UPD:記事のタイトルを変更しました、なぜなら 私は夢遊病者の間に最後の見出しを書きました(もちろん冗談です)。
先週のHabréには、Microsoft Researchの分散コンピューティングフレームワークに関する2つの投稿-Dryadが登場しました。 特に、主要なDryadコンポーネント( DryadランタイムとDryadLINQクエリ言語)の概念とアーキテクチャについて詳しく説明しました。
Dryadシリーズの記事の論理的な終わりは、DryadフレームワークをMPP開発者に馴染みのある他のツールと比較することです: リレーショナルDBMS (並列のものを含む)、 GPUコンピューティング、 Hadoopプラットフォーム 。

叙情的な余談(またはマイクロソフト製品について何かを書くとき)シリーズの最後の記事で、以下のすべてのポイントに言及しました。 しかし、読者は私のすべての記事を読むことを義務付けられていないので(さらに、私が書いたものを覚えておくために)、自分自身を繰り返すことは適切だと思います。
私は 、研究プロジェクトでのドライアドの使用を提案したり 、 落胆させたりしません (現在、アカデミックライセンスのみが利用可能です)。
ドライアドは、誰もが知っている邪悪な企業の「内部」製品であり、その開発はこの企業の内部ビジネスです (これは非常に真実です)。
Dryadがプロプライエタリなソフトウェアであるという事実は、このプラットフォームの原理とアーキテクチャを専門的な開発にあまり興味を持たせず、有用ではありません(ここでも-私自身)。 あなたが何か違うものを持っている場合- これは私のためではなく、あなた次第です。
第1部では、例としてDryadを使用して、低レベルのコンピューティング並列化ツールであるMPIおよびGPUコンピューティングよりも高いレベルの抽象化を開発者に提供する分散コンピューティングフレームワークの利点の概要を説明します。
コンテキスト(つまり、特定のタスク)から切り離したこのような比較は正しくありませんが、分散アプリケーション実行フレームワークの適切な使用のケースを示すことは、私たちの目的にとっては許容できます。
2番目の部分では、RDBMSと並列DBMSとの比較が行われます。 もちろん、パブリケーションボリュームでは、MySQLとDryadを個別に比較したり、SQL Server 2012 Parallel Data Warehouseと個別に比較したりすることはできません(その理由は?)。 そのため、DBMSの「病院の平均気温」を分析に使用しました。リレーショナルデータベースに基づくソリューションの一般的な問題を議論し、DryadをDBMSの世界で最高のアイデアの継続と見なします。
最後の部分では、Hadoopソフトウェアプラットフォームとの比較が行われます(後者を知らないか賞賛するかもしれません)。
Hadoop 2には大きな利点があります(もちろん、それ以上)-
新しいフレームワーク (後で詳しく説明します)は、独自の分散アルゴリズムを実装するためのAPIと
豊かなエコシステムを提供します。 逆説的に、これらはHadoopの主な欠点です:新しいベータフレームワーク(開発開始-2008)、およびエンタープライズセグメントでHadoopを使用してHadoopエコシステムから多くのコンポーネントをインストール(インストール、トレーニング、サポート)することは簡単な作業ではありません。
したがって、Dryadの比較は
、単純なHadoopリリースブランチと、Hadoopエコシステムによって提供される機会と、Hadoop v2.0でこの問題(存在する場合)がどのように解決されるかについての無限の調査です。
1. Dryad対GPU。 ドライアドvs MPI
Dryadのアカデミックライセンスを考えると、研究のための計算にDryadフレームワークを使用する可能性に興味を持つようになりました(私は大学院生です)。 しかし、歴史的には(確かに私の大学の)アカデミック環境では、「科学的コンピューティング」の主なプラットフォームはMPI(Message Passing Interface)とGPUコンピューティングです。
MPIとは異なり、Dryadプラットフォームは(さまざまなプロセスによって)データを共有しないシェアードナッシングアーキテクチャに基づいているため、 同期プリミティブを使用する必要はありません 。 これにより、Dryadクラスターのスケーラビリティが向上するだけでなく、並列データアルゴリズムを使用して問題を解決するための時間効率が向上します。
さらに、パフォーマンスの監視やフェールオーバーなどのインフラストラクチャタスクは通常MPI開発者の責任です 。一方、Dryadでは、リストされているタスクはフレームワークの責任です。
GPUコンピューティングについて言えば、Dryadとは異なり、 GPU開発はアプリケーションが実行されるハードウェアレベルにほとんど関連していることに注意する価値があります。 NVidiaとAMDは、グラフィックカード(それぞれCUDAとAPP)の開発用に独自のSDKを提供しています。 明らかに、これらは互いに互換性のないさまざまな開発プラットフォームです。
株式会社 悪 Microsoftは、C ++ AMPをリリースすることにより、GPUの開発プロセスを統一しようとしました。 しかし、この事実は、GPUで開発する場合、開発者がグラフィックアダプターのハードウェアを「振り返る」必要があるという余分な証拠です。 さらに、ハードウェアレベルの「ルート」はコードに深く浸透しているため、ベンダーの変更は言うまでもなく、グラフィックカードのモデルを変更する場合でもアプリケーションの起動が困難になる場合があります。 当然、これにより、デバッグ時と、特定のタスクにより生産的で適切なハードウェアプラットフォームに移行する際に、さらに困難が生じます。
最終的に、これらすべてにより、研究者は、研究対象分野の適用された問題を解決するのではなく 、ハードウェア、デバッグ、展開、およびサポートに関連するインフラストラクチャの問題に対処する必要があります 。
Dryadフレームワークは、GPUとは異なり、分散アプリケーションの開発者からハードウェアレベルを隠しますが、分散アプリケーションを実行するためのハードウェアプラットフォームには非常に特定の要件があります(要件はシリーズの最初の記事で説明しました)。
2.ドライアドと並列DB
DryadとDBMSの主な基本的な違いは、ストレージ層、パフォーマンス層、 Dryad のソフトウェアモデル間の強力な接続がないことと、DBMSでのそのような接続の存在です。 この違いは
導入部の図。
それでも、Dryadは、従来のDBMSと並列DBMSの両方の世界の多くのアイデアを「吸収」しました。
多くの並列DBMS (Teradata、IBM DB2 Parallel Edition)と同様、Dryadはシェアードナッシングアーキテクチャ、シャーディング(水平分割)、動的再分割、分割戦略(ハッシュ分割、範囲分割、ラウンドロビン)を使用します。
従来のDBMSの世界から、クエリオプティマイザーと実行計画の概念が採用されました。 これらの概念は非常に変換されています。DryadLINQスケジューラーの結果は、実行計画グラフです。これは、ポリシーに基づいて動的に変更され、統計の実行中に収集されます。
すべてのDBMSと同様に、Dryadはデータクエリ言語を使用します。 Dryadでは、クエリを記述するための言語の役割はDryadLINQプログラミングモデルによって果たされます。 しかし、SQLとは異なり、DryadLINQは:
+ データ構造と複合型を使用するために最初に作成されました 。
+は、アプリケーション層を層に関連付けない高レベルの抽象化です
ストレージ;
+は、反復などの一般的なプログラミングパターンをネイティブでサポートしています。
-トランザクションおよび更新操作をサポートしません。
さらに、SQLは、機械学習アルゴリズムの記述、事実のシーケンス(ログ、ゲノムデータベース)の解析、およびグラフ分析には根本的に不適切です。 Dryadが、ランダムアクセスデータアクセスを必要とするアルゴリズムに基づいて問題を解決するのには効果がないように。
次の表では、リレーショナルDBMSと分散コンピューティングフレームワークに基づいたソリューションを比較しています。
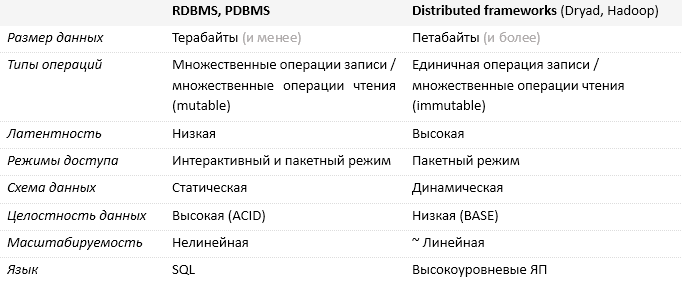
結論として、並列DBMSに基づくソリューションを広く採用する際の最大の障害は、ソリューションのコストであり、一般的には数十万ドルになります。 Dryadベースのソリューションにかかる費用。 私の意見では、合計は桁違いに低いです。
3.ドライアドとHadoop
map / reduceパラダイムは、データ並列アルゴリズムを記述する非常にエレガントな方法です。 ランタイムインフラストラクチャとmap / reduceアプリケーションを作成するためのプログラミングモデルを提供するHadoopの登場は、ビッグデータの問題を解決する上で革命的な飛躍でした。

*有向非巡回グラフ(Eng。Directed Acyclic Graph)。
**ベータ版のみが利用可能です(2013年6月現在)。
***静的型付けを使用するCLS互換PL
**** Hadoopクラスターを展開し、Hadoopタスクを実行するためのインフラストラクチャ。
***** Hadoopエコシステムのサードパーティコンポーネントをインストールする場合にのみ利用可能です。
3.1。 Hadoop
Hadoopのイデオロギー家と開発者は、不必要なものをすべて廃棄したため、開発者の最大の輪にとってシンプルで理解しやすく、MPPアプリケーション用の非常に効果的で限定的な開発プラットフォームを作りました。
Hadoopはmap / reduceに最適であり、これまでのところ、他の分散アルゴリズム(YARNを待機)向けに開発する際の批判には耐えられません。 したがって、Hadoop MapReduceコンピューティングフレームワーク(Pigなど)に基づいており、個別のコンピューティングフレームワーク(Hive、Storm、Apache Giraph)を表す膨大な数のHadoop補助ツール。 そして、これらのツールはすべて、ログ解析とPageRankカウントおよびグラフ分析の両方を解決するための単一の汎用ツールを提供するのではなく、狭い性質のタスク (実際、制限の回避)の重複ソリューションを提供します。
当然、日常的な分析タスクを解決するために必要なHadoopエコシステム全体のインストール、構成、およびサポートはかなりの時間であり、その結果、 ビジネスや研究者のタスクではなく、 インフラストラクチャの問題を解決するための財務コストになります。 この問題の部分的な解決策として、Hadoopプラットフォームのディストリビューターは「組み立てられた」ように見えました(最大のものはClouderaとHortonworksです)。 しかし、これはまだ問題の解決策ではありません -これはその存在の特別な確認です 。
map / reduce以外の分散アルゴリズムの開発に必要なコンポーネントとAPIを開発者に提供する YARNソフトウェアフレームワークは、進化的な飛躍になります(これまでのところ)。 YARNは、リソース使用率の低さやスケーラビリティのしきい値など、Hadoop v1.0の多くの問題も解決します。これは、現在、約4Kコンピューティングノードです(2011年にDryadにはすでに10Kノードがありました)。
2013年5月の時点で、YARNはまだリリースバージョンではありません。 「遅い」Apacheコミュニティを考えると、YARNのリリースバージョンのリリースと、YARN APIを使用して記述されたmap / reduce以外の分散アルゴリズムのリリースバージョンの間の時間間隔が数年になる可能性が高いことを考慮する必要があります。
3.2。 ドライアド
Dryadフレームワークにより、開発者は当初、任意の分散アルゴリズムを実装できました。 したがって、 Hadoop MapReduceソフトウェアモデル(v1.0)は、より一般的なDryadソフトウェアモデルの特殊なケースにすぎません 。
結合操作を伴うHadoopの問題、PageRankの計算効率、Hadoopプラットフォームの他の制限、およびそれらの解決方法については、この記事の範囲外であることから明らかにしません。 代わりに、Dryadフレームワークの機能について説明します。Hadoopプラットフォームには類似物がありません。
Dryadには、シリーズの以前の記事で説明した、分散アプリケーションの実行プロセスを計画するための印象的なツールのリストがあります。 そのため、DryadLINQで記述された式を実行グラフ-EPGに変換する並列コンパイラがあります。 EPGは、実行前( 静的オプティマイザー )と実行中(実行中に収集されたポリシーと統計に基づく動的最適 化 )の両方で最適化ステージを通過します。
並列コンパイラ、ランタイムグラフ、およびグラフを静的/動的に最適化する機能により、分散アプリケーションのスケジューリング/実行が改善および最適化されます。
有向非巡回グラフの概念により、Hadoopで実装されるよりもはるかに洗練された方法で、フォールトトレランス、監視、計画、およびリソース管理に関連する多くの問題を解決できます(これについてはシリーズの最初の記事で書きました)。
計算ノードの障害処理、「低速」ノードの処理、Dryadでの動的集約(図)
コンピューティングノードの障害処理により、ステージ全体を再起動しないようにすることができます。

「遅い」コンピューティングノードを処理すると、最も遅いノードを「終了」したノードを「待たない」ことができます(たとえば、Reduceフェーズを開始するため)
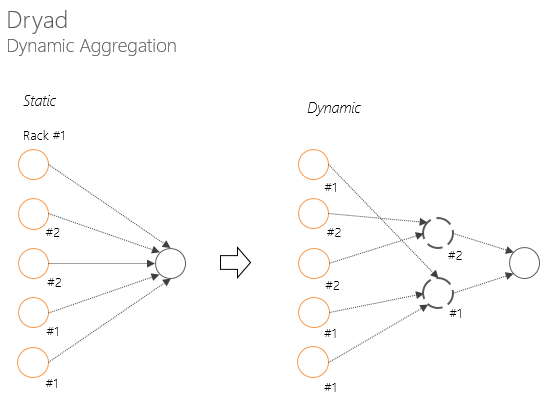
Dryadの動的な集約により、次の段階(畳み込みなど)の開始前にネットワーク帯域幅の低下が回避されます。
Hadoopに欠けているもう1つの興味深い機能は、 channelの概念の抽象化です 。 導入された抽象化のおかげで、TCP、一時ファイル、共有メモリFIFOの両方がDryadのチャネルとして機能できます。 これにより、PageRank計算などのアルゴリズムが、低遅延のチャネル(共有メモリFIFOなど)での反復間でデータを交換できます。 Hadoopでは、反復間のデータ転送は常にTCPチャネルを経由します。TCPチャネルは共有メモリに比べて待ち時間がかなり長くなります。 (この動作はYARNで修正されたという情報がありますが、動作確認はまだ見ていません。)
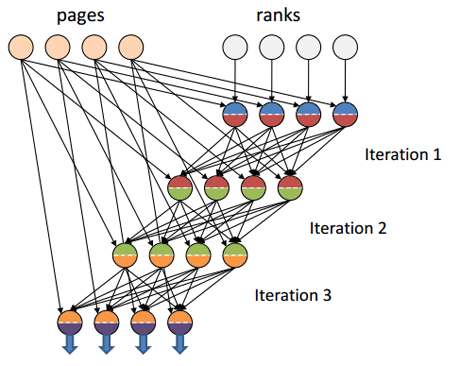
イラストのソース[7]
一部のDryadアーキテクチャソリューション(前の記事で説明した、メタデータの実行グラフへの「アタッチ」)と高レベルの静的型付きPLのフレームワークによるネイティブサポートにより、Dryadアプリケーションの開発時に非常に厳密に型付けされたデータを操作できました。 Hadoopの開発者にとっては、通常の方法は入力データを解析し、さらに(最も安全ではない)期待される型にキャストすることです。
3.3。 練習する
以下は、低レベルAPIを使用したHadoopおよびDryadの算術平均アプリケーションのリストです。
リスト1. Hadoopでの算術平均計算(Java)。 ソース[1]。
リスト2. Dryadの算術平均計算(C#)。 ソース[1]。
public static IntPair InitialReduce(IEnumerable<int> g) { return new IntPair(g.Sum(), g.Count()); } public static IntPair Combine(IEnumerable<IntPair> g) { return new IntPair(g.Select(x => x.first).Sum(), g.Select(x => x.second).Sum()); } [AssociativeDecomposable("InitialReduce", "Combine")] public static IntPair PartialSum(IEnumerable<int> g) { return InitialReduce(g); } public static double Average(IEnumerable<int> g) { IntPair final = g.Aggregate(x => PartialSum(x)); if (final.second == 0) return 0.0; return (double)final.first / (double)final.second; }
3.4。 開発者のアクセシビリティ
ドライアドはプロのコミュニティから閉鎖された独自のシステムであり、あいまいな未来を持っています(より正確には、まったくありません)。 対照的に、Hadoopは、巨大なコミュニティ、明確なライセンス方法、およびいくつかの大規模なディストリビューター(Cloudera、Hortonworksなど)を備えたオープンソースプロジェクトです。
Hadoopとの比較に関する章の終わりに、クラウドサービスの現在の開発レベルで使用するHadoopクラスターを取得することは難しくないことに注意してください。AmazonWeb サービスは 、 Amazon Elastic MapReduceサービスとMicrosoft HDInsightを介したWindows Azureクラウドプラットフォームを介してHadoopクラスターを提供します。
「Hadoop + {WA | AWS}「スタートアップや研究者向けのHadoopプラットフォームの可用性は非常に高くなっています。 Dryadの入手可能性について話す必要はありません。商用ライセンスはなく、アカデミックな使用についてはほとんど話されていません。
Hadoopは、ビッグデータを操作するための事実上の標準です。 YARNの将来のリリース後、プラットフォームがこの標準にふさわしいものになったことを疑う人はいないだろうという期待があります。 プロジェクトのように、ドライアドは「生まれ変わり」を持っているようです。そのうちの1つはナイアッド (インクリメンタルドライアド)です。 そして、Dryadで定められた原則は、Microsoft Researchプロジェクトだけでなく、オープンソースコミュニティでも継続していることは確かです。
おわりに
有向非巡回グラフの概念に基づいたDryadフレームワークは、この概念に、 分散アプリケーション実行フレームワーク、伝統的および並列DBMSの世界における最新のアイデアを課しました。 ランタイム、分散ストレージ、および個々のモジュール間のソフトウェアモデルに関連する責任の分割により 、Dryadは非常に柔軟なシステムを維持できました。 .NET開発者(.NET Framework、C#、Visual Studio) の既存のソフトウェアスタックとの緊密な統合により 、フレームワークの使用を開始するのに必要な時間が大幅に短縮されます。
シンプルでエレガントなコンセプト、革新的なアイデア、美しいアーキテクチャ、おなじみのテクノロジースタックにより、Dryadはビッグデータを扱うための効果的なツールになります。 ハードウェアにバインドされたGPUコンピューティングよりも効率的です。 従来のDBMSに基づく拡張性の低いソリューション。 高価であり、並列DBMSに基づくSQL言語ソリューションの原始性によって制限されます。 ドライアドは、マップ上の「ループ」/ Hadoopモデルの削減を上回り、YARNの出現前に、単一の障害点、場合によってはリソース使用率の低さ、または単にコミュニティの慣性から苦しみます。
同時に、Dryadの明白な利点はすべて、この製品の性質によって容易に平準化されます。これは、 内部使用のためのMicrosoft独自の製品であり、Microsoftが個々に決定する運命です。
しかし、 Dryadがそのままであることを止めるわけではありません。 新しい興味深い外観、Microsoft Researchの分散アプリケーション実行システムの革新的なビジョンです。
ソースのリスト
[1] Y. Yu、PK Gunda、M。Isard。
データ並列コンピューティングの分散集約:インターフェイスと実装 、2009年。
[2] M.アイサード、M。ブディウ、Y。ユー、A。ビレル、およびD.フェッターリー。
Dryad:シーケンシャルビルディングブロックからの分散データ並列プログラム 。 コンピュータシステムに関する欧州会議(EuroSys)の議事録、2007年。
[3]トム・ホワイト。
Hadoop:決定版ガイド、第3版。 O'Reilly Media / Yahoo Press、2012年。
[4] Arun C Murthy。
次世代のApache Hadoop MapReduce 。 Yahoo、2011年。
[5] D.デウィットとJ.グレイ。
並列データベースシステム:高性能データベース処理の未来。 ACMの通信、36(6)、1992。
[6] David Tarditi、Sidd Puri、Jose Oglesby。
アクセラレータ:データ並列性を使用して、汎用用途向けにGPUをプログラミングします。 2006年10月、マサチューセッツ州ボストンのプログラミング言語とオペレーティングシステムのアーキテクチャサポートに関する国際会議ASPLOS)。
[7]李J陽。
ドライアド/ドライアドLINQスライドは 、2009年
にYuan YuおよびMichael Isardのスライドを採用したものです 。