翻訳者から:このテキストは、材料を過度に「噛む」場所のために、小さな略語で示されています。 著者は、読者には特定のトピックが単純すぎる、または有名すぎるように見えるかもしれないと正しく警告しています。 それにもかかわらず、個人的には、このテキストは、アルゴリズムの複雑さの分析に関する既存の知識を合理化するのに役立ちました。 他の誰かに役立つことを願っています。
元の記事の量が多いため、私はそれを部分に分割しましたが、そのうち合計4つになります。
私は(いつものように)翻訳の品質の改善に関するPMのコメントに非常に感謝します。以前に公開された:
パート1パート2パート3最適なソート
おめでとうございます! これで、アルゴリズムの複雑さを分析する方法、漸近推定値と「big-O」の表記法がわかりました。 また、アルゴリズムの複雑さが
O( 1 ) 、
O( log( n ) ) 、
O( n ) 、
O( n 2 )であるかどうかを直感的に調べる方法も知っています。 シンボル
o 、
O 、
ω 、
Ω 、
Θおよび「最悪の場合」の概念に精通しています。 この場所に着いたら、私の記事はすでにそのタスクを完了しています。
この最後のセクションはオプションです。 少し複雑なので、必要に応じてスキップしても構いません。演習に集中して時間をかける必要があります。 ただし、アルゴリズムの複雑さを分析するための非常に便利で強力な方法もここで説明します。これはもちろん注目に値します。
選択ソートと呼ばれるソートの実装を見て、最適ではないことに言及しました。
最適なアルゴリズムとは、
最適な方法で問題を解決するアルゴリズムであり、これを改善するアルゴリズムがないことを意味します。 つまり この問題を解決するための他のすべてのアルゴリズムは、同じまたはより大きな複雑さを持っています。 同じ複雑さを持つ最適なアルゴリズムがたくさんあるかもしれません。 同じソートの問題は、多くの方法で最適に解決できます。 たとえば、バイナリ検索と同じ考え方を使用して、すばやく並べ替えることができます。 このメソッドは
マージソートと呼ばれ
ます 。
実際のマージソートを実装する前に、補助関数を作成する必要があります。 これを
mergeと呼び、既にソートされた2つの配列を取得して、それらを1つに結合します(これもソートされます)。 これは簡単です。
def merge( A, B ): if empty( A ): return B if empty( B ): return A if A[ 0 ] < B[ 0 ]: return concat( A[ 0 ], merge( A[ 1...A_n ], B ) ) else: return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) )
concat関数は、要素(「head」)と配列(「tail」)を受け取り、それらを連結して、最初の要素として「head」、残りの要素として「tail」を持つ新しい配列を返します。 たとえば、
concat( 3, [ 4, 5, 6 ] )は
concat( 3, [ 4, 5, 6 ] )を返します。
A_nと
B_nを使用して
Bそれぞれ配列
Aと
Bサイズを示します。
演習8上記の関数が実際にマージされることを確認してください。 再帰の代わりに反復(forループ)を使用して、お気に入りのプログラミング言語で書き換えます。
このアルゴリズムの分析により、実行時間が
Θ( n )であることが
n = A_n + B_nます。ここで、
nは結果の配列の長さです(
n = A_n + B_n )。
演習9merge実行時間がΘ( n )ことを確認します。
この関数を使用して、より良いソートアルゴリズムを構築できます。 これは、配列を2つの部分に分割し、それぞれを再帰的に並べ替え、並べ替えられた2つの配列を1つに結合するという考え方です。 擬似コード:
def mergeSort( A, n ): if n = 1: return A
この関数は、前の関数よりも理解が難しいため、次の演習では時間がかかる場合があります。
演習10mergeSort正しいことを確認します(つまり、渡された配列を正しくソートすることを確認します)。 基本的に機能する理由を理解できない場合は、小さな例を手動で解決してください。 同時に、配列を半分に分割するときにleftHalfとrightHalfが取得されることを忘れないでください。 たとえば、配列に奇数個の要素が含まれる場合、これはパーティションがちょうど真ん中にある必要はありません(これはfloor関数が必要なものです)。
最後の演習として、
mergeSortの複雑さを分析しましょう。 各ステップで、元の配列を2つの等しい部分に分割します(
binarySearchと同様)。 ただし、この場合、両方の部分でさらに計算が行われます。 再帰が戻った後、結果に
merge操作を適用します
merge 、これには
Θ( n )時間かかります。
そのため、元の配列をそれぞれ
n / 2サイズの
n / 2つの部分に分割します。 それらを接続すると、
n要素が操作に参加するため、実行時間は
Θ( n )ます。 次の図は、この再帰を示しています。
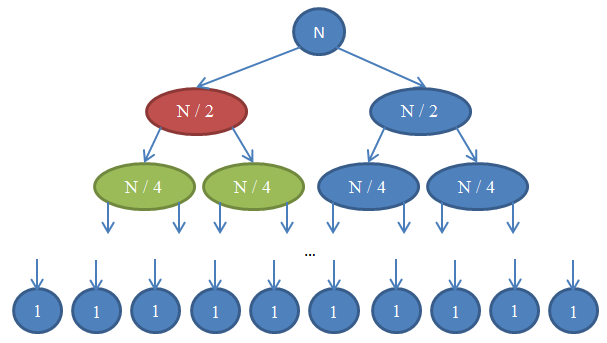
ここで何が起こるか見てみましょう。 各円は、
mergeSort関数の呼び出しを
mergeSortます。 円内の数字は、配列内の並べ替えられる要素の数を示します。 上の青い円は、サイズ
n配列に対する
mergeSortの最初の呼び出しです。 矢印は、関数間の再帰呼び出しを示しています。
mergeSortの元の呼び出しは、サイズがそれぞれ
n / 2つの新しい配列を生成します。 次に、それぞれが
n / 4要素の配列でさらに2つの呼び出しを生成し、サイズ1の配列が得られるまで続けます。この図は、
再帰の操作を示し、ツリーのように見えるため、
再帰ツリーと呼ばれます(より正確には、ルートが上部にあり、リーフが下部にあるツリーの反転として)。
各行の要素の数は
nと等しいことに注意してください。 また、各呼び出しノードは、呼び出し操作されたノードから取得した結果を
merge操作に使用することに注意してください。 たとえば、赤いノードは
n / 2個のアイテムをソートします。 これを行うには、
n / 2配列を
n / 4で2つに分割し、それぞれで
mergeSort (緑色のノード)を再帰的に呼び出し、結果をサイズ
n / 2単一整数に結合します。
その結果、各行の複雑さは
Θ( n )です。 再帰ツリーの
深さと呼ばれるこのような行の数は
log( n )なることがわかってい
log( n ) 。 この理由は、バイナリ検索に使用したのと同じ引数です。 したがって、
log( n )行の複雑さ
Θ( n )があるため、
mergeSortの一般的な複雑さは
Θ( n * log( n ) )です。 これは、選択によるソートで得られる
Θ( n 2 )よりもはるかに優れてい
log( n ) nよりはるかに小さいため、
n * log( n )も
n * n = n 2よりもはるかに小さいことに注意してください)。
前の例で見たように、複雑さの分析では、アルゴリズムを比較して、どちらが優れているかを判断できます。 これらの考慮事項に基づいて、大きな配列の場合、マージソートが選択によるソートよりもはるかに優れていることを確認できます。 このような結論は、開発したアルゴリズムの分析の理論的根拠がない場合、問題となります。 間違いなく、実行時
Θ( n * log( n ) )ソートアルゴリズムが実際に広く使用されています。 たとえば
、Linuxカーネルは、ヒープソートと呼ばれるアルゴリズムを使用します。これは、マージソートと同じランタイムです。 これらのソートアルゴリズムの最適性は証明されないことに注意してください。 これには、はるかに面倒な数学的引数が必要になりますが、注意してください。複雑さの観点から、より良いオプションを見つけることは不可能です。
この記事を学習した後、アルゴリズムの複雑さの分析に関する直感は、高速プログラムを作成し、実行速度に大きな影響を与えるものに最適化の努力を集中するのに役立ちます。 すべて一緒にすると、生産性が向上します。 さらに、この記事で説明する数学言語と表記法(「big O」など)は、ランタイムアルゴリズムに関して他のソフトウェア開発者と通信する際に役立ちます。取得したものを実践できることを願っています。知識。
結論の代わりに
この記事は、
Creative Commons 3.0 Attributionで公開されています。 これは、あなたがそれをコピーし、あなたのウェブサイトに公開し、テキストに変更を加え、一般的にあなたがそれで好きなことをすることができることを意味します。 ちょうど私の名前を言及することを忘れないでください。 唯一のこと:このテキストに基づいて作業を行う場合、コラボレーションと情報の普及を促進するために、Creative Commonsで公開することをお勧めします。
最後まで読んでくれてありがとう!参照資料
- コーメン、レイザーソン、リベスト、スタイン。 アルゴリズムの紹介 、MIT Press
- Dasgupta、Papadimitriou、Vazirani。 アルゴリズム 、McGraw-Hill Press
- フォタキス。 アテネ国立工科大学での離散数学コース
- フォタキス。 アテネ国立工科大学のアルゴリズムと複雑さのコース