Google Glassプロジェクトに触発されて、このようなメガネ専用の非常にシンプルでありながら強力な拡張現実ツールを作成することはどれほど良いことだと思いました。 また、QRコードなどの広く使用されている技術に基づいて作成してください。 そこで、QRコードに記録され、Java言語の機能の一部を実装する本格的なプログラムに解釈される一連のバイトであるQuRava言語のアイデアが生まれました。
次のすべてがアルファ版であり、数日のうちに行われることをすぐに警告したいと思います。 したがって、小さな機会については誓わず、ラムダ計算の欠如について質問しないでください。

1.目的
ほとんどの拡張現実ツールは現実から完全に離婚しているように思えます。 それらは美しく、興味深いが、実用には役に立たない。 そして、私は日常的に使用するために非常にシンプルで便利になる技術を作りたかった。 思いついた最高のことは、解釈された言語をQRコードに埋め込むことです。 それらはすでに広く普及しており、人々を拒絶することはありません。 カフェのテーブルでも店の窓でも、印刷してどこにでも貼り付けることができます。 それらはほぼ瞬時に読み取られるため、Google Glassを使用すると、プログラムをリアルタイムで表示できます。
このアプローチの利点は明らかです。
- 必要なのは通訳プログラムとQRコード自体であり、追加の機器は必要ありません
- インターフェイスの標準化。 毎回もう一度学ぶ必要はありません
- 巨大な潜在的機会:たとえば、テーブルを見てカフェで注文したり、ポスターを見てロックコンサートのチケットを注文したりできます。
- プログラムの作成と配布の基本的なシンプルさと低コスト
しかし、欠点もあります:
- 小さなプログラムサイズ。 ネットワークを介して追加のロジックをポンピングすることにより解決
- QRリンク経由でインターネットからスクリプト言語のコードをダウンロードする方が簡単かもしれませんが、遅いですが
- スティーブンソンの小説「雪崩」を思い出します。この作品では、人々は白黒の画像を見て、脳を溶かしました
2.言語構造
QRコードでは、情報はそれぞれ8ビットのセクションのシーケンスを使用して記録されます。 そのため、バイト計算、つまり00からFFまでの16進文字に基づいて言語を作成することにしました。 最初はJavaバイトコードをバーコードに書き込むというアイデアを思いつきましたが、このアプローチの冗長性のためにそれを放棄しました。 QRの解釈言語は非常に短くする必要があります。そのため、バーコードには最大2キロバイトのメモリしか含めることができません。 はい、この言語には多くの機能は必要ありません。
これまでのところ、言語では、変数、プロシージャ、Androidコンポーネントの3種類の構造のみが使用されています。 これらの3つのタイプの各オブジェクトには、独自のサブタイプ(たとえば、変数の場合は00ブール、01の場合はint、02の浮動小数点数、03の文字列)、1バイトの名前と本文があります。 パーサーの利便性のために、長さのバイトが各構造の前に置かれます。
たとえば、構文{
06,01,AA,00,00,00,03 }には次が含まれます。
- 最初のバイトは6に等しい長さのバイトで、パーサーはその後6バイトを読み取ります
- 2番目のバイトはデータ型バイトです。 01で、整数を意味します
- 3番目のバイトは、変数の名前を意味します。 ここで、変数はAAと呼ばれ、その後、インタープリターはこのニックネームでそれを認識します
- その後、本体の4バイトが続きます。 変数に最初に値3が割り当てられることを意味します
手順では、プリミティブ操作のリストが指定されています。 たとえば、{
4,14,,, }は、AA = AA + BBを意味します。
Google Glassはまだリリースされていないため、Android用のインタープリタープログラムを作成しました。 したがって、QuRavはAndroidコンポーネントをサポートするようになりました。 これまでのところ、Button、TextView、Edit Textのみです。 画面上の位置、テキストを設定できます。ボタンの場合は、押されたときに呼び出されるプロシージャの指示を追加します。 たとえば、{
05,09,05,02,03,08 }は、05という名前のボタン(コード09)を作成し、画面02の位置(1から9までの古い電話ハードキーパッドのシステムによれば上部中央)に行のテキストを含むことを意味します名前03で、押されたときに名前08でプロシージャを呼び出す。
正直なところ、構文はひどく見えます。 非常に複雑で、機能はほとんどありません。 しかし、これは単なるプロトタイプです。 将来、私はすべての原始的なライブラリ操作を押し出し、それらの設計をより短く、より便利にするつもりです。 馬鹿げに書かれたコンパイラのために、別のプロシージャからプロシージャを呼び出す方法はまだありません。 今彼についてのところで。
3.通訳
メインインタープリターパーサーはプログラムを読み取り、それを断片に分割してサブパーサーに送信します。サブパーサーは独自のサブパーサーを持つことができます。 多数のパーサーの作業の結果に基づいて、断片的なプログラムが小さな工場でも組み立てられます。 準備済みのプロシージャ、変数、およびコンポーネントはMainクラスに分類されます。
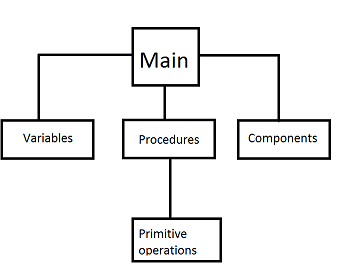
Mainクラスでは、すべてが個別のHashMapに含まれています。 このようなHashMapの例はnamesOfVariablesです:
public Object getVariable(Byte name) { return namesOfVariables.get(name); }
そして、変数とコンポーネントへのアクセスがプロシージャとプリミティブ操作からであったように、プロシージャクラスはProgramUnitクラス(図ではMainとして示されています)の継承であり、プリミティブ操作はプロシージャクラスを拡張します。
プロシージャクラスでは、変数を取る方法が再定義されています。 さらに数行追加すると、ローカル変数のメカニズムを実装できます。
@Override public Object getVariable(Byte name) { return superiorUnit.getVariable(name); }
正直に言うと、通訳者は最も退屈な部分なので、それで十分です。
4.使用例
そして、この記事を実際に読み始めた理由をお見せします。 有効なQuRavaプログラムの例。
この例では、16進数に相当するものではなく、バイト番号が使用されています!
02,03,00という名前の空の文字列の宣言
02,01,01という名前のint変数の宣言
02,01,02という名前のint変数の宣言
06,03,03,80,108,117,115 「プラス」というテキストを含む行の発表
04,11,04,01,00という名前の可変テキストフィールドを作成する
05,09,05,02,03,08押されたときにプロシージャ08を呼び出す05という名前のボタンを作成する
04,11,06,03,00という名前の可変テキストフィールドを作成する
04,13,07,08,00という名前の不変テキストフィールドの作成
31,04,08という名前の手順の発表
........03,42,00,04フィールド04に書かれたテキストを読み取り、行00に入れます
........03,41,01,00文字列00をintに変換し、結果を変数01に書き込みます
........03,42,00,06フィールド06に書かれたテキストを読み取り、行00に入れます
........03,41,02,00行00をintに変換し、結果を変数02に書き込みます
........04,14,01,01,02変数01と02を追加し、結果を01に書き込みます
........03,40,00,01値01を文字列に変換し、結果を00に書き込みます
........03,43,07,00テキストフィールド07に行00を表示
まあ、実際に仕事のデモンストレーション:(品質のために申し訳ありません)
5.さらなる開発
これで、私がやりたいことのプロトタイプのアルファ版のみを紹介しました。 将来的には、多くの興味深いものをQuRavaに追加したいと思います。
- シンプルで強力な構文を開発する
- 正規表現、配列、ループなどを追加します
- Java自体のメインライブラリクラス(たとえば、MathやArraysなど)を複製するライブラリにすべてのプリミティブ操作を分散します。
- 他のプロシージャおよびローカル変数からプロシージャを呼び出す機能を追加します
- ネットワーク、ネットワークからプログラムに追加コンテンツをダウンロードする機能、またはロジックを使用して作業を追加します
- たくさんの標準ライブラリを書く
- デスクトップ用のコンパイラと、小さくても便利なIDEを作成する
- 包括的な言語ヘルプを書く
- プロジェクトをgithubに配置します
残念ながら、まだ表示するものがほとんどないため、リンクを投稿しません。 興味深い場合は、これに取り組み、別の記事を書きます。
それまでの間、調査を実施したいと思います。