むかしむかし、草が緑になり木が高くなると、ゼノセファルという名前のトロルが生きました。 彼は原則として多くの場所に住んでいましたが、幸運なことに、ある
フォーラムで彼に会うことができました。 会話が行われたトピックも覚えていませんが、その本質は、XenocephalがLisp(マクロを含む)がすべての頭であり、テンプレートを備えたC ++が左手の悲惨な見た目であると周囲の人を説得しようとしたことです。 また、ハードプレスされた
階乗よりも複雑なものをプログラムすることは不可能であると主張されました。
私は原則として、Lispマクロがひどくクールであることに異議はありませんでした、そして、その時、私は答えることがありませんでしたが、C ++テンプレートと階乗についてのフレーズは私の壊れやすい脳に深く浸透し、内側から私を苦しめ続けました。 そして、あるひどい日、私は思った:「一体何? プログラムしましょう!」
ドラゴンブックはもう一つのインスピレーションの源でした。 タスクはすぐに見つかりました。 非決定性ステートマシン(
NFA )を決定性ステートマシン(
DFA )に変換するアルゴリズムは、C ++テンプレートを使用して実装しようとするのに十分自明ではないことがわかりました。 アレクサンドレスクの不朽の
仕事により、彼はクリティカルマスを獲得することができました...
もちろん、私はプリミティブから始めました。 私は何らかの形でグラフを表す必要がありました:
template <class T, int Src, int Dst, char Chr = 0> struct Edge { enum { Source = Src, Dest = Dst, Char = Chr }; typedef T Next; static void Dump(void) {printf("%3d -%c-> %3d\n",Src,Chr,Dst);T::Dump();} };
グラフの弧は、初期(Src)頂点と最終(Dst)頂点のインデックスで指定され、シンボル(Chr)で命名できます。 (変換アルゴリズムで使用される)名前のないアークは、デフォルトでヌル文字でマークされます。 このテンプレートで定義されたNextタイプは、タイプのリストに変換しました。 このリストへのアークの追加は、次の再帰的な方法で実装されました。
struct NullType {static void Dump(void) {printf("\n");}}; template <int S, int D, int C, class T, class R> struct AddEdge; template <int S, int D, int C, class R> struct AddEdge<S,D,C,NullType,R> { typedef typename Edge<R,S,D,C> Result; }; template <int S, int D, int C, class T, class R> struct AddEdge<S,D,C,Edge<T,S,D,C>,R> { typedef typename AddEdge<S,D,C,T,R>::Result Result; }; template <int S, int D, int C, int s, int d, int c, class T, class R> struct AddEdge<S,D,C,Edge<T,s,d,c>,R> { typedef typename AddEdge<S,D,C,T,Edge<R,s,d,c> >::Result Result; };
同様に、リストのマージが整理されました(グラフを表すものだけでなく、任意のカモタイピングのおかげです)。
追記 template <class A, class B> struct Append; template <class T> struct Append<NullType,T> { typedef T Result; }; template <int S, int D, int C, class T, class B> struct Append<Edge<T,S,D,C>,B> { typedef typename Append<T,Edge<B,S,D,C> >::Result Result; };
参加する template <class A, class B> struct Join; template <class B> struct Join<NullType,B> { typedef B Result; }; template <int N, class T, class B> struct Join<Set<N,T>,B> { typedef typename Join<T,typename AddSet<N,B,NullType>::Result>::Result Result; }; template <int S, int D, int C, class T, class B> struct Join<Edge<T,S,D,C>,B> { typedef typename Join<T,typename AddEdge<S,D,C,B,NullType>::Result>::Result Result; }; template <int N, class S, class T, class B> struct Join<StateList<N,S,T>,B> { typedef typename Join<T,typename AddState<N,S,B,NullType>::Result>::Result Result; }; template <int Src, int Dst, int a, class S, class T, class B> struct Join<StateListEx<Src,Dst,a,S,T>,B> { typedef typename Join<T,typename AddState<Dst,S,B,NullType>::Result>::Result Result; };
...そして、リストの各要素に任意のファンクターを適用します:
地図 template <class T, int V, class R, template <int,int> class F> struct Map; template <int V, class R, template <int,int> class F> struct Map<NullType,V,R,F> { typedef R Result; }; template <int N, class T, int V, class R, template <int,int> class F> struct Map<Set<N,T>,V,R,F> { typedef typename Map<T,V,Set<F<N,V>::Result,R>,F>::Result Result; }; template <class T, int S, int D, int C, int V, class R, template <int,int> class F> struct Map<Edge<T,S,D,C>,V,R,F> { typedef typename Map<T,V,Edge<R,F<S,V>::Result,F<D,V>::Result,C>,F>::Result Result; };
ここで、正規表現に基づいてNCAの構築を実装する必要がありました。 この構造の手法自体は、上記の
本で詳しく説明されており、詳細は、正規表現の要素が、名前のないアークで接続されたいくつかの基本構造に置き換えられているという事実に要約されています。
名前付きアークは基本的な方法で作成されます:
C template <char Chr> struct C { typedef typename Edge<NullType,0,1,Chr> Result; enum {Count = 2}; };
開始頂点と終了頂点は、それぞれインデックス0と1を受け取ります。
次のように2つのグラフを代替構造/ A | B /で接続できます。
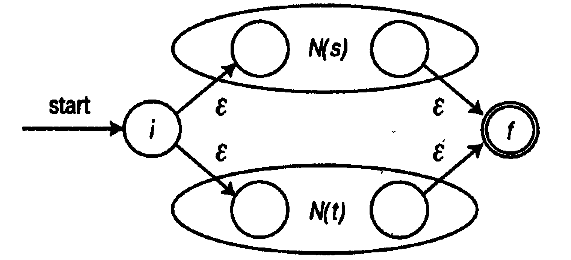
D template <int X, int N> struct Add { enum { Result = X+N }; }; template <class A, class B> struct DImpl { private: typedef typename Append< typename Map<typename A::Result, 2, NullType, Add>::Result, typename Map<typename B::Result, A::Count+2, NullType, Add>::Result >::Result N0; typedef typename Edge<N0,0,2> N1; typedef typename Edge<N1,0,A::Count+2> N2; typedef typename Edge<N2,3,1> N3; public: typedef typename Edge<N3,A::Count+3,1> Result; enum {Count = A::Count+B::Count+2}; }; template <class T1, class T2, class T3 = NullType, class T4 = NullType, class T5 = NullType> struct D: public DImpl<T1, D<T2,T3,T4,T5> > {}; template <class T1, class T2> struct D<T1,T2,NullType,NullType,NullType>: public DImpl<T1,T2> {};
ここでは、2つの入力グラフ(AとB)を「マージ」し(同時に頂点の番号を付け直します)、その後、上記の図に従って名前のないアークでそれらを接続します。 開始頂点と終了頂点のインデックスはそれぞれ0と1です。
次の/ AB /の実装は、やや理解しにくいことが判明しました。
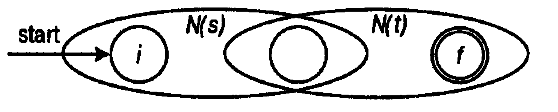
E template <int X, int N> struct ConvA { enum { Result = (X==1) ? (X+N-1) : X }; }; template <int X, int N> struct ConvB { enum { Result = (X==1) ? 1 : (X+N) }; }; template <class A, class B> struct EImpl { private: typedef typename Map<typename A::Result, A::Count, NullType, ConvA>::Result A1; typedef typename Map<typename B::Result, A::Count, NullType, ConvB>::Result B1; public: typedef typename Append<A1,B1>::Result Result; enum {Count = A::Count+B::Count}; }; template <class T1, class T2, class T3 = NullType, class T4 = NullType, class T5 = NullType> struct E: public EImpl<T1, E<T2,T3,T4,T5> > {}; template <class T1, class T2> struct E<T1,T2,NullType,NullType,NullType>: public EImpl<T1,T2> {};
ここでは、追加のアークは構築されず、グラフは共通の頂点で接続されます(Bの初期とAの最終)。
量指定子/ T * /の実装が最も難しいことが判明しました。
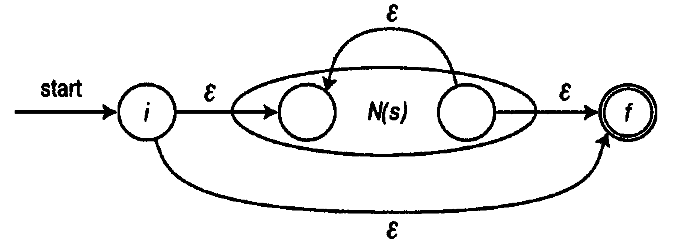
Q template <class T, int Min = 0, int Max = 0> struct Q { Q() {STATIC_ASSERT(Min<=Max, Q_Spec);} private: typedef typename Map<typename T::Result, T::Count, NullType, ConvA>::Result A1; typedef typename Map<typename Q<T,Min,Max-1>::Result,T::Count,NullType,ConvB>::Result B1; public: typedef typename Edge<typename Append<A1,B1>::Result,0,T::Count> Result; enum {Count = T::Count+Q<T,Min,Max-1>::Count}; }; template <class T, int N> struct Q<T,N,N> { private: typedef typename Map<typename T::Result, T::Count, NullType, ConvA>::Result A1; typedef typename Map<typename Q<T,N-1,N-1>::Result, T::Count, NullType, ConvB>::Result B1; public: typedef typename Append<A1,B1>::Result Result; enum {Count = T::Count+Q<T,N-1,N-1>::Count}; };
量指定子/ T * /および/ T + /は非常に一般的であるため、最適化された実装はオーバーロードされました。
Q template <class T> struct Q<T,1,1>: public T {}; template <class T> struct Q<T,0,0> { private: typedef typename Edge<typename Map<typename T::Result,2,NullType,Add>::Result,0,2> N0; typedef typename Edge<N0,3,1> N1; typedef typename Edge<N1,3,2> N2; public: typedef typename Edge<N2,0,1> Result; enum {Count = T::Count+2}; }; template <class T> struct Q<T,1,0> { public: typedef typename Edge<typename T::Result,1,0> Result; enum {Count = T::Count}; }; template <class T> struct Q<T,0,1> { public: typedef typename Edge<typename T::Result,0,1> Result; enum {Count = T::Count}; };
これで、本で説明されている正規表現/(a | b)* abb /を表すNFAを組み立てることができました。
typedef E< Q< D< C<'a'>, C<'b'> > >, C<'a'>, C<'b'>, C<'b'> >::Result G;
DKAに変換するために残ります:
DFA enum CONSTS { MAX_FIN_STATE = 9 }; template <class Graph> class DFAImpl; template <class T, int Src, int Dst, char Chr> class DFAImpl<Edge<T,Src,Dst,Chr> >: public DFAImpl<typename T> { public: typedef typename DFAImpl<typename T>::ResultType ResultType; ResultType Parse(char C) { if ((State==Src)&&(C==Chr)) { State = Dst; if (State<MAX_FIN_STATE) { State = 0; return rtSucceed; } return rtNotCompleted; } return DFAImpl<typename T>::Parse(C); } void Dump(void) {T::Dump();} }; template <> class DFAImpl<NullType> { public: DFAImpl(): State(0) {} enum ResultType { rtNotCompleted = 0, rtSucceed = 1, rtFailed = 2 }; ResultType Parse(char C) { State = 0; return rtFailed; } protected: int State; };
このコードのデバッグに関連するすべての試練(コンパイルエラーメッセージが含まれるキロメートル単位のリストのみが必要)の詳細については説明しません。アルゴリズムのフロントエンド実装がコンパイラーを完全にハングさせたため、最適化されたImportantOptテンプレートを実装する必要がありました。
これで、次のコードを実行できます。
typedef E< Q< D< C<'a'>, C<'b'> > >, C<'a'>, C<'b'>, C<'b'> >::Result G; typedef Convert<G,NullType>::Result R; R::Dump();
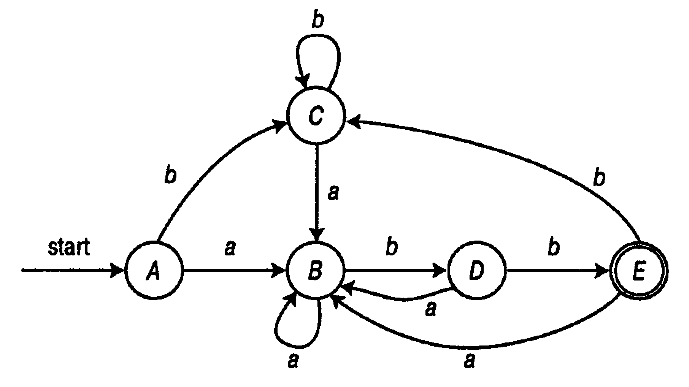
...そして、生成される結果が以下であることを確認します。
1 -a-> 10 1 -b-> 11 13 -a-> 10 13 -b-> 1 10 -a-> 10 10 -b-> 13 11 -a-> 10 11 -b-> 11 0 -a-> 10 0 -b-> 11
目的の列DKAに対応:
通常どおり、ソースは
GitHubにアップロードされ
ます 。