
BadooはCおよびC ++で多くのサービスを使用しますが、そのほとんどは大量のデータを処理します。 原則として、サービスは「高速キャッシュ」または「高速データベース」として機能します。 同じタイプのデータの配列でさまざまな操作を実行します。 データにすばやくアクセスするために、Judy配列を長く使用してきました。 しかし、一度奇妙なことを望んだ:PHPで整数の大きな配列を処理し、すぐにJudyを思い出した。
ちょっとした歴史
Judyアレイは、2000年初頭にダグラスバスキンスによって発明されました。 彼らの開発プロジェクトはHPによって資金提供されましたが、約2年後に閉鎖されました。 この間に、4つのバージョンがリリースされ、後者の開発には1年以上かかり、開発者はJudyを半分にスピードアップし、メモリ消費を半分に減らすことができましたが、これは簡単な価格ではありませんでした。 -桁違い。
Judyアレイを動作させるアルゴリズムは
特許取得済みですが、Cでの元の実装はLGPLライセンスの下で
公式Webサイトで入手できます。
開発者がより良い選択肢を思い付くことができなかったため、プロジェクトはシスターバスキンスにちなんで命名されました。
ツリー配列
実際、Judy配列は配列そのものではありません。 ジュディは
トライの開発、すなわち さまざまな圧縮手法を使用したプレフィックスツリー。 Judy配列は、C配列および標準のハッシュ配列の実装と比較して有利です。まばらなJudy配列は、メモリを効率的に使用し、完全にスケーリングしながら、同等の読み取りおよび書き込み速度を示します(
ベンチマークを参照)。
Judy作業アルゴリズムの詳細な説明がHabrの記事の形式に収まる可能性は低いため、公式ドキュメントへのリンクは
1と
2のままにします。
Judy配列にはいくつかのタイプがあります。
- Judy1-ビットマップ(ビットマップ)、インデックスは整数(整数->ビット)。
- JudyL-インデックスとして整数(整数->整数/ポインタ)を持つ配列。
- JudySL-インデックスとして文字列を使用したポインタの配列(文字列->整数/ポインタ)。
- JudyHS-インデックスとしてバイトのセットを持つポインターの配列(バイトの配列->整数/ポインター)。
Judy配列は初期化を必要とせず、空の配列は単純なNULLポインターです。 この結果、Judy配列は互いに便利にネストされます。 JudySLとJudyHSが実際にネストされたJudyL配列であるほど便利です。
ベンチマーク
PHPの組み込み
配列は普遍的であり、その結果、場合によっては非常に非効率的です。 Judyと比較して、これらは非常に簡単に実装されます。これらは、ハッシュ衝突の場合に各要素内に二重にリンクされたリストを持つハッシュ配列です。 PHP配列には、PHP変数、つまり
zval構造体へのポインター。 ほとんどの場合、これはまさにそれらに必要なものですが、例外もあります。
Judyを使用することにした理由を示すために、JudyとPHPの配列の比較テストを実施します。 PHPからJudyへのインターフェイスとして、
php-judyモジュールを使用します。この
モジュールでは、ArrayAccessインターフェイスの実装でJudyクラスが実装されます。 テストでは、整数->整数(配列()、Judy :: INT_TO_INT、Judy :: INT_TO_MIXED)または整数->ブール(Judy :: BITSET)の形式の配列を作成し、それらに順次キーを持つ要素を入力します。
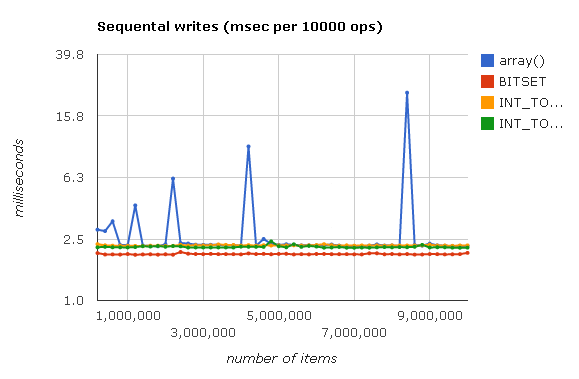
最初に、同様のコードを使用して配列への書き込み速度を測定します。
<?php $arr = array(); for ($i = 0; $i < 10000000; $i++) { $arr[] = 1; } ?>
こちらのインタラクティブチャートを
ご覧ください 。
配列()の書き込みのピークは、配列のサイズを2倍にし、すべてのハッシュ要素がいっぱいになったときに再構築することによって発生します。 Judyグラフの小さな標高は、測定誤差によって説明できます。
グラフは、書き込み速度の異なるタイプのJudyが組み込み配列にほぼ等しいことを示しています。 唯一の例外はBITSET(Judy1)です。これはわずかに高速です。
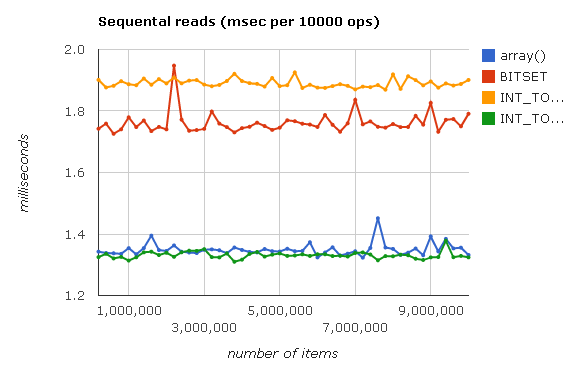
次に、配列からの順次読み取りの速度を測定します。
<?php $arr = array(); for ($i = 0; $i < 10000000; $i++) { $val = $arr[$i]; } ?>
こちらのインタラクティブチャートを
ご覧ください 。
グラフから、Judy :: BITSETおよびJudy :: INT_TO_INTを読み取ると、組み込みのPHP配列がわずかに失われることがわかります。 これは、これらの配列がPHP変数(つまりzval)ではなく、ビットと整数をそれぞれ格納するためです。 パフォーマンスの向上を奪うのは、変数を作成して入力するオーバーヘッドです。
一方、配列()とJudy :: INT_TO_MIXEDはPHP変数のみを内部に格納し、それらを作成するのに時間を費やす必要がないため、速度はほぼ同じです。
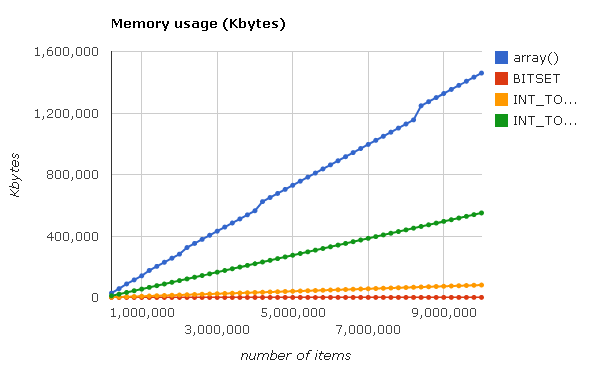
最後に、配列を埋めるときのメモリ消費量を測定し、次のグラフを取得します。
こちらのインタラクティブチャートを
ご覧ください 。
グラフからわかるように、PHP配列とJudy1 / JudyLのメモリ消費量の差は非常に大きく、この場合の主な基準はこれです。 配列から読み取るときに速度の一部を犠牲にすることができます。その代わりに、以前はサーバーのRAMにまったく収まらなかった、はるかに大きなサイズの配列を操作する機会があります。
したがって、PHPでJudy配列を使用することは、特に整数とビットの大きなデータ配列の処理に関連する問題を解決する上で正当化されます。 読み取り速度と書き込み速度の点では、Judy配列は組み込み配列とそれほど違いはありませんが、実装の違いにより、メモリをより効率的に使用します。
質問を予想して、明らかな利点にもかかわらず、Judy配列はPHPの通常の配列を置き換える可能性が低いことに注意してください。後者は整数と小文字の両方のインデックスを含むことができるからです。 2種類の配列を使用します。