はじめに
皆さんはおそらく、ロシア公共イニシアチブ(
www.roi.ru )の現象を覚えているでしょう。これは、連邦政府の人が州によって宣言されたオンライン請願の署名を収集するためのイニシアチブです。 請願書の1年で10万票が集められた場合、その請願書は当局によって正式に検討されると想定されています。 また、法案のステータスを取得する機会があります。
同時に、6つの請願書がすでにそのようなフィルターを通過してい
ます。https://www.roi.ru/complete/の 2つは、10万票の収集と4つの請願書の投票数が少なく、実際に通過しましたが、当局はどうにか反応しました。
そして、請願書はいかなる決定も行われることを保証するものではありませんが、多くは肯定的な解決策を期待するだけでなく、「メディアの議題」に問題を置くためにそれらを作成します。そして、公共の状態の反応があるでしょう。
したがって、これまでのところ、ROIは州のプロジェクトの最後ではなく、それに関心があります。 さらに、ROIには多くの欠点と問題があります。
ROIの問題
ESIA(政府サービス)による承認
これについてはすでに多くのことが書かれています-もちろん、承認により、数十万人の人々が公共サービスへの登録を開始し、投票できるようになりましたが、それは何らかの方法で障害となります。 整理するのはそれほど簡単ではなく、今のところすべての市民がそのような登録をしているわけではありません。 たとえば、携帯電話番号を参照してオンライン登録を手配できます。
これはまだ克服できない制限です。
オープンデータとAPI
ROIは、多くの人々にとって、請願だけでなく一般的な請願にも関心があります。 嘆願書は、市民が心配していることや、どの問題がすべての人に最も影響を与えているかを理解したい人にとって興味深い資料です。
多くのタスクにはオープンデータが必要です。
- イニシアチブを追跡するためのモバイルアプリ
- 視覚化および分析用
- イニシアチブの成功/失敗を予測する
- イニシアチブを促進し、それらに注意を引くためのサービスを作成する
データ収集
ROI用の本格的なAPIの作成を開始する前に、そこから情報のコレクションをモデル化することから始め、Github-
API for ROIにこのような短いドキュメントを書きました。
システム内にあり、理論的に抽出できる基本概念を事前にペイントした場所。
そしてすぐに制限を明らかにしました:
- 賛成/反対の投票は、承認されたユーザーのみが利用できます。 公共サービスを介した認可を考えると、これは特定の制限を課します。 もちろん、認可は乗り越えられますが、これまでのところ、そのような制限のないデータを「額で」収集しています。
- データは、請願ページの請願の説明と請願のリストに分けられます。 リストには投票に関するデータが含まれており、ページで既に書いたように、投票に関するデータは承認された場合にのみ利用できます。
データをダウンロードするために、嘆願書のリストとそのページからデータを抽出する小さなスクリプトを作成し、それらを1つの一般的な説明にまとめました。 MongoDBがストレージとして使用されました。 ここでダウンロードして見ることができます
-github.com/ivbeg/apiroi/blob/master/scripts/data_extract.pyスクリプトは可能な限りシンプルであり、もちろん、定期的に嘆願書を更新し、すぐに単一の形式にコンパイルするために徹底的に変更されます。
データは非常に迅速に収集されました-文字通り数時間かかりました。 パーサーの記述方法については詳しく説明しません。これは非常に単純なケースであり、驚くことはありません。
取得したデータは、GitHubの
github.com/ivbeg/apiroi/tree/master/scripts/data/rawおよびオープンデータハブ
-hubofdata.ru/dataset/roi-dumpで利用できるようになりました。
それで、データは収集されます、次は何ですか?
データの分析
最終的な目標はそれを取得することなので、この投稿をAPI投稿と呼びました。 ただし、それを実行している間、APIを最も便利かつ方法にする方法と、そこにデータを含めて、収集したデータに基づいて追加のデータスライスを作成する必要があるかどうかを理解できます。 結局のところ、APIはデータを返すためのAPIであるだけでなく、APIはより多くのタスクを実行できます。
まず、視覚化に便利なデータから何を抽出できるかを考えましょう。 APIのコンシューマーがメディアであり、それらを視覚化したいと想定します。
面白いかもしれないものについて私に思いついたいくつかの考えがあります:
1.イニシアチブが10万票を獲得する可能性を理解する。
2.イニシアチブに対する投票の強度を評価します。
3.最も「投票された著者」を特定する
4.最もリクエストの多いトピックを特定します。
実際、これがすべてだと判断するために、data_process.pyスクリプトが作成され、githubにあり、その助けにより上記のインジケーターが計算されました。
データフォルダ内-
洗練された-JSONでの予備計算の結果。
イニシアチブに合格する可能性を評価する方法は? 理想的には、イニシアチブが存在する期間全体および日ごとに投票統計の詳細を取得することが望ましいですが、理想的な状況はなく、そのような詳細はイニシアチブの作成者のみが利用できます。
それまでの間、予測式は非常に単純です。 次の式により、潜在的に投票できる人の数を計算できます。
投票+(投票/(調査日秒-開始日秒))*(終了日秒-調査日秒)- 投票-データ取得日の投票数
- probe_date_seconds-秒単位のデータサンプリングの日付
- start_date_seconds-請願の発行日(秒)
- end_date_seconds-請願情報収集の完了日(秒単位)
言い換えれば、人々は以前に投票したのと同じ方法で投票し、投票の分布はほぼ均一になるという仮定からすべてが考慮されます。 もちろん、これはほとんどの場合そうではなく、イニシエーターのメディアアクティビティに大きく依存しますが、初期の近似値は与えます。
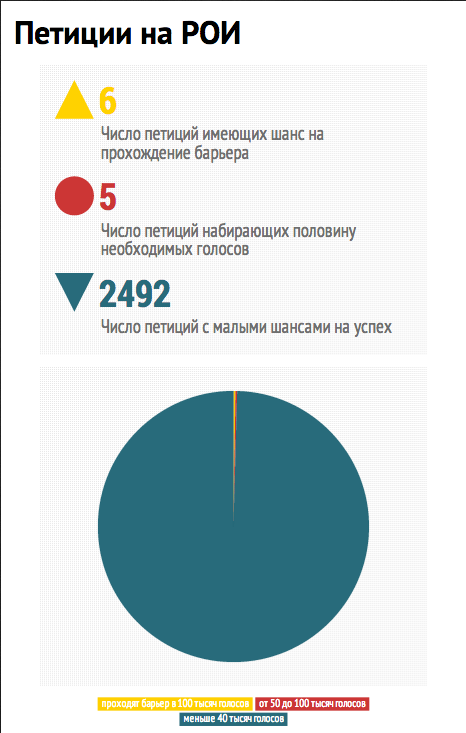
そのため、最初の分析では、スクリーンショットに示されているものの写真が示されました。

それが判明します:
- 最大10万票を獲得した6つの請願書
- 5つの請願書は最大5万票を獲得します
- 残りの2492の請願書はこれさえも受け取りません
- そして1641年の請願書は、おそらくピックアップされず、そのうちの1,000票
または同じ写真
ここから、APIに多くの追加機能を含めることが有用であると結論付けました。
- 請願の成功/失敗の可能性を調整するために、投票履歴全体の保存を想定する必要があります
- 請願書の成功を計算できるようにする必要があります
- 現在、リンクを使用して操作することは完全に不便であるため、請願ごとにリンク短縮サービスが必要です。
- RSSフィードオプションが必要
- などなど
ROIの作成者自身が、APIとデータの観点からROIをオープンにする努力をしていないのは残念です。
しかし、最初のステップが実行されたという事実のおかげで-最初のデータのアップロードがあり、アップロード用のスクリプトの例があり、誰でもそのようなAPIを実行できるようになりました。 後続の投稿では、これについてさらに詳しく説明します。