前回 、MILコードを調べてGILの実装を理解し、残りの質問に答えることを提案しました。 今日は何をしますか。

この記事のドラフト版にはCコードのビットが豊富に含まれていましたが、そのため、細部の本質は失われていました。 最終バージョンにはコードはほとんどありませんが、ソースを掘り下げたい人のために、言及した関数へのリンクを残しました。
前のシリーズ
最初の部分の後、2つの質問が残りました。
- GIL
array << nilアトミック操作を行いますか? - GILはRubyコードをスレッドセーフにしますか?
最初の質問には実装を見て答えることができますので、それから始めましょう。
前回、次のコードを見つけました。
array = [] 5.times.map do Thread.new do 1000.times do array << nil end end end.each(&:join) puts array.size
配列がスレッドセーフであると考えると、結果として5000個の要素を持つ配列を取得することを期待するのは論理的です。 配列は実際にはスレッドセーフではないため、JRubyまたはRubiniusコードを実行すると、予想とは異なる結果(要素が5,000未満の配列)が得られます。
MRIは期待どおりの結果をもたらしますが、それは事故ですか、それともパターンですか? Rubyの小さなコードから調査を始めましょう。
Thread.new do array << nil end
で始まる
このコードで何が行われているかを理解するには、MRIが新しいスレッド、主に
thread*.cファイルのコードを作成する方法を調べる必要があります。
Thread.new実装内の最初のことは、Rubyスレッドによって使用される新しいネイティブスレッドを
Thread.newすることです。 その後、
thread_start_func_2関数が
thread_start_func_2ます。 詳細に触れずに見てみましょう。
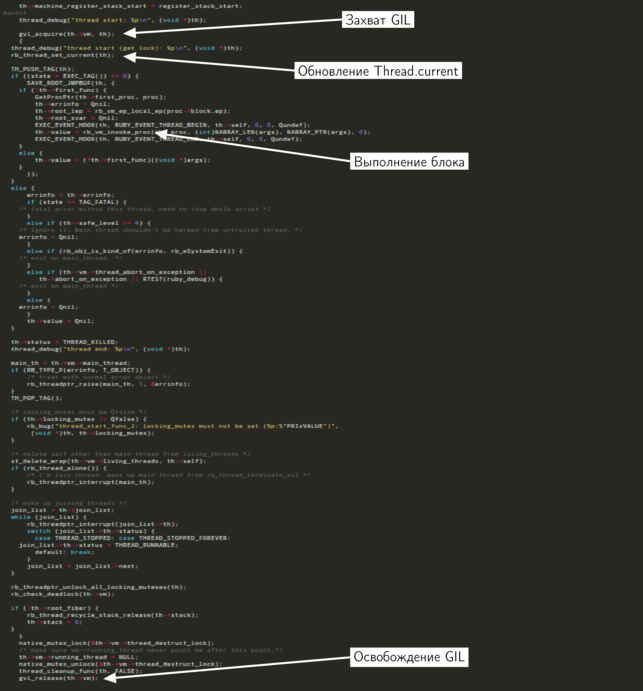
私たちにとって、すべてのコードが現在重要であるわけではないので、私たちにとって興味のある部分を強調しました。 関数の開始時に、新しいスレッドがGILをキャプチャしてから、GILが解放されるのを待ちます。 関数の途中のどこかで、
Thread.newメソッドが呼び出されたブロックが
Thread.newます。 最後に、ロックが解除され、ネイティブスレッドが終了します。
私たちの場合、メインスレッドに新しいスレッドが作成されます。つまり、GILがそのスレッドに保持されていると仮定できます。 先に進む前に、新しいスレッドはメインスレッドがロックを解除するのを待つ必要があります。
新しいスレッドがGILをキャプチャしようとするとどうなるか見てみましょう。
static void gvl_acquire_common(rb_vm_t *vm) { if (vm->gvl.acquired) { vm->gvl.waiting++; if (vm->gvl.waiting == 1) { rb_thread_wakeup_timer_thread_low(); } while (vm->gvl.acquired) { native_cond_wait(&vm->gvl.cond, &vm->gvl.lock); }
これは、新しいスレッドがGILをキャプチャしようとするときに呼び出される
gvl_acquire_common関数の一部です。
まず、ロックがすでに保持されているかどうかを確認します。 保持されている場合、
waiting属性が増分されます。 コードの場合、
1等しくなります。 次の行は、
waiting属性
1が等しいかどうかを確認します。 等しいため、次の行はタイマーストリームを起動します。
タイマースレッドはMRIスレッドを提供し、それらの1つがGILを常に保持する状況を防ぎます。 しかし、タイマーストリームの説明に進む前に、GILを扱います。

MRIの各スレッドの背後にあるのはネイティブスレッドであると、すでに何度か言及しました。 しかし、このスキームでは、MRIストリームがネイティブストリームと同様に並行して動作することを前提としています。 GILはこれを防ぎます。 スキームを補足し、より現実に近づけます。
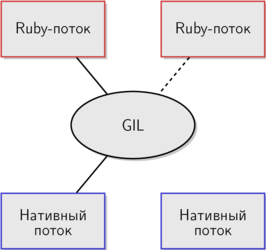
ネイティブスレッドを有効にするには、Rubyスレッドが最初にGILをキャプチャする必要があります。 GILは、Rubyスレッドと対応するネイティブスレッドの間の媒介として機能し、同時実行性を大幅に制限します。 前の図では、Rubyスレッドはネイティブスレッドを並行して使用できます。 2番目のスキームは、MRIの場合により現実に近いものです。ある時点で1つのスレッドのみがGILを保持できるため、並列コード実行は完全に排除されます。
開発チームにとって、MRI
GILはシステムの内部状態を保護します 。 GILのおかげで、内部データ構造はロックを必要としません。 2つのスレッドが一般データを同時に変更できない場合、競合状態は不可能です。
開発者として、あなたが上で書いたことは、MRIでの並行性が非常に限られていることを意味します。
タイマーの流れ
先ほど言ったように、タイマースレッドは、GILが1つのスレッドによって常に保持されるのを防ぎます。 タイマースレッドは、内部MRIのニーズに対応するネイティブスレッドであり、対応するRubyスレッドはありません。
rb_thread_create_timer_thread関数でインタープリターが開始されると開始します。
MRIが開始され、メインスレッドのみが実行されている場合、タイマースレッドはスリープしています。 しかし、あるスレッドがGILのリリースを待機し始めるとすぐに、タイマースレッドが起動します。
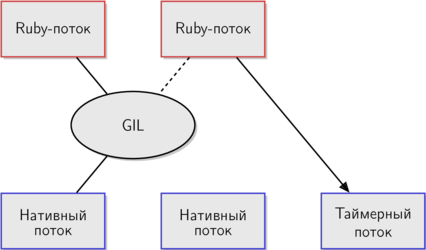
この図は、GILがMRIでどのように実装されるかをさらに示しています。 右側のスレッドが開始されたばかりで、GILの解放を待機しているのはこれだけなので、タイマースレッドが起動します。
100ミリ秒ごとに、タイマースレッドは、
RUBY_VM_SET_TIMER_INTERRUPTマクロを使用して、GILが現在保持しているスレッド割り込みフラグを設定します。 これらの詳細は、式
array << nilアトミックかどうかを理解するために重要です。
これは、慣れ親しんでいる場合、OSでのタイムスライスの概念に似ています。
フラグを設定しても、すぐにストリームが中断されることはありません(中断された場合、式
array << nilアトミックで
array << nilないと言っても安全です)。
割り込みフラグ処理
vm_eval.cファイルの
vm_eval.c Rubyでメソッド呼び出しを処理するためのコードがあります。 メソッドを呼び出すための環境を設定し、必要な関数を呼び出します。
vm_call0_body関数の最後で、メソッドが戻る直前に、割り込みフラグがチェックされます。
スレッド割り込みフラグが設定されている場合、値を返す前にコード実行が一時停止します。 他のRubyコードを実行する前に、現在のスレッドはGILを解放し、
sched_yield関数を呼び出します。
sched_yieldは、キュー内の次のスレッドを再開するようにOSスケジューラーに要求するシステム関数です。 その後、中断されたスレッドは、別のスレッドがGILを解放するのを待つ前に、GILを再度キャプチャしようとします。
最初の質問に対する答えは次のとおりです
array << nilはアトミック操作です。 GILのおかげで、Cでのみ実装されたすべてのRubyメソッドはアトミックです。
つまり、次のコード:
array = [] 5.times.map do Thread.new do 1000.times do array << nil end end end.each(&:join) puts array.size
MRIで起動したときに期待される結果が得られることが保証されています
(配列の長さの予測可能性についてのみ話しているため、要素の順序についての保証はありません-約per。)しかし、これはRubyのコードには従わないことに注意してください 。 GILを持たない別の実装でこのコードを実行すると、予測できない結果が生成されます。 GILが提供するものを知ることは有用ですが、GILに依存するコードを書くことは良い考えではありません。 そうすることで、
ベンダーロックに似た状況に陥り
ます 。
GILはパブリックAPIを提供しません。 GILに関するドキュメントまたは仕様はありません。 MRI開発チームがGILの動作を変更したり、GILを完全に削除したりできます。 そのため、現在の実装でGILに依存するコードを書くのは良い考えではありません。
Rubyに実装されているメソッドはどうですか?
したがって、
array << nilはアトミック操作であることがわかります。 この式では、1つのメソッドは
Array#<<と呼ばれ、定数としてパラメーターとして渡され、Cで実装されます。コンテキストを切り替えても、データ整合性違反は発生しません。このメソッドは、いずれの場合でも終了前にのみGILを解放します。
そのようなものはどうですか?
array << User.find(1)
Array#<<メソッドを呼び出す前に、パラメーター値を計算する必要があります。つまり、
User.find(1)呼び出します。 ご存知かもしれませんが、
User.find(1)はRubyで書かれた多くのメソッドを呼び出します。
ただし、GILはCで実装されたアトミックのみのメソッドを作成します。Rubyのメソッドについては保証されません。
新しい例では、
Array#<<への呼び出しはアトミックのままですか? はい。ただし、右利きの式を実行する必要があることを忘れないでください。 つまり、最初に
User.find(1)メソッドを呼び出す必要がありますが、これはアトミックではなく、それによって返される値のみが
Array#<<渡されます。
これは私にとって何を意味するのでしょうか?
記事の
最初の部分では、関数の途中でコンテキストの切り替えが発生した場合に何が起こるかを見ました。 GILはそのような状況を防ぎます-コンテキストの切り替えが発生しても、他のスレッドはGILが解放されるまで待機することを余儀なくされるため、実行を継続できません。
これはすべて、メソッドがCで実装され、Rubyコードにアクセスせず、GIL自体を解放しないという条件でのみ発生します (
元の記事へのコメントでは、例を示します-Cで実装された連想配列(ハッシュ)に要素を追加することは、アトミックではありません要素のハッシュを取得するためのRubyコード-約GILは、MRI実装内で競合状態を不可能にしますが、Rubyコードをスレッドセーフにしません。 GILは、インタープリターの内部状態を保護するために設計されたMRIの単なる機能であると言えます。
翻訳者はコメントや建設的な批判を喜んで聞きます。