みなさんこんにちは。 以前の投稿で、いくつかの基本的な分類方法について話しました。 今日、最後の宿題の詳細のため、投稿はメソッド自体についてではなく、データ処理と結果のモデルの分析についてです。
挑戦する
データは、ミュンヘン大学統計学部から提供されました。 ここで、データセット自体とデータ自体の
説明を取得できます(フィールド名はドイツ語で表示されます)。 データにはローンアプリケーションが含まれ、各アプリケーションは20個の変数で記述されます。 さらに、各申請書は、申請者が融資を受けたかどうかに対応しています。 ここで、変数の意味を詳しく見ることができます。
私たちのタスクは、1人または別の申請者によって下される決定を予測するモデルを構築することでした。
 残念ながら
残念ながら 、
MNISTで行われたように、モデルをテストするためのテストデータとシステムはありません
でした 。 この点で、モデルを検証するという点で想像力の範囲がありました。
データの前処理
最初に、データ自体を見てみましょう。 次のグラフは、存在する場合に利用可能なすべての変数の分布のヒストグラムを示しています。 変数を表示する順序は、明確にするために特別に変更されています。


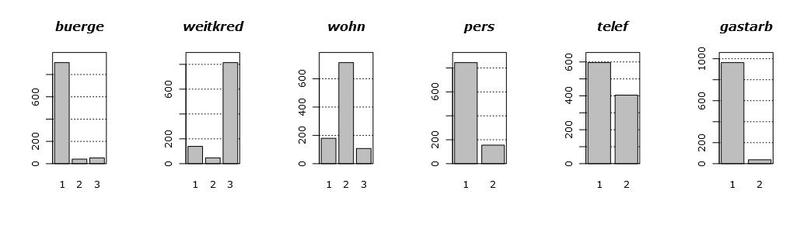
これらのグラフを見ると、いくつかの結論が導かれます。 第一に、私たちが持っている変数のほとんどは、実質的にカテゴリに分類されています。つまり、それらは2、3の値しか取りません。 第二に、条件付き連続変数は2つ(まあ、たぶん3つ)、つまり
hoeheと
alterだけです。 第三に、明らかに排出物はありません。
連続変数を扱う場合、一般的に言えば、その分布のタイプについてはかなり多くのことが許されます。 たとえば、密度が奇妙な丘陵形状で、いくつかのピークがある場合のマルチモダリティ。 同様の何かが変数
laufzeitの密度のグラフで見ることができます。 ただし、分布の引き伸ばされたテールは、モデルの構築における主要な頭痛の種です。なぜなら、それらは、プロパティと外観に大きく影響するからです。 エミッションは構築されたモデルの品質にも大きく影響しますが、幸運であり、それらがないため、次回はエミッションについて説明します。
尾に戻ると、変数
hoeheと
alterは1つの特徴を持っています:それらは正常ではありません。 つまり、強い右尾の観点から、これらは対数正規に非常に似ています。 上記のすべてを考えると、これらのテールをプリロードするためにこれらの変数を前置する何らかの理由があります。
兄弟の強さは何ですか? それとも、これらすべての人々の変数は誰ですか?
多くの場合、分析を行う際に、いくつかの変数は不要です。 それは、まあ、絶対にです。 これは、分析から除外した場合、問題を解決する際に、最悪の場合でもほとんど何も失うことを意味します。 クレジットスコアリングの場合、損失により、分類の精度がわずかに低下します。
これは最悪の場合に起こることです。 ただし、実践で
は 、一般的に
機能選択と呼ばれる変数を慎重に選択すると、正確に勝つことさえできることが
示されています。 重要でない変数はモデルにノイズのみを持ち込み、結果にはほとんど影響しません。 そして、それらの多くが行くとき、穀物をもみ殻から分離する必要があります。
実際には、この問題は、データが収集されるまでに、どの変数が分析で最も重要になるかを専門家がまだ知らないという事実により発生します。 同時に、実験自体とデータ収集の間、誰も実験者がわざわざ収集できるすべての変数を収集する必要はありません。 たとえば、すべてを収集し、アナリストがそれを何らかの方法で整理します。
変数を賢くカットする必要があります。 たとえば、可変ガスターブの場合に、形質の出現頻度に関するデータを単純にカットすると、非常に重要な形質が除外されないことを保証できません。 一部のテキストデータまたは生物学データでは、どの変数がゼロ以外の値を取るかは一般的に非常にまれなので、この問題はさらに顕著になります。
記号の選択に関する問題は、データを引き継ぐ各モデルについて、このモデル専用に作成された記号の選択基準が異なることです。 たとえば、線形モデルの場合
、係数の有意性にはt統計が使用され、 ツリーのカスケード内の変数の相対的な有意性にはランダムフォレスト
が使用され ます 。 また、一般的に機能選択を
モデルに明示的に組み込むことができます。
簡単にするために、線形モデルの変数の重要性のみを考慮します。 一般化線形モデルGLMを作成するだけです。 ターゲット変数はクラスラベルであるため、(条件付き)二項分布になります。 Rのglm関数を使用して、このモデルを構築し、その内部を見て、概要を呼び出します。 その結果、次のプレートが得られます。

最後のコラムに興味があります。 この列は、係数がゼロである、つまり最終モデルで役割を果たさない確率を示します。 ここでのアスタリスクは、係数の相対的な重要性を示しています。 表から、一般的に言えば、
laufkont 、
laufzeit 、
moral 、
sparkontを除くほとんどすべての変数を容赦なく切り取ることができることが
わかります (
切片はシフトパラメーターです。これも必要です)。 得られた統計に基づいてそれらを選択しました。つまり、これらは「離陸時」の統計が0.01以下の変数です。
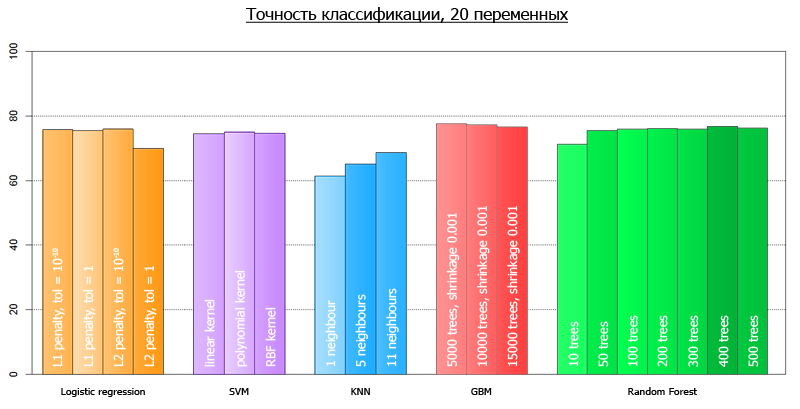
線形モデルがデータをオーバーシュートしないと仮定して、モデルの検証に目を向けると、仮説の妥当性を検証できます。 つまり、すべてのデータで2つのモデルの精度をテストします。4つの変数を含むモデルと20を含むモデルです。 20変数の場合、分類精度は77.1%であり、4変数のモデルの場合は76.1%です。 どうやら、非常に申し訳ありません。
おもしろいことに、私たちがプロロージャー化した変数がモデルに影響しなかったのです。 前対数的dzhadと同様に前対数的であることは決して重要ではなく、0.1にも達しませんでした。
分析
Scikitを使用して、Pythonで分類子自体を構築することにしました。 分析では、scikitが提供するすべての主要な分類子を使用し、何らかの方法でそれらのハイパーパラメーターを使用することにしました。 起動されたもののリストは次のとおりです。
- GLM
- SVM
- kNN
- ランダムフォレスト
- en.wikipedia.org/wiki/Gradient_boosting
記事の最後-これらのアルゴリズムを実装するクラスに関するドキュメントへのリンク。
出力を明示的にテストする機能がないため、相互検証方法を使用しました。 フォールドの数として10を使用したため、10のフォールドすべてから分類精度の平均値を導き出しました。
実装は非常に透過的です。
コードを表示from sklearn.externals import joblib from sklearn import cross_validation from sklearn import svm from sklearn import neighbors from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression import numpy as np def avg(x): s = 0.0 for t in x: s += t return (s/len(x))*100.0 dataset = joblib.load('kredit.pkl')
スクリプトを起動した後、次の結果が得られました。
| パラメータ付きメソッド | 4変数の平均精度 | 20変数の平均精度 |
|---|
| ロジスティック回帰、L1メトリック | 75.5 | 75.2 |
| 線形カーネルを使用したSVM | 73.9 | 74.4 |
| 多項式カーネルを使用したSVM | 72.6 | 74.9 |
| rbfカーネルを使用したSVM | 74.3 | 74.7 |
| kNN 1ネイバー | 68.8 | 61.4 |
| kNN 5ネイバー | 72.1 | 65.1 |
| kNN 11近傍 | 72.3 | 68.7 |
| 勾配ブースティング5000本の木の収縮0.001 | 75.0 | 77.6 |
| 勾配ブースティング10000本の木の収縮0.001 | 73.8 | 77.2 |
| 勾配ブースティング15000本の木の収縮0.001 | 73.7 | 76.5 |
| ランダムフォレスト10 | 72.0 | 71.2 |
| ランダムフォレスト50 | 72.1 | 75.5 |
| ランダムフォレスト100 | 71.6 | 75.9 |
| ランダムフォレスト200 | 71.8 | 76.1 |
| ラドムフォレスト300 | 72.4 | 75.9 |
| ランダムフォレスト400 | 71.9 | 76.7 |
| ランダムフォレスト500 | 72.6 | 76.2 |
より明確に、それらは次のチャートで視覚化できます:
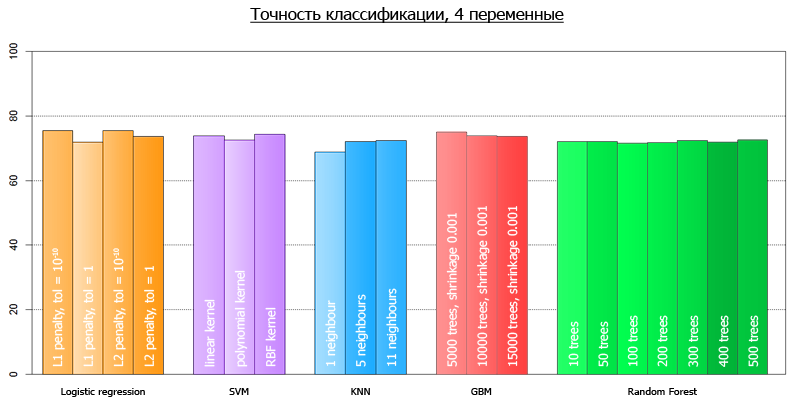
4変数のすべてのモデルの平均精度は72.7です
全変数の全モデルの平均精度は73.7です。
記事の冒頭で予測されたものとの不一致は、これらのテストが異なるフレームワークで実行されたという事実によって説明されます。
結論
モデルの精度の結果を見ると、いくつかの興味深い結論を導き出すことができます。 線形モデルと非線形モデルのパックを作成しました。 その結果、これらのモデルはすべて、データ上でほぼ同じ精度を示しています。 つまり、RFやSVMなどのモデルは、線形モデルと比較して精度の点で大きな利点はありませんでした。 これはおそらく、初期データが何らかの種類の線形依存によってほぼ確実に生成されたという事実によるものです。
この結果、ランダムフォレスト、SVM、勾配ブースティングなどの複雑で大規模な方法を使用して、このデータを正確に追跡しても意味がありません。 つまり、このデータで捕捉できるすべてのものは、すでに線形モデルで捕捉されています。 それ以外の場合、データに明示的な非線形依存関係があれば、この精度の違いはより重要になります。
これは、データが見た目ほど複雑ではない場合があり、非常に迅速にデータを絞り出すことができる最大値に到達できることを示しています。
さらに、特性の選択を使用して大幅に削減されたデータから、我々の精度は実質的に影響を受けませんでした。 つまり、このデータに対する当社のソリューションは、シンプル(安価)であるだけでなく、コンパクトでもありました。
ドキュメント
ロジスティック回帰(GLMの場合)SVMkNNランダムフォレスト勾配ブースティングさらに、相互検証の使用
例を次に示します。
この記事の執筆にご協力ください
。GameChangersのData MiningトラックとAlexei Natekinに感謝します。