
前回の記事では、仮想的ではありますが、プロセッサの内部を調べました。 並列コードが正しく実行されるためには、内部の読み取り/書き込みの最適化を実行できる制限をプロセッサに伝える必要があることがわかりました。 これらのヒントは記憶の障壁です。 メモリバリアにより、メモリアクセス(より正確には、キャッシュへのアクセス-プロセッサはキャッシュを介してのみ外部とやり取りします)を合理化できます。 このような順序の「重大度」は異なる場合があります。各アーキテクチャは、「選択」障壁のセット全体を提供できます。 特定のメモリバリアを使用して、さまざまなメモリモデルを構築できます。これは、プログラムに実装される一連の保証です。
この記事では、C ++ 11メモリモデルについて説明します。
歴史的ミニレビュー当初、メーカーはプロセッサのメモリモデルのオープンな仕様を公開していませんでした。つまり、弱く順序付けられたプロセッサがメモリを操作するための一連のルールを公開していなかったため、将来の操作のためのスペースを獲得することを期待しています(実際、いくつかの義務は?)しかし、その後、メーカーはボトルから魔神を解放しました-ギガヘルツは天井にあり、メーカーはどこでもマルチコアを導入し始めました。 その結果、実際のマルチスレッド化は大衆に行きました。 オペレーティングシステムの開発者は、最初に警告を発しました。カーネルでマルチコアをサポートする必要があり、弱く順序付けられたアーキテクチャの仕様はありません。 その後、言語標準化団体は自らを引き上げました:プログラムはますます並列化され、言語メモリモデルを標準化し、競争力のあるマルチスレッド実行を保証する時が来ました。プロセッサメモリモデルの仕様はありませんでした。 その結果、今日のほとんどすべての最新のプロセッサアーキテクチャは、メモリモデルのオープンな仕様を備えており、Java、.NET、C ++メモリモデルの標準での作業は、そのような仕様の出現に大きな役割を果たしました。
C ++は、低レベルのものを高レベルで表現する能力で長い間有名です。 C ++ 11メモリモデルを開発するとき、タスクはこのプロパティに違反することではありませんでした。つまり、プログラマに最大限の柔軟性を与えることでした。 他の言語(主にJava)の既存のメモリモデルと同期プリミティブとロックフリーアルゴリズムの内部構造の典型的な例を分析した後、標準の開発者は1つではなく
3つのメモリモデルを提案しました。
- 順次一貫性
- セマンティクスの取得/解放
- 緩和されたメモリの順序付け
これらのメモリモデルはすべて、C ++で1つの列挙
std::memory_orderで定義され、次の6つの定数があります。
memory_order_seq_cst順次整合モデルを指しますmemory_order_acquire 、 memory_order_release 、 memory_order_acq_rel 、 memory_order_consume獲得/解放のセマンティクスに基づいてモデルを参照しますmemory_order_relaxedリラックスしたモデルを示します
これらのモデルを検討する前に、プログラムでメモリモデルを指定する方法を決定する必要があります。 ここで再びアトミック操作に戻る必要があります。
標準の
memory_order標準のアトミック操作への引数として指定されているため、
アトミック性に関する記事で引用した操作は、
memory_order C ++ 11で定義されている操作とは関係ありません。 これには2つの理由があります。
- セマンティック:実際、望ましい順序(メモリバリア)は、実行するアトミック操作を具体的に指します。 読み取り/書き込みアプローチでのバリアの配置は、バリア自体が存在するコードに意味的にまったく関係していないため、シャーマニズムです。これは、同等のものの中の単なる命令です。 さらに、読み取り/書き込みバリアはアーキテクチャに大きく依存しています。
- 実用的:Intel Itaniumには、他のアーキテクチャとは異なり、読み取り/メモリ命令およびRMW操作のメモリ順序を指定する特別な方法があります。 Itaniumでは、順序付けのタイプは、命令自体のオプションのフラグ(取得、解放、またはリラックス)として示されます。 さらに、アーキテクチャに獲得/解放セマンティクスを指定するための個別の命令(メモリバリア)はありません。
atomic<T>操作が実際にどのように見えるかを示します
std::atomic<T>クラスのすべての特殊化には、少なくとも以下のメソッドが必要です。
void store(T, memory_order = memory_order_seq_cst); T load(memory_order = memory_order_seq_cst) const; T exchange(T, memory_order = memory_order_seq_cst); bool compare_exchange_weak(T&, T, memory_order = memory_order_seq_cst); bool compare_exchange_strong(T&, T, memory_order = memory_order_seq_cst);
個別のメモリバリアもちろん、C ++ 11には個別の空きメモリバリア関数もあります。
void atomic_thread_fence(memory_order); void atomic_signal_fence(memory_order);
実際、
atomic_thread_fence使用すると、
atomic_thread_fence読み取り/書き込みバリアのアプローチを使用できますが、これは廃止されたと見なされます。 ただし、
memory_order順序付けメソッド自体
memory_order 、読み取りバリア(Load / Load)または書き込みバリア(Store / Store)を指定する方法を提供し
memory_orderん。
atomic_signal_fence 、シグナルハンドラでの使用を目的としています。 原則として、この関数はコードを生成しませんが、コンパイラーの障壁です。
ご覧のとおり、C ++ 11のデフォルトのメモリモデルは順次一貫性です。 最初に検討します。 しかし、最初に、コンパイラーの障壁について少し説明します。
コンパイラーの障壁
誰が私たちが書いたコードを並べ替えることができますか? プロセッサがこれを実行できることがわかりました。 しかし、並べ替えの別のソース-コンパイラがあります。
最適化(特にグローバル)およびヒューリスティックの多くの方法が、シングルスレッド実行の仮定(おそらく暗黙的)の下で開発されました(そしてまだ開発中です)。 コードがマルチスレッドであることをコンパイラーが理解するのはかなり難しい(むしろ、理論的には不可能です)。 したがって、コンパイラにはヒントが必要です-障壁。 このようなバリアはコンパイラに伝えます。バリアの
前のコードをバリアの
後ろのコード
に移動(混合)させないでください。 コンパイラバリア自体はコードを生成しません。
MS Visual C ++の場合、コンパイラバリアは擬似関数
_ReadWriteBarrier() (この名前は常に私を困惑させました:読み取り/書き込みメモリバリアとの完全な関連付け-最も重いメモリバリア)。 GCCおよびClangの場合、
洗練されたデザインです
__asm__ __volatile__ ( "" ::: "memory" )
アセンブラー
__asm__ __volatile__ ( … )挿入は、何らかの方法でGCC / Clangに対する障壁でもあることに注意してください:コンパイラーは、コード内でそれらをスローまたは上下に移動する権利を持ちません(
__volatile__修飾子はこれを言います)。
memory_orderは、プロセッサと同様にC ++ 11をサポートするコンパイラーに影響を与えます。これらはコンパイラーの障壁であり、コンパイラーがコードを並べ替える(つまり最適化する)能力を制限します。 したがって、もちろんコンパイラが新しい標準を完全にサポートしていない限り、特別なコンパイラバリアを指定する必要はありません。

シーケンシャル一貫性
ロックフリースタック(これはロックフリーデータ構造の最も単純なもの)を実装し、コンパイルしてテストしたとします。 そして、剥離(コアファイル)を取得します。 元気? ロックフリースタックを行ごとに実装し、マルチスレッドをエミュレートして、ストリーム1の行Kとストリーム2の行Nを同時に実行する致命的な組み合わせに疑問を投げかけ、エラーを探し始めます(デバッガーはここでは役に立ちません)。崩壊。 いくつかのエラーを見つけて修正するかもしれませんが、とにかく-ロックフリーのスタックは落ちます。 なんで?
エラーを見つけて、同時に実行されているスレッドについてプログラムの行を比較することを試みることは、
順次一貫性保証と呼ばれます。 これは厳密なメモリモデルであり、プロセッサがプログラムで記述された
順序ですべてを正確に実行することを前提としています。 たとえば、次のようなコードの場合:
順次一貫性に有効なのは、
a.store / b.loadと
x.load / y.storeを交換するスクリプトを除く、すべての実行スクリプト
x.load / y.store 。 このコードでは、load / storeで
memory_order引数を明示的に
memory_orderいないことに注意してください。デフォルトの引数値に依存しています。
コンパイラーにはまったく同じ保証が適用されます:コンパイラーは
、 memory_order_seq_cst 後の memory_order_seq_cstがこのバリアの上に移動するようにコードを並べ替えることは禁じられており、その逆も同様です-seq_cst-barrierの
前の操作はバリアの下で省略できません。
シーケンシャル整合性モデルは直感的に人間に近いものですが、非常に重大な欠点があります。これは、最新のプロセッサには厳密すぎるということです。 プロセッサが投機的実行を完全に使用することを許可しない、最も厳しいメモリバリアにつながります。 そのため、新しいC ++標準ではこのような妥協案が採用されました。
- 順次一貫性モデルは、厳密さと明確さのために、アトミック操作のデフォルトモデルとして使用する必要があります。
- 他のより弱いメモリモデルをC ++に導入して、最新のアーキテクチャの可能性を実現する
順次一貫性に加えて、取得/解放セマンティクスに基づくモデルが提案されました。
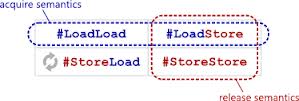
セマンティクスの取得/解放
名前の取得-リリースのセマンティクスから、このセマンティクスはリソースの取得(取得)およびリリース(リリース)に何らかの関係があると結論付けることができます。 確かにそうです。 リソースをキャプチャすると、メモリからレジスタに読み込まれ、解放するとレジスタからメモリに書き込まれます。
load memory, register ; membar #LoadLoad | #LoadStore ;
ご覧のとおり、このコードでは、重い障壁
#StoreLoad 。 また、acquire-barrierとrelease-barrierはどちらもセミバリアであることに気付くことができます
。acquireは後続のロード/ストアで以前のストア操作を順序付けせず、releaseは後続のロード/ストアで以前のロードを順序付けしません。 。 これは、プロセッサとコンパイラの両方に適用されます。
取得/リリースは
、取得/リリース
間に囲まれたすべてのコードに対する障壁です。 獲得バリアがリークする
前の一部の操作(プロセッサまたはコンパイラによって並べ替え可能)が獲得/リリースセクション内にあり
、リリースバリアが上に移動した
後の一部の操作が(再びプロセッサまたはコンパイラによって)獲得/リリース内にある場合がありますセクション。 ただし、acquire-release内で完了した操作はそれを超えることはありません。
おそらく、取得/解放セマンティクスを適用する最も単純な例はスピンロックです。
ロックフリーおよびスピンロックロックフリーアルゴリズムに関するサイクルの記事で、ロックアルゴリズムの例を挙げているのは奇妙に思えるかもしれません。 説明する必要があります。
いずれにしても、私は純粋なロックフリーの熱烈なファンではありません。 はい、完全なロックフリー(さらに待機フリー)アルゴリズムは私を幸せにし、実装されることがわかった場合は二重に幸せになります(これは常に起こるとは限りません)。 私は実用的なアプローチを支持しています。効果的なものはすべて良いです。 したがって、私は、利益をもたらすことができるロックを適用することを軽disしません。 スピンロックは、ごく小さなコード、つまり数個のアセンブラー命令を「保護」する場合、通常のミューテックスと比較して大きな利点を提供できます。 さらに、スピンロックは、その単純さにもかかわらず、あらゆる種類の興味深い最適化の尽きることのないソースです。
これは、取得/解放時に最も単純なスピンロックのように見えます(C ++の専門家は、特殊なタイプの
atomic_flagを使用してスピンロックを実装する必要があることを指摘しますが、アトミック変数(ブール値ではなく)にスピンロックを構築します-これの観点からはより視覚的です記事):
class spin_lock { atomic<unsigned int> m_spin ; public: spin_lock(): m_spin(0) {} ~spin_lock() { assert( m_spin.load(memory_order_relaxed) == 0);} void lock() { unsigned int nCur; do { nCur = 0; } while ( !m_spin.compare_exchange_weak( nCur, 1, memory_order_acquire )); } void unlock() { m_spin.store( 0, memory_order_release ); } };
このコードでは、
compare_exchangeが参照によってその最初の引数を受け入れ、CASが失敗した場合にそれを変更するという事実は、本当に私を悩ますことに注意してください! 空でない本体で
do-whileループを作成する
do-whileます。
lockをマスターする
lockメソッドでは、取得セマンティクスを使用し、
unlockメソッドではリリースセマンティクスを使用します(ちなみに、取得/リリースセマンティクスは、同期プリミティブから歴史を取りました。標準の開発者は、さまざまな同期プリミティブの実装を慎重に分析し、取得/リリースパターンを導き出しました。 )上で書いたように、この場合に置かれた障壁は、
lock()と
unlock()間に囲まれたコードが漏れることを許可しません-これが必要なものです! また、
m_spin変数の
原子性により、 m_spin m_spin=1である限り、誰もロックを取得できないことが保証されます。
アルゴリズムでは、
compare_exchange_weakを
compare_exchange_weakていることがわかります。 これは何ですか

弱く強力なCAS
覚えているように、プロセッサアーキテクチャは2つのクラスのいずれかに属することができます。プロセッサは、アトミックプリミティブCAS(比較とスワップ)を実装するか、LL / SCペア(ロードリンク/ストア条件付き)のいずれかです。 LL / SCペアを使用すると、アトミックCASを実装できますが、それ自体は多くの理由でアトミックではありません。 これらの理由の1つは、LL / SC内で実行されているコードがオペレーティングシステムによって中断される可能性があることです。 たとえば、OSが現在のスレッドを混雑させることを決定するのはこの時点です。 したがって、ストア条件付きの場合、再開後は機能しません。 つまり、CASは
falseを返し
falseが、実際にはこの
falseの理由はデータではなく、サードパーティのイベント(スレッドの中断)にある可能性があります。
この考慮事項により、標準の開発者は2つの
compare_exchangeプリミティブ(弱および強)を導入するようになりました。 これらのプリミティブは
compare_exchange_strong compare_exchange_weakおよび
compare_exchange_strongと呼ばれ
compare_exchange_strong 。 弱いバージョン
は失敗する
可能性があります。つまり、変数の現在の値が予想される値と等しい場合でも
false返し
false 。 つまり、弱いCASはCASのセマンティクスに違反し、実際に
trueを返す必要がある場合に
falseを返す
trueができ
true (ただし、その逆はできません!)。強力なCASはこれを行えません。CASのセマンティクスに厳密に従います。 もちろん、何か価値があるかもしれません。
弱いCASを使用する必要がある場合と、強力なCASを使用する場合 私はこのルールを思い付きました:CASがループで使用され(これがCASを使用するための主なパターンであり)、ループ内に操作がない場合(つまり、ループの本体が軽い場合)、
compare_exchange_weak -weak CASを使用します。 それ以外の場合、強い
compare_exchange_strong 。
獲得/解放セマンティクスのメモリ順序
上で述べたように、次の
memory_order値は、取得/解放セマンティクスのために定義されています。
memory_order_acquirememory_order_consumememory_order_releasememory_order_acq_rel
読み込み(ロード)の場合、有効な値は
memory_order_acquireおよび
memory_order_consumeです。
書き込み用(ストア)
memory_order_releaseのみ。
Memory_order_acq_relはRMW操作
fetch_xxx 、
exchange 、
fetch_xxxに対してのみ有効です。 一般に、アトミックRMWプリミティブは、
memory_order_acquire取得セマンティクス、
memory_order_acquireリリースセマンティクス
memory_order_releaseまたはその両方である
memory_order_acq_relを持つことができます。 RMW操作の場合、read-modify-writeプリミティブがアトミックな読み取りと書き込みを同時に実行するため、これらの定数が
セマンティクスを決定します。 意味的には、RMW操作は、取得の読み取り、リリースのレコード、またはその両方と見なすことができます。
RMW操作のセマンティクスは、適用されるアルゴリズムでのみ決定できます。 多くの場合、ロックフリーアルゴリズムでは、スピンロックに多少似ている部分を区別できます。最初に特定のリソースを取得(取得)し、何かを実行(通常は新しい値を計算)し、最後にリソースに新しい値を設定(解放)します。 リソースの取得がRMW操作(通常はCAS)によって実行される場合、そのような操作はセマンティクスを取得する可能性があります。 新しい値の設定がRMWプリミティブ(CASまたは
exchange )によって実行される場合、ほとんどの場合、リリースセマンティクスがあります。 「かなり可能性が高い」という理由が挿入されています。RMW操作に適したセマンティクスを理解するには、アルゴリズムの詳細な分析が必要です。
RMWプリミティブが個別に実行される場合(取得/解放パターンを分離することは不可能です)、セマンティクスの3つのオプションが可能です。
memory_order_seq_cst -RMW操作はアルゴリズムの重要な要素です。コードを並べ替え、読み取りと書き込みを上下に移動するとエラーが発生する可能性がありますmemory_order_acq_rel - memory_order_seq_cstに似ていmemory_order_seq_cstが、RMW操作は取得/解放セクション内にありますmemory_order_relaxed -RMW操作(そのロード部分とストア部分)をコードの上下に移動しても(たとえば、操作がそのようなセクション内にある場合、取得/解放セクション内で)エラーになりません
これらのすべてのヒントは、RMWプリミティブに1つまたは別のセマンティクスを掛けるためのいくつかの一般原則を概説する試みとしてのみとるべきです。 各アルゴリズムについて詳細な分析を実行する必要があります。
セマンティクスを消費する
個別の、より弱い、取得セマンティクスの種類があります-消費読み取りセマンティクスです。 このセマンティクスは、DEC Alphaプロセッサの「賛辞」として導入されました。
アルファアーキテクチャには、他の最新のアーキテクチャとは大きな違いがあります。データの依存関係を壊す可能性があります。 このコード例では:
struct foo { int x; int y; } ; atomic<foo *> pFoo ; foo * p = pFoo.load( memory_order_relaxed ); int x = p->x;
彼女は、
p->x読みを並べ替えて、実際に
p取得できます(これがどのように可能かを聞かないでください-これ
は Alpha
プロパティです。Alphaを操作する必要がないため、確認も拒否もできません)。
この並べ替えを防ぐために、消費セマンティクスが導入されました。 構造体へのポインタのアトミックな読み取りに適用でき、その後に構造体のフィールドを読み取ります。 この例では、
pFooポインターは次のようになります。
foo * p = pFoo.load( memory_order_consume ); int x = p->x;
セマンティクスは、読み取りのリラックスしたセマンティクスと獲得したセマンティクスの中間にあります。 多くの現代建築では、リラックスした読書に対応しています。
そして再びCASについて
上記では、2つのCASを使用した
atomic<T>インターフェースを示しました-弱いものと強いものです。 実際、CASにはさらに2つのバリアントがあり、追加の引数
memory_orderます。
bool compare_exchange_weak(T&, T, memory_order successOrder, memory_order failedOrder ); bool compare_exchange_strong(T&, T, memory_order successOrder, memory_order failedOrder );
この引数
failedOrderとは何ですか?
CASは読み取り-変更-書き込みプリミティブであることを思い出してください。 障害が発生した場合でも、アトミック読み取りを実行します。
failedOrder引数は、CASが失敗した場合のこの読み取りのセマンティクスを定義するだけです。 通常の読み取りと同じ値がサポートされています。
実際には、「失敗時のセマンティクス」の表示はほとんど必要ありません。 もちろん、すべてアルゴリズムに依存しています!
緩和されたセマンティクス
最後に、3番目のタイプのアトミック操作モデルは緩和されたセマンティクスであり、これはすべてのアトミックプリミティブ(ロード、ストア、すべてのRMW)に適用可能であり、
ほとんど制限を課さないため、プロセッサーは
ほぼ完全に並べ替えることができ、そのフルパワーを発揮します。 なぜほとんど?
まず、標準の要件は、リラックスした操作の
原子性を観察することです。 つまり、リラックスした操作でさえ、部分的な効果を伴わずに分割できないはずです。
第二に、投機的録音はアトミックリラックス録音の標準では禁止されています。
これらの要件は、いくつかの弱く順序付けられたアーキテクチャでのアトミックな緩和操作の実装に制限を課す場合があります。 たとえば、Intel Itaniumのアトミック変数の緩和されたロードは、
load.acqとして実装され
load.acq (読み取りを取得します
load.acq取得とC ++の取得を混同しないでください)。
Itaniumのレクイエム私の記事では、Intel Itaniumについてよく言及しています。 あなたは、私がItaniumアーキテクチャのファンであるという印象を得るかもしれません。 いいえ、私はファンではありませんが...
Itanium VLIWアーキテクチャは、コマンドシステムの構築原理が他のアーキテクチャとは多少異なります。 メモリの順序は、ロード/ストア/ RMW命令の接尾辞として示されますが、これは他の最新のアーキテクチャには当てはまりません。 使用、取得、リリースなどの用語でさえ、C ++ 11がItaniumから廃止されていないことを示唆しています。
話を思い出すと、Itaniumは、AMDが時間内に大騒ぎせず、64ビットx86拡張機能であるAMD64をリリースしなかった場合に私たち全員が座っているアーキテクチャ(またはその子孫)です。 当時のインテルは、64ビットコンピューティング用の新しいアーキテクチャを徐々に開発していました。 そして、この新しいアーキテクチャについて漠然とほのめかした。 ヒントから、デスクトップ上のItaniumが私たちを待っていることを理解することができました。 ちなみに、Microsoft Windowsへの移植とItanium用のVisual C ++コンパイラもこれを間接的に証言しています(誰もがitaniumでWindowsが動作しているのを見たことがありますか?) Itaniumはサーバーセグメントにとどまり、開発のための適切なリソースを取得できず、ゆっくりと死にかけていました。
一方、「非常に長い命令語」(VLIW-非常に長い命令語)の命令の「束」を持つItaniumは、依然として興味深く画期的なプロセッサです。 Itaniumでは、最新のプロセッサ自体が実行するもの-実行ユニットをロードし、操作を並べ替える-はコンパイラに委ねられました。 しかし、コンパイラーはそのようなタスクに対処できず、最適なコードではない生成(および生成)を行うことができませんでした。 その結果、Itaniumのパフォーマンスは数回低下しました。そして、VLIWの「バンドル」に関する指示の不合理な(Itaniumの観点からの)配布のみにより(Itaniumで何と呼ばれているのか覚えていませんが、翻訳-「バンドル」は記憶されていました)実行ブロックの不合理なロード。
Itanium – .
, , , ?..
Happens-before, synchronized-with
, C++11, : « , , — happened before, synchronized-with ?»
– .
C++ Concurrency in Action (
), . .
– () C++, ,
. C++.
, ,
memory_order - lock-free . sequential consistency – -
memory_order - . , .
– acquire/release relaxed – .
UPD:
cheremin . , sequential consistency , — . : lock-free , , —
.

lock-free
—
relacy . , . , lock-free relacy ( ? – , , , ). , ,
memory_order -, production- .
lock-free , — , . , .
( «» – , , - ) ( ), — , .
, relacy, , ( – relacy ), Intel – , (relacy - ) . . - safe iterators STL.
Google
ThreadSanitizer . data race ( ) , , , . , STL, — (Clang 3.2,
GCC 4.8 ).
ThreadSanitizer – , — .
libcds , ,
libcds .
x86x86, , (weakly-ordered) . , lock-free : , x86, .
, memory_order - null ( nop!), — x86 . , release- – mov , mov relaxed-.
lock-free , , x86- - .
« ...» —
, C++11! , ,
. - :
template <typename T> class atomic { template <memory_order Order = memory_order_seq_cst> T load() const ; template <memory_order Order = memory_order_seq_cst> void store( T val ) ; template <memory_order SuccessOrder = memory_order_seq_cst> bool compare_exchange_weak( T& expected, T desired ) ;
, , .
, , . [] . , , (, , , release- ). . , :
extern std::memory_order currentOrder ; std::Atomic<unsigned int> atomicInt ; atomicInt.store( 42, currentOrder ) ;
C++11. , , , :
- , — , ?
- sequential consistent – « ».
currentOrder , , - switch/case
currentOrder . - . , — release- acquire-
.
memory_order . , :
std::Atomic<int> atomicInt ; atomicInt.store<std::memory_order_release>( 42 ) ;
, , «» , — .
C++11 , , — C.
std::atomic C++11 C-
atomic_load ,
atomic_store .
, libcds , C++11 , . , - , libcds C++11.
–
.

« ». , - …
“ ” – lock-free .