は、これらすべての略語と規則を理解して覚えるのはかなり難しいことを認識していますが、特定の頻度でさまざまな場所で5〜7回読んだ後、OSPFの仕組みを理解できます。
8)これで、すべてのルーターがネットワークに関するすべてを認識できるようになりましたが、この知識はルーティングには役立ちません。
次のステップであるOSPFは、ダイクストラのアルゴリズム(またはSPF-Shortest Path Firstとも呼ばれます)を使用して、ゾーン内の各ルーターへの最短ルートを計算します-トポロジ全体を認識しています。 この点でメトリックが役立ちます。 低いほど、ルートは良くなります。 メトリックは、ルートに沿って移動するコストです。

たとえば、このようなネットワークでは、R1からR3に直接またはR2経由で到達できます。
当然、最初のオプションの方が費用がかかりません。 ただし、これは、どこにでも同じタイプのインターフェースがある場合に提供されます。 また、たとえば、R1とR3の間に56kモデム接続または非常に不安定なGPRSリンクがある場合はどうでしょうか。 その場合、コストが非常に高くなり、OSPFはより長いがより高速な方法を好みます。
次に、見つかったパスがルーティングテーブルに追加されます。
現在、各ルーターは10秒ごとにHelloパケットを送信し、LSAは30分ごとに送信されます。このタイプのデータはすでに古くなっていると見なされており、変更がなくても更新する必要があります。
理想的な世界では、これについて平衡が確立されます。 しかし、私たちは残酷で無関心な世界に住んでおり、エンジニアはIT専門家、または一般にコンピューター技術者であり、エレベーターはわずか
3つの問題を後戻りさせることを学びました。それはこの世界ではないでしょうか?)-言い換えれば、トポロジーは絶えず変化しています。 また、ネットワークが大きくなるほど、頻繁かつグローバルな変更が行われます。
もちろん、40秒(デッドインターバル)待ってからテーブルの再構築を開始するのは少し奇妙です。 これはRIPにも許されますが、膨大な数の最新ネットワークで使用されているプロトコルには許されません。 そのため、リンク(または複数)のいずれかがクラッシュするとすぐに、ルーターはLSDBを変更してLSUを生成し、以前よりも大きい番号を割り当てます(各LSDBには、最後に受信したLSAから取得した番号があります)。
このLSUメッセージは、マルチキャストアドレス224.0.0.5に送信されます。 それを受信するルーターは、LSUに含まれるLSA番号をチェックします。
1)数値がルーターの現在のLSAの数値よりも大きい場合、LSDBが変更されます。 (LSDBバージョンは古い、情報は新しい)、
2)番号が同じ場合、何も起こりません。 このルーターは、既に他の方法でこのLSAを受信しています。
3)受信したLSA番号がローカルLSDBより小さい場合、これはルーターが既に最新の情報を持っていることを意味し、古いLSDBに基づいて新しいLSAを古いLSAの送信者に送信します。
実行された(または実行されなかった)アクションの後、LSAckはLSUの送信元のネイバーに送信され(「パッケージを受信しました-すべてが正常です」)、元のLSUは変更なしで他のネイバーに送信されます。 このルーターでSPFアルゴリズムが再び開始され、必要に応じてルーティングテーブルが更新されます。
一般に、これはすべてのデバイスで情報の関連性を維持するために行われます。LSDBはすべてのユーザーで同じでなければなりません。
ここで、ルーターは、ネイバーに直接接続する場合にのみ変更を通知することに注意する必要があります。 たとえば、それらの間にスイッチがある場合、デバイスは物理インターフェースの落下を検出せず、何もしません。 このような状況には、2つの解決策があります。
1)タイマーを設定します。 OSPFの場合は、msレベルに減らすことができます。
2)非常にクールなBFD( 双方向転送検出 )プロトコルを使用します。 また、ミリ秒レベルでリンクのステータスを追跡できます。 設定では、BFDは他のプロトコルと通信し、ネットワークに問題があることを知る必要がある人を非常に迅速に通知できます。 具体的には、別の部分でBFDを扱います。
お気づきのように、すべてのメッセージには確認があります。LSAckか、Helloへの返信です。 これは、TCPを拒否するための料金です-どういうわけか、正常な配信を確認する必要があります。
合計で、ゾーンに非常に結び付けられた7種類のLSAがあり、そのうち5個もあります。 ルーターには4つのタイプもあります。 また、指定ルーター(DR)およびバックアップDR(BDR)、ABRおよびASBRの概念もあります。 メトリックスなどを計算するための公式があります。 これは独立した研究のために残します。
OSPFの実践
前回のルーティングのセットアップ中に私たちがどのように苦しんだかを覚えておいてください。各デバイスから各ネットワークへ、そして神は忘れることを禁じます。 今では過去のものです-IGPを長生きさせましょう!
コマンドを個別に説明する時間を無駄にすることはありませんが、すぐにすばらしい設定の世界に飛び込みます。
ダックスフント、次の論理図が保持されます。
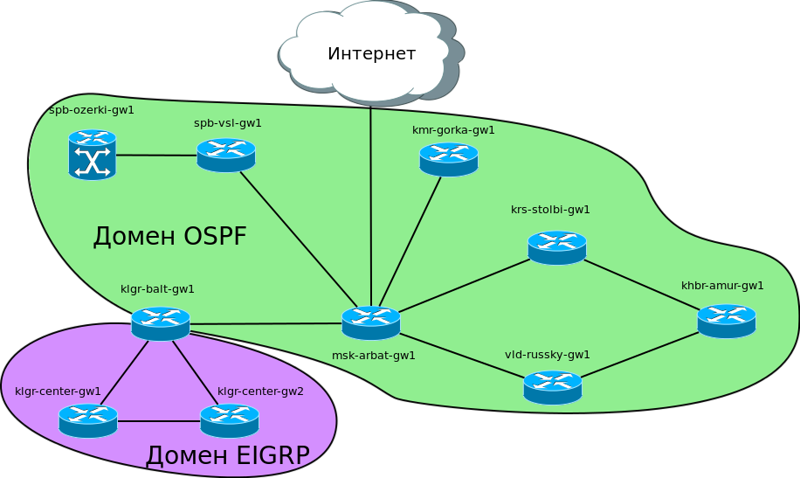
これまでのところ、クラスノヤルスク、ハバロフスク、ウラジオストックを通るこの大きなシベリアのリングに興味があります。 ここおよびすでに構築されているネットワーク上で、OSPFを起動します。 以前に静力学があった場合、それを放棄し、動的プロトコルにスムーズに切り替える必要があります。
前のポイントとして、クラスノヤルスクがBalagan Telecomを介して接続されており、他の都市へのリンクがさまざまなプロバイダーを通じて編成されているとします。 リングは、プロバイダー「フィルキン証明書」を通じてモスクワで閉鎖されています。 L2-VPNとIPトラフィックを購入した都市間のあらゆる場所が透過的に移動するとします。
私たちのネットワークに特化したIGPの実装は何ですか?
1)設定のシンプルさ。 各ノードでは、ローカルエリアネットワークのみを知る必要があり、OSPFはその分散の問題に戸惑います。
2)通信チャネルの冗長性を提供する冗長リンク。 例えば、ホームレスの人々がモスクワとクラスノヤルスクの間の光学を遮断した場合、単一のブランチが接続なしで残されることはありません。すべてのトラフィックはウラジオストクを通過します
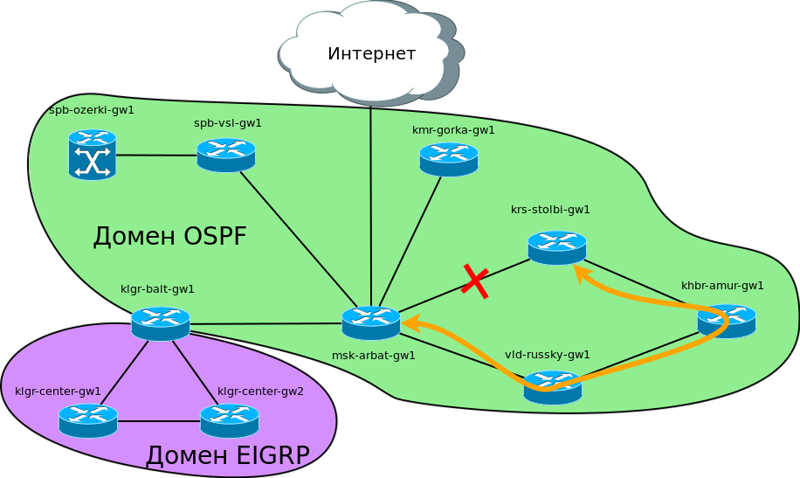
3)問題を自動的に検出し、トポロジを再構築して、ルーティングテーブルを変更します。 それがパラグラフ2を満たすことを可能にするものです。
4)TTLが期限切れになるまで2つのノード間でパケットがトスされる場合、ルーティングループを作成する危険はありません。 静的チューニングでは、この状況は可能な範囲を超えています。
5)拡張の利便性。 たとえば、Tomskに新しいブランチを追加する必要があり、Kemerovoを介して接続することを想像してください。 次に、モスクワ、ケメロヴォ、およびトムスク自体に静的ルートを登録する必要があります。 スピーカーを使用するときは、新しいルーターを構成するだけです...それだけです。
ブランチおよびPoint-to-PointリンクのサブネットのIPプランをすでに
準備していますが、すべてのノードですべての初期設定も完了しているとします。
-ホスト名
-セキュリティ設定(telnet、sshのパスワード)
-リンクインターフェイスのIPアドレス
-LANサブネットのIPアドレス
-ループバックインターフェイスのIPアドレス。
Loopbackインターフェースの新しいコンセプトを導入しています。 各ルーターで構成されます。 このために、特別なサブネット172.16.255.0/24が割り当てられます。 現在、OSPFに必要であり、将来的にはBGP、MPLSに必要になる可能性があります。
長い間、これらのインターフェースの意味を理解していませんでした。 一般的に、これは仮想インターフェイスであり、物理インターフェイスの状態に関係なく、その状態は常にUPです(シャットダウン自体が実行されていない限り)。 彼の役割の1つを説明してみましょう。
ここでは、たとえば、Nagios監視サーバーがあります。 R1 FE0/0 — 10.1.0.1.

— . , .

, , FE0/1. Nagios' , , . , IP- .
Nagios' Loopback-, , .
IP- Loopback- /32, 11111111.11111111.11111111.1111111 — — .
すべての準備が既に完了しているため、非常に簡単なタスクがあります。すべてのルーターを通過して、OSPFプロセスをアクティブにすることです。1)最初に行う必要があるのは、ルーターのOSPFプロセスを開始することです。msk-arbat-gw1(config)#ルーターOSPF 1
最初の言葉では、動的ルーティングプロトコルを起動していることを示し、最後にプロセス番号を示します(理論的には、同じルーター上に複数存在する可能性があります)。この直後に、ルーターIDが自動的に割り当てられます。デフォルトでは、これはループバックインターフェイスの最大アドレスです。2)このことを偶然に任せないでください。一般規則:ルーターIDは一意でなければなりません。いいえ、もちろんそれらを同じにすることができますが、この場合は奇妙になり始めます。私のアプリケーションの1つはこれでした:LDPタグは機器で終わります。8千人のうち、1人だけが空いていました。新しいVPNは作成または機能していません。それを整理して整理し、最終的にはOSPFプロセスがルーティングテーブルで毎分数千のレコードを作成および削除することを確認しました。トポロジーは絶えず再構築され、新しいLDPラベルはそのような再構築ごとに割り当てられ、その後は解放されません。そして、それはすべて同じルーターIDをランダムに構成することです。
原則として、必要に応じて設定できます。設定する必要さえありません。ルーターが自動的に割り当てますが、順序のために私たちはそれを行います-将来的には保守が容易になります。ループバックインターフェイスのアドレスに従って割り当てます。msk-arbat-gw1(config-router)#router-id 172.16.255.1
3)現在、どのネットワークをアナウンスするかを発表しています(OSPFネイバーに送信)。このコマンドは、ACLのようにワイルドカードマスクを使用することに注意してください。msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255エリア0
ここで詳しく説明します。networkコマンドを使用して、ルーターがブロードキャストする間違ったネットワークを指定し、プロセスに関係するインターフェイスを決定します。IPアドレスが構成された範囲172.16.0.0 0.0.255.255(172.16.0.0-172.16.255.255)内にあるすべてのルーターインターフェイスがプロセスに含まれます。これは、次のことを意味します。a)これらのインターフェイスからHelloメッセージが送信され、それらを介して近隣関係が確立され、ネットワークトポロジに関する更新が送信されます。b)OSPFはこれらのインターフェイスのサブネットを調査し、それらのステータスをアノスし、監視するのはそれらです。つまり、設定した172.16.0.0 0.0.255.255ではなく、この範囲を満たすものです。この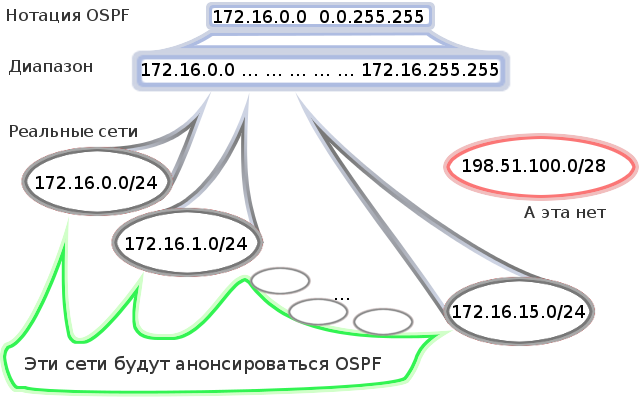 場合、設定方法は関係ありません。
場合、設定方法は関係ありません。msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
または
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.15.255 area 0
または
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.1.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.2.0 0.0.255.255 area 0
……
msk-arbat-gw1(config-router)#network 172.16.15.0 0.0.255.255 area 0
この場合、これらのコマンドはすべて同じように機能します。ネットワーク172.16.0.0/16のアドレスを持つすべてのローカルネットワークがあるため、最も一般的なエントリを使用します。同時に、もちろん、外部インターフェイスFastEthernet0 / 1.6はインターネットに到達しません。これは、そのアドレス(198.51.100.2)がこの範囲外であるためです。この構成では、172.16.0.0〜172.16.255.255の範囲のアドレスを指定した新しいインターフェイスは、自動的にOSPFプロセスのメンバーになります。良くも悪くも、それはあなたの欲求に依存します。エリア0は、これらのサブネットがゾーン番号0に属していることを意味します(この例では、これのみになります)。エリア0は単純なゾーンではなく、いわゆるバックボーンエリアです。これは、他のすべてのゾーンを結合することを意味します。非ゼロゾーンから非ゼロへのパケットはエリア0を通過する必要があります
networkコマンドを設定するとすぐに、ウェルカムワードが正しいインターフェイスから飛び出しますが、まだ答える人はいません-隣人はいません:msk-arbat-gw1#sh ip OSPFネイバー
msk-arbat-gw1#
ここで、OSPF設定をKemerovoに書き込みます(ルーターID =ループバックインターフェイスのIPアドレス、IPプランから取得):kmr-gorka-gw1(config)#router OSPF 1
kmr-gorka-gw1(config-router)#router-id 172.16.255.48
kmr-gorka-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
そしてその直後にコンソールにメッセージが表示されます02:27:33:%OSPF-5-ADJCHG:プロセス1、FastEthernet0 / 0.5のNbr 172.16.255.1のLOADINGからFULL、完了
モスクワのルーターにも同じことが示されています。02:27:33:%OSPF-5-ADJCHG:プロセス1、FastEthernet0 / 1.5のNbr 172.16.255.48からLOADINGからFULL、完了しました。
ここでは、隣接関係が正常に確立され、LSA交換が発生したことがわかります。各ルーターは独自のLSDBを構築しています。近隣の詳細情報:msk-arbat-gw1#sh ip OSPF neighbor detail
Neighbor 172.16.255.48 , interface address 172.16.2.18
In the area 0 via interface FastEthernet0/1.5
Neighbor priority is 1, State is FULL , 4 state changes
DR is 172.16.2.17 BDR is 172.16.2.18
Options is 0x00
Dead timer due in 00:00:38
Neighbor is up for 00:02:51
Index 1/1, retransmission queue length 0, number of retransmission 0
First 0x0(0)/0x0(0) Next 0x0(0)/0x0(0)
Last retransmission scan length is 0, maximum is 0
Last retransmission scan time is 0 msec, maximum is 0 msec
近隣の状態に関するすべての重要な情報は次のとおりです。そのルーターID(172.16.255.48)、ループバック、近隣が確立されるリモート側インターフェイスのアドレス(172.16.2.18)、物理インターフェイスのタイプと番号(FastEthernet0 / 1.5)、現在のステータス(FULL)およびデッドタイマー。後者は、観察してもゼロにはなりません。その値は減少し、減少し、そしてOp! 10秒ごとにルータがhelloメッセージを受信しているためと40の上にこれがあるobsorokolyayutデッド間隔をゼロに。show ip routeコマンドを使用すると、ルーティングテーブルがどのように変更されたかを確認できます。msk-arbat-gw1#show ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 17 subnets, 5 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
既知のネットワーク(C-直接接続およびS-静的)に加えて、O(OSPF)とマークされた2つの新しいルートがあります。ここではすべてが明確になっているはずですが、注意深い読者は尋ねます。「ルーティングテーブルに172.16.24.0ネットワークへの2つのルートがあるのはなぜですか。なぜより望ましい静的なものが残らないのでしょうか?」一般的に、ネットワークへの最適なルートのみがルーティングテーブルに入ります。デフォルトでは1つです。ただし、静的ルートはサブネット172.16.24.0/22に到達し、OSPFから172.16.24.0/24に受信されます。これらは異なるサブネットであるため、どちらも太陽の前の場所を見つけました。実際のところ、OSPFは、あなたがそこで何を計画し、どの範囲を割り当てたかわからない-実際のデータ、つまりIPアドレスとマスクで動作します:インターフェイスFastEthernet0 / 0.2
IPアドレス172.16.24.1 255.255.255.0
ケメロヴォで起こっていること:kmr-gorka-gw1#sh ip route
最終手段のゲートウェイは172.16.2.17からネットワーク0.0.0.0へ
172.16.0.0/16は可変サブネット化、14サブネット、3マスク
O 172.16.0.0/24 [110/2]経由で172.16経由です。 2.17、00:32:42、FastEthernet0 / 0.5
O 172.16.1.0/24 [110/2]経由172.16.2.17、00:32:42、FastEthernet0 / 0.5
O 172.16.2.0/30 [110/2]経由172.16。 2.17、00:32:42、FastEthernet0 / 0.5
C 172.16.2.16/30は直接接続され、FastEthernet0 / 0.5
O 172.16.2.32/30 [110/2] 172.16.2.17、00:32:42、FastEthernet0 / 0.5
O 経由172.16.2.17、夜12時32分42秒、FastEthernet0 / 0.5経由172.16.2.128/30 [2分の110]
172.16.2.17、夜12時32分42秒、FastEthernet0 / 0.5経由O 172.16.2.196/30 [2分の110]
O 172.16.3.0/24 [110/2] 172.16.2.17経由、00:32:42、FastEthernet0 / 0.5
O 172.16.4.0/24 [110/2] 172.16.2.17経由、00:32:42、FastEthernet0 / 0.5
O 172.16.5.0/24 [110/2] 172.16.2.17、00:32:42経由、FastEthernet0 / 0.5
O 172.16.6.0/24 [110/2]経由172.16.2.17、00:32:42、FastEthernet0 / 0.5
C 172.16.24.0/24は直接接続され、FastEthernet0 / 0.2
O 172.16.255.1/32 [110/2]経由172.16.2.17、00:32:42、FastEthernet0 / 0.5
C 172.16.255.48/32は直接接続され、Loopback0
S * 0.0.0.0/0 [1/0]は172.16.2.17経由
ご覧のとおり、以前に構成されたデフォルトルートに加えて、モスクワのすべてのサブネットがここに表示されました。角括弧内の数字に注意してください。S * 0.0.0.0/0 [ 1/0 ]
O 172.16.6.0/24 [ 2分の110 ]
最初の桁はアドミニストレーティブディスタンスであり、OSPFはスタティックよりもはるかに大きいため、優先順位は低くなります。実際、サブネット172.16.24.0/24より前では、トラフィックは、マスクが狭いため(24対22)、OSPFが提供するルートをすでに通過していました。しかし、静的ルートを削除して、何が起こるか見てみましょう。予想通り、すべてが機能します:msk-arbat-gw1#ping 172.16.24.1
中止するにはエスケープシーケンスを入力します。
5、100バイトのICMPエコーを172.16.24.1に送信すると、タイムアウトは2秒です。
!!!
成功率は100パーセント(5/5)、最小往復/平均/最大= 8/10/15ミリ秒
それは素晴らしいことです。
サンクトペテルブルクでOSPFを設定しましょう:spb-vsl-gw1(config)#router OSPF 1
spb-vsl-gw1(config-router)#router-id 172.16.255.32
spb-vsl-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
ご覧のとおり、設定はどこでも非常に簡単です。同時に、異なるルーターのOSFPプロセス番号は同じである必要はありませんが、その場合はより良いことに注意してください。msk-arbat-gw1には、2つの近傍がありますmsk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Address Interface
172.16.255.32 1 FULL / DROTHER 00:00:39 172.16.2.2 FastEthernet0 / 1.4
172.16.255.48 1 FULL / DROTHER 00:00:31 172.16。 2.18 FastEthernet0 / 1.5
しかし、サンクトペテルブルク(およびケメロヴォ)で:spb-vsl-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Address Interface
172.16.255.1 1 FULL / DR 00:00:34 172.16.2.1 FastEthernet1 / 0.4
実際には、隣接関係は直接接続されたデバイス間でのみ確立され、spb-vsl-gw1はmsk-arbat-gw1を介してkmr-gorka-gw1と通信するため、互いの隣接関係にはありません。保守主義の最後の砦-spb-ozerki-gw1は、3つのシベリアリングルーターのように、問題なくあなたに降伏します。すべては類推によって行われます-実際には、ルーターIDのみが変更されます。また、静的ルートを削除することを忘れないでください。 タスクNo. 1サンクトペテルブルクのルーター間では、近隣の損失を検出する時間を短縮する必要があります。ルーターは3秒ごとにHelloメッセージを送信する必要があり、12秒間近隣からのHelloメッセージがなかった場合はお互いが利用できないと見なします。答えすべてのタスクに関する一般的なアドバイス:, :
— , ?
— ?
, , , , , , , .
- .
実際のネットワークでは、発表されたサブネットの範囲を選択するとき、規制と緊急のニーズに導かれる必要があります。バックアップリンクと速度のテストに進む前に、別の便利なことを行います。サーバーに向かっているFE0 / 0.2インターフェイスmsk-arbat-gw1でトラフィックをキャッチする機会があった場合、10秒ごとにHelloメッセージが未知のものに飛んでいくことがわかります。Helloに答える人はいません。隣接関係を確立する人もいないので、ここからメッセージを送信しようとしても意味がありません。オフにするのは非常に簡単です。msk-arbat-gw1(config)#router OSPF 1
msk-arbat-gw1(config-router)#passive-interface fastEthernet 0 / 0.2
このコマンドは、OSPFネイバーが確実に存在しない(インターネットへの接続を含む)すべてのインターフェイスに対して指定する必要があります。その結果、写真は次のようになります。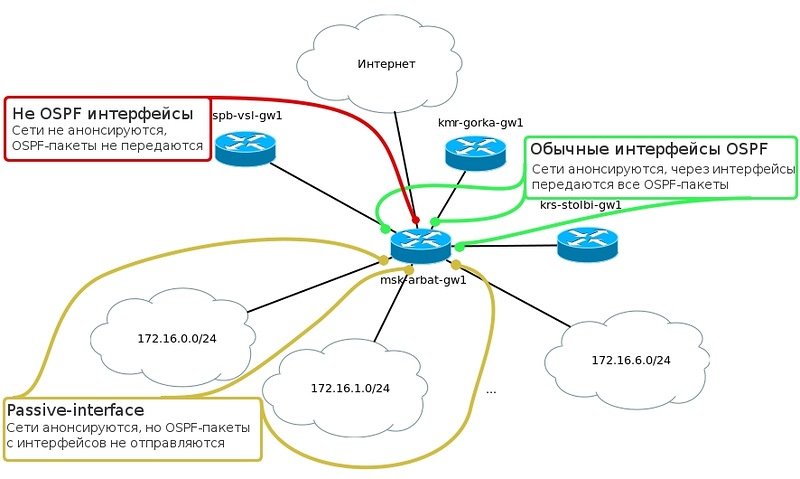 *まだ混乱していないことは想像できません。*さらに、このコマンドはセキュリティを強化します。このネットワークの誰もルーターのふりをせず、私たちを完全に破壊しようとしません。それでは、楽しい部分、テストに取り掛かりましょう。シベリアのリング内のすべてのルーターでOSPFをセットアップするのに複雑なことはありません-自分で行います。その後、画像は次のようになります。
*まだ混乱していないことは想像できません。*さらに、このコマンドはセキュリティを強化します。このネットワークの誰もルーターのふりをせず、私たちを完全に破壊しようとしません。それでは、楽しい部分、テストに取り掛かりましょう。シベリアのリング内のすべてのルーターでOSPFをセットアップするのに複雑なことはありません-自分で行います。その後、画像は次のようになります。msk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Address Interface
172.16.255.32 1 FULL / DR 00:00:31 172.16.2.2 FastEthernet0 / 1.4
172.16.255.48 1 FULL / DR 00:00:31 172.16。 2.18 FastEthernet0 / 1.5
172.16.255.80 1 FULL / BDR 00:00:36 172.16.2.130 FastEthernet0 / 1.8
172.16.255.112 1 FULL / BDR 00:00:37 172.16.2.197 FastEthernet1 / 0.911
ピーター、ケメロヴォ、クラスノヤルスク、ウラジオストクは直結しています。msk-arbat-gw1#sh ip route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.32/32 [110/2] 172.16.2.2、00:24:03、FastEthernet0 / 1.4
経由O 172.16.255.48/32 [110/2] 172.16.2.18、00:24:03、FastEthernet0 / 1.5経由
O 172.16.255.80/32 [110/2] 172.16.2.130経由、00:07:18、FastEthernet0 / 1.8
O 172.16.255.96/32 [110/3] 172.16.2.130経由、00:04:18、FastEthernet0 / 1.8
[110/3] 172.16.2.197経由、00:04:18、FastEthernet1 / 0.911
O 172.16.255.112/32 [110/2] 172.16.2.197経由、00:04:28、FastEthernet1 / 0.911
198.51.100.0/28はサブネット化、1つのサブネット
C 198.51.100.0が直接接続され、FastEthernet0 / 1.6
S * 0.0.0.0/0 [1/0]経由で198.51.100.1
誰もがすべてのことを知っています。モスクワからクラスノヤルスクまでの交通はどのようなルートですか?この表は、krs-stolbi-gw1が直接接続されていることを示しており、トレースからも同じことがわかります。
msk-arbat-gw1#traceroute 172.16.128.1
中止するにはエスケープシーケンスを入力します。
172.16.128.1
1 172.16.2.130 へのルートのトレース35ミリ秒8ミリ秒5ミリ秒
ここで、モスクワとクラスノヤルスク間のインターフェースを切断し、復元されるリンクの数を確認します。5秒未満で、すべてのルーターがインシデントについて学習し、ルーティングテーブルを再カウントしました。msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Routing entry for 172.16.128.0/24
Known via «OSPF 1», distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1
vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via «OSPF 1», distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1
msk-arbat-gw1#traceroute 172.16.128.1
中止するにはエスケープシーケンスを入力します。
Tracing the route to 172.16.128.1
1 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
つまり、クラスノヤルスクのトラフィックは次のようになります。

リンクを上げるとすぐに、ルータは再び接触し、ベースを交換し、最短パスを再計算してルーティングテーブルに入力します。
ビデオでは、これはすべて明白です。
慣れることを
お勧めします。
タスク番号2シベリアのリング内のルーターでOSPFをセットアップした後、モスクワの中央オフィス(msk-arbat-gw1)のルーターの背後にあるすべてのネットワークは、2つのルート(クラスノヤルスクとウラジオストク経由)でハバロフスクに利用できます。 ただし、クラスノヤルスクを介したチャネルの方が優れているため、ハバロフスクが利用可能な場合はクラスノヤルスクを介したチャネルを使用するように、デフォルト設定を変更する必要があります。 そして、彼はクラスノヤルスクのチャンネルに何かが起こった場合にのみウラジオストクに切り替えました。
答え優れたプロトコルと同様に、OSPFは認証をサポートします。2つの近隣は、近隣関係を確立する前に、受信したOSPFメッセージの信頼性を検証できます。 私たちは独立した研究のために出発します-非常に簡単です。
タスク番号3Filkin Certificateプロバイダーで不愉快な話がありました。 VPN設定のエラーにより、おそらく別のクライアントまたはプロバイダーの内部ネットワーク自体から、ウラジオストクのルーターにいくつかの奇妙なルートが届き始めました。 一部のネットワークはローカルネットワークと交差し、ネットワークの一部との通信が失われました。 この事件の後、そのような状況から将来を守ることが決定されました。
一般的に言えば、この状況は大げさではなく、ありそうもないことですが、それはタスクとして実行されます。
モスクワとウラジオストクの間のセクションでは、近隣関係を確立するときに、設定されたパスワードもチェックするようにルーターを構成する必要があります。 パスワードはMskVladPassで、ハッシュmd5(キー番号1)の形式で送信する必要があります。
答えEIGRP
次に、もう1つの非常に重要なプロトコルを取り上げます。
それでは、EIGRPは何に適していますか?
-設定が簡単
-
事前に計算された予備ルートへの高速切り替え
-必要なルーターリソースが少ない(OSPFと比較)
-任意のルーターでルートを合計する(OSPFでABR \ ASBRのみ)
-等しくないルートでのトラフィックのバランス調整(OSPFは同等のルートでのみ)
Ivan Pepelnyakのブログエントリの 1つを翻訳することにしました。EIGRPに関する多くの一般的な神話を理解しています。
「EIGRPはハイブリッドルーティングプロトコルです。」 私の記憶が正しければ、何年も前の最初のEIGRPプレゼンテーションから始まり、通常「EIGRPはリンク状態および距離ベクトルプロトコルから最高のものを取得した」と理解されています。 これは完全に間違っています。 EIGRPには、リンク状態の特徴的な機能はありません。 「EIGRPは高度な距離ベクトルルーティングプロトコルです」と正しく表示されます。
-「EIGRPは距離ベクトルプロトコルです。」 悪くはないが、完全に真実でもない。 EIGRPは、失われたルート(またはメトリックが増加するルート)を処理する方法が他のDVと異なります。 他のすべてのプロトコルは、ネイバーからの情報の更新を受動的に待機し(たとえば、RIPなど、ルーティングループを防ぐためにルートをブロックすることもあります)、EIGRPはより積極的に動作し、情報自体を要求します。
「EIGRPの実装と保守は困難です。」 違います。 かつて、低速リンクを備えた大規模ネットワークのEIGRPは、スタブルーターが導入されるまで正確に実装することは困難でした。 それら(およびDUALアルゴリズムのいくつかの修正)を使用すると、OSPFほど悪くありません。
「LSプロトコルと同様に、EIGRPは交換するルートのトポロジのテーブルを維持します。」 これがいかに間違っているかは驚くばかりです。 EIGRPは、最近隣の隣に何があるのかわかりませんが、LSプロトコルは、接続先のエリア全体のトポロジを正確に把握しています。
-「EIGRPはLSのように機能するDVプロトコルです。」 悪い試みではありませんが、それでも完全に間違っています。 LSプロトコルは、次の手順を実行してルーティングテーブルを作成します。
-各ルーターは、LSA(OSPF内)またはLSP(IS-IS)と呼ばれるパケット(または複数)を介して、ローカルで利用可能な情報(リンク、配置されているサブネット、隣接ノード)に基づいてネットワークを記述します
-LSAはネットワークを介して配布されます。 各ルーターは、ネットワークで作成された各LSAを受信する必要があります。 LSAから取得した情報は、トポロジテーブルに入力されます。
-各ルーターが独自にトポロジテーブルを分析し、SPFアルゴリズムを実行して、他の各ルーターへの最適なルートを計算します
EIGRPの動作はこれらの手順によく似ていないため、なぜ「LSのように動作する」のかは不明です。
EIGRPが行うことは、ネイバーから受信した情報を保存することだけです(RIPは、現在使用できないものをすぐに忘れます)。 この意味では、BGPに似ており、BGPテーブルにもすべてを保存し、そこから最適なルートを選択します。 トポロジテーブル(ネイバーから受信したすべての情報を含む)は、EIGRPにRIPよりも有利です。スペア(現在使用されていない)ルートに関する情報を含めることができます。
仕事の理論に少し近づいた:
各EIGRPプロセスは3つのテーブルを提供します。
-近隣のテーブル(近隣テーブル)。これには「近隣」に関する情報が含まれます。 現在に直接接続され、ルートの交換に参加している他のルーター。
show ip eigrp neighborsコマンドを使用して
表示できます
-近隣から受信したルート情報を含むネットワークトポロジテーブル。
show ip eigrp topologyコマンドを見る-ルーティングテーブル。これに基づいて、ルーターはパケット転送に関する決定を行います。
show ip routeを
表示メトリック。
特定のルートの品質を評価するために、さまざまな特性または一連の特性(メトリック)を反映して、ルーティングプロトコルで特定の番号が使用されます。 考慮される特性は、特定のルート上のルーターの数から始まり、ルートに沿ってすべてのインターフェイスをロードする算術平均で終わる、異なる場合があります。 EIGRPメトリックについては、ジェレミーシオアラを引用しましょう。「EIGRPの作成者は、作成を批判的に見て、すべてがあまりにも簡単かつうまく機能していると判断したという印象を受けました。 そして、彼らは誰もが言う、「なんてこった、これは本当に複雑でプロフェッショナルに見える」メトリック式を思いついた。 EIGRPメトリックを計算するための完全な式を参照してください:(K1 * bw +(K2 * bw)/(256-負荷)+ K3 *遅延)*(K5 /(信頼性+ K4))、ここで:
-bwは単なる帯域幅ではなく、(10,000,000 /ルートのルートの最小帯域幅(キロビット))* 256
-遅延は単なる遅延ではなく、
数十マイクロ秒 * 256のすべての道路遅延の合計(show interface、show ip eigrp topologyおよびその他のコマンドの遅延はマイクロ秒で表示されます!)
-K1〜K5は、式に1つまたは別のパラメーターを「含める」のに役立つ係数です。
怖い これがすべて書かれているとおりに機能する場合です。 実際、式の4つの可能なすべての項のうち、デフォルトでは2つのみが使用されます:bwとdelay(係数K1とK3 = 1、残りはゼロ)、これにより大幅に簡素化されます-これら2つの数字を追加するだけですまだ式で考慮されています)。 次のことを覚えておくことが重要です。メトリックは
、ルートの全長に沿ったスループットの
最悪の指標と見なされます。
MTUで興味深いことが起こりました。MTUがEIGRPメトリックに関連しているという情報を頻繁に見つけることができます。 実際、ルートを交換するときにMTU値が送信されます。 ただし、完全な式からわかるように、MTUについては言及されていません。 実際には、このインジケータはかなり特定の場合に考慮されます。たとえば、ルーターが他の特性と同等のルートの1つをドロップする必要がある場合、MTUの低いルートを選択します。 ただし、 すべてがそれほど単純ではありません (コメントを参照)。
EIGRP内で使用される用語を定義しましょう。 EIGRPの各ルートは、実行可能距離とアドバタイズされた距離の2つの数値によって特徴付けられます(アドバタイズされた距離の代わりにレポートされた距離が見つかることがありますが、これは同じことです)。 これらの各数値は、異なる測定ポイントからの特定のルートのメトリック、またはコスト(大きい、悪い)を表します。FDは「私から目的地まで」、AD-「このルートについて教えてくれた隣人から目的地。」 「隣人からの費用が既にFDに含まれているのに、なぜ私たちは隣人からの費用を知る必要があるのか」という論理的な質問への回答は少し低いです(今のところ、あなたは自分の頭を止めて、自分の頭を粉砕することができます)。
EIGRPが認識している各サブネットについて、各ルーターには、プロトコルに従って、このサブネットへの最適な(メトリックの少ない)ルートが通過する近隣ルーターの中から後継ルーターがあります。 また、サブネットには1つ以上の代替ルートが含まれる場合があります(このルートが通過する近隣ルーターは、フィージブルサクセサと呼ばれます)。 EIGRPは、予備ルートを記憶する唯一のルーティングプロトコルです(OSPFでは、それらはトポロジテーブルに生の形で含まれています。つまり、SPFアルゴリズムで処理する必要があります)。プロトコルが決定するとすぐに速度が向上します。メインルート(後継者経由)が利用できない場合、すぐにバックアップルートに切り替わります。 ルーターがルートのフィージブルサクセサになるためには、そのADがこのルートのFDサクセサよりも小さくなければなりません(そのためADを知る必要があります)。 このルールは、ルーティングリングを回避するために適用されます。
前の段落は脳を吹き飛ばしましたか? 素材は難しいので、もう一度例を挙げます。 このようなネットワークがあります:
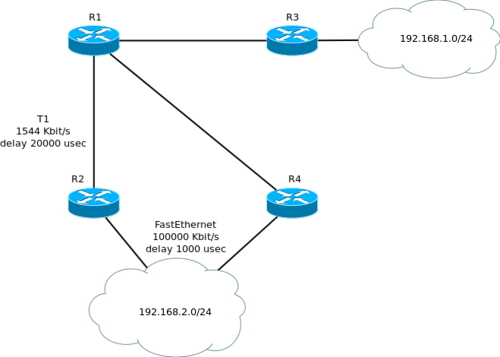
R1から見ると、R2は192.168.2.0/24サブネットの後継です。 このサブネットのFSになるには、R4でADがこのルートのFDより小さい必要があります。 FD((10000000/1544)* 256)+(2100 * 256)= 2195456、ADはR4(彼の観点からはFD、つまりこのネットワークに到達するのにどれくらいの費用がかかりますか)=((10000000/100000 )* 256)+(100 * 256)= 51200。 すべてが収束し、R4はFDルートよりもADが少なく、FSになります。 *ここで脳はそのようなもので、「速い」と言っています。 R3を見てみましょう-ネットワーク192.168.1.0/24をネイバーR1にアナウンスし、次にネイバーR2とR4に通知します。 R4は、R2がこのサブネットを認識していることを認識せず、通知することにしました。 R2は、R4を介してサブネット192.168.1.0/24にアクセスできるという情報をR1で送信します。 R1は、R2が誇るルートとADのFDを厳密に調べます(図から簡単にわかるように、FDも含まれているため、明らかにFDよりも大きくなります)、あらゆる種類のナンセンスを混乱させないようにします。 この状況はかなりありそうにありませんが、特定の状況下で発生する可能性があります。たとえば、「スプリットホライズン」メカニズムが無効になっている場合です。 そして今、より可能性の高い状況のために:R4がFastEthernetではなく56kモデム(ダイヤルアップの遅延は20,000 usec)を介して192.168.2.0/24ネットワークに接続されているので、取得する価値があると考えてみましょう((10000000/56)* 256 )+(2000 * 256)=46226176。これはこのルートのFDよりも大きいため、R4はフィージブルサクセサになりません。 ただし、これはEIGRPがこのルートをまったく使用しないという意味ではありません。 切り替えるだけで時間がかかります(これについては後で詳しく説明します)。
近所
ルーターは、ルートについてだれとも話さない-情報を交換する前に、近隣関係を確立する必要があります。 router eigrpコマンドによって自律システムの番号を使用してプロセスがオンになった後、networkコマンドは、どのインターフェイスが参加するか、同時にどのネットワークを配布するかについての情報を伝えます。 すぐに、helloパケットはこれらのインターフェイスを介してマルチキャストアドレス224.0.0.10に送信されます(デフォルトでは、イーサネットでは5秒ごと)。 EIGRPが有効になっているすべてのルーターがこれらのパケットを受信すると、各宛先ルーターは次のことを行います。
-helloパケットの送信者アドレスを、パケットの受信元のインターフェースのアドレスで検証し、それらが同じサブネットからのものであることを確認します
-K係数のパッケージから取得された値(つまり、メトリックの計算に使用される変数)をそれ自体の値と比較します。 それらが異なる場合、ルートのメトリックは異なるルールに従って考慮されることは明らかであり、これは受け入れられません
-自律システム番号を確認します
-オプション:認証が構成されている場合、そのタイプとキーが一致するかどうかを確認します。
受信者がすべてに満足したら、送信者を隣人のリストに追加し、既知のすべてのルートのリストを含む更新パケット(別名、完全更新)を送信します(既にユニキャスト)。 そのようなパケットを受信した送信者は、同様に同じことを行います。 ルートを交換するために、EIGRPはReliable Transport Protocol(RTP、IPテレフォニーで使用されるReal-time Transport Protocolと混同しない)を使用します。これは配信の確認を意味するため、更新パケットを受信する各ルーターはackパケット(短い確認-確認から)。 それで、近隣関係が確立され、ルーターはお互いからルートに関する包括的な情報を学習しました、次に何をしますか? その後、彼らは接触していることを確認してマルチキャストhelloパケットを送信し続け、トポロジが変更された場合、変更に関する情報のみを含むパケットを更新します(部分更新)。
さて、前のモデム回線に戻ります。

何らかの理由でR2が192.168.2.0/24との接続を失いました。 このサブネットの前は、代替ルートはありません(つまり、FSはありません)。 EIGRPを備えた責任あるルーターと同様に、彼は再接続を望んでいます。 これを行うために、彼はすべての隣人に特別なメッセージ(クエリパケット)を送信し始め、隣人は自分自身の正しいルートを見つけられず、すべての隣人に質問します。 リクエストの波がR4に達すると、彼は「ちょっと待って、このサブネットへのルートがあります! 悪いが、少なくとも何か。 誰もが彼のことを忘れていましたが、私は覚えています。」 彼はこれをすべて返信パケットにまとめ、クエリ(クエリ)を受信したネイバーに送信します。 もちろん、これはすべてフィージブルサクセサに切り替えるよりも時間がかかりますが、最終的にはサブネットに接続できます。
そして今が危険な瞬間です。おそらく、このファンのメールについての瞬間を読んで気づいていて、警戒しているかもしれません。 1つのインターフェイスが落ちると、ネットワーク上のブロードキャストストームに似たものが発生し(もちろん、そのような規模ではありませんが)、ルーターが多いほど、これらすべての要求/応答メッセージにより多くのリソースが費やされます。 しかし、これはまだ問題の半分です。 状況はさらに悪化しています。写真に示されているルーターは、大規模で分散されたネットワークの一部にすぎないことを想像してください。 いくつかは、R2から何千キロも離れた、貧弱なチャネルなどにあります。 そのため、問題は、近隣にクエリを送信することにより、ルーターが近隣からの応答を待たなければならないことです。 答えが何であれ、彼は来なければなりません。 この場合のように、ルーター
が既に肯定的な回答を受け取っ
ていたとしても、すべての要求に対する回答を受け取るまで、このルートを運用することはできません。 そして、おそらく、アラスカのどこか他の場所を探検します。 ルートのこの状態は、スタックインアクティブと呼ばれます。 ここで、EIGRPのルートの状態を反映する用語(アクティブ\パッシブルート)を理解する必要があります。 通常、彼らは誤解を招きます。 常識では、アクティブとは、ルートが「アクティブ」、有効、実行中であることを意味します。 ただし、反対は真実です。パッシブは「大丈夫」であり、アクティブ状態はサブネットが利用できないことを意味し、ルーターは別のルートをアクティブに検索し、クエリを送信して応答を待機しています。 そのため、スタック状態(アクティブ状態のまま)は最大3分間持続します! この期間の終わりに、ルータは、応答を待機できないネイバーとの近隣関係を解除し、R4を介した新しいルートを使用できます。
問題の詳細ネットワークエンジニアを冷やす物語。 3分のダウンタイムは冗談ではありません。 この状況で
心臓発作をどのように回避できますか? 2つの方法があります。ルートの合計と、いわゆるスタブ構成です。
一般的に言えば、別の方法があり、ルートフィルタリングと呼ばれます。 しかし、これは非常に膨大なトピックであるため、別の記事を作成しますが、今回はすでに本の半分があります。 したがって、あなたの裁量で。
すでに説明したように、EIGRPでは、ルートの集約はどのルーターでも実行できます。 説明のために、192.168.0.0 / 24から192.168.7.0/24のサブネットが、非常に便利な192.168.0.0/21に要約されているR2に接続されていると仮定します(バイナリ数学を思い出してください)。 ルーターはこのサマリールートをアナウンスし、他のすべての人は知っています。宛先アドレスが192.168.0-7で始まる場合、これがこれです。 サブネットの1つが消えるとどうなりますか? ルーターはこのネットワークのアドレス(具体的には、たとえば192.168.5.0/24)でクエリパケットを送信しますが、隣人は自分に代わって悪質なメールを送信し続ける代わりに、これがあなたのサブネットであると言って、すぐに冷静な応答を送信します、あなたと理解。
2番目のオプションはスタブ構成です。 比Fig的に言えば、スタブはEIGRPの「パスの終わり」、「行き止まり」を意味します。つまり、そのようなルーターに
直接接続
されていないサブネットに入るには、戻る必要があります。 スタブとして設定されたルーターは、EIGRPから学習したサブネット間でトラフィックを転送しません(つまり、show ip routeで文字Dでマークされています)。 さらに、彼の隣人は彼にクエリパケットを送信しません。 最も一般的なユースケースは、特に冗長リンクを使用したハブアンドスポークトポロジです。 次のネットワークを使用します。左側-ブランチ、右側-メインサイト、メインオフィスなど。 フォールトトレランスの冗長リンク用。 デフォルト設定のEIGRPが起動されました。
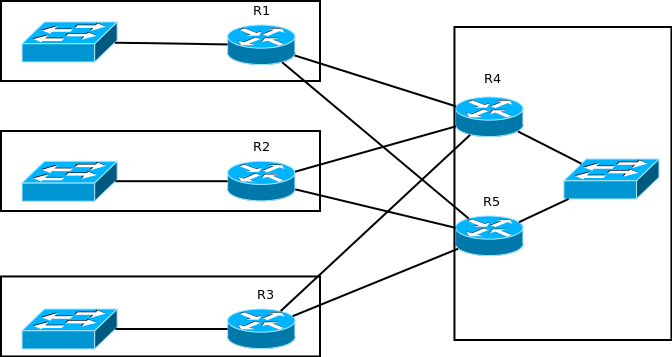
そして今、「注意、質問」:R1がR4との接続を失い、R5がLANを失った場合はどうなりますか? R1サブネットから本社オフィスサブネットへのトラフィックは、R1-> R5-> R2(またはR3)-> R4のルートを通ります。 それは効果的ですか? いや
トラフィック量の増加とその結果により、R1のサブネットだけでなく、R2(またはR3)のサブネットも影響を受けます。ここでは、そのような状況のスタブも考えられます。ブランチ内のルーターの背後には、他のサブネットにつながる他のルーターはありません;これが「道の終わり」であり、その後のみです。そのため、軽いハートでそれらをスタブとして構成できます。これにより、最初に上記の「曲線ルート」の問題が回避され、次にルートが失われた場合のクエリパケットのフラッドが回避されます。スタブルータにはさまざまな動作モードがあり、eigrp stubコマンドによって設定されます。R1(config)#router eigrp 1
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
デフォルトでは、eigrp stubコマンドを発行するだけで、接続モードと要約モードが有効になります。興味深いのは、受信専用モードです。このモードでは、ルーターはネットワークをアナウンスせず、近隣の発言のみをリッスンします(RIPには同じことを行うパッシブインターフェイスコマンドがありますが、EIGRPでは、選択したインターフェイスのプロトコルを完全に無効にします。近所を確立します)。記事に該当しなかったEIGRP理論の重要な点:EIGRPプラクティス
「エレベーターmi Up」はカリーニングラードに工場を購入しました。それらは、エレベータの頭脳を生み出します:超小型回路、ソフトウェア。工場は非常に大きく、市内の3つのポイントにあり、3つのルーターがリングで接続されています。 しかし、問題は、それらがすでにEIGRPを動的ルーティングプロトコルとして起動していることです。さらに、完全に異なるサブネットからのエンドノードのアドレス指定は10.0.0.0/8です。他のすべてのパラメーター(リンクアドレス、ループバックインターフェイスのアドレス)を変更しましたが、サーバー、プリンター、アクセスポイントを含むローカルネットワークの数千のアドレス(数時間動作しませんでした)は後で延期され、Kaliningradサブネット172の将来のために予約したIPプランで.32.0 / 20。現在、
しかし、問題は、それらがすでにEIGRPを動的ルーティングプロトコルとして起動していることです。さらに、完全に異なるサブネットからのエンドノードのアドレス指定は10.0.0.0/8です。他のすべてのパラメーター(リンクアドレス、ループバックインターフェイスのアドレス)を変更しましたが、サーバー、プリンター、アクセスポイントを含むローカルネットワークの数千のアドレス(数時間動作しませんでした)は後で延期され、Kaliningradサブネット172の将来のために予約したIPプランで.32.0 / 20。現在、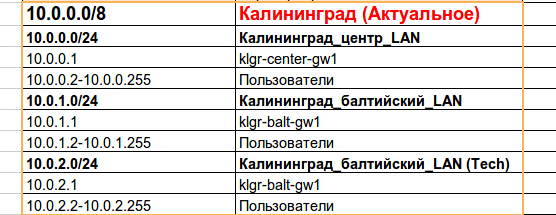
 このようなネットワークを使用しています。この奇跡はどのように構成されていますか?一見複雑でない:
このようなネットワークを使用しています。この奇跡はどのように構成されていますか?一見複雑でない:router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
EIGRP , , , (16 B — 172.16.0.0 8 8 — 10.0.0.0)
. router eigrp, №1. ( OSPF).
EIGRP : ( IOS 15).
:
10.0.0.1/24 klgr-center-gw1 :
klgr-center-gw1:
10.0.0.0/8はさまざまにサブネット化され、2つのサブネット、2つのマスク
D 10.0.0.0/8は要約、00:35:23、Null0
C 10.0.0.0/24は直接接続され、FastEthernet1 / 0
しかし、彼は10.0.1.0/24と10.0.2.0/24/klgr-balt-gw1が2つのネットワーク10.0.1.0/24と10.0.2.0/24について知っているわけではありませんが、ここではどこか10.0.0.0/24ですそれを隠した。10.0.0.0/8は
さまざまにサブネット化され、3つのサブネット、2つのマスクD 10.0.0.0/8は要約、00:42:05、Null0
C 10.0.1.0/24は直接接続され、FastEthernet1 / 1.2
C 10.0.2.0/24直接接続されている、FastEthernet1 / 1.3
どちらも、アドレスnext hop Null0でルート10.0.0.0/8を作成しました。ただし、klgr-center-gw2は、10.0.0.0 / 8サブネットが両方のWANインターフェイスの背後にあることを認識しています。D 10.0.0.0/8 [90/30720] 172.16.2.41経由、00:42:49、FastEthernet0 / 1
[90/30720] 172.16.2.45経由、00:38:05、FastEthernet0 / 0
非常に奇妙なことが起こっています。ただし、このルーターの構成を確認すると、おそらく次のことに気付くでしょう。ルーターeigrp 1
ネットワーク172.16.0.0
ネットワーク10.0.0.0
自動要約
自動集計が原因です。これはEIGRPの最大の悪です。何が起こっているのか、さらに詳しく考えてみましょう。 klgr-center-gw1およびklgr-balt-gw1には10.0.0.0/8のサブネットがあり、近隣に渡されるとデフォルトでそれらを要約します。つまり、たとえば、msk-balt-gw1は2つのネットワーク10.0.1.0/24と10.0.2.0/24を送信せず、1つの一般化されたネットワーク10.0.0.0/8を送信します。つまり、彼の隣人は、このネットワークがmsk-balt-gw1の背後にあると考えます。しかし、アドレス10.0.50.243のパケットが突然balt-gw1に到達すると、彼は何も知りません。この場合、いわゆるブラックホールルートが作成されます。10.0.0.0/ 8が要約、00 :42 :05、Null0受信したパケットはこのブラックホールにスローされます。これは、ルーティングループを回避するためです。したがって、これらのルーターは両方ともブラックホールルートを作成し、他の人のアナウンスを無視します。実際には、このようなネットワークでは、これら3つのデバイスは、自動要約をオフにするまで...相互にpingを実行できません。EIGRPを設定するときに最初に行うべきこと:ルーターEIGRP 1
自動要約なし
すべてのデバイス。そして、みんな大丈夫です:klgr-center-gw1:10.0.0.0/24はサブネット化され、3つのサブネット
C 10.0.0.0は直接接続され、FastEthernet1 / 0
D 10.0.1.0 [90/30720]は172.16.2.37、00:03:11、FastEthernet0 / 0
D 10.0.2.0 [90 / 30720] 172.16.2.37経由、00:03:11、FastEthernet0 / 0
klgr-balt-gw110.0.0.0/24はサブネット化され、3つのサブネット
D 10.0.0.0 [90/30720]は172.16.2.38を介して、00:08:16、FastEthernet0 / 1
C 10.0.1.0は直接接続され、FastEthernet1 / 1.2
C 10.0.2.0は直接接続済み、FastEthernet1 / 1.3
klgr-center-gw2:10.0.0.0/24はサブネット化され、3つのサブネット
D 10.0.0.0 [90/30720]は172.16.2.45を介して、00:11:50、FastEthernet0 / 0
D 10.0.1.0 [90/30720]は172.16.2.41を介して、00:11 :48、FastEthernet0 / 1
D 10.0.2.0 [90/30720] via 172.16.2.41、00 :11:48、FastEthernet0 / 1
タスクNo. 4KaliningradルーターのさまざまなQoSメカニズムの設定により、インターフェイスの帯域幅の値が変更されましたが、これらの値は正しくありません。したがって、遅延のみが考慮され、インターフェイスの帯域幅が考慮されないように、カリーニングラードルータのEIGRPメトリックの計算を変更する必要があることが決定されました。答え異なるプロトコル間のルート転送の構成
私たちのタスクは、これらのプロトコル間でのルートの転送を編成することです。OSPFからEIGRPへ、またはその逆に、すべてのサブネットへのルートを全員が把握できるようにします。これはルート再配布と呼ばれます。その実装には、2つのプロトコルが同時に起動される少なくとも1つのジャンクションポイントが必要です。msk-arbat-gw1またはklgr-balt-gw1にすることができます。2番目のものを選択します。EIGRPからOSPFへ:klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1サブネット
msk-arbat-gw1のルートを確認します。msk-arbat-gw1#sh ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 [110/20] via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
O E2 172.16.2.36/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.160.0/24 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 [110/20] 172.16.2.34経由、01:00:55、FastEthernet0 / 1.7
O 172.16.255.80/32 [110/2] 172.16.2.130、01:00:55 経由、FastEthernet0 / 1.8
O 172.16.255.96/32 [110/3] 172.16.2.130経由、00:13:21、FastEthernet0 / 1.8
[110/3] 172.16.2.197経由、00:13:21、FastEthernet1 / 0.911
O 172.16.255.112/ 32 [110/2] 172.16.2.197経由、00:13:31、FastEthernet1 / 0.911
198.51.100.0/28はサブネット化され、1つのサブネット
C 198.51.100.0は直接接続され、FastEthernet0 / 1.6
S * 0.0.0.0/0 [1 / 0] 198.51.100.1経由
E2というラベルの付いたものがあります-新しくインポートされたルート E2-これらが2番目のタイプの外部ルート(External)であることを意味します。つまり、OSPFからEIGRPへの外部NowからOSPF プロセスに導入されたことを意味します。これは少し複雑です。klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
メトリック(この長い数字のセット)を指定しないと、コマンドは実行されますが、再配布は行われません。インポートされたルートは、ルーティングテーブルのEXマークと、内部ルートの90ではなく170のアドミニストレーティブディスタンスを受け取ります。klgr-gw2#sh ip route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [ 170 /33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [ 90 /30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 [90/30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
[90/30720] via 172.16.2.46, 00:38:59, FastEthernet0/1
….
したがって、これを行うのは簡単に思えますが、単純さは表面的です。2つの異なるドメイン間に少なくとも1つの冗長リンクが追加されると、再配布には微妙で不快な瞬間が多くなります。普遍的なヒント-可能であれば再配布を避けるようにしてください。ここでは、主要なライフルールが機能します-シンプルなほど良いです。 問題番号5(RTでは不可能)モスクワのルーターは、ネットワーク上の他のすべてのルーターのデフォルトルートをアナウンスします。ただし、1に等しい同じメトリックを持つ他のすべてのルーターに到達し、ルート伝送ルートに沿ってメトリックが増加することはありません。便宜上、デフォルト設定を変更して、デフォルトで初期ルートメトリックが30になり、途中でデフォルトルートがネットワーク経由で転送されると、パスのコストが初期メトリックに追加されるようになりました。さらに、将来、モスクワにバックアップルーターを追加し、そこから別のデフォルトルートがプロバイダーを指すようにすることも可能です。バックアップルーターは、プライマリが消失した場合にのみ使用されるため、アドバタイズするデフォルトルートは異なるメトリックである必要があります。答えデフォルトルート
今こそあなたのインターネットアクセスをチェックする時です。モスクワからはそれ自体でうまく機能しますが、たとえばサンクトペテルブルクからチェックすると(すべての静的ルートを削除したことに注意してください):PC> ping linkmeup.ru
32バイトのデータを使用した192.0.2.2のping :
172.16.2.5からの返信:宛先ホストに到達できません。
172.16.2.5からの返信:宛先ホストに到達できません。
172.16.2.5からの返信:宛先ホストに到達できません。
172.16.2.5からの返信:宛先ホストに到達できません。
192.0.2.2のping統計:
パケット:送信済み= 4、受信済み= 0、損失= 4(100%損失)、
これは、spb-ozerki-gw1、spb-vsl-gw1、およびネットワーク上の誰もが静的に構成されているmsk-arbat-gw1を除き、デフォルトルートを認識していないためです。この状況を修正するには、モスクワで1つのコマンドを実行するだけで十分です。msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#デフォルト情報発信
その後、最後の希望のゲートウェイがどこにあるかについての情報がネットワークを介してあふれています。インターネットが利用可能になりました:PC> tracert linkmeup.ru
最大30ホップで192.0.2.2へのトレースルート:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2
トレース完了。
タスクNo. 6(RTでは実行不可) klgr-balt-gw1ルーターで、OSPFのEIGRPルートの再配布が設定されます。さらにネットワークに沿って、ルートは外部として送信されます。メトリックは20で、ルート送信ルートに沿って増加することはありません。ネットワーク上の外部ルートを転送するパスに沿って、パスのコストが外部ルートのメトリックに追加されるように、設定を変更する必要があります。答え便利なトラブルシューティングコマンド
1)ネイバーのリストとそれらとの通信状態は、show ip ospf neighborコマンドによって呼び出されますmsk-arbat-gw1:
ネイバーIDプリステートデッドタイムアドレスアドレスインターフェイス
172.16.255.32 1 FULL / DROTHER 00:00:33 172.16.2.2 FastEthernet0 / 1.4
172.16.255.48 1 FULL / DR 00:00:34 172.16.2.18 FastEthernet0 / 1.5
172.16.255.64 1 FULL / DR 00:00:33 172.16.2.34 FastEthernet0 / 1.7
172.16.255.80 1 FULL / DR 00:00:33 172.16.2.130 FastEthernet0 / 1.8
172.16.255.112 1 FULL / DR 00:00:33 172.16。 2.197 FastEthernet1 / 0.911
2)またはEIGRPの場合:show ip eigrp neighborsプロセス1のIP-EIGRPネイバー
アドレスインターフェイスホールドアップタイムSRTT RTO Q Seq
(sec)(ms)Cnt Num
0 172.16.2.38 Fa0 / 1 12 00:04:51 40 1000 0 54
1 172.16.2.42 Fa0 / 0 13 00 :04:51 40 1000 0 58
3)show ip protocolsコマンドを使用すると、動的ルーティングプロトコルの実行とそれらの関係に関する情報を表示できます。klgr-balt-gw1:Routing Protocol is «EIGRP 1 »
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: EIGRP 1, OSPF 1
Automatic network summarization is in effect
Automatic address summarization:
Maximum path: 4
Routing for Networks:
172.16.0.0
Routing Information Sources:
Gateway Distance Last Update
172.16.2.42 90 4
172.16.2.38 90 4
Distance: internal 90 external 170
Routing Protocol is «OSPF 1»
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.255.64
It is an autonomous system boundary router
Redistributing External Routes from,
EIGRP 1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.2.32 0.0.0.3 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.255.64 110 00:00:23
Distance: (default is 110)
4)プロトコルの動作をデバッグして理解するには、次のコマンドを使用すると便利です。debug ip OSPF events
debug ip OSPF adj
debug EIGRP packetsさまざまなインターフェイスを微調整して、デバッグで何が起こるか、どのメッセージが飛んでいるかを確認します。 問題番号7最後に、複雑なタスク。Lift mi Upの最後の会議で、KaliningradネットワークもOSPFに転送することが決定されました。移行は切断せずに完了する必要があります。 3つのカリーニングラードルーターでOSPFをEIGRPと並行して上げることが最善の選択肢であり、カリーニングラードルートに関するすべての情報がネットワークの残りの部分に広がっていることを確認した後、逆にEIGRPを無効にすることが決定されました。しかし、カリーニングラードネットワークは非常に大きく、多数のネットワークがあるため、カリーニングラードネットワークの変更が他のネットワークルーターでのSPFアルゴリズムの起動につながらないように、他のネットワークから分離する必要があると判断されました。答え。リリース資料
新しいIP計画、各ポイントおよび規制の切り替え計画、実験 装置の構成を含むRTファイル便利なリンク
私たちの素晴らしいアシスタントXGU.ru
CiscoOSPFのOSPFハブルの同僚
ドメイン間ルーティングループOSPFの外部タイプ1および外部タイプ2ルートの機能。 パート1OSPFの外部タイプ1および外部タイプ2ルートの作業の機能。 パート2その他
シスコウィキペディア 最小の自己宣伝ネットワークのロシアミニッツで 同じことは、独自のウェブサイト-linkmeup.ruを持っています。これで、LJだけでなく、このサイクルの個人ブログでもコメントを読んで、残すことができます。共著者であるマキシムのtheGluckに感謝の意を表したいと思います。編集と貴重なコメントについてはDmitry JDima、提供されたタスクについてはNatasha Samoilenkoにはたまらない。ブログ用のサイトをプログラミングしてくれた Anton Antuan。そして、サイトのロゴの栄光の名前ニーナを持つ少女。PS
今後のLinkMiapポッドキャストには、ジングルとバックグラウンドミュージックが必要です。私たちは喜んでお手伝いし、作曲家の名前は何世紀にもわたって称賛されます。PPS
Packet Tracerの機能はすでに不足しています。次のステップは、より深刻なものへの移行です。提案はありますか?IOU vs GNSのトピックに関するコメントにホリバーを配置することを提案します。