問題を解決すると、MikrotikでのL7の奇妙な動作が明らかになりました。 正規表現で明示的に指定すると、正規表現の文字がバイト単位で指定されている場合でも、大文字と小文字は無視されます。

問題を提起します(タスクは、エラーを示すために特別に考案されました)。
次のURLをブロックします:
http :
//chelaxe.ru/Summary/URLでわかるように、大文字の文字
Sがあります
。これを行うには
、MikroTikのLayer7を使用します。これ
により 、パケットをガットできます。 接続から最初の10パケットまたは2kbを収集し、必要な正規表現データを探します。
すべてが次のように構成されます。
/ip firewall layer7-protocol add name=lock regexp=^.*(\/Summary\/).*(chelaxe\.ru).*$/ip firewall filter add action=drop chain=forward disabled=no dst-port=80 layer7-protocol=lock protocol=tcp src-address=192.168.0.0/24次に、正しい正規表現(
POSIX )を作成する必要があります。 最初に、私はこれをやろうとしました:
^.*(chelaxe\.ru\/Summary\/).*$しかし、私は成功しませんでした、それから
Wiresharkを取り、パッケージを見ました:
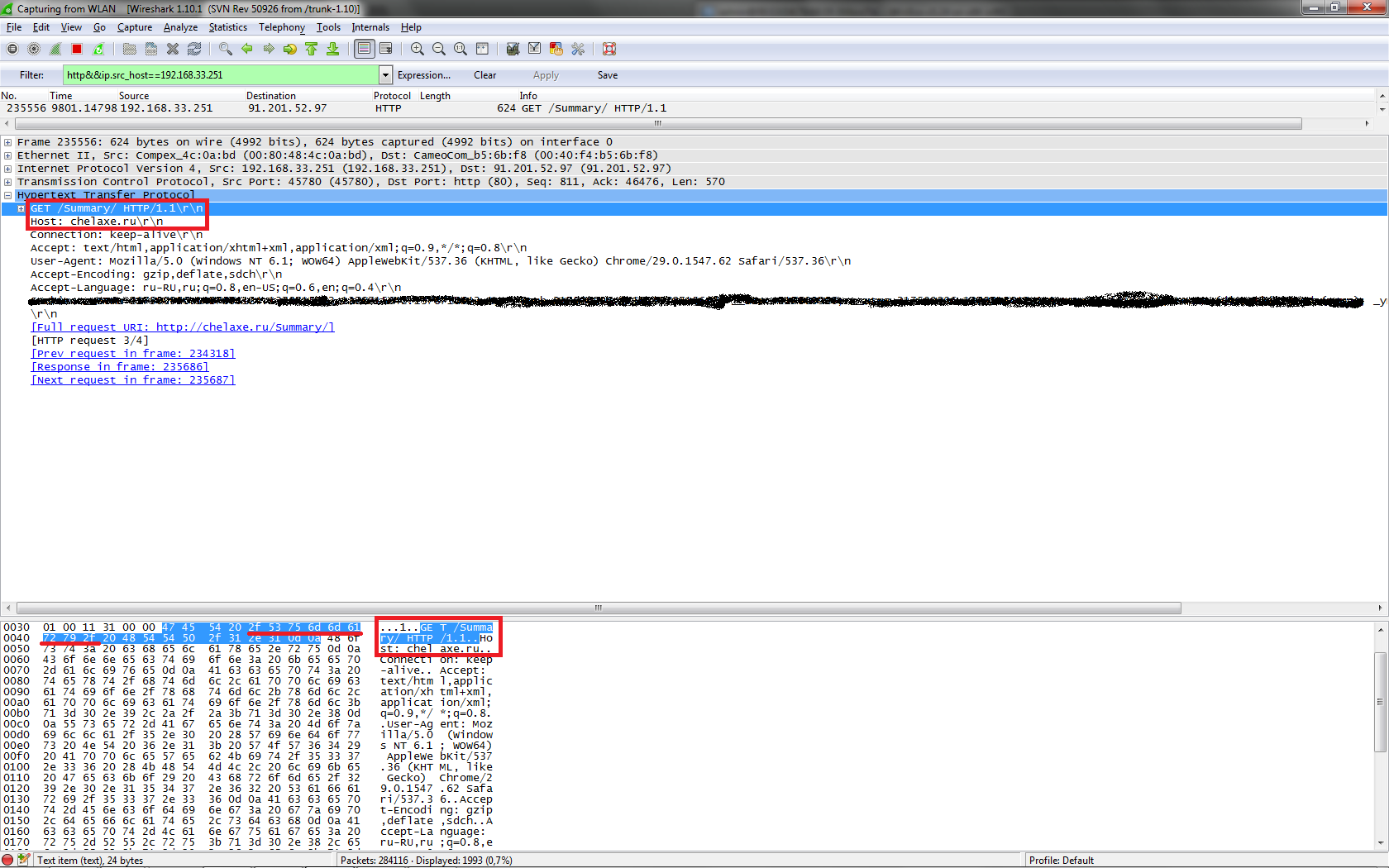
ご覧のとおり、パッケージのGET行はHost行とは別であり、GET行は先に進みます。
GET /Summary/ HTTP/1.1Host: chelaxe.ru正規表現のやり直し:
^.*(\/Summary\/).*(chelaxe\.ru).*$私たちはチェックします:
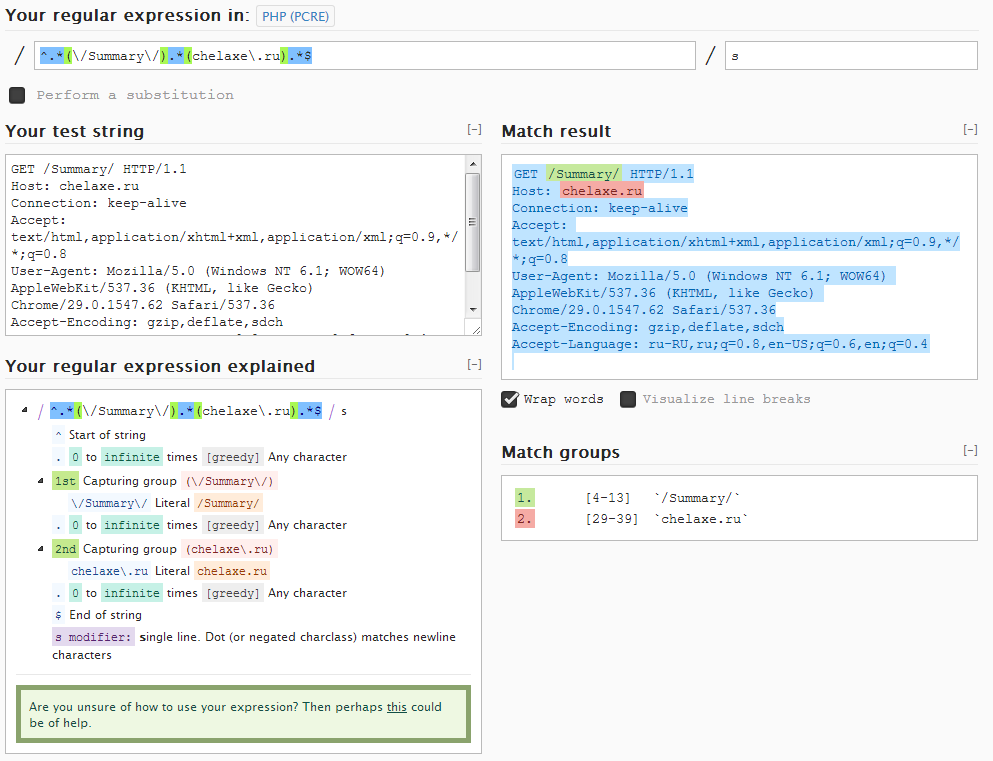
正規表現をチェックして作成するために、正規表現の
解析の記事に
regex101.com thanks
0dminを使用し
ました 。
すべてをMikroTikに追加し、
http: //chelaxe.ru/Summary/にアクセスし
ます結果:動作しません
正規表現を修正します:
^.*(\/summary\/).*(chelaxe\.ru).*$その結果、WORKS、ただし
http://chelaxe.ru/Summary/と
http://chelaxe.ru/summary/の両方をブロックし
ます (特に、Sの大文字と小文字を区別する2つのページを作成しました)
私は別の方法でやろうとしました:
^.*(\x2f\x53\x75\x6d\x6d\x61\x72\x79\x2f).*$バイト単位のこの文字列は、文字列/ Summary /
結果:動作しません
バイト\ x53を\ x73に変更(Sからs):
^.*(\x2f\x73\x75\x6d\x6d\x61\x72\x79\x2f).*$その結果、WORKSですが、
http://chelaxe.ru/Summary/と
http://chelaxe.ru/summary/の両方をブロックし
ますパッケージには大文字の文字列が残されており、同じ形式でサーバーに送られます(サイトは大文字または小文字で解析されます)、正規表現は正しいですが、大文字の文字列を検索するとき、および文字列を検索するときに何も返しません小文字は両方のオプション(大文字と小文字の両方)を返します。
結論:MikroTikでL7を使用して、パッケージ内の大文字と小文字を区別する情報を決定することはできません。
UPD:バージョンv5.26(ブランチ5の最後)を使用し、ブランチ6でこのバグが修正されました。
6.0rc12の新機能(2013-Mar-26 17:18):
*)layer7マッチャーを修正-大文字小文字を区別しなくなりました。
バージョンv6.3でチェックすると、すべてが正常に機能します。 そのため、この機能は
RouterOSの 5番目のブランチにのみ存在し
ます。考察:プロバイダーがどのようにレジストリからサイトをブロックするかを見ました:GETパスのレジスタを変更するとき、ページはまだブロックされています。
そのようなページがブロックされたサイトが大文字のみで同じURLのページを作成し、禁止されているものが含まれていないためブロックを解除する必要がある場合、レジストリに入力されたURLもロック解除されます。