
ITスペシャリストの場合は、
1月2日に仕事に出かけることはできません。サイキックの戦いの第3シーズンをレビューしたり、NTVでゴードンプログラムを記録したり(
メンタルテイストの問題)。
他の従業員があなたに間違いなく贈り物を持っているので、それは不可能です。秘書はコーヒーを使い果たし、MPは期限を使い果たし、データベース管理者は
健忘症を持ちます。
Hadoopチームのエンジニアも、新年のサプライズでお互いを甘やかすのが好きであることがわかりました。
2008年
1月2日 以下で説明するイベントに参加している人の感情的および心理的状態の詳細な説明がないため、すぐに事実に
戻ります。MAPREDUCE-279Map -Reduce 2.0タスクが配信されました。 数についての冗談を残した後、Hadoopの最初の安定バージョンが4年弱であるという事実に注目します。
この期間中、Hadoopプロジェクトは、2005年に開始された小さな革新的な雪玉から、2012年にITに迫る大きな雪玉へと進化します。
以下では、Hadoopプラットフォームの進化において、MAPREDUCE-279の1月のタスクが果たした重要性(そして2013年に確実に果たすことになる)の把握を試みます。
2011
2011年2月、Yahooのエンジニアは記事「Apache Hadoop MapReduceの次世代」[2]で世界中を喜ばせました。 2011年10月、Apache Software Foundationは、「Apache Hadoop NextGen MapReduce(YARN)」[1]というタイトルのウィキ作品で公開しました。 12月27日、Apache Software FoundationのWebサイトに次のような碑文がありました。
...リリース1.0.0が利用可能です。 妊娠6年後、Hadoopは1.0.0に達しました!
また、リンクはHadoop v1.0の安定バージョンです。
2012
Hadoop 2.0.0-alphaは、5月末にダウンロードできるようになりました。 5月、Hadoop:The Definitive Guide、Third Edition(Tom White著)が出版され、かなりの量がYARNに割り当てられています。 6月上旬、Tom WhiteはChicago Hadoop User GroupでMapReduce 2.0(
ビデオ )のプレゼンテーションを行いました。 同じ月に、ClouderaはCDH4製品でHadoop 2.0.0 Alphaのサポートを発表しました。 少し後に、HortonworksはディストリビューションでのHadoop 2.0のサポートも発表しました。
9月17日、Apache Software Foundationは、YARNとMapReduce v2がHadoop 0.23.3で利用できることを発表しました。
以下では、従来のHadoop MapReduceと新しいアーキテクチャでの分散コンピューティングへのアプローチを検討し、新しいモデルの概念を実装する手法とコンポーネントを説明し、従来のアーキテクチャと2.0アーキテクチャを比較します。1. Hadoop MapReduce Classic
Hadoopは、大規模並列処理(MPP)データ用の分散アプリケーションを構築するための一般的なソフトウェアフレームワークです。
Hadoopには次のコンポーネントが含まれます。
- HDFS-分散ファイルシステム。
- Hadoop MapReduce-マップ/削減パラダイムのフレームワーク内で大量のデータの分散コンピューティングを実行するためのソフトウェアモデル(フレームワーク)。
Hadoop MapReduceアーキテクチャと
HDFS構造に組み込まれた概念は、単一障害点など、コンポーネント自体に多くのボトルネックを引き起こしています。 最終的にHadoopプラットフォーム全体の制限を決定しました。
後者には以下が含まれます。
- Hadoopクラスターのスケーラビリティ制限 :〜4Kコンピューティングノード; 〜40Kの並列ジョブ。
- 分散アルゴリズムを実装する分散コンピューティングフレームワークとクライアントライブラリの強力な接続性 。 その結果:
- 分散コンピューティングを実行するための代替ソフトウェアモデルのサポートの欠如:Hadoop v1.0では、map / reduce計算モデルのみがサポートされます。
- 単一障害点が存在し、その結果、高い信頼性が要求される環境で使用できない。
- バージョンの互換性の問題 :Hadoopプラットフォームを更新する(新しいバージョンまたはサービスパックをインストールする)際のクラスターのすべてのコンピューティングノードの1回限りの更新の要件。
- 更新された/ストリーミングデータの操作に対するサポートの欠如。
新しいHadoopアーキテクチャは、上記の制限の多くを取り除くことを目的としていました。
Hadoop 2.0のアーキテクチャと、Hadoop 2.0が克服できる制限について、以下で説明します。
2. Hadoop MapReduce Next
大きな変更は、Hadoop MapReduceの分散コンピューティングコンポーネントに影響を与えました。
従来のHadoop MapReduceは、単一の
JobTrackerプロセスと任意の数の
TaskTrackerプロセスでした。
新しいHadoop MapReduceアーキテクチャでは、JobTrackerのリソース管理とジョブスケジューリング/調整機能が2つの別個のコンポーネントに分割されました。
- ResourceManager リソースマネージャー
- ApplicationMasterプランナーおよびコーディネーター。
各コンポーネントをさらに詳しく見てみましょう。
リソースマネージャー
ResourceManager (RM)は、アプリケーションによって要求されたリソースを配布し、これらのアプリケーションが実行されているコンピューティングノードを監視するタスクを持つグローバルリソースマネージャーです。
ResourceManagerには、次のコンポーネントが含まれます。
- スケジューラは、リソースを必要とするアプリケーション間でリソースを割り当てる責任があるスケジューラです。
スケジューラは「クリーン」なスケジューラです。アプリケーションの状態を監視または監視しません。
- ApplicationsManager (AsM)は、ApplicationMasterインスタンスを起動し、実行が実行されるノード(コンテナ)を監視し、「デッド」ノードを再起動するコンポーネントです。
ResourceManagerのスケジューラがプラグ可能なコンポーネントであることは注目に値します。 スケジューラには、FIFOスケジューラ(デフォルト)、キャパシティスケジューラ、フェアスケジューラの3種類があります。 Hadoop 0.23バージョンでは、最初の2種類のスケジューラーがサポートされていますが、3番目のスケジューラーはサポートされていません。
Containerの抽象概念については、RMからリソースが要求されます。これについては、後で説明します。必要なプロセッサー時間、RAMの量、必要なネットワーク帯域幅などのパラメーターを設定できます。 2012年12月現在、「RAM容量」パラメーターのみがサポートされています。
はじめにRMでは、クラスターノードをコンピューティングリソースとして扱うことができます。これにより、クラスターリソースの使用率が質的に向上します。
アプリケーションマスター
ApplicationMaster (AM)は、ライフサイクルの計画、調整、および分散アプリケーションの実行ステータスの監視を担当するコンポーネントです。 各アプリケーションには、ApplicationMasterの独自のインスタンスがあります。
このレベルでは、YARNを検討する価値があります。
YARN (Yet Another Resource Negotiator)は、分散アプリケーションを実行するためのソフトウェアフレームワークです(これはApplicationMasterです)。 YARNは、分散型アプリケーションの開発に必要なコンポーネントとAPIを提供します。 フレームワーク自体が、実行中のアプリケーションからのリソースの要求に応じてリソースの割り当てを担当し、アプリケーション実行のステータスを監視します。
YARNモデルは、従来のHadoop MapReduceで実装されたモデルよりも一般的です。
YARNのおかげで、Hadoopクラスター上のアプリケーションのマップ/削減だけでなく、Open MPI、Spark、Apache HAMA、Apache Giraphなどを使用して作成された分散アプリケーションも実行できます。 他の分散アルゴリズムを実装することも可能です(ここではOOPの強みです!)。 詳細な
手順は 、Apache Wikiで説明されています。
次に、
MapReduce 2.0 (またはMR2、またはMRv2)は、MAP / reduceプログラミングモデルのフレームワーク内で分散コンピューティングを実行するためのフレームワークであり、YARNレベルの上に「横たわっています」。
リソース管理とアプリケーションライフサイクルの計画/ ResourceManagerとApplicationMasterコンポーネント間の調整の責任の分離により、Hadoopプラットフォームがより分散されました。 これは、プラットフォームのスケーラビリティにプラスの効果をもたらしました。
NodeManager
NodeManager (NM)-計算ノード上で実行されているエージェント。
- 使用済みのコンピューティングリソース(CPU、RAM、ネットワークなど)の追跡。
- ResourceManager / Schedulerリソースマネージャのスケジューラに使用済みリソースに関するレポートを送信します。
相互作用プロトコル
Hadoopプラットフォームのさまざまなコンポーネントへの制御コマンドとステータス転送は、次のプロトコルを通過します。
- ClientRMProtocol-クライアントのResourceManagerとのやり取りのためのプロトコルで、アプリケーションの起動、ステータスの確認、終了を行います。
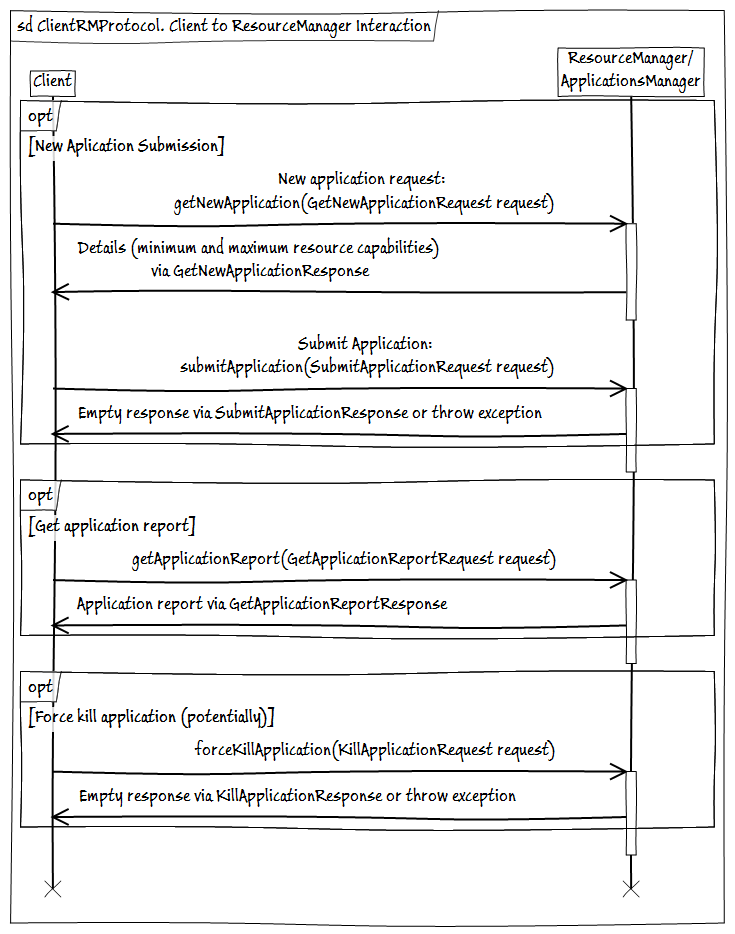
- AMRMProtocol -ApplicationMasterインスタンスとResourceManagerとの相互作用のためのプロトコルで、AMのサブスクライブ/サブスクライブ解除、リクエストの送信、RMからのリソースの受信を行います。
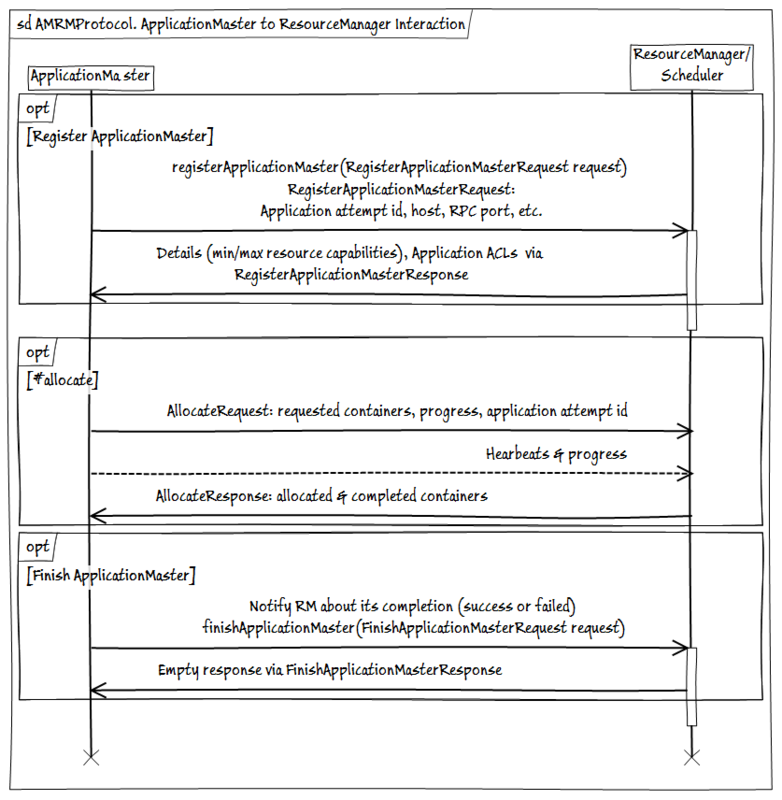
- ContainerManager -NMによって管理されるコンテナの開始/停止およびステータス取得のためのNodeManagerとのApplicationMaster対話プロトコル。

3. Hadoop MapReduce。 に対して
「Hadoop MapReduce Classic」のパート1では、Hadoopプラットフォームの概要を説明し、プラットフォームの主な制限について説明します。 Hadoop MapReduceのパート2では、新しいバージョンのHadoop MapReduce Distributed Computing Frameworkで導入された概念とコンポーネントについて説明しました。
YARN、MR2の概念とこれらの概念を実装するコンポーネントがHadoopプラットフォームの分散コンピューティングのアーキテクチャをどのように変更し、これらの変更が既存のプラットフォームの制限を回避するのに役立つ(またはしない)方法について説明します。
-用語について
以降では、以下を回避するために、Hadoop MapReduceのクラシックバージョンと「2.0」バージョンの比較について説明します。
- 議論されているバージョンに関連する曖昧さ、および/または
- 問題のバージョンの無限の改良、
次の
条件付き用語を引き続き使用します。
- Hadoop MapReduce 1.0- 「クラシック」プレーン(特に指定がない限り)Hadoop MapReduce;
- Hadoop MapReduce 2.0はYARNおよびMapReduce v2.0です。
-
建築
Hadoop MapReduce 1.0では、クラスターには、タスクを直接実行する複数のTaskTrackerノードにタスクを分散する単一のJobTrackerノードがあります。
新しいHadoop MapReduceアーキテクチャでは、リソース管理の責任とアプリケーションライフサイクルのスケジューリング/調整は、それぞれResourceManager(クラスターごと)とApplicationMaster(アプリケーションごと)の間で共有されます。
各コンピューティングノードは、CPU、RAMなどの所定量のリソースを含む任意の数の
コンテナコンテナに分割されます。 コンテナの監視はNodeManager(ノードごと)によって行われます。
以下は、クラシックバージョンのアーキテクチャにおけるHadoop MapReduceの個々のコンポーネントの相互作用の図解です
YARNのようなアーキテクチャ(コンポーネント間の新しいタイプの通信は太字で強調表示されています)。
次に、新しいHadoop MapReduceアーキテクチャが、可用性、スケーラビリティ、リソース使用率などのプラットフォームの側面にどのように影響したかを見ていきます。
在庫状況
Hadoop MapReduce 1.0では、JobTrackerがクラッシュし、JobTrackerを特別なログから読み取ることで再起動する必要があり、最終的にクラスターのダウンタイムにつながります。
新バージョンのアクセシビリティソリューションは、質的には新しいレベルに達していませんが、それでも事態は悪化していません。 Hadoop MapReduce 2.0は、次の方法で高可用性の問題を解決します。ResourceManagerおよびApplicationMasterコンポーネントの状態が保存され、最後に正常に保存された状態のロードに失敗した場合にリストされたコンポーネントを自動的に再起動するシステムが提供されます。
ResourceManagerの場合、Apache ZooKeeperは状態の永続性を処理します。 また、リソースマネージャーに障害が発生すると、障害が発生する前の状態で新しいRMプロセスが作成されます。 したがって、RM障害の結果は、すべての計画および実行中のアプリケーションが再起動することです。
ApplicationMasterは、独自のチェックポイントエンジンを使用します。 その過程で、AMはその状態をHDFSに保存します。 AMが利用できなくなると、RMはスナップショットからの状態でAMを再起動します。
拡張性
Hadoop MapReduce 1.0を使用する開発者は、Hadoopクラスターのスケーラビリティの制限が4Kマシンの領域にあることを繰り返し指摘しています。 この制限の主な理由は、JobTrackerノードがアプリケーションのライフサイクルに関連するタスクにかなりの量のリソースを費やすことです。 後者は、クラスター全体ではなく、特定のアプリケーションに固有のタスクに起因する可能性があります。
ResourceManagerとApplicationMasterの間で異なるレベルのタスクの責任を共有することは、おそらくHadoop MapReduce 2.0の主要なノウハウになっています。
Hadoop MapReduce 2.0は、最大10K +計算ノードのクラスターで実行できるように計画されています。これは、Hadoop MapReduceのクラシックバージョンと比較して大幅な進歩です。
リソース使用率
クラスターリソースをマップスロットとリデューススロットにハードに分割することによるリソースの低い使用率は、多くの場合、従来のHadoop MapReduceに対する批判の対象でもあります。 MapReduce 1.0のスロットの概念は、交換可能な分離リソースのセットであるユニバーサル
コンテナーの概念に置き換えられました。
実際、Hadoop MapReduce 2.0での「
コンテナ 」の概念の導入により、Hadoopプラットフォームに別のプロパティである
マルチテナンシーが追加されました。 コンピューティングリソースとしてのクラスターノードに対する態度は、リソース使用率に対するスロットの悪影響を取り除くのに役立ちます。
つながり
Hadoop MapReduce 1.0のアーキテクチャ上の問題の1つは、分散コンピューティングフレームワークと分散アルゴリズムを実装するクライアントライブラリという、相互依存ではない2つのシステムの強力な接続性でした。
この接続により、HadoopクラスターでMPIまたはその他の代替マップ/削減、分散アルゴリズムを実行できなくなりました。
新しいアーキテクチャでは、分散コンピューティングフレームワークYARNと、YARN-MR2に基づくマップ/削減プログラミングモデルのフレームワーク内のコンピューティングフレームワークが強調表示されました。
MR2はApplicationMasterが提供するアプリケーション固有のフレームワークであり、YARNはResourceManagerとNodeManagerのコンポーネントによって「表され」、分散アルゴリズムの仕様から完全に独立しています。
オフスクリーン
2つの側面は言うまでもありませんが、完全な図はありません。
1.この記事では、分散コンピューティングフレームワークのみを検討しました。
記事の範囲外で、データウェアハウスに影響する変更がありました。 これらの中で最も注目すべきは、HDFSネームノードの高可用性とHDFSネームノードのフェデレーションです。
2.上記はHadoop v2.0にのみ実装されます(執筆時点でアルファ版が利用可能です)。 そのため、YARNとMR2はHadoop v0.23ですでに利用可能ですが、高可用性NameNodeのサポートはありません。
それとは別に、冒頭で述べた6月のシカゴHUG 2012カンファレンスで、Tom WhiteがHadoop 2.0 Alphaのパフォーマンス、セキュリティ、およびResourceManagerに関連する作業がまだあると述べました。
おわりに
2010年のHadoopプロジェクトは、
アイデア 、2011年に
は流通の
スピード 、2012年に
は変化の
規模に見舞われた
アイデアに喜んでいた。
HadoopプラットフォームでYARNとMR2が変更されたことの「従来の」要約に時間を浪費しません。 これは間違いなくプラットフォームの定性的な飛躍です。
Hadoopは、ビッグデータ関連タスクの事実上の業界標準のようになりました。 バージョン2.0の今後のリリースにより、開発者は、マップ/リデュースプログラミングモデルのみで「ループ」されない、オープンで、フォールトトレラントで、非常にスケーラブルで拡張可能な大規模並列処理ツールを利用できます。
それはすごいですね。 これが非常に現実に近いことはさらに信じられません。 警告が1つだけあります。
この現実に備えてください 。
ソースのリスト
[1]
Apache Hadoop NextGen MapReduce(YARN) 。 Apache Software Foundation、2011。
[2] Arun C Murthy。
次世代のApache Hadoop MapReduce 。 Yahoo、2011年。
[3]アーメド・ラドワン。
Hadoop 0.23のMapReduce 2.0 Cloudera、2012年。
[4]トム・ホワイト。 Hadoop:決定版ガイド、第3版。 O'Reilly Media / Yahoo Press、2012年。
[5]
Apache Hadoop Main 2.0.2-alpha API 。 Apache Software Foundation、2012。
著者の追記およびその他の経験
* Clouderaを使用すると、CDH4ディストリビューション(YARNサポート付き)をダウンロードして、擬似分散モードでローカルマシンで実行できます。
配布と指示 。