
この記事では、Android内のRenderscriptテクノロジーの動作について簡単に説明し、Intelプロセッサーを搭載したAndroidデバイスの特定の例でDalvikとパフォーマンスを比較し、renderscriptを最適化するための小さなテクニックを検討します。
Renderscriptは、2D / 3Dレンダリングと高性能数学計算の機能を含むAPIです。 大量のデータに対して同じタイプの独立したコンピューティングでタスクを記述し、マルチコアAndroidプラットフォームで迅速かつ並行して実行できる同種のサブタスクに分割できます。
このような技術は、画像処理、パターン認識、物理モデリング、セルオートマトンモデルなどに関連する多数のdalvikアプリケーションのパフォーマンスを向上させることができます。これらのアプリケーションは、ハードウェアの独立性を失うことはありません。
1. Android内のRenderscriptテクノロジー
Android内のRenderscriptテクノロジーのメカニズム、その長所と短所について簡単に説明します。
1.1 Renderscriptオフラインコンパイル
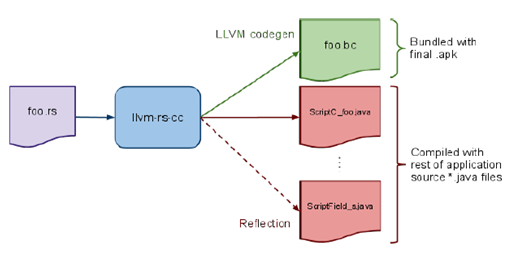
RenderscriptはHoneycomb / Android 3.0(API 11)でサポートされるようになりました。 つまり、Android SDKのplatform-toolsディレクトリでは、llvm-rs-cc(オフラインコンパイラー)がレンダリングスクリプト(* .rsファイル)をバイトコード(* .bcファイル)にコンパイルし、javaオブジェクトクラス(* .javaファイル)を生成します。 )構造の場合、renderscript内のグローバル変数とrenderscript自体。 llvm-rs-ccは、
LLVMコンパイラーのフロントエンドであるAndroid用の小さな変更を加えた
Clangコンパイラーに基づいています。
1.2 Renderscriptランタイムコンパイル
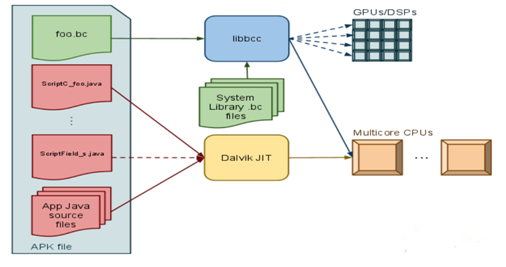
Androidは、LLVMバックエンドに基づいて構築されたフレームワークを導入しました。これは、バイトコードのランタイムコンパイル、必要なライブラリとのリンク、renderscriptの起動および実行制御を担当します。 このフレームワークは、次の部分で構成されています
。libbccは、バイトコード内の指定されたプラグマおよびその他のメタデータ、バイトコードのコンパイル、libRSの必要なライブラリとの動的リンクに従ってLLVMコンテキストを初期化します。
libRSには、ライブラリ(数学、時間、描画、参照カウントなど)、構造、およびデータ型(スクリプト、型、要素、割り当て、メッシュ、さまざまな行列など)の実装が含まれています。
 利点:
利点:- apkファイルに含まれるrenderscriptバイトコードは、実行時に起動されるプラットフォームのハードウェアコンピューティングモジュール(CPU)のマシンコードにコンパイルされるため、 ハードウェアに依存しないアプリケーションが取得されます。
- 計算の並列化、ランタイムコンパイラの最適化、ネイティブコードの実行により、実行速度が達成されます。
短所:- renderscriptを使用するための詳細なドキュメントがないため、アプリケーション開発が複雑になります。 すべては、 ここに提示されているレンダースクリプトランタイムAPIの簡単な説明に限定されています 。
- GPU、DSPでrenderscriptスレッドを実行するためのサポートの欠如。 異種メモリのスタートアップで共有メモリを管理する実行時バランススレッドに問題がある可能性があります。
2.ダルヴィクvs. モノクロ画像処理のレンダリングスクリプト
dalvik関数
Dalvik_MonoChromeFilter (カラーRGBイメージを白黒(モノクロ)に変換する)を考えてください:
private void Dalvik_MonoChromeFilter() { float MonoMult[] = {0.299f, 0.587f, 0.114f}; int mInPixels[] = new int[mBitmapIn.getHeight() * mBitmapIn.getWidth()]; int mOutPixels[] = new int[mBitmapOut.getHeight() * mBitmapOut.getWidth()]; mBitmapIn.getPixels(mInPixels, 0, mBitmapIn.getWidth(), 0, 0, mBitmapIn.getWidth(), mBitmapIn.getHeight()); for(int i = 0;i < mInPixels.length;i++) { float r = (float)(mInPixels[i] & 0xff); float g = (float)((mInPixels[i] >> 8) & 0xff); float b = (float)((mInPixels[i] >> 16) & 0xff); int mono = (int)(r * MonoMult[0] + g * MonoMult[1] + b * MonoMult[2]); mOutPixels[i] = mono + (mono << 8) + (mono << 16) + (mInPixels[i] & 0xff000000); } mBitmapOut.setPixels(mOutPixels, 0, mBitmapOut.getWidth(), 0, 0, mBitmapOut.getWidth(), mBitmapOut.getHeight()); }
何が言えますか? 多数のピクセルを「粉砕」する、独立した反復を行う単純なループ。 それがどれほど速く動くか見てみましょう!
実験では、新年の贈り物を運ぶレゴロボットでAndroid ICS 4.0.4および600x1024の画像を備えたIntel Atom Z2460 1.6GHzでMegaFon Mintを撮影します。


次のスキームに従って、処理にかかった時間を測定します。
private long startnow; private long endnow; startnow = android.os.SystemClock.uptimeMillis(); Dalvik_MonoChromeFilter(); endnow = android.os.SystemClock.uptimeMillis(); Log.d("Timing", "Excution time: "+(endnow-startnow)+" ms");
「タイミング」でタグ付けされたメッセージは、
ADBを使用して取得できます。 数十回の測定を行い、その前にデバイスを再起動し、測定結果の広がりが小さいことを確認します。
dalvik実装による画像処理時間は353ミリ秒でした。注:マルチスレッドツール(たとえば、個別のスレッドで実行されるタスクを記述するAsyncTaskクラス)を使用
すると、最良の場合、 Intel Atom Z2460 1.6GHzに2つの論理コアが存在するため、ダブルアクセラレーションを絞り出すことができます。
次に、同じフィルターの
RS_MonoChromeFilterの renderscript実装を検討します。
private RenderScript mRS; private Allocation mInAllocation; private Allocation mOutAllocation; private ScriptC_mono mScript; … private void RS_MonoChromeFilter() { mRS = RenderScript.create(this); mInAllocation = Allocation.createFromBitmap(mRS, mBitmapIn, Allocation.MipmapControl.MIPMAP_NONE, Allocation.USAGE_SCRIPT); mOutAllocation = Allocation.createTyped(mRS, mInAllocation.getType()); mScript = new ScriptC_mono(mRS, getResources(), R.raw.mono); mScript.forEach_root(mInAllocation, mOutAllocation); mOutAllocation.copyTo(mBitmapOut); }
注: dalvikの実装のパフォーマンスを評価します。
renderscript実装による同じ画像の処理時間は112ミリ秒でした。3.2倍のパフォーマンス向上が得られました(dalvikとrenderscriptのランタイム比較:353/112 = 3.2)。
注: renderscript実装の動作時間には、renderscriptコンテキストの作成、必要なメモリの割り当てと初期化、renderscriptの作成とコンテキストへのバインド、mono.rsでのルートとしての作業が含まれます。
注:モバイルアプリケーション開発者にとって重要な場所は、生成されるapkファイルのサイズです。 この実装では、apviファイルのサイズは、dalvikの実装と比較して、バイトコード(* .bcファイル)のレンダースクリプトのサイズだけ増加できます。 私の場合、dalvikバージョンのサイズは404KB、renderscriptバージョンのサイズは406KBで、そのうち2KBはrenderscriptバイトコード(mono.bc)です。
3. renderscriptの最適化
Renderscriptの現在のパフォーマンスは、実数を使用した算術演算の精度を少し放棄することで改善できますが、これは当面のタスクでは原則的ではありません。 これを行うには、プラグマ
rs_fp_impreciseをrenderscriptに追加
します 。
この結果
、renderscriptの実装で112ミリ秒のパフォーマンスがさらに10%向上します。 -> 99ミリ秒。注:結果として、アーティファクトや歪みのない視覚的に同じモノクロ画像を取得します。
注: renderscriptには、NDKとは異なり、ランタイムコンパイラの最適化を明示的に制御するメカニズムがありません。 コンパイラキーは、各プラットフォーム(x86、ARMなど)のAndroid内に事前登録されています。
4. dalvikおよびrenderscript実装のランタイムの画像サイズへの依存
次の質問を検討します。各実装の動作時間は、処理されたイメージのサイズにどのように依存しますか? これを行うには、サイズ300x512、600x1024(レゴロボットを使用した元の画像)、1200x1024、1200x2048の4つの画像を取得し、対応するモノクロ画像処理時間を測定します。 結果を以下のグラフと表に示します。
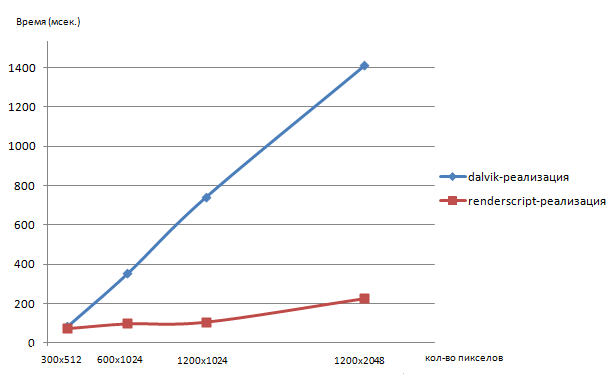
| 300x512 | 600x1024 | 1200x1024 | 1200x2048 |
| ダルビク | 85 | 353 | 744 | 1411 |
| レンダースクリプト | 75 | 99 | 108 | 227 |
| 勝つ | 1.13 | 3.56 | 6.8 | 6.2 |
renderscriptとは異なり、画像サイズに対するdalvikの線形の時間関係に注意してください。 この違いは、renderscriptコンテキストの初期化時間によって説明できます。
比較的小さなサイズの画像の場合、ゲインは重要ではありません。 renderscriptコンテキストの初期化時間は約50〜60ミリ秒です。 ただし、Androidデバイスで最もよく使用される中サイズの画像では、ゲインは4〜6倍になります。
おわりに
この記事では、さまざまなサイズのモノクロ画像処理のdalvikおよびrenderscriptの実装について検討しました。 並列化、コンパイラの最適化、ネイティブコードの実行により、renderscriptは中サイズのイメージのパフォーマンスでdalvikを大幅に上回ります。 この小さな例を使って、renderscriptがアプリケーションのパフォーマンスを改善するためのアシスタントになり、同時にデバイスに依存しないようにすることを試みました。