この記事では、オリジナルのDVDディスクから字幕をコピーしてオリジナルの言語で映画を観たいと思っている、オリジナル言語の映画やビデオ製品を見るファンが直面する重要な側面に触れたいと思います。 ほとんどの場合、最高の翻訳は元のサウンドトラックに失われることに同意します。
ご存じのとおり、DVDディスクでは字幕は事前にレンダリングされた形式で表示されるため、字幕を編集または翻訳することはできません。 利用可能な自動変換ユーティリティは、英語を話す視聴者向けであるだけでなく、仕事が非常に貧弱であることに加えて、認識されたテキストに多くのエラーがあります。 この質問を処理した後、ある晩、Perlで簡単なテクニックとスクリプトを開発してテストしました。
FineReader、SubRip、Perlインタープリターのプログラムを使用して、FineReaderが認識するテキストファイルから字幕を作成するためのスクリプトを実行する必要があります。 それらを入手する場所はYandexまたはGoogleに伝えますが、これらのプログラムはすべて広く知られています。
それで、私たちは始めています。
1. SubRibユーティリティを実行し、目的のビデオシーケンスファイルのサフィックス* _0.VOBでVOBを開きます。 以下のスクリーンショットに示すように、必要な字幕トラックを選択します。 「subticturesをBMPとして保存」オプションを選択します。
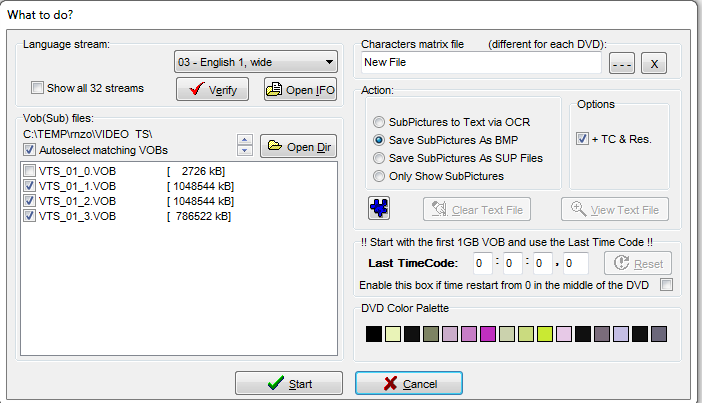
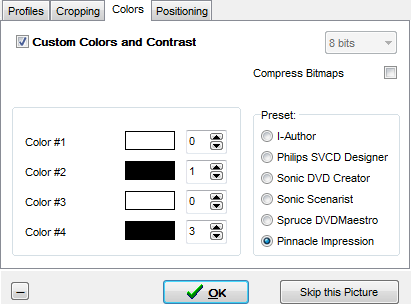
2. [スタート]ボタンをクリックします。 SubRipが抽出された字幕画像をBMP形式で保存するディレクトリを選択し、ファイルプレフィックス、番号、および拡張子BMPを指定してSubRipに自動的に追加します。 次に、以下に示すように字幕のレンダリングスタイルを選択します。 私自身の経験から、白黒のカスタムスキームを選択し、Color 1およびColor3パラメーターの値をリセットし、Color2およびColor4パラメーターの最小値を設定することをお勧めします。
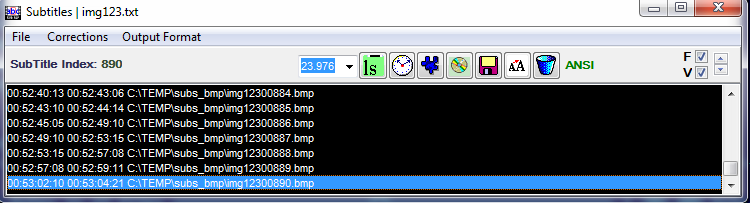
3. SubRipがVOBファイルから画像を抽出し、以前に選択したディレクトリにBMP形式の画像を作成するのを待ちます。 保存プロセスは、アプリケーションによって開かれた新しいウィンドウに表示されます。
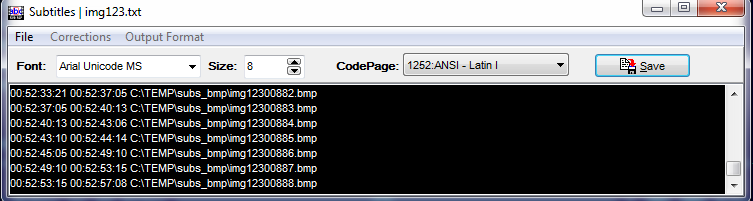
4.プロセスが完了したら、生成されたSubRipファイルを字幕のタイミングで保存します。BMPイメージの生成中に開く新しいウィンドウに表示されます。 ASCII形式を選択します。
5.これで、字幕とタイミングのファイルが手に入りました。 FineReaderを開く時間です。 FineReaderを起動し、字幕に存在する認識言語(複数ある場合)を選択し、「PDFまたは画像を開く」オプションを選択し、CTRL-Aを使用してダイアログのカタログからすべての画像を選択します。 画像を開く前に、認識オプションを示します。 オプションの構成を以下の2つのスクリーンショットに示します。
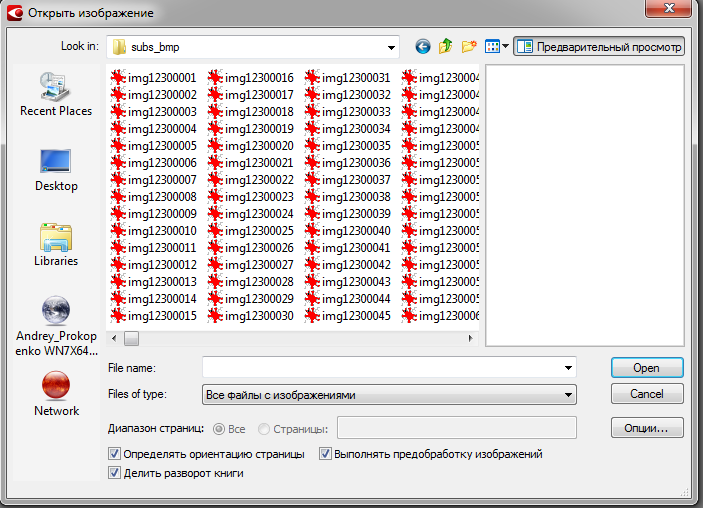
プロセスを簡素化するには、組み込みテンプレートのみを使用できますが、独自のテンプレートを使用して認識プロセスを制御する場合は、2番目のオプションを選択します。
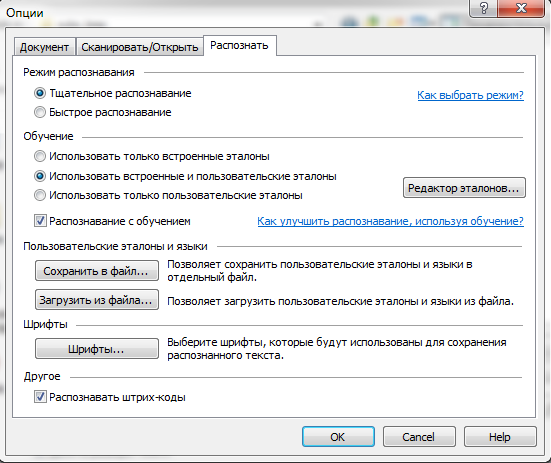
6.テキストを認識してチェックした後、結果を保存する必要があります。 FineReaderは字幕の段落の終わりを常に正しく認識しなかったため、実験の結果に応じて、個別のファイルに保存するオプションを選択しました。
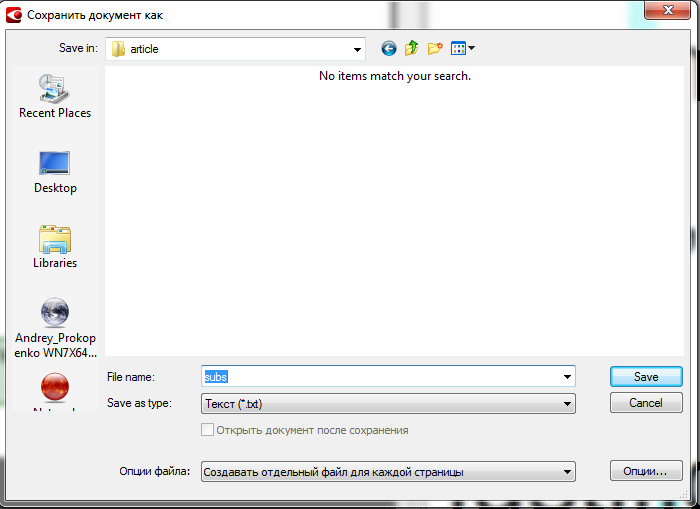
保存するファイルの種類(テキストファイルに保存)を以下のスクリーンショットに示します。

保存するときは、ディレクトリを選択し、テキストファイルのプレフィックスを指定し、ドロップダウンメニューから[ページごとに個別のファイルを作成]を選択し、[オプション]ボタンをクリックします
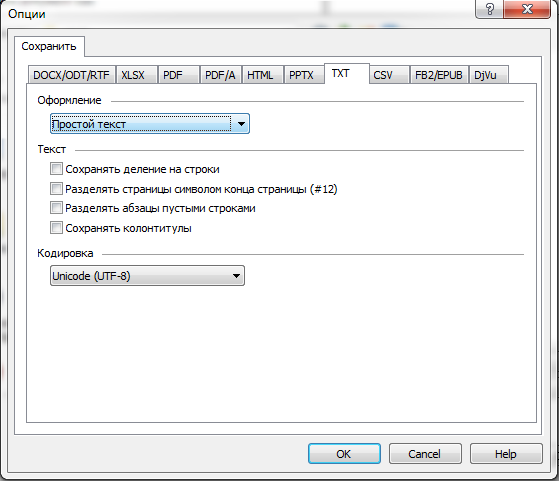
次に示すように保存オプションを指定します。
7.上記のすべてのアクションの結果、UTF-8エンコーディングのテキストファイルが多数含まれるディレクトリが作成されました。 次に、それらを変換する必要があります。 これを行うために、ステップ4で以前に保存した字幕と多くのテキストファイルに基づいて字幕を組み立てるための小さなスクリプトを作成しました。 これを行うには、以下に示すPerlスクリプトを保存するか、スクリプトのコンパイル済みバージョンの実行可能ファイルを
ダウンロードして、 2つのパラメーターで実行します。
-フルパスとディレクトリ名をテキストファイルとともに含みます
-タイミングファイルのフルパスと名前のタイミング。
スクリプトは、作成されたファイルをUTF8形式でコンソールに表示するため、選択したファイルにリダイレクトできます。
それだけです、ご清聴ありがとうございました。