読者の皆さん、こんにちは。
前の
記事で約束したように、今日は、Pythonでのpandasモジュールとデータ分析に関する話を続けます。 この記事では、分析結果のデータの迅速な視覚化のトピックに触れたいと思います。
matplotlibデータ視覚化
ライブラリと
Spyder開発環境はこれを支援します。
開発環境
したがって、前回見たように、パンダにはデータ分析の機会が十分にありますが、
IPythonインタラクティブシェルを使用すると、データ分析を完全に公開できます。 それについてはHabréで
読むことができ
ます 。 その主な利点として、計算でデータを視覚化するのに便利なmatplotlibライブラリとの統合に注目したいと思います。 そのため、IDEを選択するときに、IPythonをサポートするIDEを探しました。 その結果、私の選択は
Spyderでした。
Spyder(Scientific PYthon Development EnviRonment)は、MATLABに似た開発環境です。 この環境の主な利点は次のとおりです。
- カスタマイズ可能なインターフェース
- matplotlib、NumPy、SciPyとの統合
- 複数のIPythonコンソールの使用のサポート
- コードを記述するときの関数の動的ヘルプ(最後に印刷された関数のヘルプを表示)
- コンソールをhtml / xmlに保存する機能
環境の詳細な概要は
ここに書かれてい
ます 。
データの予備分析とパンダを使用して目的の形式にする
それでは、作業環境の簡単な概要の後、データの視覚化に移りましょう。 例として、ロシア連邦の人口に関する
データを取り上げました。
開始するには、
read_excel()関数を使用して、ダウンロードしたxlsファイルをデータセットにロードしましょう。
import pandas as pd data = pd.read_excel('data.xls',u'1', header=4, parse_cols="A:B",skip_footer=2, index_col=0) c = data.rename(columns={u'':'PeopleQty'})
この場合、関数には6つのパラメーターがあります。
- 開かれたファイルの名前
- データを含むシートの名前
- フィールド名を含む行番号(この例では、最初の3行に参照情報が含まれているため、これは4行目です)
- データセットに分類される列のリスト(この例では、テーブル全体から、年とそれに対応する人口の数の2列のみが必要です)
- 次のパラメーターは、最後の2行を考慮しないことを意味します(コメントが含まれています)
- 最後のパラメーターは、取得した列の最初の列をインデックスとして使用することを示します
rename()関数は、データセットのヘッダーの名前を変更するために使用されます;パラメーターでは、タイプ
{'Old field name': 'New field name'}の辞書が渡されます
これで、データセットは次のようになります。
| PeopleQty |
|---|
| 人口 |
| 万人 |
| 1897.0 | |
| ロシア帝国の国境内 | 128.2 |
| 現代の国境内 | 67.5 |
| 1914 | |
| ロシア帝国の国境内 | 165.7 |
| 現代の国境内 | 89.9 |
| 1917 | 91 |
| 1926 | 92.7 |
| 1939 | 108.4 |
| 1959 | 117.2 |
| 1970 | 129.9 |
| 1971年 | 130.6 |
| 1972 | 131.3 |
| 1973 | 132.1 |
| 1974 | 132.8 |
| 1975 | 133.6 |
| 1976 | 134.5 |
| 1977 | 135.5 |
| 1978 | 136.5 |
| ... | ... |
| 2013 | 143.3 |
さて、データはロードされますが、ご覧のとおり、インデックス列のデータは完全に正しいわけではありません。 たとえば、年番号だけでなくテキストによる説明も含まれ、空の値も含まれます。 さらに、1970年までは、隣接する値の間の時間間隔が大きいため、データが十分に満たされていなかったことがわかります。
いくつかの方法でデータを美しいビューに取り込むことができます。
- またはフィルターを使用する
- または、日付形式の年を含むDataFrameに接続することにより(これはグラフィックの設計にも役立ちます)
フィルターの基本的な作業は、前の記事で説明しました。 したがって、今回は追加のDataFrameを使用します。これは、その形成過程で、pandasを使用して一時シーケンスを作成する方法が示されるためです。
タイムラインを形成するには、date_range()関数を使用できます。 パラメーターでは、3つのパラメーターが初期値、期間数、期間サイズ(日、月、年など)に転送されます。 私たちの場合、1970年から現在までのシーケンスを形成しましょう。なぜなら、 この時点から、テーブルのデータはほぼ毎年満たされます。
a = pd.date_range('1/1/1970', periods=46, freq='AS')
出口で、1970年から2015年までシーケンスを形成しました。
<class 'pandas.tseries.index.DatetimeIndex'>[1970-01-01 00:00:00, ..., 2015-01-01 00:00:00]ここで、このシーケンスをDataFrameに追加する必要があります。元のデータセットに接続することに加えて、シーケンスのように開始日ではなく、直接年数が必要です。 このため、タイムシーケンスにはyearプロパティがあり、各レコードの年番号を返すだけです。 次のようなDataFrameを作成できます。
b = pd.DataFrame(a, index=a.year,columns=['year'])
以下の値が関数パラメーターとして渡されます。
- DataFrameが作成されるデータの配列
- データセットのインデックス値
- セット内のフィールドの名前
データセットの形式は次のとおりです。
| 年 |
|---|
| 1970 | 1970-01-01 00:00:00 |
| 1971年 | 1971-01-01 00:00:00 |
| 1972 | 1972-01-01 00:00:00 |
| 1973 | 1973-01-01 00:00:00 |
| 1974 | 1974-01-01 00:00:00 |
| 1975 | 1975-01-01 00:00:00 |
| 1976 | 1976-01-01 00:00:00 |
| 1977 | 1977-01-01 00:00:00 |
| 1978 | 1978-01-01 00:00:00 |
| 1979 | 1979-01-01 00:00:00 |
| 1980 | 1980-01-01 00:00:00 |
| 1981 | 1981-01-01 00:00:00 |
| ... | ... |
| 2015 | 2015-01-01 00:00:00 |
さて、2つのデータセットがありますが、それらを接続する必要があります。 前の記事で、
merge()でこれを行う方法を示しました。 今回は別の関数
join()を使用します。 この関数は、データセットに同じインデックスがある場合に使用できます(ところで、この関数を示すために追加しました)。 コードでは、次のようになります。
i = b.join(c, how='inner')
関数のパラメーターでは、結合するセットと接続のタイプを渡します。 ご存知のように、内部結合の結果は両方のセットに存在する値で構成されます。
関数merge()とjoin()の違いにすぐに注目する価値があります。 Merge()は異なる列にまたがって結合でき、join()はインデックスでのみ機能します。
分析結果の可視化
操作が完了すると、データセットは次のようになります。
| 年 | PeopleQty |
|---|
| 1970 | 1970-01-01 00:00:00 | 129.9 |
| 1971年 | 1971-01-01 00:00:00 | 130.6 |
| 1972 | 1972-01-01 00:00:00 | 131.3 |
| 1973 | 1973-01-01 00:00:00 | 132.1 |
| 1974 | 1974-01-01 00:00:00 | 132.8 |
| 1975 | 1975-01-01 00:00:00 | 133.6 |
| ... |
| ... | ... | ... |
| ... | ... | ... |
| 2013 | 2013-01-01 00:00:00 | 143.3 |
それでは、人口増加のダイナミクスを示す最も簡単なグラフを描いてみましょう。 これは、
plot()関数を使用して実行できます。 この関数には多くのパラメーターがありますが、簡単な例では、x軸とy軸の値、およびスタイルを担当するスタイルパラメーターを設定するだけです。 次のようになります。
i.plot(x='year',y='PeopleQty',style='k--')
その結果、チャートは次のようになります。

IPythonシェルでplot()関数が呼び出されると、グラフがシェルに直接表示されるため、ウィンドウ間の不要な切り替えを回避できます。 (標準シェルを使用すると、チャートは別のウィンドウで開きますが、あまり便利ではありません)。 さらに、Spyder経由でIPythonを使用する場合、生成されたすべてのチャートとともにセッション全体をhtmlファイルにアップロードできます。
次に、ダイナミクスを棒グラフで表示しましょう。 これはkindパラメーターを使用して実行できます。 デフォルトでは、パラメーターは `line`です。 垂直の列を持つグラフを作成するには、このパラメーターの値を「bar」に変更する必要があります。水平の列には「barh」の値があります。 したがって、水平列の場合、コードは次のようになります。
i.plot(y='PeopleQty', kind='bar')
結果のグラフを以下に示します。
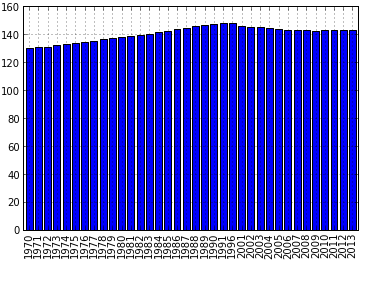
コードからわかるように、ここではxの値を設定しません。前の例とは異なり、インデックスはxとして使用されます。 グラフィックとビューティーガイダンスを使用した本格的な作業には、matplotlibの機能を使用する必要があります。これについては既に多くの記事があります。 これは、pandasの描画関数が、
matplotlib.pyplot.bar()など、上記のライブラリから基本的な描画関数をすばやく呼び出すための単なるアドオンであるという事実によるものです。 したがって、matplotlibから関数を呼び出す際に使用されるすべてのパラメーターは、pandasパッケージのplot()関数を介して設定できます。
おわりに
これで、パンダの分析結果の視覚化の概要は完了です。 この記事では、グラフィックを扱うために必要な基礎を説明しようとしました。 すべての機能の詳細な説明は、
pandasの
ドキュメントと
matplotlibライブラリに記載されています。 また、matplotlib、pandas、IDE Spyder、IPythonシェルなどのライブラリとアドオンを既に含んでいる、データ分析用に特別に調整されたPythonアセンブリがあるという事実にも注目したいと思います。 このような2つのアセンブリは
Python(x、y)と
Anacondaであることを知っています。 1つ目はWindowsのみをサポートしますが、組み込みパッケージの大規模なセットがあります。 Anaconda; tはクロスプラットフォームであり(これが私が使用する理由の1つです)、その無料版には含まれるパッケージが少なくなっています。