__COUNTER__インラインマクロの安全な代替案を開発することが提案されています。 マクロの最初の出現は
0に、2番目の出現は
1に、というように置き換えられます。 値
__COUNTER__前処理段階で置換されるため、
定数式のコンテキストで使用できます。
残念ながら、
__COUNTER__マクロ
__COUNTER__ヘッダーファイルで使用するの
__COUNTER__危険です。ヘッダーファイルが異なる方法でオンになっていると、カウンター値が変更されます。 これにより、たとえば、
foo.cppでは
AWESOME定数の値が42であるのに対し、
bar.cpp AWESOME≡33ある状況が発生する可能性があります。 これは、C ++の世界ではひどい犯罪である1つの定義ルールの原則に違反しています。
1つのグローバルカウンタではなくローカルカウンタを使用する機能が必要です(少なくとも各ヘッダーファイルに対して)。 同時に、
定数式でカウンター値を使用する機能は保持
する必要があります。
スタックオーバーフローに関する
この質問に基づいています。
動機付けの例
コンパイル時カウンターはいつ便利ですか?マクロを実装して、シリアル化をサポートする単純なデータ構造を定義するとします。 次のようになります。
STRUCT(Point3D) FIELD(x, float) FIELD(y, float) FIELD(z, float) END_STRUCT
ここでは、
x, yおよび
zフィールドのリストで
Point3D構造体を定義するだけではありません。 また、シリアル化関数と逆シリアル化関数も
自動的に取得します。 新しいフィールドを追加して、そのフィールドのシリアル化サポートを忘れることはできません。 あなたは
ブーストよりもはるかに少ないことを書かなければならない。
残念ながら、フィールドの定義を生成し、シリアル化関数を生成するために、フィールドのリストを少なくとも2回調べる必要があります。 プリプロセッサのみを使用することはできません。 しかし、ご存知のように、C ++の問題はテンプレートの助けを借りて解決できます(テンプレートの過剰な問題を除く)。
FIELDマクロを次のように定義します(わかりやすくするために
__COUNTER__を使用します)。
#define FIELD(name, type) \ type name;
FIELD(x, float)展開すると
FIELD(x, float)次のようになります
float x;
FIELD(y, float)デプロイする
FIELD(y, float)判明します
float y;
FIELD()マクロの以降の各オカレンスは、フィールド定義に
加えて 、
serialize< i >()関数
の特殊化
>() i = 0,1,2、...
N )に展開されます
。 serialize<i>()関数は
serialize<i+1>()などを呼び出します。 カウンターは、異なる機能をリンクするのに役立ちます。
リンクは動作するサンプルコードです。
1ビットのコンパイル時カウンター
まず、1ビットカウンターの実装を示します。
- テンプレート構造
cn<n>定義します。 sizeof(cn<n>) ≡ n+1ことに注意してください。
- テンプレート関数
magic定義します。
- 式に適用された
sizeof演算子は、指定された式が持つ型のサイズを返します。 式は評価されないため、 magic関数の本体の定義は不要です。
現在定義されている唯一のmagic関数は、手順2のテンプレートです。したがって、戻り値の型と式全体はcn<0>です。
- オーバーロードされた
magic関数を定義します。 オーバーロードされた関数はテンプレート関数よりも優先されるため、 magic呼び出すときにあいまいさが発生しないことに注意してください。
- これで、
magic(cn<0>())呼び出すときに、関数の別のバリアントが使用されます。 sizeof内の式のタイプはcn< 1 >()です。
要約-関数呼び出しを含む式があります。 オーバーロードされた関数の定義を追加します。その結果、コンパイラーは新しい関数を使用します。 したがって、式は
テキスト的に同じままですが、関数からの戻り値の型と式全体の型が変更されました。
1ビットカウンターの読み取りと「インクリメント」のためのマクロを定義します。
#define counter_read(id) \ (sizeof(magic(cn<0>())) - 1) #define counter_inc(id) \ cn<1> magic(cn<0>)
idパラメーターについて設計上、 idパラメーターは、一意の型を識別し、それらをidとして使用することにより、いくつかの独立したカウンターを使用できます。 idをサポートするには、 magicが追加のidパラメーターを取る必要があります。 オーバーロードされたmagic関数は特定のidを参照し、他のすべてのidには影響しません。
Nビットコンパイル時間カウンター
Nビットカウンタは、シングルビットカウンタと同じ原理に基づいて構築されています。
sizeof内の単一の
magicコールの代わりに、ネストされたコールのチェーン
a(b(c(d(e( … ))))).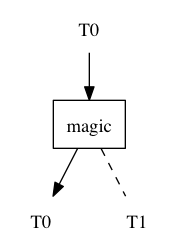
これが基本的なビルディングブロックです。 これは、タイプT
0の単一引数の関数です。 利用可能なスコープ宣言に応じて、戻り値の型はT
0またはT
1になります。 このデバイスは、鉄道の矢印に似ています。 初期状態では、「矢印」は左に向けられています。 矢印は一度だけ切り替えることができます。
いくつかの基本ブロックを使用して、広範なネットワークを構築できます。
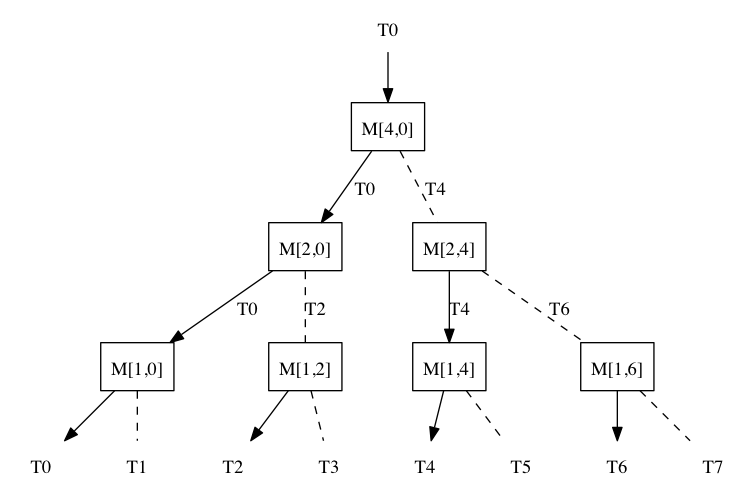
関数の適切なバリアントを検索する場合、C ++コンパイラはパラメータのタイプのみを考慮し、戻り値のタイプを無視します。 式にネストされた関数呼び出しがある場合、コンパイラーは内部から「移動」します。 たとえば、次の式:M
1 (M
2 (M
4 (T
0 ())))では、コンパイラーは最初に関数M
4 (T
0 )の呼び出しを許可(「解決」)します。 次に、関数M
4の戻り値のタイプに応じて、M
2 (T
0 )またはM
2 (T
4 )などの呼び出しを許可します。
鉄道の類推を続けると、コンパイラーは鉄道ネットワークに沿って上から下に移動し、矢印を右または左に「回して」いると言えます。
N個のネストされた関数呼び出しの式は、2
N個の出力を持つネットワークを生成します。 矢印を正しい順序で切り替えると、ネットワークの出力で2
Nのすべての可能なタイプのT
iを順番に取得できます。
ネットワークの出力の現在のタイプがT
iである場合、次のタイプは矢印
M [(i + 1)&〜i、(i + 1)&i]を切り替える必要があることが示されます。
コードの最終バージョンは
こちらから入手でき
ます 。
結論の代わりに
コンパイル時カウンターは、オーバーロードされた関数のメカニズムに完全に基づいています。 Stack Overflowでこの手法を
見つけました 。 原則として、C ++での
非自明なコンパイル時間の計算はテンプレートに実装されます。これは、提示されたソリューションがテンプレートの代わりに他のメカニズムを使用するため、特に興味深い理由です。
これらのソリューションはどの程度実用的ですか?
単一のC ++ファイルが5分以上コンパイルされ、コンパイラの最新バージョンのみがそれに対処できる場合、これは間違いなく
非実用的です。 C ++で言語機能を使用するための多くの「創造的な」オプションは、純粋に学術的な関心の対象です。 原則として、同じタスクは、外部コードジェネレーターを使用するなど、他の方法でより適切に解決できます。 私は言わなければならないが、著者はこの問題にやや偏っており、
精神を断固として認識しておらず、
バイソンに関連していくつかの弱点を経験している。
次のグラフから明らかなように、コンパイル時のカウンターもあまり実用的ではないようです。
x軸はテストプログラムのカウンターインクリメントの絶対値を表し(テストプログラムは
counter_inc(int)行で構成されます)、
y軸はコンパイル時間を秒単位で
counter_inc(int)ます。 比較のために、nginx-1.5.2のコンパイル時間も延期されます。
