この記事では、
読者の問題で定式化された質問に答えたいと思い
ます。 天国はどこか近くにありますか? 。 一番下の行は次のとおりです。 テキストメッセージを受信するシステムがあり、各メッセージのテキストに関連する一連のウィキセージを作成する必要があります。 「バラク・オバマがプーチンと会った」というテキストがあるとしましょう。 出力には、Wikipediaページ「Barack Obama」および「Putin V.V」へのリンクが含まれている必要があります。 可能なアルゴリズムの1つを説明します。
そしてそうしましょう
freq(A)-Wikipediaページのテキスト内のフレーズ
Aのリンクまたはプレーンテキストとしての出現頻度。 つまり、
A =“ Santa Claus”としましょう。 次に、
freq(「サンタクロース」)は、特定のテキストがWikipediaページに表示される回数です。 当然、さまざまな形式を考慮する必要があります。これには、レマタイズまたはステミングのアルゴリズムの1つを使用します。
リンク(A) -Wikipediaページ上のリンクとしてのフレーズ
Aの出現頻度。
link(サンタクロース) -このフレーズがすべてのwikiページで何回リンクされているか。
リンク(A)<= freq(A) -これは明らかだと思います。
lp(A)=リンク(A)/周波数(A) -Aがリンクである確率。 つまり、一般的に
Aはテキスト内のWikificationの候補と見なされるべきです。
Pg(A) -テキスト
Aリンクを
持つリンク先のすべてのウィキペディアページ。
link(p、A) -ページ
Aへのテキスト
Aリンクを
持つリンクの回数。
P(p | A)は、
Aがページ
pにリンクする確率です。
リンク(p、A)/ Pg(A)として計算されます。 テキスト
Aの注釈は、確率
P(p | A)に直接依存します
計算
リンク(A)と
lp(A)でプレートを作成します。 次に、
link(A)<2または
lp(A)<0.1のすべての要素を破棄します。残った要素はlinkP辞書を形成します。 この辞書に基づいて、テキストからフレーズを選択します。 独自に設定できるしきい値。 しきい値が高いほど、バイクフィケーションの候補が少なくなります。 したがって、構築前に、すべての
Aは初期形式に還元可能です。
しかし、
P(p | A)のみを操作する場合、意味はコンテキストに大きく依存するため、結果は疑わしくなります。 これを行うには、Wikipediaページの依存関係に関するデータが必要です。
すべてのページについて、Googleの距離に基づいて依存関係を計算します。
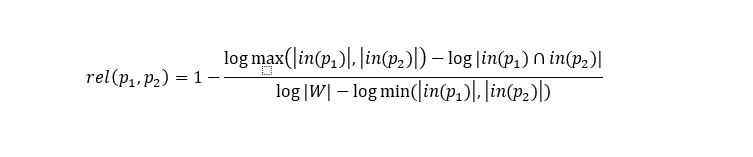 (p)に
(p)には、
pにリンクするページのセットがあります
| W | -ウィキペディアのページ数。 係数が特定のしきい値よりも大きいページのペアに対してこのデータを保存します。
前述のように、多くの点でフレーズに関連付けるページはコンテキストに依存するため、コンテキストの影響を計算します。
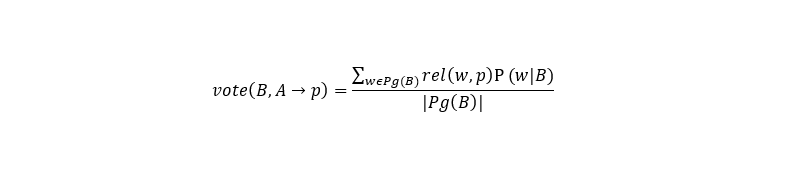
ここで、
B、AはWikiページで比較する必要があるテキストから抽出されたフレーズで、
pはWikiページ、
Aの一致オプションです
。 一般的な選択式は次のとおりです。
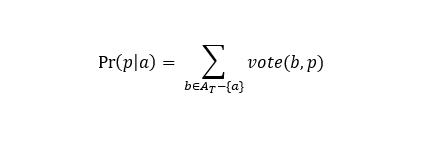 a
aがページ
pと一致
しなければならない可能性、At-テキスト
Aの強調表示されたフレーズ(一致するページの候補)。
一般に、アルゴリズムの手順は次のとおりです。
- 結果のテキストはトークン化され、Steamになります。
- N個までのすべてのフレーズを割り当てます(リソースの可用性の計算から選択します)。
- linkP辞書でハイライトされたフレーズの存在を探します(Wikipediaで見つかったすべてのリンクテキストは、しきい値を超えている可能性があります)。 テキストから選択されたフレーズを形成し、 linkP辞書で見つけます。
- 辞書linkPと部分文字列bの両方で、a、bが顕著なフレーズである場合、 lp(a)<lp(b)であれば、 lp(a)とlp(b)を比較します。 したがって、 a = "apple" b = "apple computers"の場合を取り除きます。 lp(a)> = lp(b)の場合、 freq(a)およびfreq(b)を見てください 。 freq(a)> freq(b)の場合、ほとんどの場合、 aは無意味な要素であり、それも取り除きます。
- 各フレーズに対して、 P(p | a)> 0 (合計確率、 aはAtに属する)に基づいて、比較のための候補のセットを構築します。 つまり、利用可能なすべての一致オプションが見つかります。
- コンパイルされたセットに基づいてPr(p | a)を計算します。
- 各aに対して最大のPr(p | a)を持つpを選択します。
このアルゴリズムを実装するには、次の表が必要です。
linkP-テキストからWikification候補を強調表示するのに役立ちます。
- A-ウィキペディアでリンクとして見つかったフレーズ。
- lp(A) ;
- freq(A) 。
共通 -ページのコロケーションに一致するオプション、および基本式を計算するオプションを検索します。
- A-ウィキペディアでリンクとして見つかったフレーズ。
- p-ウィキペディアページのID。
- P(p | A)は、 Aがページpにリンクする確率です。
関連 -基本的な数式を計算します。
- Wikiページp1 ;
- Wikiページp2 ;
- rel(p1、p2) 。
おわりに
アルゴリズム自体は非常に単純ですが、実装が困難になります。 特に、保存されているデータのサイズは非常に大きいため、検索には最小限の時間がかかります。 実装の1つでは、luceneを使用したメモリインデックスの構築が満たされ、その後、これらのインデックスで検索が実行されました。 主な問題は、関連テーブルでの作業です。 データベースにデータを保存する場合、テキスト処理にはかなり長い時間がかかります。メモリに保存する場合、かなりの量のメモリが必要になります。
私が出会ったすべてのWikificationアルゴリズムは、上記の原則に基づいて構築されましたが、わずかな違いがあります。 ニューラルネットワークを使用した実装を見るのは面白いでしょうが、そのような仕事を見たことはありません。