
こんにちは この投稿では、
Laplace blur を使用した単純
なベイジアン分類器を
使用した単純なスパムフィルタリングモデルを見て、
Rに数行のコードを記述
し 、最後に英語の
SMSスパムデータベースでテストし
ます 。 一般に、ハブでこのトピックに関する記事が2つ見つかりましたが、コードをダウンロードして結果を確認できる良い例はありませんでした。 また、複雑なテキストの前処理などとは異なり、多くの労力をかけずにモデルの品質を大幅に向上させるぼかしについては言及されていません。 しかし、一般的に、Rコードの例を使用して学生向けのトレーニングマニュアルを書いていたため、私は素朴なベイに関する別の投稿をカットするように促されたので、情報を共有することにしました。
単純ベイズ分類器
いくつかのオブジェクトのセット
D = {dq、d2、...、dm}を考えます。それぞれのオブジェクトは、すべての記号のセット
F = {f1、f2、...、fq}からの記号のセットと、ラベルのセットからの1つのラベルを持っています。
C = {c1、c2、...、cr} 。 私たちのタスクは、属性のセット
Fd = {fd1、fd2、...、fdn}に基づいて、着信オブジェクトdの最も可能性の高いクラス/ラベルを計算することです。 言い換えれば、事後最大(
事後確率の最大値 、MAP)が達成される
確率変数
Cの値を計算する必要があります。

- 2.1-実際、これは私たちの目標です
- 2.2-ベイズの定理による分解
- 2.3-尤度関数を最大化する引数を探していること、および分母がこの引数から独立しており、この場合は定数であることを考慮すると、合計確率P(d)の値を安全に無視できます。
- 2.4- x> 0で対数が単調に増加するため、関数f(x)の最大値はln(f(x))の最大値と同じになります。 これは、将来、プログラミング中にゼロに近い数で動作しないようにするために必要です。
単純ベイズ分類器モデルは、2つの仮定を受け入れます。
- オブジェクトの記号の順序は重要ではありません。
- このクラスでは、サインの確率は互いに依存しません。
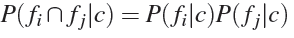 。
。
上記の仮定を前提に、式の導出を続けます。

- 2.6-2.7-これは単なる仮定の適用の結果です
- 2.8-ここでは、まさに、対数の顕著な特性が適用されます。これにより、非常に小さな値で動作するときに精度の損失を回避できます
次のよう
に、単純なベイズ分類器の
グラフィックモデルを描くことができます。

スパム分類器
次に、より一般的な分類タスクから、スパム分類の特定のタスクに飛び込みます。 したがって、セット
DはSMSメッセージで構成されます。 各メッセージは
C = {ham、spam}のセットからタグ付けされ
ます 。 標識の概念を定式化するために
、単語の表現モデルの
バッグを使用します。これを例で示します。 データベースに2つのハムSMSメッセージしかないとしましょう
hi how are youhow old are youその後、テーブルを作成できます
| 言葉 | 頻度 |
|---|
| こんにちは | 1 |
| どうやって | 2 |
| は | 2 |
| あなたは | 2 |
| 老人 | 1 |
非スパムメッセージの本文には8つの単語しかないため、正規化後、
最尤推定を使用して単語の事後確率を取得します。 たとえば、メッセージがスパムではない場合、単語「how」の確率は次のようになります。
P(fi = "方法" | C =ハム)= 2/8 = 1/4または、このメソッドを一般的な形式で記述できます。
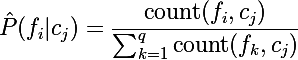
ここで、qは辞書内の一意の単語の総数です。
ラプラスブラー
この時点で、次の問題に注意を払うときです。 2つのハムメッセージのデータベースを思い出して、メッセージが分類に来たとしましょう: "
こんにちは仲間 "と、たとえば、非スパム
P(ハム)= 1/2のアプリオリ確率。 単語の確率を計算します。
- P( "こんにちは" |ハム)= 1/8
- P( "bro" |ハム)= 0/8 = 0
式2.8を思い出して、
c = hamで
argmaxの下の式を計算します
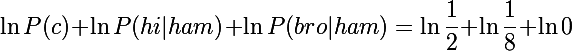
明らかに、エラーまたは負の無限大を取得します。 ゼロの対数は存在しません。 対数を使用しなかった場合、単に0を取得します。 このメッセージの確率はゼロになりますが、これは原則として私たちにとって非常に有益です。
これを回避するために、
ラプラスによるブラーリングまたはk加法平滑化が可能です-この方法では、カテゴリーデータの確率を計算するときにブラーリングが可能になります。 この場合、次のようになります。
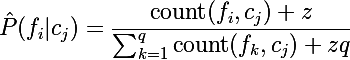
ここで、z> = 0はぼかし係数、qはランダム変数が取ることができる値の数です。この場合、クラス内の単語の数です。 qは、モデルの指導に使用された単語の総数です。
たとえば、ハムとスパムメッセージを読むと、10個の一意の単語が見つかり、
P( "hi" | ham)=(1 + 1)/(8 + 1 * 10)= 2/18 = 1/9 、ぼかし係数z = 1.ゼロの確率は次のようになります:
P( "bro" | ham)=(0 + 1)/(8 + 1 * 10)= 1/18 。
ベイジアンの観点から、この方法は事後分布の数学的期待に対応し、パラメーターzでパラメーター化された
ディリクレ分布をアプリオリ分布として使用します。
実験とコード
カンピナス大学の Webサイトからダウンロードしたデータベースを使用します。このデータベースには、4827の通常のSMSメッセージ(ハム)と747のスパムメッセージが含まれています。
ステミングなどの深刻なテキストの前処理は行いませんでした。いくつかの簡単な操作だけを行いました。
- テキストを小文字に縮小
- すべての句読点を削除しました
- すべての数値シーケンスを1つに置き換えました
前処理コード PreprocessSentence <- function(s) { # Cut and make some preprocessing with input sentence words <- strsplit(gsub(pattern="[[:digit:]]+", replacement="1", x=tolower(s)), '[[:punct:][:blank:]]+') return(words) } LoadData <- function(fileName = "./Data/Spam/SMSSpamCollection") { # Read data from text file and makes simple preprocessing: # to lower case -> replace all digit strings with 1 -> split with punctuation and blank characters con <- file(fileName,"rt") lines <- readLines(con) close(con) df <- data.frame(lab = rep(NA, length(lines)), data = rep(NA, length(lines))) for(i in 1:length(lines)) { tmp <- unlist(strsplit(lines[i], '\t', fixed = T)) df$lab[i] <- tmp[1] df$data[i] <- PreprocessSentence(tmp[2]) } return(df) }
次の関数は、適切な比率でデータ配列のパーティションを作成し、それにより、トレーニング、検証、およびテストデータセットのインデックスを生成します。
分離設定日 CreateDataSet <- function(dataSet, proportions = c(0.6, 0.2, 0.2)) { # Creates a list with indices of train, validation and test sets proportions <- proportions/sum(proportions) hamIdx <- which(df$lab == "ham") nham <- length(hamIdx) spamIdx <- which(df$lab == "spam") nspam <- length(spamIdx) hamTrainIdx <- sample(hamIdx, floor(proportions[1]*nham)) hamIdx <- setdiff(hamIdx, hamTrainIdx) spamTrainIdx <- sample(spamIdx, floor(proportions[1]*nspam)) spamIdx <- setdiff(spamIdx, spamTrainIdx) hamValidationIdx <- sample(hamIdx, floor(proportions[2]*nham)) hamIdx <- setdiff(hamIdx, hamValidationIdx) spamValidationIdx <- sample(spamIdx, floor(proportions[2]*nspam)) spamIdx <- setdiff(spamIdx, spamValidationIdx) ds <- list( train = sample(union(hamTrainIdx, spamTrainIdx)), validation = sample(union(hamValidationIdx, spamValidationIdx)), test = sample(union(hamIdx, spamIdx)) ) return(ds) }
次に、入力データ配列に基づいてモデルが作成されます。
モデル作成 CreateModel <- function(data, laplaceFactor = 0) { # creates naive bayes spam classifier based on data m <- list(laplaceFactor = laplaceFactor) m[["total"]] <- length(data$lab) m[["ham"]] <- list() m[["spam"]] <- list() m[["hamLabelCount"]] <- sum(data$lab == "ham") m[["spamLabelCount"]] <- sum(data$lab == "spam") m[["hamWordCount"]] <- 0 m[["spamWordCount"]] <- 0 uniqueWordSet <- c() for(i in 1:length(data$lab)) { sentence <- unlist(data$data[i]) uniqueWordSet <- union(uniqueWordSet, sentence) for(j in 1:length(sentence)) { if(data$lab[i] == "ham") { if(is.null(m$ham[[sentence[j]]])) { m$ham[[sentence[j]]] <- 1 } else { m$ham[[sentence[j]]] <- m$ham[[sentence[j]]] + 1 } m[["hamWordCount"]] <- m[["hamWordCount"]] + 1 } else if(data$lab[i] == "spam") { if(is.null(m$spam[[sentence[j]]])) { m$spam[[sentence[j]]] <- 1 } else { m$spam[[sentence[j]]] <- m$spam[[sentence[j]]] + 1 } m[["spamWordCount"]] <- m[["spamWordCount"]] + 1 } } } m[["uniqueWordCount"]] <- length(uniqueWordSet) return(m) }
モデルに関する最後の関数は、訓練されたモデルを使用して着信メッセージを分類します。
ポスト分類 ClassifySentense <- function(s, model, preprocess = T) { # calculate class of the input sentence based on the model GetCount <- function(w, ls) { if(is.null(ls[[w]])) { return(0) } return(ls[[w]]) } words <- unlist(s) if(preprocess) { words <- unlist(PreprocessSentence(s)) } ham <- log(model$hamLabelCount/(model$hamLabelCount + model$spamLabelCount)) spam <- log(model$spamLabelCount/(model$hamLabelCount + model$spamLabelCount)) for(i in 1:length(words)) { ham <- ham + log((GetCount(words[i], model$ham) + model$laplaceFactor) /(model$hamWordCount + model$laplaceFactor*model$uniqueWordCount)) spam <- spam + log((GetCount(words[i], model$spam) + model$laplaceFactor) /(model$spamWordCount + model$laplaceFactor*model$uniqueWordCount)) } if(ham >= spam) { return("ham") } return("spam") }
セットでモデルをテストするには、次の関数を使用します。
モデルテスト TestModel <- function(data, model) { # calculate percentage of errors errors <- 0 for(i in 1:length(data$lab)) { predictedLabel <- ClassifySentense(data$data[i], model, preprocess = F) if(predictedLabel != data$lab[i]) { errors <- errors + 1 } } return(errors/length(data$lab)) }
最適なぼかし係数を検索するには、対応するセットで
交差検証が使用されます。
相互検証モデル CrossValidation <- function(trainData, validationData, laplaceFactorValues, showLog = F) { cvErrors <- rep(NA, length(laplaceFactorValues)) for(i in 1:length(laplaceFactorValues)) { model <- CreateModel(trainData, laplaceFactorValues[i]) cvErrors[i] <- TestModel(validationData, model) if(showLog) { print(paste(laplaceFactorValues[i], ": error is ", cvErrors[i], sep="")) } } return(cvErrors) }
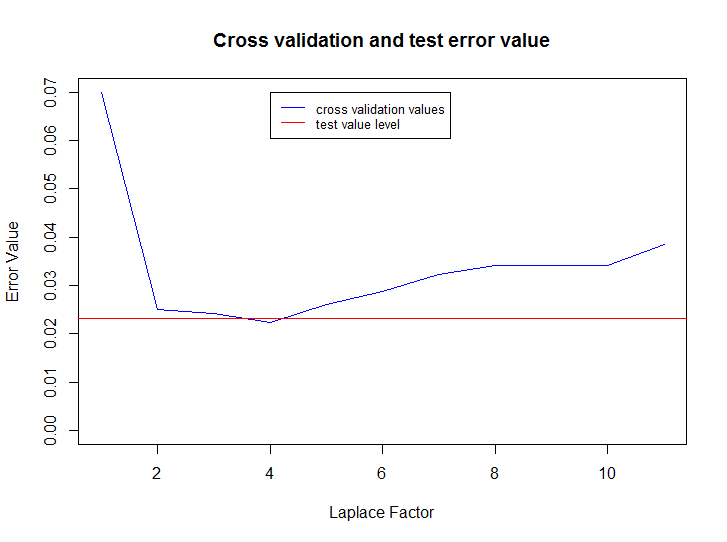
次のコードは、データを読み取り、0から10までのblurパラメーターの値のモデルを作成し、最良の結果を選択し、以前に使用されていないテストセットでモデルをテストし、その後、blurパラメーターとテストセットの最終エラーレベルからクロス検証セットのエラー変化のグラフを作成します:
rm(list = ls()) source("./Spam/spam.R") set.seed(14880) fileName <- "./Data/Spam/SMSSpamCollection" df <- LoadData() ds <- CreateDataSet(df, proportions = c(0.7, 0.2, 0.1)) laplaceFactorValues <- 1:10 cvErrors <- CrossValidation(df[ds$train, ], df[ds$validation, ], 0:10, showLog = T) bestLaplaceFactor <- laplaceFactorValues[which(cvErrors == min(cvErrors))] model <- CreateModel(data=df[ds$train, ], laplaceFactor=bestLaplaceFactor) testResult <- TestModel(df[ds$test, ], model) plot(cvErrors, type="l", col="blue", xlab="Laplace Factor", ylab="Error Value", ylim=c(0, max(cvErrors))) title("Cross validation and test error value") abline(h=testResult, col="red") legend(bestLaplaceFactor, max(cvErrors), c("cross validation values", "test value level"), cex=0.8, col=c("blue", "red"), lty=1)
すべてのコードは
githubからダウンロードできます。
おわりに
ご覧のとおり、この方法は単純な前処理でも非常に効果的です。テストセットのエラーインジケーター(メッセージの総数に対する誤って分類されたメッセージの割合)はわずか
2.32%です。 この方法はどこで使用できますか? たとえば、サイトには多くのコメントがあり、最近1〜5のコメントの評価を入力しましたが、実際に評価されているのはほんの一部です。 その後、残りのコメントに対して関連性の高い評価を自動的にランク付けできます。