先日、RAMをプロセッサキャッシュメモリにマッピングする原理に関する知識を体系化することにしました。 その結果、この記事が誕生しました。
プロセッサキャッシュメモリは、RAMにアクセスする際のプロセッサのダウンタイムを削減するために使用されます。
キャッシングの基本的な考え方は、データと命令の局所性の特性に基づいています。特定のアドレスへのアクセスが発生した場合、近い将来、同じアドレスまたは隣接アドレスにメモリがアクセスされる可能性があります。
論理的には、キャッシュはキャッシュラインのコレクションです。 各キャッシュラインには、特定のサイズのデータブロックと追加情報が格納されます。 キャッシュラインのサイズは、通常、キャッシュラインに保存されるデータブロックのサイズとして理解されます。 x86アーキテクチャの場合、ラインキャッシュサイズは64バイトです。
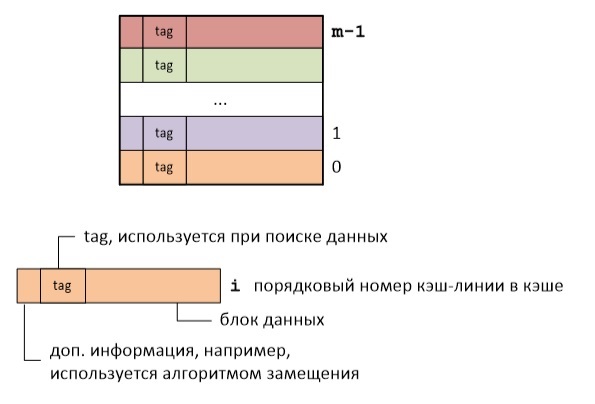
したがって、キャッシングの本質は、RAMをキャッシュラインに分割し、キャッシュラインキャッシュにマップすることです。 この表示にはいくつかのオプションがあります。
直接マッピング
RAMをキャッシュに直接マッピングする主な考え方は次のとおりです。RAMはセグメントに分割され、各セグメントはキャッシュのサイズに等しく、各セグメントはブロックに分割され、各ブロックはキャッシュラインのサイズに等しくなります。

異なるセグメントのRAMブロックですが、これらのセグメントに同じ番号が含まれている場合、常に同じキャッシュキャッシュラインにマップされます。
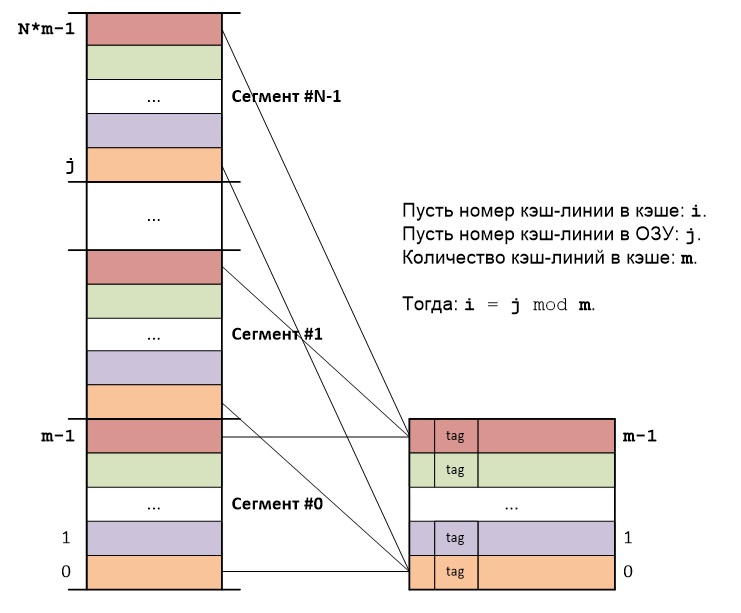
各バイトのアドレスは、セグメントのシーケンス番号、セグメント内のキャッシュラインのシーケンス番号、およびキャッシュライン内のバイトのシーケンス番号の合計です。 その結果、バイトアドレスは古い部分(セグメントのシーケンス番号)のみが異なり、セグメント内のキャッシュラインのシーケンス番号とキャッシュライン内のバイトのシーケンス番号が繰り返されます。
したがって、キャッシュラインアドレス全体を保存する必要はありません。アドレスの最も重要な部分のみを保存すれば十分です。 各キャッシュラインのタグは、このキャッシュラインの最初のバイトのアドレスの最も重要な部分を保存するだけです。
bはキャッシュラインのサイズです。
mは、キャッシュ内のキャッシュラインの数です。
各キャッシュライン内のbバイトをアドレスするには、log2bビットが必要です。
各セグメント内のmキャッシュラインをアドレスするには、log2mビットが必要です。
m =キャッシュ容量/ラインキャッシュサイズ。
N個のRAMセグメントをアドレス指定するには:log2Nビット。
N = RAM容量/セグメントサイズ。
バイトをアドレスするには、 log2N + log2m + log2bビット
が必要です。
キャッシュ内の検索ステップ:
1.キャッシュのキャッシュライン番号を決定するアドレスの中央部分(log2m)が取得されます。
2.この番号のキャッシュラインタグは、アドレスの先頭部分(log2N)と比較されます。
タグのいずれかで一致した場合、キャッシュヒットが発生しました。
タグのいずれにも一致しなかった場合、キャッシュミスが発生しました。
完全連想マッピング
RAMをキャッシュに完全に関連付けてマッピングする主な考え方は次のとおりです。RAMは、キャッシュラインのサイズに等しいサイズのブロックに分割され、各RAMブロックは任意のキャッシュキャッシュラインに格納できます。
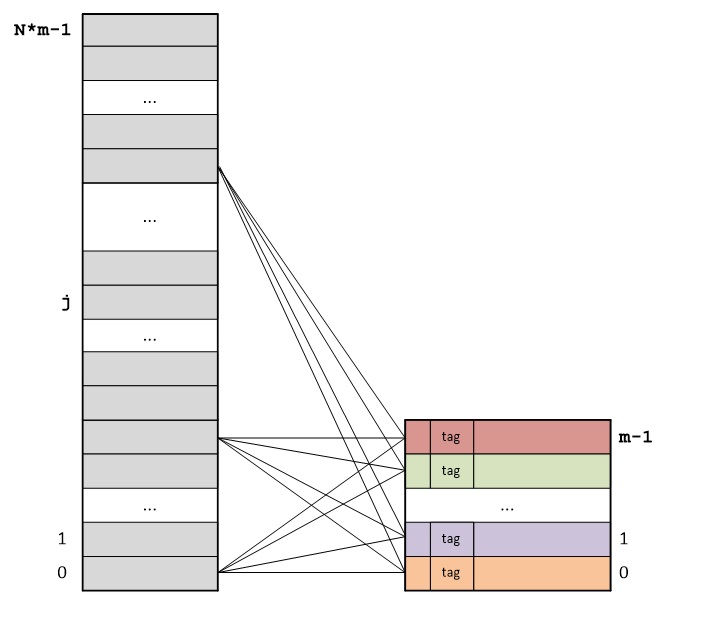
各バイトのアドレスは、キャッシュラインのシーケンス番号とキャッシュライン内のバイトのシーケンス番号の合計です。 バイトアドレスは、キャッシュライン番号である古い部分でのみ異なることになります。 キャッシュライン内のバイト番号が繰り返されます。
各キャッシュラインのタグには、特定のキャッシュラインの最初のバイトのアドレスの最も重要な部分が格納されます。
bはキャッシュラインのサイズです。
mは、RAMに収まるキャッシュラインの数です。
各キャッシュライン内のbバイトをアドレスするには、log2bビットが必要です。
mキャッシュラインをアドレス指定するには:log2mビット。
m = RAMサイズ/キャッシュラインサイズ。
バイトをアドレスするには、 log2m + log2bビット
が必要です。
キャッシュ内の検索ステップ:
1.すべてのキャッシュラインのタグは、同時にアドレスの最上部と比較されます。
タグのいずれかで一致した場合、キャッシュヒットが発生しました。
タグのいずれにも一致しなかった場合、キャッシュミスが発生しました。
アソシエイティブマッピングの設定
RAMをキャッシュにセットアソシアティブマッピングする主な考え方は次のとおりです。RAMは直接マッピングと同様に共有され、キャッシュ自体は直接マッピングを使用するk個のキャッシュ(kチャネル)で構成されます。
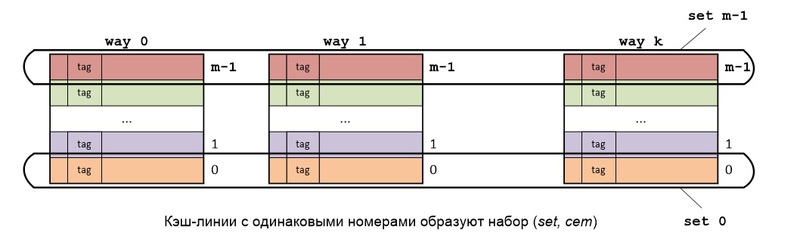
すべてのチャネルで同じ番号のキャッシュラインがセット(セット、セット)を形成します。 各セットは、完全連想マッピングを使用するキャッシュです。
異なるセグメントのRAMブロックですが、これらのセグメントに同じ番号がある場合、常に同じキャッシュセットにマップされます。 このセットに空きキャッシュラインがある場合、RAMから読み取られたブロックは空きキャッシュラインに保存されます。すべてのセットキャッシュラインがビジーの場合、使用される置換アルゴリズムに従ってキャッシュラインが選択されます。
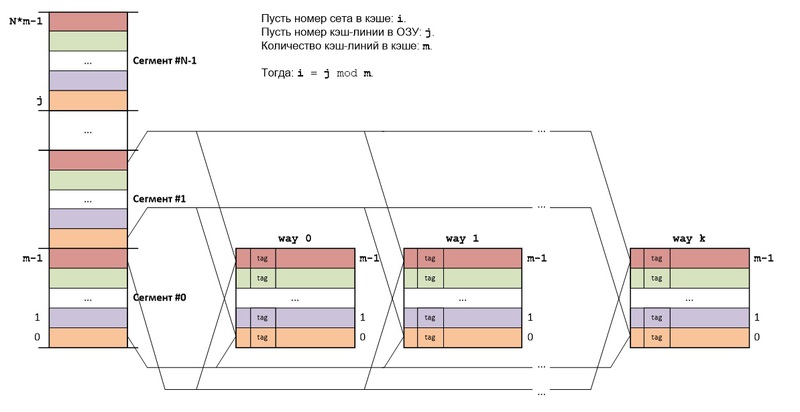
バイトアドレスの構造は、直接マッピングの場合とまったく同じです。log2N+ log2m + log2bビットですが、 セットはk個の異なるキャッシュラインであり、キャッシュ内の検索は少し異なります。
キャッシュ内の検索ステップ:
1.キャッシュ内のネットワーク番号を決定するアドレスの中央部分(log2m)が取得されます。
2.このセットのすべてのキャッシュラインのタグは、同時にアドレスの最上部(log2N)と比較されます。
タグのいずれかで一致した場合、キャッシュヒットが発生しました。
タグのいずれにも一致しなかった場合、キャッシュミスが発生しました。
したがって、キャッシュチャネルの数によって、同時に比較されるタグの数が決まります。