これまでのところ、VLAN、静的ルート、OSPFなど、独自の方法で調理しました。 環境にやさしい学生から強力なエンジニアまで、自らの上にスムーズに成長しています。
さて、これらのおもちゃを脇に置いて、BGPの時間です。
今日は
- BGPプロトコルを理解しています:タイプ、属性、動作原理、構成
- BGPを介してプロバイダーに接続します
- 複数のリンク間の予約と負荷分散を整理します
- BGPを使用せずにバックアップオプションを検討する-IP SLA
まず、動的ルーティングプロトコルの基本を更新しましょう。
プロトコルには、IGP(自律システムの内部)とEGP(外部)の2種類があります。
どちらも、DV(Distance Vector)とLS(Link State)の2つのアルゴリズムのいずれかに依存しています。
すでに内部のものを
検討しています。 これらには、ISIS / OSPF / RIP / EIGRPが含まれます。 これらは、ネットワーク
内でルーティング情報を確実に配信するために必要です。
EGPは、BGP-Border Gateway Protocolの1つのプロトコルのみを表します。 異なるネットワーク(自律システム)間でルートを確実に転送するように設計されています。
大まかに言えば、Balagan Telecomとそのアップリンクプロバイダー間の接続は、BGPを介して正確に編成されます。
つまり、アプリケーションスキームはおよそ次のとおりです。

自律システム-AS
BGPは、自律システム(AS-自律システム)の概念と密接にリンクしています。自律システムは、すでにサイクルで複数回見られています。
Wikiの定義によれば、ASは、インターネットと共通のルーティングポリシーを持つ1つ以上のオペレーターによって管理されるIPネットワークとルーターのシステムです。
少しわかりやすくするために、たとえば、都市が自律システムであると想像できます。 2つの都市が高速道路で相互接続されているように、2つのスピーカーがBGPで相互接続されています。 同時に、各都市には独自の道路システム-IGPがあります。
近距離から見ると次のようになります。

BGPでは、ASは便宜上の単なる抽象的なものではありません。 このことは非常に形式化されており、社会保障部門には特別なウィンドウがあり、平日9から6に自律システムの番号を取得できます。 これらの番号は、RIR(Regional Internet Registry)またはLIR(Local Internet Registry)によって発行されます。
一般に、
IANAはこれをグローバルに行います。 しかし、彼女が引き裂かれないように、彼女は仕事を委任しますRIRは地域組織であり、それぞれが地球の特定の部分を担当しています(ヨーロッパとロシアの場合はRIPE NCC)

必要な文書を持つほとんどすべての組織がLIRに
なることができます。 RIRがLinkMiApのような小規模オフィスからの要求に負担をかける必要がないようにするために必要です。
たとえば、Balagan-TelecomはLIRになる可能性があります。 そして、彼からASN(AC番号)-64500などを取りました。 そして、彼自身がAS 64501を持っています。
2007年までは、16ビットのAS番号しか使用できませんでした。つまり、合計65,536個の番号が使用可能でした。 0および65535は予約されています。
64512から65534までの番号は、グローバルにルーティングされないプライベートAS(プライベートIPアドレスなど)用です。
番号64496-64511-使用する例とドキュメントで使用します。
32ビットAS番号を使用できるようになりました。 この移行は、IPv4-> IPv6よりもはるかに簡単です。
繰り返しますが、IPアドレスのブロックに縛られずに自律システムについて話すことはできません。 実際には、アドレスのブロックを各ASに関連付ける必要があります。
PIおよびPAアドレス
私のプロの若さのとき、私たちのLIRとの契約を読んでいる間、私はIPアドレスを正しく書くことができなかったマネージャーを笑いました。「PIアドレス」という言葉がテキストに現れました。
神に感謝し、私はこの質問をグーグルする心を持っていた
実際、PIはプロバイダー非依存です。
通常の状況では、プロバイダーに接続すると、パブリックアドレスの範囲、いわゆるPAアドレス(プロバイダー集約可能)が提供されます。
それらを受け取ることは単なるつばですが、LIRでない場合は、プロバイダーを変更するときにPAアドレスを返す必要があります。 さらに、実際には1つのプロバイダーのみに接続できます。
そして、プロバイダーを変更することにした場合、古いアドレスは彼に残され、新しいプロバイダーは新しいアドレスを発行します。 さて、柔軟性はどこにありますか?
LIRからは、Pover-Independent Address Block(PI)を購入でき、
必然的に ASNも購入できます。 この場合、ブロック100.0.0.0/23とし、BGPでネイバーに通知します。 そして、これらのアドレスはすでに純粋に私たちのものであり、プロバイダーは私たちを怖がっていません。私たちは一方が好きではありませんでした。
PIアドレスの取得はかつてないほど容易になりました。 多くのドキュメントを準備し、そのようなブロックの必要性を正当化する必要があります
。現在、IPv4の枯渇により、大きなブロックを取得することは難しくなっています。 RIRはそれらを発行しなくなり、LIRは後者を配布します。
したがって、同じオフィスでAS番号とPIアドレスの両方を取得できます。
このファームをすべて受け取ったら、RIPEデータベースに変更を加える必要があります。 このビジネスは面倒で困難であり、理解するのに長い時間がかかります。
RIPEデータベースのオブジェクトに関する簡単な説明を次に示します。
この場合、LinkMiApがアドレスブロック100.0.0.0/23およびAS 64500を受信したと仮定します。類推に戻って、都市に名前を付け、さまざまなインデックスを提供しました。
このトピックに関する別の記事 。
簡単なFAQBGP
そのため、これらのパブリックアドレスに関する情報をASから別のAS(インターネットで読み取られた)に転送するために、BGPが使用されます。 そして、YandexまたはMicrosoftが何らかの天体テクノロジーを使用してデータセンターをインターネットに接続していると思う場合、あなたは間違っています-すべて同じBGP。
さて、初心者にとって常に興味深い主な質問:なぜBGPなのか、悪名高いOSPFや静的なものさえとらないのか?
おそらく大叔父はこれを非常に詳細かつ徹底的に説明できるかもしれませんが、表面的な理解を与えようとします。
-OSPF / IS-ISといえば、これらは(注意!)各ルーターがネットワーク
全体のトポロジを知っていることを意味するリンク状態アルゴリズムです。 インターネット上の何百万ものルーターを想像して、これらの目的のためにリンク状態を一般的に使用するという考えを捨ててください。
一般に、エリア間のルーティング時のOSPFは、実際には距離ベクトルプロトコルです。 仮に、グローバルルーティングの観点から「AS」を「エリア」に置き換えることができますが、OSPFはこのような大量のルーティング情報を消化するように設計されておらず、インターネット上のエリア0を隔離することは不可能です。
RIP、EIGRP ... Khe-khe。 さて、ここではすべてが明確です。
-IGPは親密なものであり、出会うすべてのISPに見せることは価値がありません。 ASがなくても、クライアントがプロバイダーでIGPを上げる状況は非常にまれです(L3VPNを除く)。 実際、IGPには十分な柔軟性のあるルート管理システムがありません-LSプロトコルの場合、一般的に
すべてまたは何も知ら
ないことです(ここでも、ゾーンの境界でフィルタリングできますが、柔軟性はありません)。
その結果、プライベートネットワークの隠された部分を他の人に公開するか、異なるIGPプロセス間でトリッキーなインポートポリシーを設定する必要があることがわかりました。
-現在、インターネットには450,000以上のルートがあります。 OSPF / ISISでさえもインターネットトポロジ全体を保存できる場合、SPFアルゴリズムにかかる時間を想像してください。
以下は、グローバルなものが要求される場所でIGPを使用することが危険な場合の
良い例です 。
したがって、AS間の相互作用には独自の特別なプロトコルが必要です。
まず、
距離ベクトルでなければなりません-これは一意です。 ルーターは、インターネット上の各ネットワークへのルートを計算する必要はありません。いくつかの推奨されるものの1つを選択するだけです。
次に、非常に
柔軟なルートフィルタリングシステムが必要です。 近所の人たちが何を照らし、何を小屋から持ち出してはならないかを簡単に判断する必要があります。
第三に、それは
容易にスケーラブルでなければならず、
ループに対する保護と ルートの優先順位を管理する
システムを持たなければなりません。
第四に、
高い安定性が必要です。 経路データは常に品質が保証されているとは限らない環境(少なくとも2つの組織がジャンクションを担当している)を介して送信されるため、経路情報の損失の可能性を排除する必要があります。
第5に、ASを他人と区別するために、ASを理解する必要があります。
会う:
BGP一般に、この真に壮大なプロトコルの作業の説明を2つの部分に分割します。 そして今日は基本的なポイントを検討します。
BGPはIBGPとEBGPに分かれています。
IBGPは 、単一の自律システム内でBGPルートを転送するために必要です。 はい、BGPは多くの場合AS
内で起動さ
れますが 、これについては後で少し説明します。
EBGPは、自律システム間の通常のBGPです。 その上で停止します。
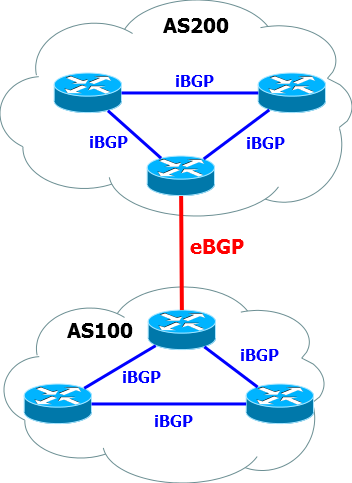
BGPセッションの確立とルート交換手順
プロバイダーゲートウェイに直接接続している典型的な状況を考えてみましょう。

BGPセッションが確立されるデバイスは、BGPピアまたはBGPネイバーと呼ばれます。
BGPはネイバーを自動的に検出しません—各ネイバーは手動で構成されます。
近隣関係を確立するプロセスは次のとおりです。
I) BGP近隣
の初期状態は
IDLEです。 何も起きていません。

BGPネイバーへのルートがない場合、BGPはIDLE状態になります。
II) BGPはTCPを使用して信頼性を確保します。
これは、理論的にはBGPピアを直接接続するのではなく、たとえば次の
ように接続できることを意味します。
ただし、プロバイダーに接続する場合、原則として、直接接続が引き続き使用されるため、直接接続されているため、近隣へのルートは常にそこにあります。
BGPルーター(BGPスピーカー/スピーカーまたはBGPスピーカーとも呼ばれる)は、179番目のTCPポートをリッスンして送信します。
リッスンしているとき、これは
CONNECT状態です。 BGPはごく短時間この状態にあります。
送信され、ネイバーからの応答を待機している場合、これは
ACTIVE状態です。

R1はTCP SYNをネイバーのポート179に送信し、TCPセッションを開始します。
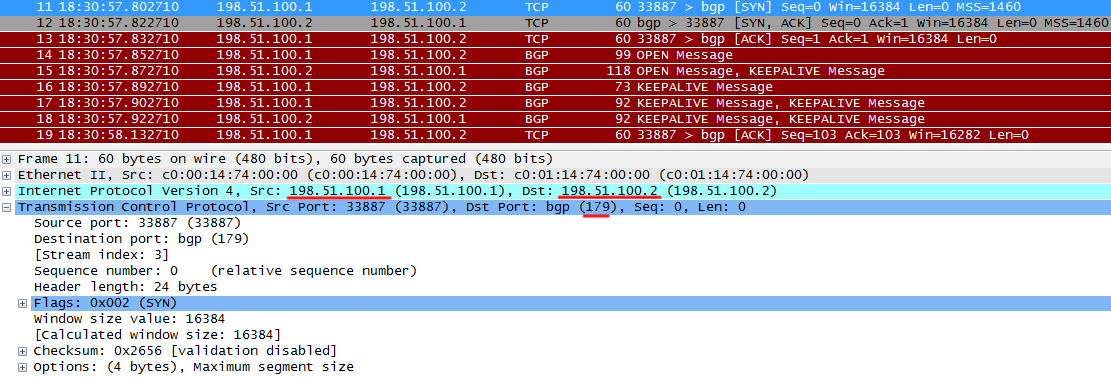
R2はTCP ACKを返します、彼らは言う、私はすべてを得た、私はTCP SYNに同意します。

R1は、R2からSYNを受信したことも報告します。
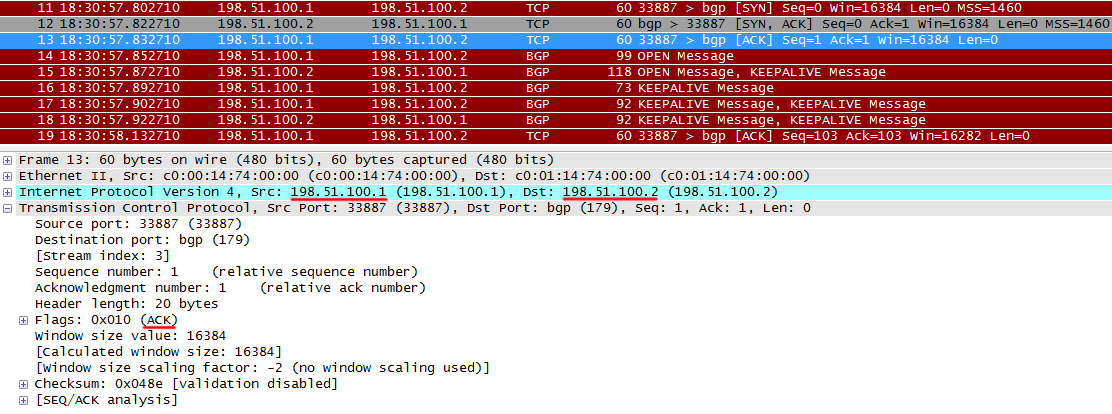
その後、TCPセッションが確立されます。
ACTIVE状態では、BGPがフリーズする場合があります
- R2とのIP接続なし
- BGPはR2で実行されていません
- ポート179はACLによって閉じられます
失敗したTCPセッションの例を次に示します。 BGPはACTIVE状態になり、時々IDLEに切り替わり、再び元に戻ります。
R1からR2に送信されるTCP SYN。
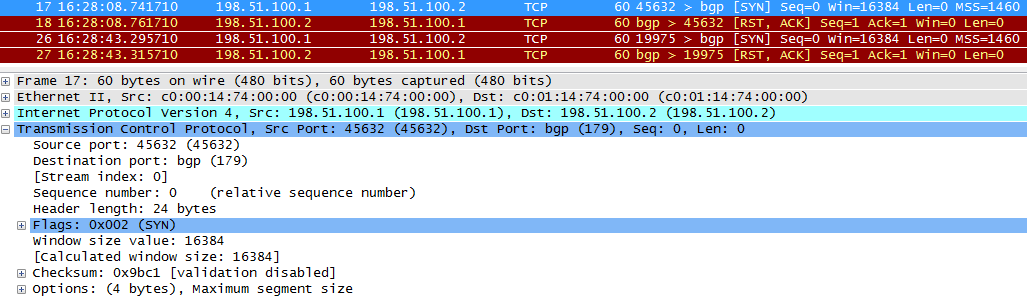
BGPはR2で実行されておらず、R2はSYNがR1およびRSTから受信されたことを示すACKを返します。つまり、接続をリセットする必要があります。

定期的に、R1はTCPセッションの確立を再試行します。
私が環境にやさしい頃、私がプロバイダーと最初にBGPピアリングを設定したとき、私は半日かけて問題を探しました。 BGPがどのように設定されているのか本当に知りませんでしたが、設定のエラーを探しました。自分の状況に微妙な点があると思ったので、すでにコミュニティについて読み始めました。 しかし最後に、ネットワークの入り口でACLを確認するという明るい考えが浮かびました。 はい、プロバイダーのTCPリクエストは拒否され、セッションは確立されませんでした。
注意してください。 プロバイダーは、ACLの「世界」に固執するすべての外部インターフェイスに固執することが一般的です。
III) TCPセッションが確立された後、BGPスピーカーは
OPENメッセージングを開始します。
OPENは、BGPメッセージの最初のタイプです。 パラメータネゴシエーションのために、BGPセッションの最初にのみ送信されます。
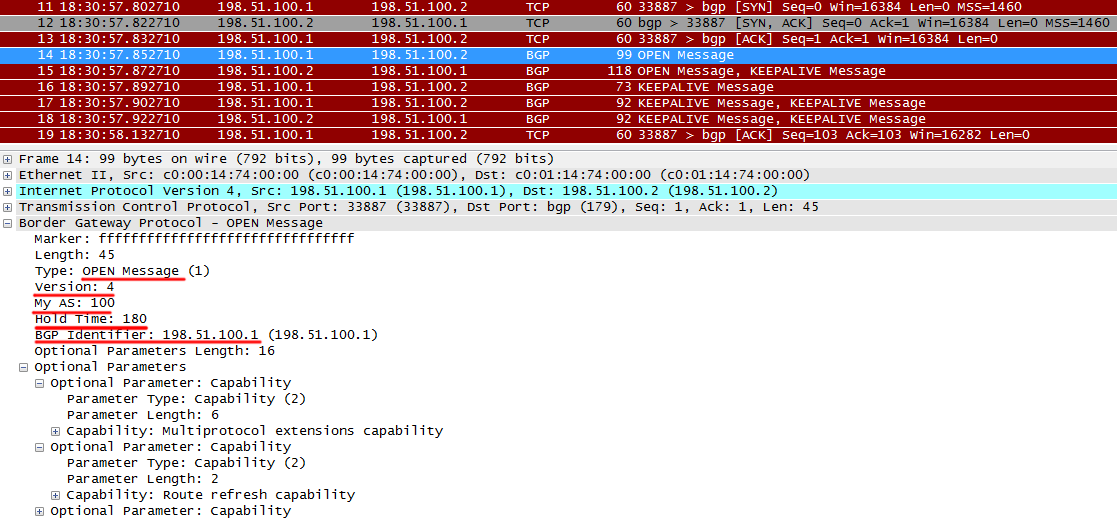
プロトコルバージョン、AS番号、ホールドタイマー、ルーターIDを送信します。 BGPセッションが立ち上がるには、次の条件が満たされている必要があります。
- プロトコルバージョンは同じである必要があります。 異なる可能性は低い
- OPENメッセージのAS番号は、リモート側の設定と一致する必要があります
- ルーターIDは異なる必要があります
また、下部では、ルーターが追加のプロトコル機能をサポートしているかどうかを確認できます。
R1からOPENを受信すると、R2はOPENとKEEPALIVEを送信し、R1からOPENを受信したことを示します。これは、R1が次の状態に移行するための信号です-確立済み。
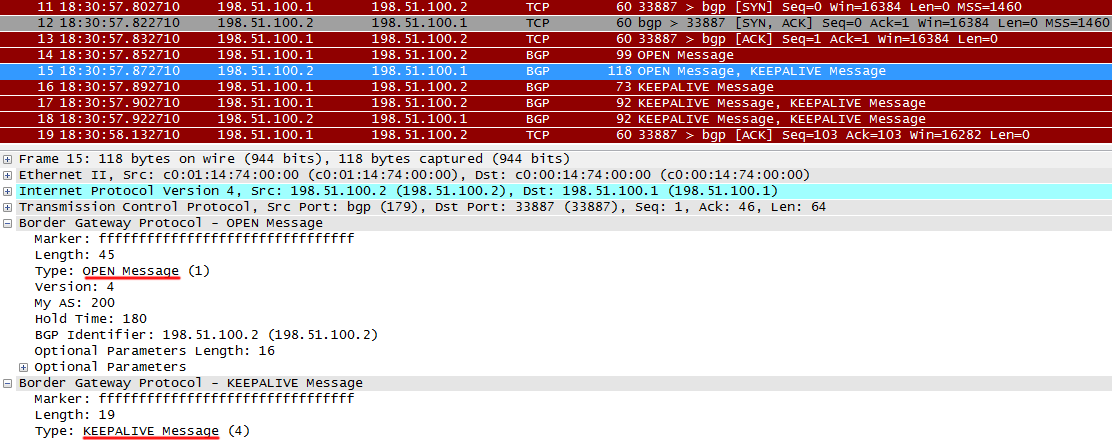
パラメーターの不一致の例を次に示します。
a)不正なAS (AS 300はR2で設定されますが、R1では、このネイバーはAS 200にあると見なされます):
R2は通常のOPENを送信します
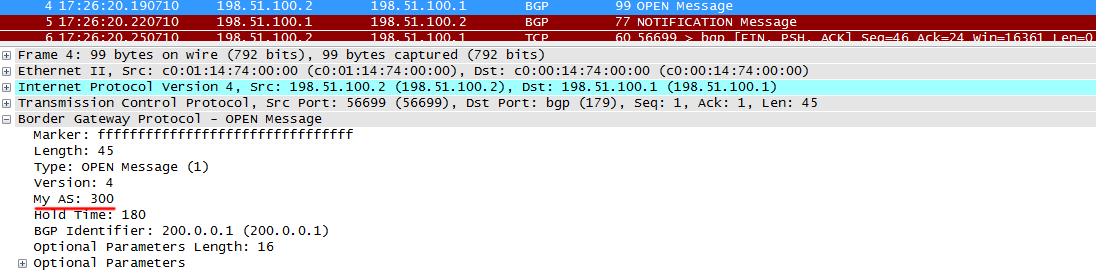
R1は、メッセージ内のASが構成済みのASと一致しないことに気付き、
NOTIFICATIONメッセージを送信してセッションをリセットし
ます 。 セッションを中断するために問題が発生した場合に送信されます。
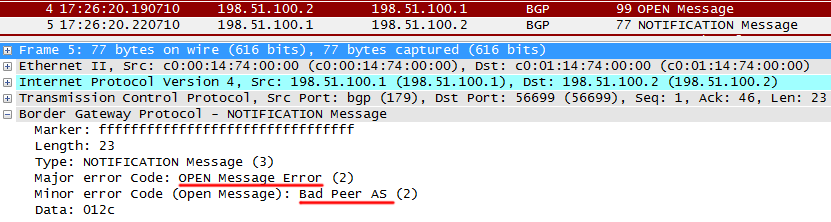
この場合、R1コンソールに次のメッセージが表示されます。

 b)同じルーターID
b)同じルーターIDR2はOPENルーターIDを送信します。これはR1 IDと同じです。
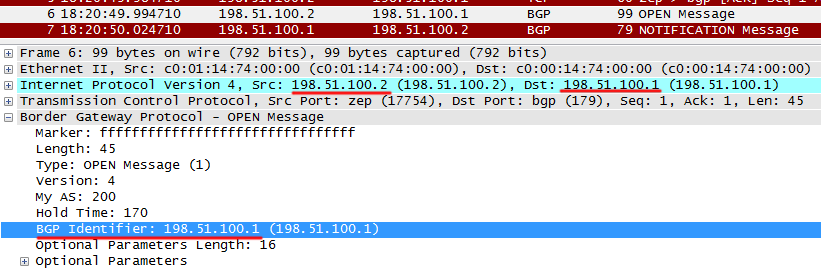
R1はNOTIFICATIONを返します。

同時に、次のメッセージプランがコンソールに表示されます。


これらのエラーの後、BGPは最初にアイドル状態になり、次にアクティブ状態になり、TCPセッションを再確立してからOPENメッセージを再度交換しようとしますが、突然、何かが変更されましたか?
Openメッセージが送信されると、これは
OPEN SENT状態になります。
受信すると、これは
OPEN CONFIRMの状態です。
ホールドタイマーが異なる場合、最小のものが選択されます。 キープアライブタイマーはOPENメッセージで送信されないため、自動的に計算されます(Hold Timer / 3)。 つまり、キープアライブはネイバーによって異なる場合があります
次に例を示します。R2では、タイマーは次のように構成されます。キープアライブ30、ホールド170。

R2はこれらのパラメーターをOPENメッセージで送信します。 R1はそれを取得して比較します。受信した値は170、独自の180です。小さい方の値-170を選択し、キープアライブタイマーを計算します。

これは、R2がキープアライブを30秒ごとに送信し、R1-56を送信することを意味します。しかし、最も重要なことは、それらは同じホールドタイマーを持ち、事前にセッションを中断しないことです。
OPENSENTまたはOPENCONFIRMの状態を確認することはほとんど不可能です。BGPはそれらを保持しません。
IV)これらすべてのステップの後、それらは
ESTABLISHEDの安定状態に移行します。
これは、BGPの正しいバージョンが実行されており、すべての設定に一貫性があることを意味します。
各ネイバーについて、稼働時間-ESTABLISHED状態になっている時間を確認できます。
 V)
V) BGPテーブルにBGPセッションをインストールした後の最初の瞬間には、ローカルルートに関する情報のみ。

ルーティング情報の交換に進むことができます。
このために、
UPDATEメッセージが使用されます。
各UPDATEメッセージには、 1つの新しいルートに関する情報、または古いルートのグループの削除に関する情報を含めることができます。 そして同時に。

それらをより詳細に分析します。
R1はR2にルーティング情報を送信します。
UPDATEメッセージの最初のプラス記号は、パス属性です。 それらについては後で詳しく検討しますが、すでに2つを理解している必要があります。
AS_PATHは、ルートが100のASから来たことを意味します。
NEXT_HOP-これは、R2の論理的な情報であり、このルートのゲートウェイとして指定するものです。 理論的には、必ずしもアドレスR1があるとは限りません。
ORIGIN属性は、ルートの起点を報告します。
- IGP -networkコマンドで手動で設定するか、BGP経由で受信しました!!!!!!!!!!!!!!!!!
- EGP-このコードは表示されません。これは、ルートが「EGP」と呼ばれる古いプロトコルから取得され、すべての場所でBGPに完全に置き換えられたことを意味します
- 不完全 -ほとんどの場合、ルートは再配布を通じて受信されることを意味します
2番目のプラスは、実際のルート情報-NLRI-ネットワーク層到達可能性情報です。 実際には、ネットワーク100.0.0.0/23がここに示されています。
さて、R2からR1に更新します。
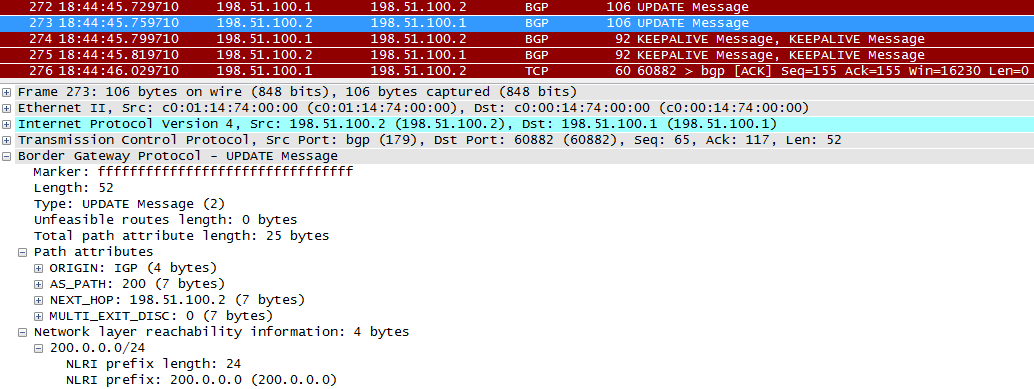
次のKEEPALIVIEは、情報が受信されたことの一種の確認です。
ネットワーク情報がBGPテーブルに表示されます。

そして、ルーティングテーブルで:

BGPセッションが継続する限り、ネットワーク内のすべての変更で更新が送信されます。 OSPFとは異なり、ルーティングテーブルの同期は行われないことに注意してください。 それは技術的には愚かなことです。完全なBGPルートテーブルは、各ネイバーで数十メガバイトの重さがあります。
VI)すべてが順調になったため、各BGPルーターは定期的に
KEEPALIVEメッセージを送信し
ます 。 他のプロトコルと同様、これは「私はまだ生きている」という意味です。 これは、キープアライブタイマーの期限が切れたときに発生します-デフォルトは60秒です。
BGPセッションが正常に確立されているが、その後中断し、一定の頻度で繰り返される場合-キープアライブがパスしないことを確認してください。 ほとんどの場合、サイクル期間は3分です(デフォルトではホールドタイマー)。 L2で問題を探す必要があります。 たとえば、通信品質の低下、インターフェイスの輻輳、CRCエラーなどが考えられます。
別のタイプのBGPメッセージ-ルート
更新 -を使用すると、BGPプロセスを再起動せずに、すべてのルートを再度近隣から要求できます。
すべてのタイプのBGPメッセージの
詳細をご覧ください 。
BGPの完全な
FSM (
状態マシン )は次のようになります。
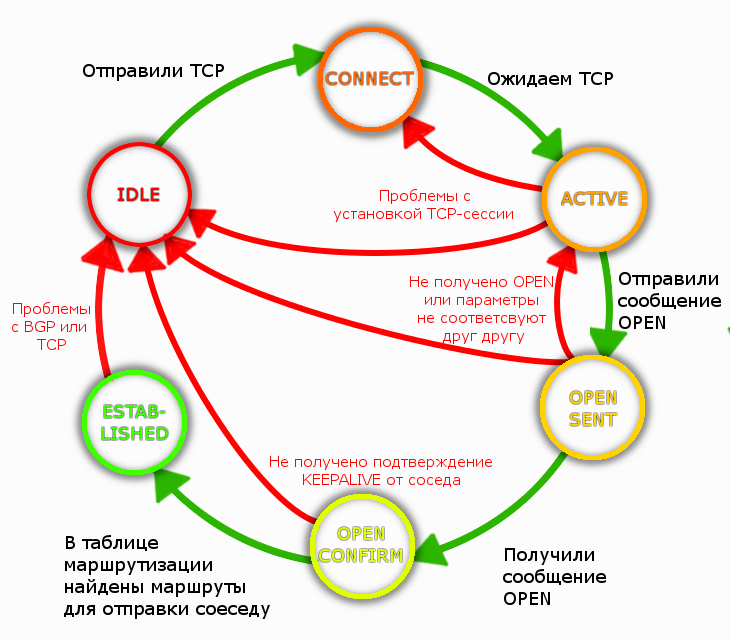
 ネットワークで各ステップの詳細な説明が見つかりました。バックフィルの質問:
ネットワークで各ステップの詳細な説明が見つかりました。バックフィルの質問:アップタイムBGPセッションが24時間であるとします。 過去12時間にどのメッセージがネイバー間で送信されることが保証されていませんでしたか?
次に、このようなネットワークに視野を広げます。
サブネットのない写真

そして、ルータR1にあるBGPルートテーブルを見てみましょう。

ご覧のとおり、ルートはNextHopだけでなく、目的のサブネットへのデバイスのリストだけではありません。 これはASのリストです。 それ以外の場合、AS-Pathと呼ばれます。
つまり、123.0.0.0 / 24ネットワークに入るためには、パケットを送信し、AS 200およびAS 300を克服する必要があります。
ASパスは次のように形成されます。
a)ルートがAS内を歩いている間、リストは空です。 すべてのルーターは、同じASから受信したルートを理解します
b)ルータは、外部ネイバーへのルートをアナウンスするとすぐに、ASパス番号にAS番号を追加します。
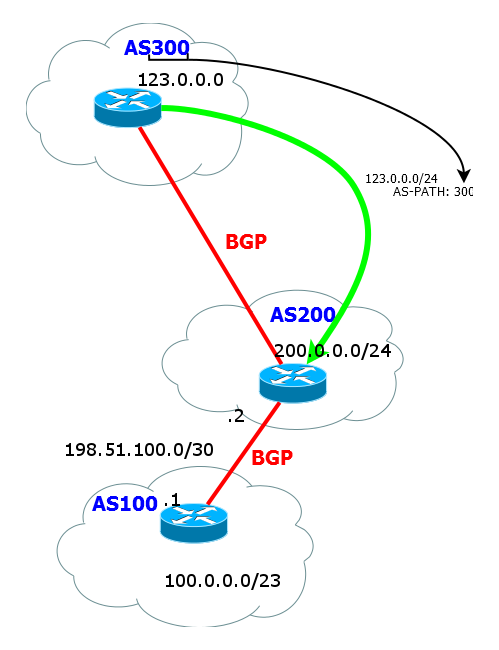
c)隣接AS内では、リストは変更されず、元のASの番号のみが含まれます
d)ルートが隣接ASからリストの先頭にさらに転送されると、現在のAS番号が追加されます。
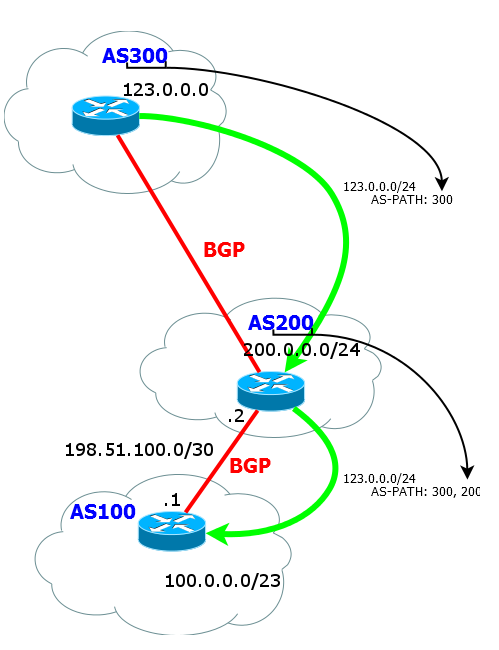
などなど。 ルートが外部ネイバーに渡されると、AS番号は常にASパスリストの先頭に追加されます。 つまり、実際には、これはスタックです。
ASパスは、R1が宛先ネットワークへのパスを知るだけでなく、実際にはネクストホップで十分です。各ルーターは、ルーティングテーブルに基づいて決定を行います。 実際、ここではさらに2つの重要な目標を追求しています。
1)ルーティングループの防止。 AS-Pathには重複した番号を使用しないでください
実際、AS-Pathで2つの場合にASNを繰り返すことができます
a)以下で説明するAS-Path Prependを使用する場合。
b)互いに直接接続されていない、同じASの2つの部分を接続する場合。
2)最適なルートの選択。 ASパスが短いほど、ルートの優先度は高くなりますが、それについては
後で詳しく説明します
BGPのセットアップと実践
この問題では、理論が最も理解しやすいため、理論と実践を組み合わせています。 実際、LinkMiApネットワークに目を向けます。
いつものように、不要なものはすべて切り取り、必要なものを追加します。
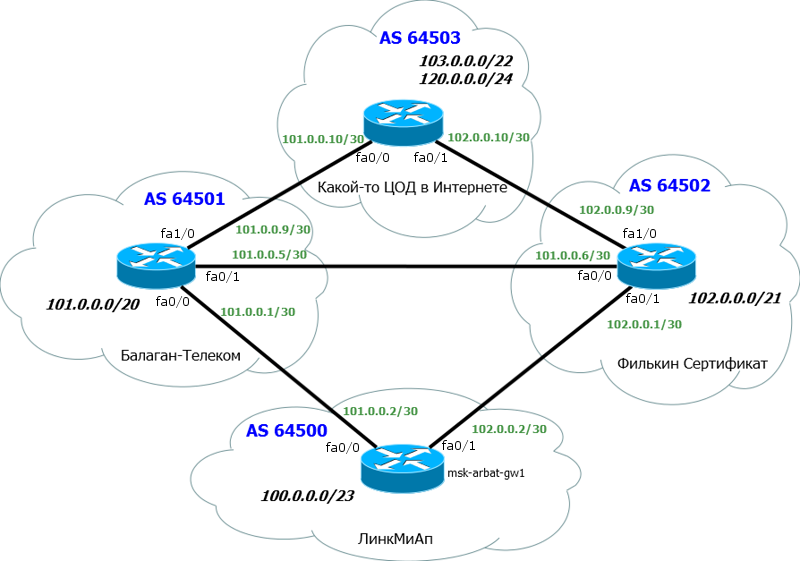
以下は、メインルーターmsk-arbat-gw1です。 構成と理解を簡素化するために、すべての古い設定と無料のインターフェースを放棄します。
上記の2つの古いプロバイダー-Balagan TelecomとFilkin Certificateです。
もちろん、各プロバイダーには独自のASがあります。 もう1つのデッドエンドASを追加しました。その前に、たとえばインターネット上のデータセンターであってもチェックします。
簡単にするために、各ASは1つのルーターのみで表され、ACLはなく、中間デバイスはないことを前提としています。
両方のプロバイダーとのBGPセッションを発生させています。
次の情報は重要です。
1)AS番号とIPアドレスのブロック。 AS64500とブロック:100.0.0.0/23を既に受け取っています。
2)AS AS Balagan Telecom番号およびそれとのリンクサブネット。 AS64501およびリンクネットワーク:101.0.0.0/30。
3)AS「フィルキン証明書」とそれにリンクするサブネットの番号。 AS64502およびリンクネットワーク:102.0.0.0/30。
BGPを介して接続する場合、/ 30サブネットマスクのパブリックアドレスは通常リンクアドレスとして使用され、上位プロバイダーから提供されます。
これは、どこでもトラフィックがパブリックアドレスをたどり、トレースの途中で10.X.X.Xが表示されないという単純な理由で行われます。 禁止されているわけではありませんが、通常はこのルールを順守しています。
ありきたりから始めましょう。
インターフェイス設定:msk-arbat-gw1 R1(config)#int fa0/0 R1(config-if)#ip address 101.0.0.2 255.255.255.252 R1(config-if)#no shutdown R1(config)#int fa0/1 R1(config-if)#ip address 102.0.0.2 255.255.255.252 R1(config-if)#no shutdown


次に、ループバックインターフェイスにアドレスを割り当ててから、接続を確認します。
R1(config)#int loopback 0 R1(config-if)#ip address 100.0.0.1 255.255.255.255
BGPの番。 ここでは、各行に焦点を当てます。
R1(config)#router bgp 64500
最初に、BGPプロセスを開始し、AS番号を指定します。 これは、LIRが発行した番号です。 これはOSPFではありません-自由は許可されていません。
次に、ピアリングを上げます。
R1(config-router)#neighbor 101.0.0.1 remote-as 64501
neighborコマンドを使用して、誰とセッションを確立するかを指定します。 ルーターが最初にTCP-SYNを送信し、次にOPENするのはアドレス101.0.0.1です。 また、リモート自律システムの番号-64501を示す必要があります。
背面の構成は対称的です:
R2(config)#router bgp 64501 R2(config-router)#neighbor 101.0.0.2 remote-as 64500
すでに1つのメッセージ
*Mar 1 00:11:12.203: %BGP-5-ADJCHANGE: neighbor 101.0.0.2 Up
BGPが上昇したと判断できますが、そのステータスを確認しましょう。
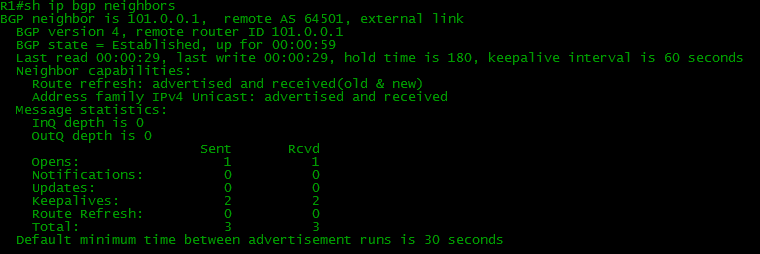
ここで、彼らはすべての州を駆け巡り、現在、彼らのステータスは確立されています。
ルーターは1つのOPENを送受信し、この間にすでに2つのキープアライブを送受信できました。
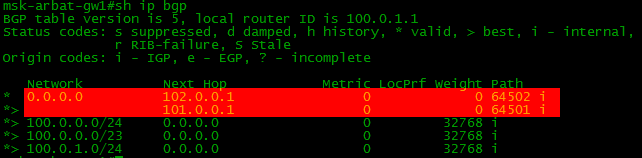
sh ip bgpコマンドを使用すると、
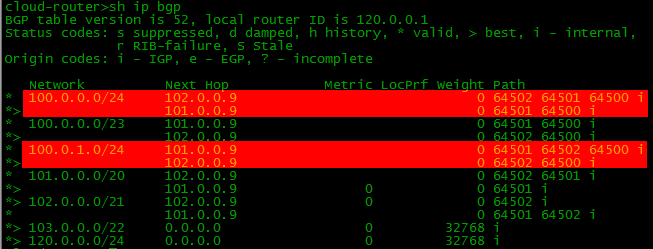
BGPが認識しているネットワークを確認できます。
空です。 このグリッド100.0.0.0/23があることを示して、プロバイダーに渡す必要がありますか?
これには3つのオプションがあります。
-networkコマンドでネットワークを定義する
-別のソースからのインポート(直接、静的、IGP)
-aggregate-addressコマンドを使用して集約ルートを作成します
今後の展望として、ネットワークの優先度が高いことに注意してください。インポートでは、過剰を逃さないように注意する必要があります。
R1(config)#router bgp 64500 R1(config-router)#network 100.0.0.0 mask 255.255.254.0
ネットワークが表に表示されているかどうかを確認します。
奇妙だが、いや、何も現れなかった。 R2でも。
そして、問題は、
networkコマンドで登録した
ネットワークへの正確なルートがなければならないということです。そうでなければ、BGPテーブルに追加されません-これは前提条件です。 もちろん、そのようなルートはありません。 彼はどこから来たのですか?

実際には、そのようなルートを登録する場所はないので、1つのループバックインターフェイスを除き、そのようなネットワークはどこにも存在しないため、次のことができます。
R1(config)#ip route 100.0.0.0 255.255.254.0 Null 0
このルートは、このサブネット上のすべてのパケットが破棄されることを示しています。 しかし、心配しないでください、通常の操作は邪魔されません。 より正確なルート(/ 23、たとえば、/ 24、/ 30、/ 32よりも大きいマスク)がある場合、最長プレフィックス一致ルールに従って推奨されます。
そして今、BGPテーブルにローカルルートがあります。

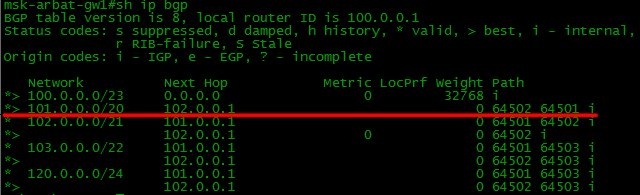
スキームのすべてのデバイスでBGPと必要なルートを設定すると、境界(境界-ネットワーク境界上のルーター)のBGPとルーティングテーブルは次のようになります。
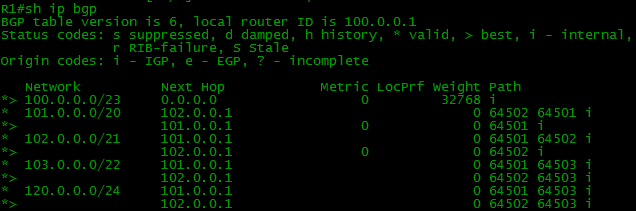

BGPテーブルにはいくつかのネットワークへの2つのルートがあり、ルーティングテーブルには1つしかないことに注意してください。 ルーターは最適なものを選択し、ルーティングテーブルに転送するだけです。 これについては
後で説明します。
これは必要最小限であり、その後はもう少し幸せになります。
=======================
 タスク番号1
タスク番号1スキーム:

条件:
ルーターの設定は重要ではありません。 ルートフィルタは設定されていません。 AS400経由のネットワーク195.12.0.0/16への代替ルートが欠落しているのはなぜですか?
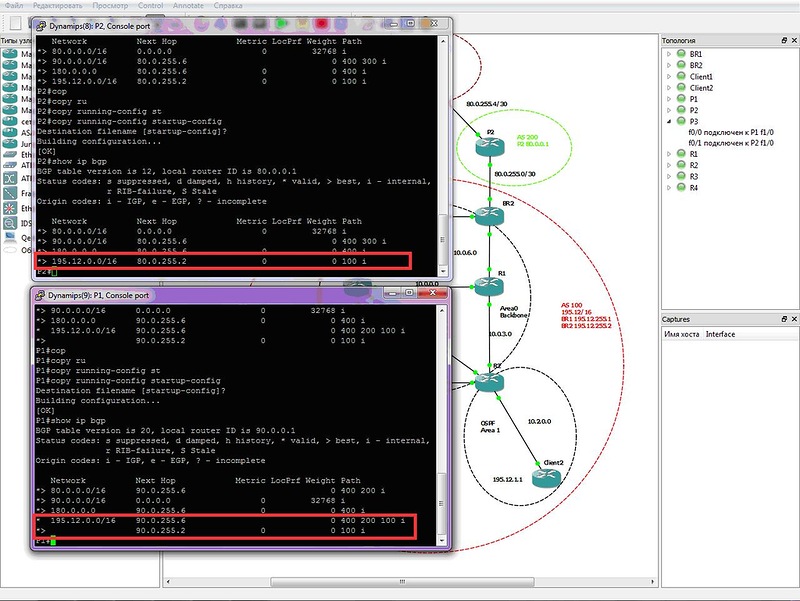 サイト
サイトでのタスクの詳細
=======================
完全なビューとデフォルトルート
BGPについて話し、プロバイダーに接続する場合、このトピックに触れることはできません。 ASとPIアドレスをすでに持っているLinkMiApがBalagan-Telecomと接続する場合、それらからの最初の質問の1つは「フルビューまたはデフォルト?」です。 ここでの主なことは、混乱しないこと、ナンセンスを凍結しないことです。
これまでに見てきたこと、いわゆるフルビュー-ルーターは、この場合5個または6個であっても、
すべてのインターネットルートを
絶対に学習します。 実際には、現在40万を超えています。したがって、1つのプロバイダーから40万のルートを受け取り、2番目のプロバイダーからは40万のルートを受け取ります。 3番目のバックアップに加えて、さらに400kがある場合があります。 合計で百万人以上。
さて、このためだけに少しアンダーエンタープライズtsiskaシニアシリーズを購入しないでください?
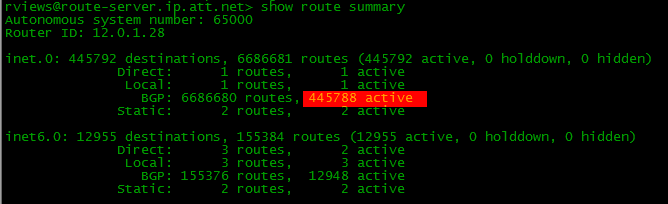 *パブリックサーバーの1つからのルーティングテーブルの出力(telnet route-server.ip.att.netで利用可能)
*パブリックサーバーの1つからのルーティングテーブルの出力(telnet route-server.ip.att.netで利用可能)実際、ASを持っているすべての人が完全なビューを必要とするわけではありません。 通常、当社のような企業の場合、デフォルトルートで十分です。名前からわかるように、違いは明らかです。 後者の場合、数十万の特定のルートではなく、各プロバイダーからデフォルトルートが1つだけ送信されます(一般的に
eを含むこともできます)。
両方を支持する小さな議論をしましょう。
- 完全なビュー 。 インターネットの構造に関する完全で純粋な知識があります。 インターネット上の任意のアドレスに、自分からパスを表示できます。
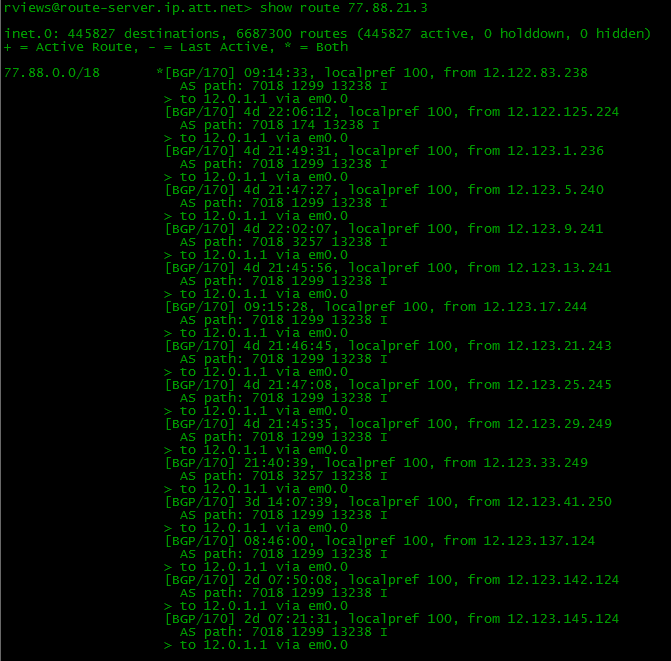
どのASがそれにつながるかを知っています。 RIPE Webサイトを通じて、どのプロバイダーがトランジットを提供しているかを確認できます。 すべての変更に従います。 誰かが最初のリンク(突然、あなたやプロバイダーではなく、さらに別の場所)に突然落ちた場合、BGPはルーティングテーブルを追跡して再構築し、2番目のプロバイダーを介してデータを転送します。
同時に、ルートを非常に柔軟に管理できるため、最適なパスを選択するための標準的な手順に干渉します。
たとえば、Balagan Telecomを介してYandexへのすべてのトラフィックを許可し、Filkin証明書を介してgoogleを許可します。 これは、 負荷分散と呼ばれます 。
これは、たとえば、特定のプレフィックスのルート優先度を設定することにより実現されます。
スピーカーが移動中の場合、つまり、BGPを介してより多くのクライアントを接続する場合は、フルビューが必要です。
これらのすべての利点をパフォーマンスで支払う必要があります。つまり、メモリ使用率が高く、BGPセッションを確立した後のルーティング情報の非常に長い調査です。 たとえば、上位プロバイダーとのリンクがけいれんした後、完全な復旧には数分かかる場合があります。
- デフォルトルート
まず、もちろん、これにより、機器のリソースが大幅に節約されます。
第二に、保守が簡単だという人もいるかもしれません。 AS全体で何十万ものルートを運転する必要はありません。
第三に、インターネットの状態と受信者の実際の可用性についての考えがありません。上流から受信したデフォルトを盲目的に単純に信頼します。 つまり、上記の問題の場合、あなたはそれについて知らず、いくつかのサービスが落ちるかもしれません。 しかし、ここでは、より高いプロバイダーでは、ネットワークの信頼性が桁違いに高く、心配する必要がないことを願っています。
デフォルトでルートを受信するときの着信トラフィックのバランスと分散は、まったく影響を受けません-問題は同じです。 しかし、もちろん、すべてを発信することで、少し異なりますが、以前の柔軟性はもうありません。
一般的に、非常に無礼なアドバイスは次のように聞こえます。
自分でトランジットを整理する予定がなく(クライアントをスピーカーに接続する)、発信トラフィックを細かく分配する必要がない場合は、デフォルトルートで十分です。
ただし、あるプロバイダーからフルビューを受け入れ、別のプロバイダーからデフォルトを受け入れることは確かに意味がありません。この場合、ルーターはより具体的なパスを選択するため、発信トラフィックで常に1つのリンクがアイドル状態になります。
さらに、すべてのプロバイダーから、Defaultと特定のプレフィックス(この特定のプロバイダーなど)を取得できます。 したがって、必要なリソースへのフルビューのない特定のルートがあります。
ダウンストリームルーターへのデフォルトルート転送を構成する方法の例を次に示します。
balagan-router(config-router)#neighbor 101.0.0.2 default-originate
そして、この後のボーダーのルートテーブルは次のようになります。
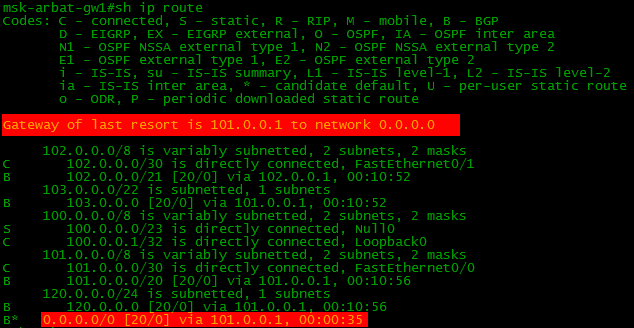
つまり、通常のルート(フルビュー)に加えて、デフォルトルートも送信されます。
ここで、デフォルトルートはフルビューとは対照的ではないと推測し始める必要があります。 必ずしも「どちらか一方」(英語のXORのようにhealyまたはxylの概念を導入する必要があります)が存在するわけではありませんが、フルビューまたはデフォルトルートと他のいくつかのルートに加えてデフォルトルートを使用できます。
=======================
タスク番号2スキーム:一般的なネットワーク図
割り当て:
プロバイダーによるフィルタリングを設定して、デフォルトルート
のみを提供し、それ以外は提供しないようにします。
つまり、BGPテーブルは次のようになります。
 サイト
サイトでのタスクの詳細
=======================
完全なBGPテーブルの利点と害についてLooking Glassおよびその他のツール
BGPを操作するための非常に強力なツールの1つは、Looking Glassです。 これらはインターネット上にあるサーバーで、外部からネットワークを見ることができます。可用性を確認し、自律システムへのパスがどのASを介しているかを確認し、内部アドレスへのトレースを開始します。

「聞いて、でもそこに私の発表がどのように見えるか見てみてください」と誰かに尋ねたかのようです。しかし、誰かに尋ねる必要はありません。
外部ツールの力を過小評価しないでください。 かつて私は、外部への返品率が非常に低いという問題を抱えていました。 彼女はかろうじて数メガビットを超えました。 かなり長い間トラブルシューティングを行った後、Looking Glassを見ることにしました。 VPNチャネルを介して、IBGPがインストールされている別の都市の支社へのトラフィックが到着していることを発見したとき、私は驚きました。 当然、チャネル幅は小さく、ほぼ完全に利用されていました。
インターネット上のBGPアナウンスを追跡し、予期しない何かが発生した場合、ネットワーク所有者(
BGPMon 、
Renesys 、
RouterViews)に通知できる特別な組織もあります。
彼らのおかげで、いくつかの世界的な事故が防止されました。
BGPlayサービスを使用すると、ルート配布情報を視覚化できます。
nag.ruでは、「AS 7007インシデント」や「Googleの2005年5月の停止」など、誤ったBGPアナウンスメントがインターネット上でグローバルな問題を引き起こした最も顕著なケースについて読むことができます。
BGPを操作するためのさまざまな優れたツールに関する非常に優れた
記事 。
Looking Glassサーバーのリスト 。
コントロールプレーンとデータプレーン
ルート管理の深い渦に突入する前に、最後の叙情的な余談をします。 章のタイトルの概念に対処する必要があります。
やがて、
MPLS Enabled Applicationを読んで、脳を壊しました。 著者が何について話しているのか理解できませんでした。
恥ずかしくないように。
これらはモデルのレベルではなく、環境のレベルでもデータ転送の瞬間でもありません-これは非常に抽象的な区分です。
制御レベル(
Control Plane )-データ転送の条件を提供するサービスプロトコルの作業。
たとえば、BGPが起動すると、すべての状態を実行し、ルーティング情報を交換します。
または、MPLSネットワークでは、LDPはラベルをプレフィックスに配布します。
または、BPDUを交換するSTPがL2トポロジを構築します。
これらはすべて、コントロールプレーンプロセスの例です。 つまり、送信のためのネットワークの準備、つまり、ルーティングテーブルを埋めるスイッチングの編成です。
送信レイヤー(
データプレーン )-有用な顧客データを実際に送信します。
2つのレベルのデータが「互いに向かって」異なる方向に進むことがよくあります。 したがって、BGPでは、AS200がAS100にデータを転送できるように、AS100からAS200にルートが転送されます。
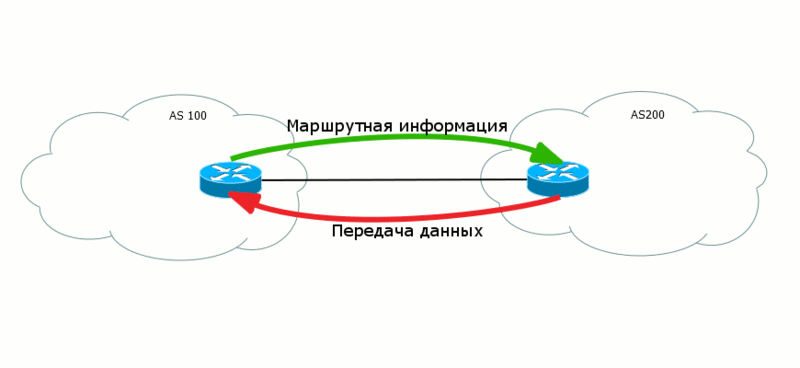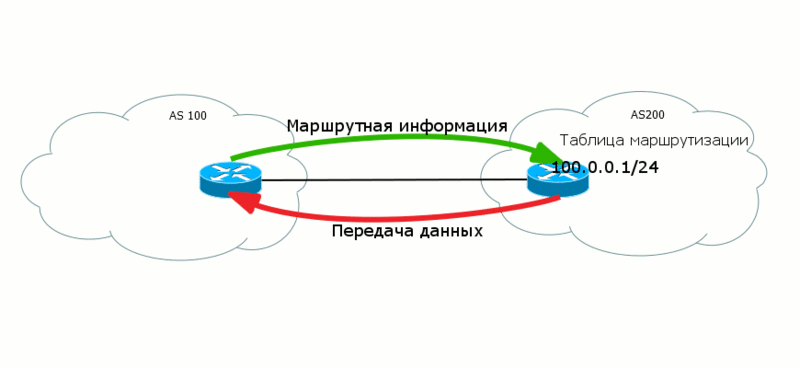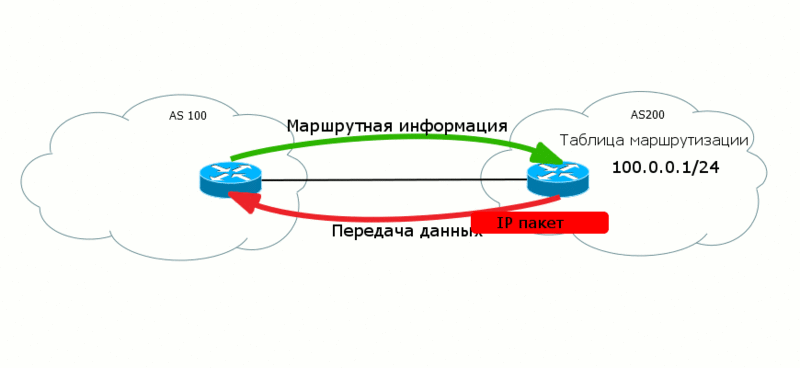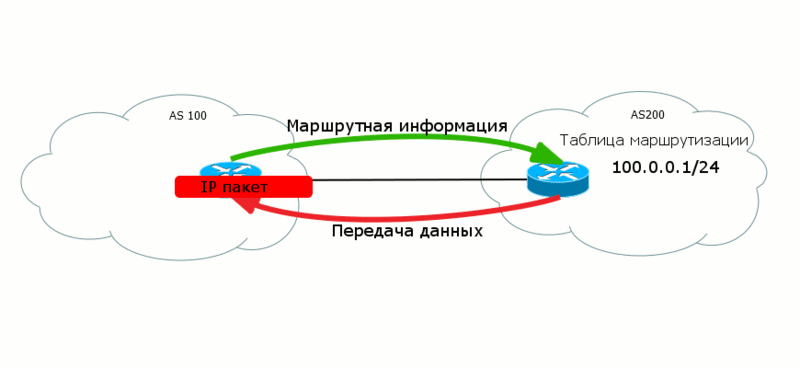
さらに、さまざまなレベルで、さまざまな作業パラダイムが存在する場合があります。 たとえば、MPLS Data Planeでは、接続の作成に重点が置かれています。つまり、データは事前定義されたパス(LSP)に沿ってそこに送信されます。
しかし、このパス自体は、ホストからホストへの標準的なIP法に従って準備されます。
レベルの目的と違いは何かを理解することが重要です。
BGPの場合、これは原則の問題です。 ルートをアナウンスすると、実際には
着信トラフィックのパスが作成されます。 つまり、ルートはあなたから来て、トラフィックはあなたに来ます。
ルート選択
このような状況はルートにあります。
近隣から受信した絶対的にすべてのルートが保存されるBGPテーブルがあります。
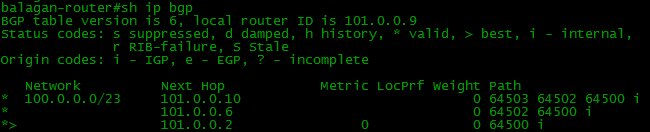 つまり、ネットワーク100.0.0.0/23への複数のルートがある場合、これらの「不良」に関係なく、それらはすべてBGPテーブルに含まれます。
つまり、ネットワーク100.0.0.0/23への複数のルートがある場合、これらの「不良」に関係なく、それらはすべてBGPテーブルに含まれます。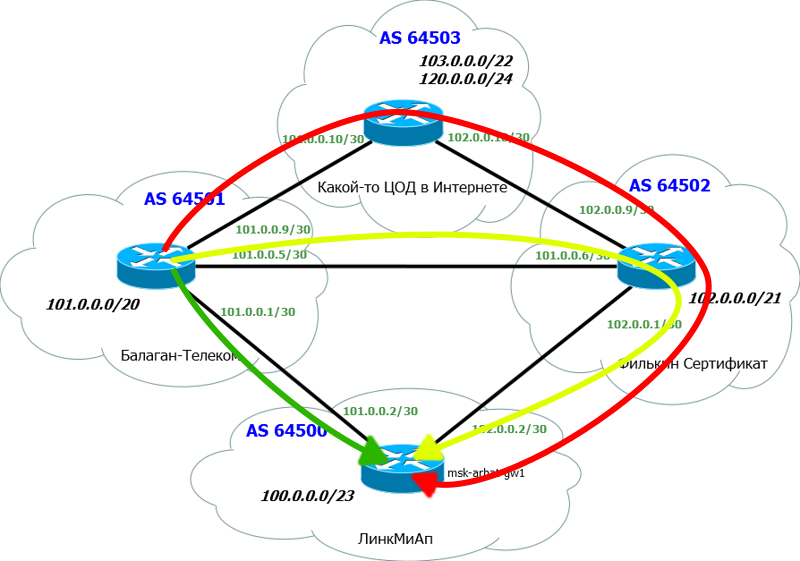
そして、最高の最高のものだけを保存するルーティングテーブルがあります。 同様に、BGPはすべての着信ルートをアナウンスするのではなく、最良のもののみをアナウンスします。 つまり、1つの近隣から同じネットワークへの2つのルートを取得することはありません。
したがって、最良の選択基準:
- 最大重量(ルーターのローカル、Ciscoのみ)
- 最大ローカルプリファレンス(AS全体)
- ルーターのローカルルートを優先する(ネクストホップ= 0.0.0.0)
- 自律システムを通る最短経路。 (最短AS_PATH)
- 最小オリジンコード(IGP
- 最小MED値(スタンドアロンシステム間で分散)
- eBGPパスはiBGPパスよりも優れています
- 最も近いIGPネイバーを通るパスを選択します
この条件が満たされると、複数の同等のリンク間で負荷分散が行われます
次の条件はベンダーによって異なる場合があります。
- eBGPパスの最も古いルートを選択する
- 最小のBGPルーターIDを持つネイバーを通るパスを選択します
- 最小のIPアドレスを持つネイバーを通るパスを選択します
ご覧のとおり、多くの選択基準があります。 さらに、それらは非常に複雑であり、それらをすべて理解することは簡単ではありません。 ゆっくり参加してください。
以下で説明する属性のいくつかについて説明します。具体的には、別の記事でルートを選択します。
=======================
タスク番号3スキーム:一般的なネットワーク図
条件:すべてのルーターの全景
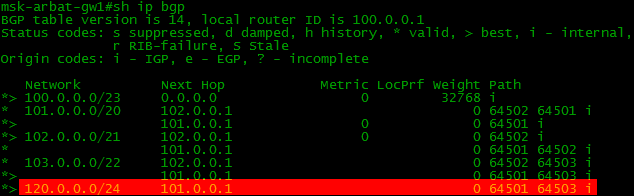
ここでBalagan TelecomプロバイダーのルーターのBGPテーブルを見ると、ネットワーク102.0.0.0/21-Filkin証明書ネットワークへの3つのルートが表示されます。 そして、ルートの1つがLinkMiApネットワークを経由しています。

これは、ボーダーが他の人のルートをさらに発表していること、つまりASが通過していることを示しています。
割り当て:
AS64500が送信中にならないようにフィルタリングを設定します。
サイトでのタスクの詳細
=======================
ルート管理
BGPを使用した負荷分散の大きなトピックに移る前に、このプロトコルでルートを一般的に管理する方法を理解する必要があります。
ルーティング情報の交換をこのように制御できる可能性があるため、IGPとは異なり、BGPがいくつかの異なるプロバイダーの相互作用に柔軟で適切なものになります。
そして、このためのツールがたくさんあります。
- AS-Path ACL
- プレフィックスリスト
- 重さ
- ローカル設定
- MED
ただし、アドバタイズまたは受信されたルートをフィルタリングできるのは最初の2つのみで、残りは優先順位のみを設定します。
AS-Path ACL
非常に強力ですが、最も一般的なメカニズムではありません。
AS-Path ACLを使用すると、たとえば、AS 200に属するルートのアナウンスの受け入れを禁止することができます。そうすることはしたくありません。
このアプローチの最も難しい部分は、すべての正規表現を覚えて、それらの使用方法を学ぶことです。 最初に、彼らからの頭:
| サイン | 価値 |
|---|
| 。 | スペースを含む任意の文字 |
| * | expressionと一致する0個以上の一致 |
| + | 式との1つ以上の一致 |
| ? | 式と一致する0または1つの一致 |
| ^ | 行頭 |
| $ | 行末 |
| _ | 任意のセパレーター(開始、終了、スペースを含む) |
| \ | 次の文字を特別なものとして受け取らないでください |
| [] | 範囲内の文字のいずれかに一致 |
| | | 論理的または |
もう少し明確にするために、いくつか例を示します。
1AS番号の前後に記号「_」があります。これは、ASパス番号200の先頭、中間、または末尾にあることができることを意味します。
2「^」はリストの先頭を意味し、「$」は末尾を意味します。 つまり、ASパスにはAS番号が1つしかありません。これは、ルートがAS 200で発信され、そこからすぐに転送されたことを意味します。
3「$」はリストの最後を意味します。つまり、これが最初のASであり、そのルートから始まります。「_」記号は、次に何が関係なく、少なくとも7つの他のASであることを示します。
4「^」記号は、ASN 200が最後に追加されたこと、つまりAS 200からルートが来たことを意味しますが、これは彼が生まれたという意味ではありません-「_」記号は、これがリストの最後であることを示し、または、次のASの前のスペースかもしれません。
5ASパスリストは空です。つまり、ルートはローカルであり、AS内で生成されます。
例
ここでは、ネットワークで、AS 64501から発信されたルートをフィルタリングします。つまり、101.0.0.1近隣からすべてのインターネットルートを受信しますが、ローカルルートは受信しません。
ip as-path access-list 100 deny ^64501$ ip as-path access-list 100 permit .* router bgp 64500 neighbor 101.0.0.1 filter-list 100 in
 デバイス構成正規表現の指示
デバイス構成正規表現の指示プレフィックスリスト
ここではすべてがシンプルで論理的です。 まあ、ほとんど。
プレフィックスリストは、通常のネットワーク/マスクであり、このようなルートが許可されているかどうかを示しています。
コマンド構文:
ip prefix-list {list-name} [seq {value}] {deny|permit} {network/length} [ge {value}] [le {value}]
list-name-リストの名前 。 あなたのKO。 通常、
name_inまたは
name_outとして指定されます。 これにより、着信ルートと発信ルートのどちらが動作するか
がわかり
ます (もちろん、この段階では決定されません)。
seq-ルールの序数(ACLの場合と同様)。したがって、それらを使用して操作しやすくなります。
拒否/許可 -そのようなルートを許可するかどうかを決定します
ネットワーク/長さ -192.168.14.0/24などの通常のレコード。
しかし、さらに注意が必要です。もっと複雑です。さらに2つのパラメーター、
geと
leが可能です。 NAT(またはFortran)の構成と同様に、これは「
g reater or
e qual」および「lessまたは
e qual」を意味します。
つまり、特定のプレフィックスを1つだけでなく、その範囲も指定できます。
たとえば、そのような記録
ip prefix-list NetDay permit 10.0.0.0/8 ge 10 le 16
次のルートが選択されることを意味します。
10.0.0.0/10、10.0.0.0/11、10.0.0.0/12、10.0.0.0/13、10.0.0.0/14、10.0.0.0/15、10.0.0.0/16
例
ここで、プロバイダーFilkin証明書を介したネットワーク120.0.0.0/24のアナウンスの受け入れを禁止し、その他すべてを許可します。 エントリ
0.0.0.0/0 le 32は、マスク長(32(0-32)以下)のサブネットを意味します。
ip prefix-list TEST_PL_IN seq 5 deny 120.0.0.0/24 ip prefix-list TEST_PL_IN seq 10 permit 0.0.0.0/0 le 32 router bgp 64500 neighbor 102.0.0.1 prefix-list TEST_PL_IN in
念のため、予約します。最後の例は、次のプロバイダーがあなたに送信しないことを意味しません-もちろん、それはあなたのポリシーについて何も知らないためです-しかし、そのようなアナウンスを受け取ったルーターはそのルートをBGPに追加しません-テーブル。
デバイス構成ルートマップ
これまで、すべてのルールは無条件で適用されてきました-ごちそうまたはごちそうからのすべての発表に対して。
ルートマップ(他のベンダーの場合はルーティングポリシーと呼ぶことができます)を使用して、アナウンスを差別化することで非常に柔軟にルールを適用できます。
コマンドの構文は次のとおりです。
route-map {map_name} {permit|deny} {seq} [match {expression}] [set {expression}]
map_name-マップ名
許可/拒否 -ルートマップの条件に該当するデータの通過を許可するかどうか
seq-ルートマップのルール番号
match-トラフィックがこのルールに該当する条件。
式 :
| 基準 | 設定コマンド |
|---|
| ネットワーク/マスク | 一致するIPアドレスのプレフィックスリスト |
| ASパス | パスとして一致 |
| BGPコミュニティ | マッチコミュニティ |
| ルート発信者 | match ip route-source |
| BGPネクストホップアドレス | マッチIPネクストホップ |
設定 -フィルタ処理ルートをどうするかの式:| パラメータ | 設定コマンド |
|---|
| ASパスの先頭に追加 | パスとして追加する |
| 重さ | 設定重量 |
| ローカル設定 | ローカル設定を設定します |
| BGPコミュニティ | コミュニティを設定する |
| MED | メトリックを設定 |
| 起源 | 原点を設定 |
| BGPネクストホップ | ネクストホップを設定する |
応用例
Filkin証明書を介して120.0.0.0/24サブネットに行き、Balagan Telecomを介して103.0.0.0/22に行くことが望ましいことを指摘します。これを行うには、Local Preference属性を使用します。このパラメーターの値が高いほど、ルートの優先度が高くなります。 ip prefix-list TEST1_IN seq 5 permit 120.0.0.0/24 ip prefix-list TEST2_IN seq 5 permit 103.0.0.0/22 route-map BGP1_IN permit 10 match ip address prefix-list TEST1_IN set local-preference 50 route-map BGP1_IN permit 20 set local-preference 100 route-map BGP2_IN permit 10 match ip address prefix-list TEST2_IN set local-preference 50 route-map BGP2_IN permit 20 set local-preference 100 router bgp 64500 neighbor 101.0.0.1 route-map BGP2_IN in neighbor 102.0.0.1 route-map BGP1_IN in
最初に、通常の方法でprefix-listを作成し、120.0.0.0 / 24サブネットを割り当てました。許可は、ルートマップルールが将来このプレフィックスに作用することを意味します。通常のACLと同様に、他のすべてに対する暗黙の拒否ルールが続きます。この場合、ルートマップに該当するのは120.0.0.0/24のみであり、それ以外は何も含まれないことを意味します。作成されたルートマップBGP1_INでは、作成されたprefix-listに該当するルーティング情報(permit)の通過を許可しました(match ip address prefix-list TEST1_IN)。これらのアナウンスメントでは、ローカルプリファレンスを50に設定します-標準の100よりも低く設定します(local-preference 50を設定します)。つまり、彼らは「面白くない」でしょう。最後に、マップを特定のBGPネイバー(ネイバー102.0.0.1 route-map BGP1_IN in)にバインドします。結果は何ですか?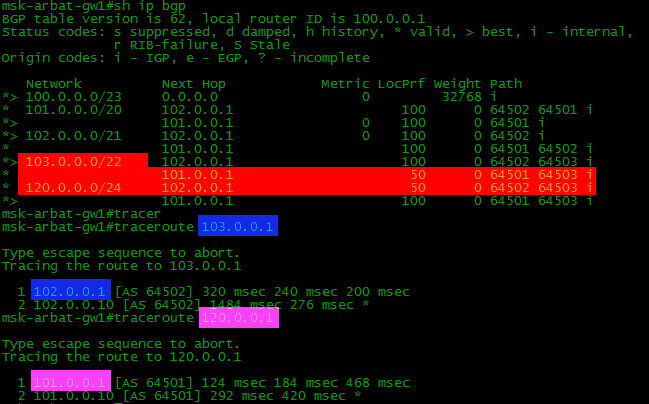 デバイス構成他の例については、次のセクションで説明します。===================== タスク#4スキーム:一般的なネットワーク図条件:LinkMiApは両方のプロバイダーからフルビューを受け取ります。件名:トラブルシューティング。プロバイダーから:完全なBGPルートテーブルmsk-arbat-gw1ルーターで、プロバイダーBalagan TelecomとFilkin Certificate間の発信トラフィックの配信が設定されます。プロバイダーネットワークFilkin証明書へのトラフィックは、利用可能な場合、それを通過する必要があります。残りの発信トラフィックは、利用可能な場合はプロバイダーBalagan Telecomを介して送信する必要があります。発信トラフィックをチェックするとき、Balagan Telecomを切断すると、データセンター(103.0.0.1)への発信トラフィックはFilkin証明書を通過しないことが判明しました。
デバイス構成他の例については、次のセクションで説明します。===================== タスク#4スキーム:一般的なネットワーク図条件:LinkMiApは両方のプロバイダーからフルビューを受け取ります。件名:トラブルシューティング。プロバイダーから:完全なBGPルートテーブルmsk-arbat-gw1ルーターで、プロバイダーBalagan TelecomとFilkin Certificate間の発信トラフィックの配信が設定されます。プロバイダーネットワークFilkin証明書へのトラフィックは、利用可能な場合、それを通過する必要があります。残りの発信トラフィックは、利用可能な場合はプロバイダーBalagan Telecomを介して送信する必要があります。発信トラフィックをチェックするとき、Balagan Telecomを切断すると、データセンター(103.0.0.1)への発信トラフィックはFilkin証明書を通過しないことが判明しました。構成: neighbor 102.0.0.1 route-map OUTBOUND in no auto-summary ! route-map OUTBOUND permit 10 match as-path 10 set weight 1000 ! ip prefix-list LAN permit 100.0.0.0/23 ! ip as-path access-list 10 permit ^64502$ ! ip route 100.0.0.0 255.255.254.0 Null0
残りの構成は標準です。タスク:設定を修正して、ISP2プロバイダーのネットワークからクライアントおよび会社のリモートオフィスのネットワークへの発信トラフィックがISP2プロバイダーを通過するようにします。サイトでのタスクの詳細======================負荷分散と分散
「そして、BGPでトラフィックのバランスを取る方法を知っていますか?」これは、インタビュー中に人々が尋ねたい質問です。この記事の準備を始めて、私はナターシャと会話しました。それから、BGPのバランスと分散は2つの大きな違いであることが明らかになりました。さらに考えられる分割は条件付きであり、代替の見解が存在します。
負荷分散
バランシングは通常、同じネットワークに向けられたトラフィックの複数のリンク間の分散として理解されます。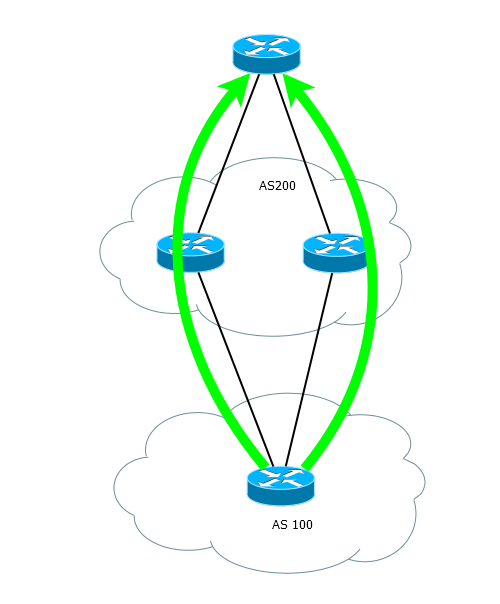 ただオンになります
ただオンになります router bgp 100 maximum-paths 2
次の条件を満たしている必要があります。- このネットワークのBGPテーブルに少なくとも2つのルート。
- 両方のルートは1つのプロバイダーを通過します。
- Weight, Local Preference, AS-Path, Origin, MED, IGP .
- Next Hop .
router bgp 64500 bgp bestpath as-path multipath-relax
AS-path, - .
ネットワークでこれをどのようにテストできますか?バランスが機能することを確認する必要があります。通常、バランシングはストリーム(送信者のIPアドレス/ポートと受信者のIPアドレス/ポート)に基づいているため、パケットは正しい順序で到着します。したがって、2つのスレッドを作成する必要があります。何も簡単であることができなかった:1)直接103.0.0.1でping MSK-アルバート-GW1から2)ソース(スレッド何かを持つ他のルータからのMSK-アルバート-GW1(設定を構成することを忘れないでください)、および実行のpingにTelnetを介して接続されています。互いに異なる)はその後、pingが一方のリンク及び他介して第2通過します。検証済みデフォルトでは、外部チャネルの帯域幅は考慮されません。ただし、このような機会はチームによって実装および開始されます。 router bgp 64500 bgp dmzlink-bw neighbor 101.0.0.1 dmzlink-bw neighbor 102.0.0.1 dmzlink-bw
デバイス構成===================== タスクNo. 5スキーム:一般的なネットワークスキーム条件:LinkMiApは両方のプロバイダーからデフォルトルートを受信します。タスク:プロバイダーBalagan TelecomとFilkin証明書からのデフォルトルート間の発信トラフィックのバランスを3対1の比率で設定します。サイトでのタスクの詳細====================負荷分散
配信のあるまったく異なる曲は、発信トラフィックと着信トラフィックのパスをより細かく調整することです。発信
発信トラフィックは、上から受信したルートに従ってルーティングされます。したがって、それらを管理する必要があります。ネットワークのスキームを思い出してください。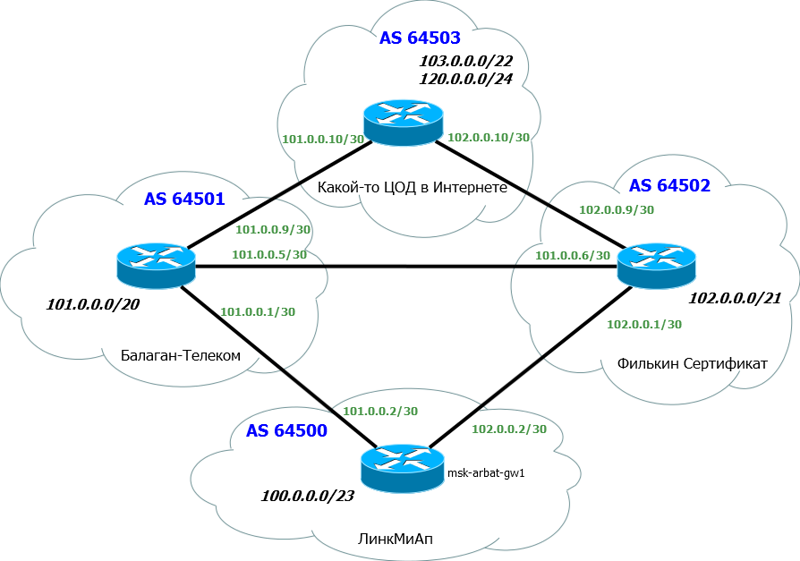 したがって、以下の方法があります:1)重みを設定する。これはtsiskovskyの内部パラメーターであり、どこにも送信されず、ルーター内で機能します。多くの場合、他のベンダーにも類似製品があります(たとえば、HuaweiのPreVal)。具体的なことは何もありません-私たちも止まらないでしょう。(デフォルトは0)近隣から受信したすべてのルートに適用します。
したがって、以下の方法があります:1)重みを設定する。これはtsiskovskyの内部パラメーターであり、どこにも送信されず、ルーター内で機能します。多くの場合、他のベンダーにも類似製品があります(たとえば、HuaweiのPreVal)。具体的なことは何もありません-私たちも止まらないでしょう。(デフォルトは0)近隣から受信したすべてのルートに適用します。 neighbor 192.168.1.1 weight 500
ルートマップ経由のアプリケーション: route-map SET_WEIGHT permit 10 set weight 500 ! router bgp 64500 neighbor 102.0.0.1 route-map SET_WEIGHT in
 2)ローカル設定。このパラメーターは標準です。デフォルトは、すべてのルートで100です。特定のサブネットへのトラフィックを特定のリンクに転送する場合は、ローカルプリファレンスが不可欠です。このパラメーターの使用例については既に検討しました。3)maximum-paths コマンドを使用した上記のバランシング===================== タスク番号6スキーム:一般的なネットワークスキーム条件:LinkMiApは両方のプロバイダーからフルビューを受信します。タスク:重み、ローカルプリファレンス、またはフィルタリング属性を使用せずに、msk-arbat-gw1ルーターを構成して、Balagan Telecomが発信トラフィックのメインルーターになり、Filkin証明書がバックアップされるようにします。サイトでのタスクの詳細=======================
2)ローカル設定。このパラメーターは標準です。デフォルトは、すべてのルートで100です。特定のサブネットへのトラフィックを特定のリンクに転送する場合は、ローカルプリファレンスが不可欠です。このパラメーターの使用例については既に検討しました。3)maximum-paths コマンドを使用した上記のバランシング===================== タスク番号6スキーム:一般的なネットワークスキーム条件:LinkMiApは両方のプロバイダーからフルビューを受信します。タスク:重み、ローカルプリファレンス、またはフィルタリング属性を使用せずに、msk-arbat-gw1ルーターを構成して、Balagan Telecomが発信トラフィックのメインルーターになり、Filkin証明書がバックアップされるようにします。サイトでのタスクの詳細=======================着信
ここではすべてが複雑です。事実、大規模なプロバイダーであっても、発信トラフィックは着信と比較して無視できるほどです。そして、不均一な分布が非常にはっきりと見られます。しかし、データ処理センターまたはホスティングプロバイダーについて話している場合、状況は逆であり、バランスの問題は非常に深刻です。ここでは、手段が非常に制限されています。1)AS-Path Prepend
最もよくあるトリックの1つは、パスを「悪化させる」ことです。 1つのプロバイダーを介して、別のプロバイダーよりも長いASパス長でルートが送信されることがよくあります。もちろん、BGPは最初にカテゴリを選択し、それを介してのみトラフィックが送信されます。ルートを発表するときの状況を均等にするために、AS-Pathに追加の「ホップ」を追加できます。そして、あるプロバイダーが少しのお金でより広いチャネルを提供することがありますが、それを通る経路はより長く、すべてのトラフィックは別のものに行きます-高価で狭い。この状況は私たちにとって不採算であり、狭いチャネルをバックアップにしたいと考えています。ここで分析します。しかし、あなたは完全に退化した状況を取る必要があります。たとえば、Balagan TelecomからLikMiApネットワークへのアクセス。これは、通常の状況でBalagan Telecomプロバイダー上でBGPとルーティングテーブルがどのように見えるか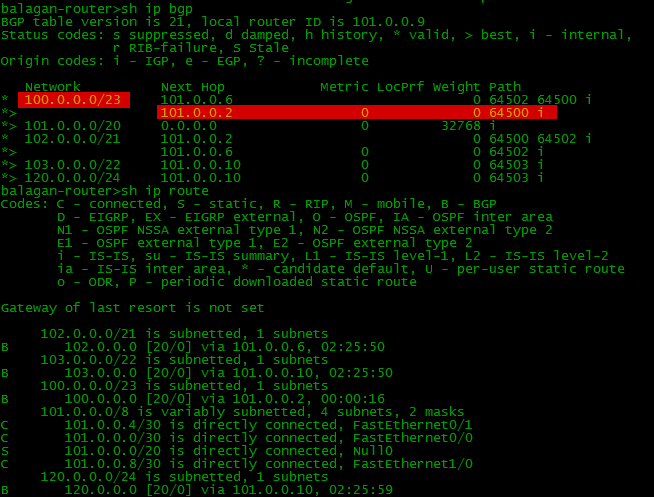 です。メインパス(それらの間の直接リンク)を低下させる場合、AS-ASリストにASを追加する必要があります。
です。メインパス(それらの間の直接リンク)を低下させる場合、AS-ASリストにASを追加する必要があります。 router bgp 64500 neighbor 101.0.0.1 route-map AS_PATH_PREP out route-map AS_PATH_PREP permit 10 set as-path prepend 64500 64500
そして、絵は次のようになります。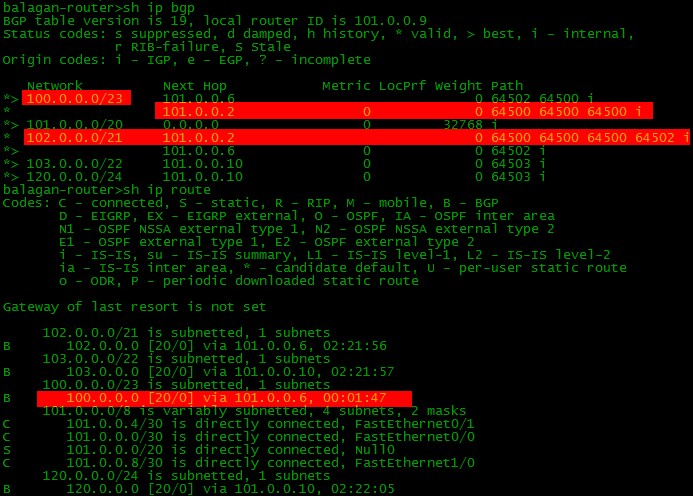 Fil'kin証明書(AS6502)を介して、あること、ASパス短い長さでパスを選択し、当然のことながら、
Fil'kin証明書(AS6502)を介して、あること、ASパス短い長さでパスを選択し、当然のことながら、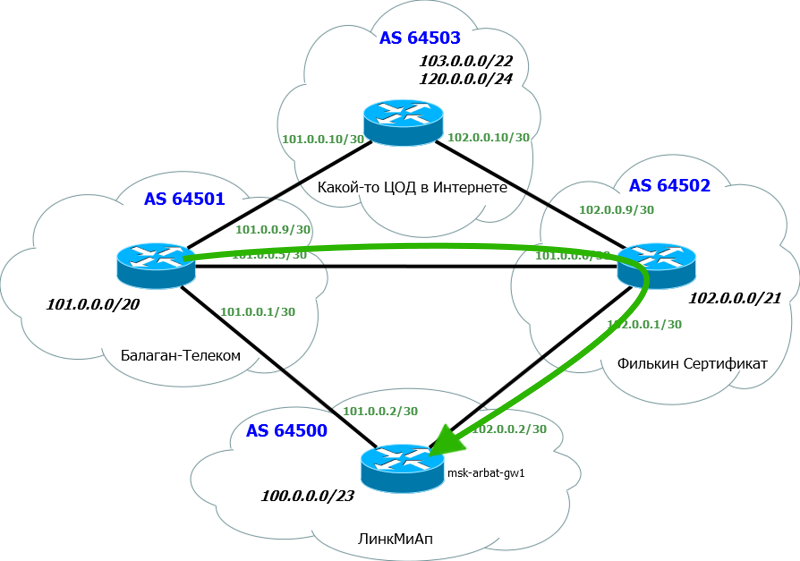 このルートおよびルーティングテーブルに追加されます。通常、AS-Pathでは独自のAS番号を追加することに注意してください。もちろん、他の人のこともできますが、まともな社会では理解されません。したがって、トラフィックが計画したパスに沿っていることを確認しました。当然、チャネルの1つがクラッシュすると、設定されたAS-Path Prependsに関係なく、トラフィックは2番目に切り替わります。デバイス構成。
このルートおよびルーティングテーブルに追加されます。通常、AS-Pathでは独自のAS番号を追加することに注意してください。もちろん、他の人のこともできますが、まともな社会では理解されません。したがって、トラフィックが計画したパスに沿っていることを確認しました。当然、チャネルの1つがクラッシュすると、設定されたAS-Path Prependsに関係なく、トラフィックは2番目に切り替わります。デバイス構成。2)MED
多重出口弁別器。シスコでは、メトリック(AS間メトリック)と呼ばれます。MEDは弱い属性です。弱い。ルートを選択する際に6番目のステップでのみチェックされ、本質的に弱い効果があるため。ローカルプリファレンスが自律システムからのトラフィック出口のパスの選択に影響を与える場合、MEDは隣接ASに転送されるため、トラフィック入力パスに影響します。一般に、MEDとローカルプリファレンスは初心者によって混同されることが多いため、プレートの違いについて説明します。| ローカル設定 | MED |
|---|
| トラフィックを終了するためのパスの優先度を決定します。 | トラフィックエントリのパスの優先度を決定します |
| AS内でのみ有効です。他のASに転送されません | 他のASに送信され、トラフィックを転送することが望ましい方法を介してヒント |
| 別のASに接続すると機能します | 1つのASへの複数の接続でのみ機能します |
| 値が大きいほど、優先度が高くなります。 | 値が高いほど、優先順位は低くなります。 |
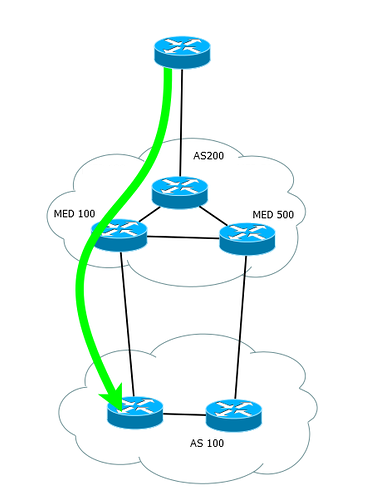 使用することはめったにないので、ここでは説明しません。ネットワークはこれに適していないため、2つのAS間に複数の接続があり、それぞれ1つしかありません。
使用することはめったにないので、ここでは説明しません。ネットワークはこれに適していないため、2つのAS間に複数の接続があり、それぞれ1つしかありません。3)異なるISPを介した異なるプレフィックスのアナウンス
負荷を分散する別の方法は、異なるネットワークを異なるプロバイダーに分散することです。データセンターネットワークでは、アナウンスは次のようになります。 つまり、ネットワーク100.0.0.0/23は2つの方法で知られていますが、ルーティングテーブルに追加されるのは1つだけです。したがって、すべてのトラフィックは1つに戻ります-最良の方法です。
つまり、ネットワーク100.0.0.0/23は2つの方法で知られていますが、ルーティングテーブルに追加されるのは1つだけです。したがって、すべてのトラフィックは1つに戻ります-最良の方法です。しかし!
これを2つのサブネット/ 24に分割し、1つをBalagan Telecomに、もう1つをFilkin Certificateに渡すことができます。したがって、データセンターは異なるパスを介してこれらのサブネットを認識し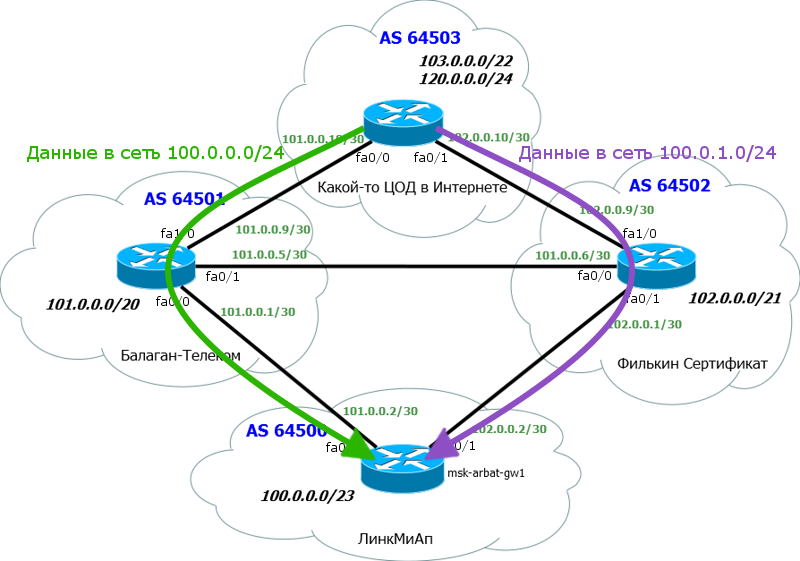 ます。このように構成されます。最初に、すべてのサブネットを規定します。3つすべて:1つの大/ 23と2つの小/ 24:
ます。このように構成されます。最初に、すべてのサブネットを規定します。3つすべて:1つの大/ 23と2つの小/ 24: router bgp 64500 network 100.0.0.0 mask 255.255.254.0 network 100.0.0.0 mask 255.255.255.0 network 100.0.1.0 mask 255.255.255.0
それらをアナウンスするには、これらのサブネットへのルートを作成する必要があります。 ip route 100.0.0.0 255.255.254.0 Null0 ip route 100.0.0.0 255.255.255.0 Null0 ip route 100.0.1.0 255.255.255.0 Null0
そして今、私たちはそれぞれ1つのサブネット/ 24と一般的な/ 23サブネットを許可するプレフィックスリストを作成します。 ip prefix-list LIST_OUT1 seq 5 permit 100.0.0.0/24 ip prefix-list LIST_OUT1 seq 10 permit 100.0.0.0/23 ! ip prefix-list LIST_OUT2 seq 5 permit 100.0.1.0/24 ip prefix-list LIST_OUT2 seq 10 permit 100.0.0.0/23
プレフィックスリストをネイバーにバインドします。 router bgp 64500 neighbor 101.0.0.1 remote-as 64501 neighbor 101.0.0.1 prefix-list LIST_OUT1 out neighbor 102.0.0.1 remote-as 64502 neighbor 102.0.0.1 prefix-list LIST_OUT2 out
外部に送信するルートについて話しているため、それらをOUT-発信に結び付けます。そのため、ネットワーク100.0.0.0/24および100.0.0.0/23をネイバー101.0.0.1(Balagan Telecom)に発表します。そして、ネイバー102.0.0.1(フィルキン証明書)-ネットワーク100.0.1.0/24および100.0.0.0/23。結果は次のようになります。
 バラガンテレコムとFilkin証明書を介して、各ネットワーク/ 24に2つのルートがあるため、間違っているようです。しかし、よく見ると、AS-Pathによる
バラガンテレコムとFilkin証明書を介して、各ネットワーク/ 24に2つのルートがあるため、間違っているようです。しかし、よく見ると、AS-Pathによる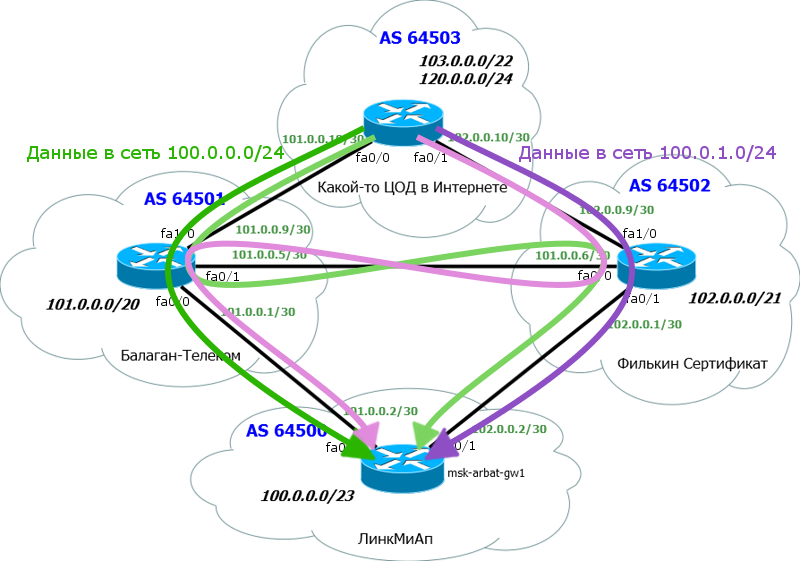 と、そのようなルートがあることがわかります。つまり、実際にはすべてが正しいということです。はい、すべてがルーティングテーブルに正しく収まります。
と、そのようなルートがあることがわかります。つまり、実際にはすべてが正しいということです。はい、すべてがルーティングテーブルに正しく収まります。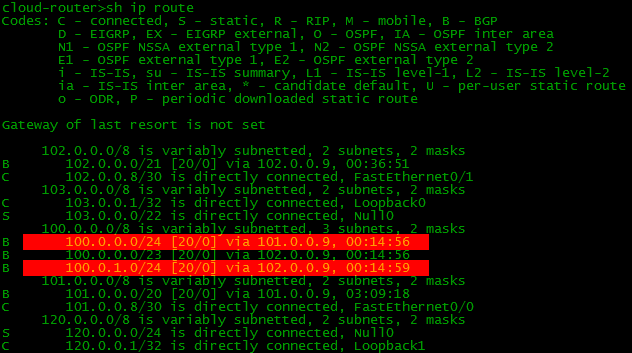 今、大きなサブネット/ 23を自分のためにドラッグしたのはどのような悪魔なのかという質問に答える必要がありますか?実際、最長プレフィックス一致ルールによれば、/ 24がある場合は不要であるかのように、より正確なルート、つまり/ 23が望ましいです。しかし、Balagan Telecomのネットワークが崩壊した状況を想像してください。どうなるの? 100.0.0.0/24サブネットはインターネット上で認識されなくなります-構成のおかげでBalagan Telecomだけが何かについて知っていたからです。したがって、ネットワークの一部も落ちます。
今、大きなサブネット/ 23を自分のためにドラッグしたのはどのような悪魔なのかという質問に答える必要がありますか?実際、最長プレフィックス一致ルールによれば、/ 24がある場合は不要であるかのように、より正確なルート、つまり/ 23が望ましいです。しかし、Balagan Telecomのネットワークが崩壊した状況を想像してください。どうなるの? 100.0.0.0/24サブネットはインターネット上で認識されなくなります-構成のおかげでBalagan Telecomだけが何かについて知っていたからです。したがって、ネットワークの一部も落ちます。しかし!
より一般的なルート100.0.0.0/23で節約できます。Filkin証明書はそれについて知っており、インターネットでそれを発表します。したがって、データセンターはネットワーク100.0.0.0/24を認識しませんが、100.0.0.0 / 23を認識し、Filkin証明書の方向にトラフィックを送ります。 つまり、ライプニッツの栄光、私たちはそのような状況に保険をかけられています。
つまり、ライプニッツの栄光、私たちはそのような状況に保険をかけられています。ルーターの構成に加えて、RIPEデータベースに3つすべてのネットワークを作成する必要があることに注意してください。ネットワーク/ 24とネットワーク/ 23の両方があるはずです。
デバイス構成4)BGPコミュニティ
BGPコミュニティの助けを借りて、プロバイダーにプレフィックスの処理方法、転送先、転送先、設定するローカル設定などを指示できます。コミュニティのトピックを次の号に移すので、このオプションは今は考慮しません。===================== タスク#7スキーム:一般的なネットワーク図条件:msk-arbat-gw1ルーターで、着信および発信トラフィック制御が設定されています。メインプロバイダーはBalagan Telecom、バックアップはFilkin Certificateです。設定を確認すると、発信トラフィックが正しく送信されていることがわかりました。着信トラフィックを確認すると、着信トラフィックはBalagan Telecomプロバイダーを通過しますが、Balagan Telecomが切断されると、着信トラフィックはFilkin証明書を通過しませんでした。タスク:設定を修正します。構成: hostname msk-arbat-gw1 ! interface Loopback0 ip address 100.0.0.1 255.255.255.255 ! interface FastEthernet0/0 description Balagan_Telecom_Internet ip address 101.0.0.2 255.255.255.252 duplex auto speed auto ! interface FastEthernet0/1 description Philkin_Certificate_Internet ip address 102.0.0.2 255.255.255.252 speed 100 full-duplex ! router bgp 64500 no synchronization bgp log-neighbor-changes network 100.0.0.0 mask 255.255.254.0 neighbor 101.0.0.1 remote-as 64501 neighbor 101.0.0.1 prefix-list LAN out neighbor 101.0.0.1 weight 500 neighbor 102.0.0.1 remote-as 64502 neighbor 102.0.0.1 prefix-list LAN out neighbor 102.0.0.1 route-map INBOUND out no auto-summary ! route-map INBOUND permit 10 set as-path prepend 64502 64502 64502 ! ip prefix-list LAN permit 100.0.0.0/23 ! ip route 100.0.0.0 255.255.254.0 Null0
上の問題の詳細についてサイト=====================均衡と負荷分散命令の種類によって、ナターシャSamoylenko -著者xgu.ruは、私たちのためにプレゼンテーションを準備しました。http://www.slideshare.net/NatashaSamoylenko/linkmeup-bgpipsla 帰属表示を使用して、必要に応じてダウンロードして使用できます。PBR
静的ルーティング、動的ルーティング(IGPまたはEGP)のいずれであっても、記事でこれまで使用していたすべてのルーティングテクノロジーは、パケットの1つの兆候のみを考慮しました:宛先アドレス。単純に、彼らはすべて同じ原則に基づいて行動しました。彼らはパケットがどこに向かっているのかを見て、ルーティングテーブルで宛先への最も具体的なルート(最長一致)を見つけ、このルートの反対側のテーブルに書き込まれたインターフェイスにパケットを転送しました。これは一般に、ルーティングの本質です。しかし、この順序が私たちに合わない場合はどうでしょうか?送信元アドレスに基づいてパケットをルーティングする場合はどうなりますか?または、右側にHTTP ボーイ、左側にSNMP ガールが必要ですか?この状況では、PBR(ポリシーベースルーティング)というポリシーに基づくルーティングが役立ちます。このテクノロジーにより、パッケージの次の機能に基づいてトラフィックを管理できます。- 送信元アドレス(または送信元アドレスと受信者アドレスの組み合わせ)
- OSIレベル7(アプリケーション)情報
- パケットが来たインターフェース
- QoSタグ
- 一般的に、拡張ACLで使用される情報(送信元\宛先ポート、プロトコルなど、任意の組み合わせ)。 つまり 拡張ACLを使用して関心のあるトラフィックを分離できる場合は、必要に応じてルーティングできます。
PBRを使用する利点は明らかです。ルーティングの信じられないほどの柔軟性です。しかし、短所もあります:- すべてを手で書く必要があるため、多くの作業とエラーのリスク
- パフォーマンス。 ほとんどの腺では、PBRは通常のルーティングよりも低速です(例外はCatalys 6500です。鉄PBRをサポートするスーパーバイザーがいます)
PBRの実装に基づくポリシーは、ルートマップPOLICY_NAMEコマンドによって作成され、2つのセクションが含まれます。- 必要なトラフィックの割り当て。ACLを使用するか、トラフィックが到着したインターフェイスに応じて実行されます。matchコマンドは、ルートマップコンフィギュレーションモードでこれを担当します。
- このトラフィックにアクションを適用します。これはsetコマンドが担当します。
修正のための少しの練習:このトポロジーがあります: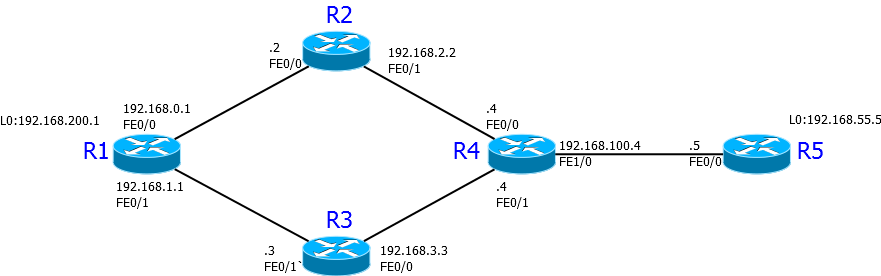 現時点では、トラフィックR1-R5およびバックはルートR1-R2-R4-R5に沿って進み、便宜上、アドレスの最後の桁がルーター番号になるようにアドレスが割り当てられます。
現時点では、トラフィックR1-R5およびバックはルートR1-R2-R4-R5に沿って進み、便宜上、アドレスの最後の桁がルーター番号になるようにアドレスが割り当てられます。R1#traceroute 192.168.100.5
1 192.168.0.2 20ミリ秒36ミリ秒20ミリ秒
2 192.168.2.4 40ミリ秒44ミリ秒16ミリ秒
3 192.168.100.5 56ミリ秒* 84ミリ秒
R5#traceroute 192.168.0.1
1 192.168.100.4 56ミリ秒40ミリ秒8ミリ秒
2 192.168.2.2 20ミリ秒24ミリ秒16ミリ秒
3 192.168.0.1 64ミリ秒* 84ミリ秒
たとえば、ルートR5-R4- R3 -R1に沿って移動するために、R5からのトラフィック(送信元アドレスを含む)が必要であるとします。スキームによれば、R4がこれを決定する必要があることは明らかです。その上で、まず必要なパッケージを選択するACLを作成します。 R4(config)#access-list 100 permit ip host 192.168.100.5 any
次に、「BACK」という名前のルーティングポリシーを作成します。 R4(config)#route-map BACK
その中に、私たちが興味を持っているトラフィックを示します R4(config-route-map)#match ip address 100
そしてそれをどうするか: R4(config-route-map)#set ip next-hop 192.168.3.3
次に、R5の方を向くインターフェイスに移動します(PBRは着信トラフィックで機能します!)そして受信したポリシーを適用します: R4(config)#int fa1/0 R4(config-if)#ip policy route-map BACK
私たちはチェックします:R5#traceroute 192.168.0.1
1 192.168.100.4 40ミリ秒40ミリ秒16ミリ秒
2 192.168.3.3 52ミリ秒52ミリ秒44ミリ秒
3 192.168.1.1 56ミリ秒* 68ミリ秒
うまくいく!
さて、ダイアグラムを注意深く見て、考えてみましょう:すべては大丈夫ですか?そしていや!このACLに従って、R5ソースを持つすべてのトラフィックはR3でラップされます。これは、たとえば、R5が短く明白なルートR5-R4-R2ではなくR2に乗りたい場合、ルートR5-R4-R3-R1-R2に沿って送信されることを意味します。したがって、PBRのACLを非常に慎重かつ思慮深くコンパイルし、できるだけ具体的にする必要があります。この例では、トラフィックに適用されるアクションとして、nextop(ホスト、パケットがさらに進む場所)を再定義することを選択しました。PBRで他に何ができますか?次のコマンドを使用できます。- ip next-hopを設定します
- インターフェイスを設定する
- ip default next-hopを設定します
- デフォルトのインターフェースを設定する
最初の2つでは、すべてが比較的明確です-それらは、ネックストップとパケットが出るインターフェイスを再定義します(ほとんどの場合、設定されたインターフェイスはポイントツーポイントリンクに使用されます)。また、set ip default next-hopまたはset default interface コマンドを使用する場合、ルーターは最初にルーティングテーブルを調べ、チェック対象のパケットのルートがある場合、それに応じてテーブルに送信します。ルートがない場合、ポリシーに記載されているように、パケットが送信されます。たとえば、トポロジでset ip next-hop 192.168.3.3の代わりにset ip default next-hop 192.168.3.3を注文した場合、R4にはR1へのルートがあるため(R2経由)、何も変更されません。しかし、存在しない場合、トラフィックはR3に送られます。, set : QoS MPLS BGP
====================== タスク番号8条件:LinkMiApは、プロバイダー(BGPではない)への静的ルートを使用します。スキームと構成。プロバイダールーターもBGPを使用しません。タスク:プロバイダー間の切り替えを構成します。google ping(103.0.0.10)またはyandex(103.0.0.20)へのicmp応答が到着する限り、Balagan Telecomへのデフォルトルートを使用する必要があります。リクエストは、Balagan Telecom経由で送信する必要があります。指定されたリソースのいずれも応答しない場合、デフォルトルートはFilkin証明書プロバイダーに切り替える必要があります。個々のicmp応答の一時的な損失による切り替えを防ぐために、切り替え遅延を少なくとも5秒に設定する必要があります。タスクの詳細ここ======================IP SLA
そして今、最もおいしい:私たちのスキームでは、メインパスR4-R2-R1が1つのプロバイダーによって提供され、スペアのR4-R3-R1が別のプロバイダーによって提供されることを想像してみましょう。場合によっては、最初のプロバイダーの負荷の問題により、音声トラフィックが低下し始めることがあります。同時に、別のルートがアンロードされ、この時点で音声を転送するのが良いでしょう。さて、上記で行ったように、ルートマップを作成します。これは、音声トラフィックを割り当て、通常動作するプロバイダーを介して送信します。そして、ここで-op、状況は逆転しました-再び、すべてを元に戻す必要があります。平日のテクニカルサポート:「そして、一日中このようなゴミ:アザラシが呼び出し、次に鹿が呼び出します」。ただし、必要なメインチャネルの特性(たとえば、遅延やジッター)を追跡できれば、それはクールであり、その値に応じて、プライマリまたはバックアップチャネルに音声またはビデオを自動的に送信しますか?それで、奇跡が起こります。この場合、奇跡はIP SLAと呼ばれます。この技術は、実際には、アクティブなネットワーク監視です。特定のネットワーク特性を評価するためのトラフィックの生成。しかし、監視はそこで終わりではありません。ルーターは、受信したデータを使用して、ルーティングに関する意思決定に影響を与え、問題に反応して解決することができます。たとえば、ビジーなチャネルをアンロードし、負荷を他のユーザーに分散します。さらに苦労せずに、すぐに設定に。まず、監視したいことを言う必要があります。監視オブジェクトを作成し、それに番号を割り当てます。 R4(config)#ip sla 1
それでは、ここで何を監視できますか?R4(config-ip-sla)#?
IP SLAs entry configuration commands:
dhcp DHCP Operation
dns DNS Query Operation
exit Exit Operation Configuration
frame-relay Frame-relay Operation
ftp FTP Operation
http HTTP Operation
icmp-echo ICMP Echo Operation
icmp-jitter ICMP Jitter Operation
mpls MPLS Operation
path-echo Path Discovered ICMP Echo Operation
path-jitter Path Discovered ICMP Jitter Operation
slm SLM Operation
tcp-connect TCP Connect Operation
udp-echo UDP Echo Operation
udp-jitter UDP Jitter Operation
voip Voice Over IP Operation
, , IP SLA, : IOS 12.4(4)T , , . , ip sla 1 rtr 1 ip sla responder – rtr responder
ご覧のとおり、このリストは印象的です。興味がある人はtsisko.comに詳細な記事があります。====================== タスクNo. 9条件:LinkMiApはプロバイダー(BGPではない)への静的ルートを使用します。スキームと構成。プロバイダールーターもBGPを使用しません。タスク:ローカルネットワーク10.0.1.0からのHTTPトラフィックがBalagan Telecomを通過し、ネットワーク10.0.2.0からのすべてのトラフィックがFilkin証明書を通過するようにルーティングを構成します。送信者のアドレスに他のアドレスが含まれている場合、トラフィックは破棄され、標準のルーティングテーブルに従ってルーティングされません(インターフェースに適用されたACLを使用してフィルタリングなしでタスクを完了する必要があります)。追加条件:PBRルールは、適切なプロバイダーが使用可能な場合にのみ機能する必要があります(このタスクでは、最も近いプロバイダーデバイスの可用性を確認するだけで十分です)。それ以外の場合は、標準のルーティングテーブルを使用する必要があります。タスクの詳細はこちら======================通常、IP SLAの動作は、最も単純なicmp-echoの例を使用して考慮されます。つまり、行の終わりにpingできる場合、トラフィックはそれを通過しますが、できなければ-もう一方に沿って通過します。しかし、もう少し複雑な方法で進めます。したがって、ジッタなど、音声トラフィックにとって重要なチャネル特性に関心があります。より具体的には、udp-jitter、したがって、 R4(config-ip-sla)#udp-jitter 192.168.200.1 55555
このコマンドでは、検証のタイプ(udp-jitter)を指定した後、サンプルの送信先IPアドレスが送信されます(つまり、私たちから192.168.200.1までを測定します-これはR1へのループバックです)およびポート(箇条書き55555から)です。次に、チェックの頻度を設定できます(デフォルトは60秒です)。 R4(config-ip-sla-jitter)#frequency 10
制限値を超えると、ip sla 1オブジェクトは使用不可について報告します。 R4(config-ip-sla-jitter)#threshold 10
IP SLAの一部のタイプの測定では、反対側にいわゆる「レスポンダー」の存在が必要ですが、一部のタイプ(FTP、HTTP、DHCP、DNSなど)は必要ありません。私たちのUDPジッタは、あなたが測定を開始する前に、あなたはR1を準備する必要があり、必要があります。 R1(config)#ip sla responder
次に、統計の収集を開始する必要があります。命じる R4(config)#ip sla schedule 1 start-time now life forever
つまり
すぐにオブジェクト1の監視を開始し、数日が終わるまで監視します。統計収集が開始されている場合、オブジェクトパラメータを変更することはできません。 つまりたとえば、サンプルの頻度を変更するには、まず情報の収集をオフにする必要があります:no ip sla schedule 1
これで何が起こっているのかがわかります。R4#sh ip sla statistics 1
Round Trip Time (RTT) for Index 1
Latest RTT: 36 milliseconds
Latest operation start time: *00:39:01.531 UTC Fri Mar 1 2002
Latest operation return code: OK
RTT Values:
Number Of RTT: 10 RTT Min/Avg/Max: 19/36/52 milliseconds
Latency one-way time:
Number of Latency one-way Samples: 0
Source to Destination Latency one way Min/Avg/Max: 0/0/0 milliseconds
Destination to Source Latency one way Min/Avg/Max: 0/0/0 milliseconds
Jitter Time:
Number of SD Jitter Samples: 9
Number of DS Jitter Samples: 9
Source to Destination Jitter Min/Avg/Max: 0/5/20 milliseconds
宛先からソースへのジッター最小/平均/最大:0/16/28ミリ秒
パケット損失値:
損失ソースから宛先:0損失宛先からソース:0
シーケンス外:0テールドロップ:0
パケット遅延到着:0パケットスキップ:0
音声スコア値:
計算された計画障害係数(ICPIF):0
平均オピニオンスコア(MOS):0
成功
数:12 失敗数:0
稼働時間:永遠
そこに設定したものと同様にR4#sh ip sla conf
IP SLAs Infrastructure Engine-II
Entry number: 1
Owner:
Tag:
Type of operation to perform: udp-jitter
Target address/Source address: 192.168.200.1/0.0.0.0
Target port/Source port: 55555/0
Request size (ARR data portion): 32
Operation timeout (milliseconds): 5000
Packet Interval (milliseconds)/Number of packets: 20/10
Type Of Service parameters: 0x0
Verify data: No
Vrf Name:
Control Packets: enabled
Schedule:
Operation frequency (seconds): 10 (not considered if randomly scheduled)
Next Scheduled Start Time: Pending trigger
Group Scheduled: FALSE
Randomly Scheduled: FALSE
Life (seconds): 3600
Entry Ageout (seconds): never
Recurring (Starting Everyday): FALSE
Status of entry (SNMP RowStatus): Active
Threshold (milliseconds): 10
Distribution Statistics:
Number of statistic hours kept: 2
Number of statistic distribution buckets kept: 1
Statistic distribution interval (milliseconds): 4294967295
Enhanced History:
次に、いわゆるトラックを設定します(正しくないが、理解できる翻訳「トラッカー」)。その後、ルートマップのアクションが添付されます。トラックでは、状態の切り替えの遅延を設定できます。これにより、1つの失敗したサンプルのルーティングを変更し、次の既に成功したサンプルのルーティングを変更するときの問題を解決できます。トラック番号と、接続するip slaオブジェクトの番号(rtr 1)を示します。 R4(config)#track 1 rtr 1
遅延を調整します。 R4(config-track)#delay up 10 down 15
つまり、監視オブジェクトが落下して15秒以内に上昇しなかった場合、トラックをdownに設定します。オブジェクトがダウン状態であったが、上昇し、少なくとも10秒間上昇状態であった場合、トラックをアップ状態にします。次のステップは、トラックをルートマップにバインドすることです。私はR1にR5から標準的な方法は、R2を通過、あなたを思い出させるしましょう、しかし、我々はロス-MAPAを持っBACK、デフォルトの状況を再割り当て、R5のソースの場合:R4#sh run | sec route-map
ip policy route-map BACK
route-map BACK permit 10
match ip address 100
set ip next-hop 192.168.3.3
監視をこのマップに関連付け、set ip next-hop 192.168.3.3コマンドをset ip next-hop verify-availability 192.168.3.3 10 track 1に置き換えると、逆の効果が得られます:トラックドロップの場合(インジケーターを超えたため) sla 1のジッター)、マップは動作しません(すべてがルーティングテーブルに従って移動します)、およびその逆、通常の値の場合、トラックはアップし、トラフィックはR3を通過します。仕組み:ルーターは、パケットが一致条件を満たしていることを確認しますが、PBRの前の例のようにすぐに設定されず、中間アクションで最初にトラック1の状態をチェックし、その後、設定されている場合は設定済みですそうでない場合は、ルートマップの次の行に移動します。マップが正常に機能するためには、何らかの方法でトラックの値を反転させる必要があります。ジッタが大きい場合、トラックはUPである必要があります。これは、トラックリストなどの処理に役立ちます。IP SLAでは、トラック内の他のトラックのリスト(本質的に1または0を出力)を組み合わせて、それらに対して論理演算ORまたはANDを実行できます。これらの演算の結果は、このトラックの状態になります。さらに、トラックの状態に論理否定を適用できます。トラックリストを作成します。 R4(config)#track 2 list boolean or
この「リスト」の唯一のものは、トラック1の値の論理否定です。 R4(config-track)#object 1 not
ルートマップをこのトラックにバインドします R4(config)#route-map BACK R4(config-route-map)#no set ip next-hop 192.168.3.3 R4(config-route-map)#set ip next-hop verify-availability 192.168.3.3 10 tr 2
neksthopアドレスの後の10は、そのシーケンス番号です。たとえば、次のように使用できます。 route-map BACK permit 10 match ip address 100 set ip next-hop verify-availability 192.168.3.3 <b>10</b> track 1 set ip next-hop verify-availability 192.168.2.2 <b>20</b> track 2
ロジックは次のとおりです。ACL100に該当するトラフィックを選択し、トラック1の中間チェックがあり、アップしている場合はパケットを192.168.3.3 neksthopに設定し、ダウンしている場合は次のシリアル番号(この場合は20)に行き、再び中間のステータスをチェックしますトラック(すでに異なります、2)、結果に応じて、nextop 192.168.2.2を設定するか、平和的に送信します(一般的なルーティング)。ここで、間違っていることを言葉で少し説明しましょう。そのため、R2を通るルートに沿って、ソースR4からレスポンダーR1までのジッターを測定します。このルートの最大許容ジッター値は10です。ジッターがこの値を超え、15秒間このレベルのままである場合、R5によって生成されたトラフィックをR3を介してルートに切り替えます。ジッタが10を下回り、少なくとも10秒間そこに留まる場合、R5から標準ルートに沿ってトラフィックを開始します。マテリアルを統合するには、これらのすべての値が設定されているコマンドを見つけてください。そのため、目標を達成しました。メインチャネルの品質が低下した場合(少なくとも、udp-jitterの値)、バックアップチャネルに切り替えます。しかし、あまりない場合はどうですか?この問題を解決するためにIP SLAを使用してみてください。やりたいことのロジックを構築してみましょう。バックアップチャネルに切り替える前に、ジッタをどのように処理しているかを確認します。これを行うには、追加の監視オブジェクトを取得する必要があります。これは、パスR4-R3-R1のジッターを考慮し、2とします。同じ値を使用して、最初のオブジェクトと同様にします。バックアップチャネルに条件を切り替えると、その後、次のようになります。オブジェクトダウン1 とオブジェクト2アップ。メインチャネルの外側のジッタを測定するには、R1およびR4でループバックインターフェイスを作成し、R3ラウンドトリップを介して静的ルートを登録し、SLA 2オブジェクトにこれらのアドレスを使用するというトリックを行う必要があります。 R1(config)#int lo1 R1(config-if)#ip add 192.168.30.1 255.255.255.0 R1(config-if)#exit R1(config)#ip route 192.168.31.0 255.255.255.0 192.168.1.3 R3(config)#ip route 192.168.30.0 255.255.255.0 192.168.1.1 R3(config)#ip route 192.168.31.0 255.255.255.0 192.168.3.4 R4(config)#int lo0 R4(config-if)#ip add 192.168.31.4 255.255.255.0 R4(config-ip-sla-jitter)#exit R4(config)#ip sla 2 R4(config-ip-sla)#udp-jitter 192.168.30.1 55555 source-ip 192.168.31.4 R4(config-ip-sla-jitter)#threshold 10 R4(config-ip-sla-jitter)#frequency 10 R4(config-ip-sla-jitter)#exit R4(config)#ip route 192.168.30.0 255.255.255.0 192.168.3.3 R4(config)#ip sla schedule 2 start-time now life forever R4(config)#track 3 rtr 2
次に、ルートマップがアタッチされるトラック2の条件を変更します。 R4(config)#track 2 list boolean and R4(config-track)#object 1 not R4(config-track)#object 3
これで、トラフィックR5-> R1は、メインチャネルのジッタが10を超え、同時にバックアップチャネルのジッタが10未満の場合にのみフォールバックルートに切り替わります。両方のチャネルで高いジッタが観察される場合、トラフィックはメインに沿って進みますそして静かに苦しむ。トラックステータスは静的ルートにリンクすることもできます。たとえば、ip route 0.0.0.0 0.0.0.0 192.168.1.1 track 1コマンドを使用して、デフォルトゲートウェイ192.168.1.1を作成し、これをトラック1に接続します(これにより、確認できます)。ネットワーク上にこれと同じ192.168.1.1が存在するか、それとの通信品質の重要な特性を測定します)。リンクされたトラックが落ちた場合、ルートはルーティングテーブルから削除されます。また、IP SLAを介して受信した情報をSNMPを介して引き出して、監視システムのどこかに保存および分析できるようにすることも重要です。SNMPトラップを 構成することもできます。====================== タスク番号10スキーム:他のPBRタスクと同様。以下の設定。条件:LinkMiApは、プロバイダー(BGPではない)への静的ルートを使用します。PBRはmsk-arbat-gw1ルーターで構成されます。HTTPトラフィックはFilkin証明書プロバイダーを通過する必要があり、10.0.2.0ネットワークからのトラフィックはBalagan Telecomを通過する必要があります。指定されたトラフィックは正しく送信されますが、Balagan Telecomプロバイダーを介して送信する必要があるローカルネットワークからの残りのトラフィックはルーティングされません。タスク:条件を満たすように設定を修正します。構成: hostname msk-arbat-gw1 interface Loopback1 ip address 10.0.1.1 255.255.255.0 ip nat inside ! interface Loopback2 ip address 10.0.2.1 255.255.255.0 ip nat inside ! interface FastEthernet0/0 description Balagan_Telecom_Internet ip address 101.0.0.2 255.255.255.252 ip nat outside duplex auto speed auto ! interface FastEthernet0/1 description Philkin_Certificate_Internet ip address 102.0.0.2 255.255.255.252 ip nat outside speed 100 full-duplex ! ! ip access-list extended LAN permit ip 10.0.1.0 0.0.0.255 any permit ip 10.0.2.0 0.0.0.255 any ! route-map BALAGAN permit 10 match ip address LAN match interface FastEthernet0/0 route-map PH_CERT permit 10 match ip address LAN match interface FastEthernet0/1 ! ip nat inside source route-map BALAGAN interface Fa0/0 overload ip nat inside source route-map PH_CERT interface Fa0/1 overload ! ip access-list extended HTTP permit tcp any any eq 80 ! ip access-list extended LAN2 permit ip 10.0.2.0 0.0.0.255 any ! route-map PBR permit 10 match ip address HTTP set ip next-hop 102.0.0.1 route-map PBR permit 20 match ip address LAN2 set ip next-hop 101.0.0.1 ! ip local policy route-map PBR
ここ でのタスクの詳細======================便利なリンク
BGP
IP SLA
eucariot thegluck 。
助けてくれてありがとう、JDima。タスクは、比類のないナターシャ・サモイレンコによって私たちに書かれました。「最小のネットワーク」というサイクルには、独自のWebサイトlinkmeup.ruがあり、すべての問題をきちんと折りたたんで思慮深い読書の準備ができています。