こんにちは、読者の皆様。 本日の投稿では、
Pandasモジュールを使用してPythonでのデータ分析に関する一連の記事を続け、このモジュールを
scikit-learn機械学習
モジュールと組み合わせて使用するためのオプションの1つについて説明し
ます 。 このバンドルの
作業は、タイタニック号から救出された
タスクの例で示されます。 このタスクは、データ分析と
機械学習に従事し始めたばかりの人々の間で非常に人気があります。
問題の声明
そのため、タスクの本質は、機械学習法を使用して、人が救われるかどうかを予測するモデルを構築することです。 2つのファイルがタスクに添付されます。
- train.csv-モデルの構築に基づくデータセット( トレーニングセット )
- test.csv-モデル検証用のデータセット
上記で書いたように、分析にはPandasとscikit-learnモジュールが必要です。
Pandasを使用して、データの初期分析を行い、
sklearnは予測モデルの計算に役立ちます。 したがって、まず最初に、必要なモジュールをロードします。
さらに、いくつかのフィールドについて説明します。
- PassengerId-乗客ID
- Survival-人が保存されているフィールド(1)または保存されていない(0)
- Pclass-社会経済的状況が含まれます:
- 高い
- 平均的
- 低い
- 名前 -乗客名
- セックス -乗客の性別
- 年齢 -年齢
- SibSp -2次(親、妻、兄弟、セット)の親relativeの数に関する情報が含まれています
- パーチ -一次船内の親relativeの数に関する情報が含まれています(母、父、子供)
- チケット -チケット番号
- 運賃 -チケット価格
- キャビン -キャビン
- 乗船 -着陸の港
- C-シェルブール
- Q-クイーンズタウン
- S-サウサンプトン
入力分析
>それで、タスクが形成され、それを解決し始めることができます。
最初に、テストサンプルを読み込み、その外観を確認します。
from pandas import read_csv, DataFrame, Series data = read_csv('Kaggle_Titanic/Data/train.csv')
| PassengerId | 生き残った | Pclass | お名前 | 性別 | 年齢 | シブス | パーチ | チケット | 遠い | キャビン | 乗船 |
|---|
| 1 | 0 | 3 | ブラウン、ミスター オーウェン・ハリス | 男性 | 22 | 1 | 0 | A / 5 21171 | 7.2500 | ナン | S |
| 2 | 1 | 1 | カミングス、夫人 ジョン・ブラッドリー(フィレンツェ・ブリッグス... | 女性 | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | ヘイキネン、ミス。 ライナ | 女性 | 26 | 0 | 0 | STON / O2。 3101282 | 7.9250 | ナン | S |
| 4 | 1 | 1 | フトレル夫人 ジャック・ヒース(リリー・メイ・ピール) | 女性 | 35 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | アレンさん ウィリアム・ヘンリー | 男性 | 35 | 0 | 0 | 373450 | 8.0500 | ナン | S |
社会的地位が高ければ高いほど、救われる可能性が高くなると考えられます。 クラスの内訳に応じて、生存者とand死者の数を見て、これを確認しましょう。 これを行うには、次の要約を作成します。
data.pivot_table('PassengerId', 'Pclass', 'Survived', 'count').plot(kind='bar', stacked=True)
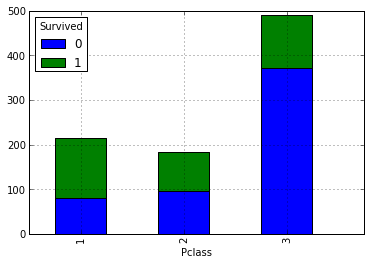
上記の仮定は、乗客の社会的地位が高いほど、救われる可能性が高いということです。 では、親relativeの数が救いの事実にどのように影響するかを見てみましょう。
fig, axes = plt.subplots(ncols=2) data.pivot_table('PassengerId', ['SibSp'], 'Survived', 'count').plot(ax=axes[0], title='SibSp') data.pivot_table('PassengerId', ['Parch'], 'Survived', 'count').plot(ax=axes[1], title='Parch')
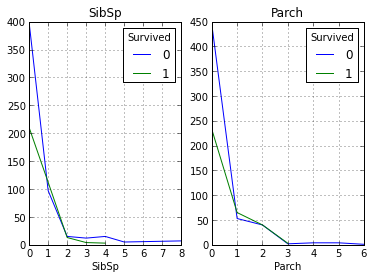
グラフからわかるように、私たちの仮定は再び確認され、2人以上の親withを持つ人々から救われた人は多くありませんでした。
次に、キャビンの数であるデータについて説明します。 理論的には、ユーザーキャビンに関するデータがない可能性があるため、このフィールドがどのくらい埋められているかを見てみましょう。
data.PassengerId[data.Cabin.notnull()].count()
その結果、合計204エントリと890エントリが入力されました。これに基づいて、このフィールドは分析中に省略できると結論付けることができます。
次に分析するフィールドは、年齢のあるフィールドです。 それがどれだけ満たされているか見てみましょう:
data.PassengerId[data.Age.notnull()].count()
このフィールドはほぼ完成しています(空ではない714エントリ)が、定義されていない空の値があります。 サンプル全体の年齢の中央値に等しい値を与えましょう。 このステップは、モデルをより正確に構築するために必要です。
data.Age = data.Age.median()
チケット 、
乗船 、
運賃 、
名前の各フィールドを処理する必要があります。 乗船港がある乗船フィールドを見て、港が指定されていない乗客がいるかどうかを確認しましょう。
data[data.Embarked.isnull()]
| PassengerId | 生き残った | Pclass | お名前 | 性別 | 年齢 | シブス | パーチ | チケット | 遠い | キャビン | 乗船 |
|---|
| 62 | 1 | 1 | アイカード、ミス。 アメリ | 女性 | 28 | 0 | 0 | 113572 | 80 | B28 | ナン |
| 830 | 1 | 1 | ストーン夫人 ジョージ・ネルソン(マーサ・エブリン) | 女性 | 28 | 0 | 0 | 113572 | 80 | B28 | ナン |
そのため、このような乗客が2人いました。 これらの乗客に、村の人が最も多い港を割り当てましょう。
MaxPassEmbarked = data.groupby('Embarked').count()['PassengerId'] data.Embarked[data.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
さて、もう1つのフィールドを見つけましたが、現在は乗客の名前、チケット番号、チケット価格のフィールドがあります。
実際、これら3つのフィールドの価格(
Fare )のみが必要です。 ある程度、
Pclassフィールドのクラス内のランキングを決定します。 つまり、たとえば、中流階級内の人々は、最初の(上)クラスに近い人と、3番目(下)のクラスに近い人に分けることができます。 このフィールドに空の値がないかどうかを確認し、値がある場合は、価格をすべてのサンプルの価格の中央値に置き換えます。
data.PassengerId[data.Fare.isnull()]
この場合、空のエントリはありません。
また、チケット番号と乗客の名前は参考情報にすぎないため、役に立ちません。 彼らが便利になる唯一の理由は、どの乗客が潜在的に親relativeであるかを決定することですが、親haveを持っている人はほとんど生き残っていないため(上記を参照)、これらのデータは無視できます。
不要なフィールドをすべて削除した後、セットは次のようになります。
data = data.drop(['PassengerId','Name','Ticket','Cabin'],axis=1)
| 生き残った | Pclass | 性別 | 年齢 | シブス | パーチ | 遠い | 乗船 |
|---|
| 0 | 3 | 男性 | 28 | 1 | 0 | 7.2500 | S |
| 1 | 1 | 女性 | 28 | 1 | 0 | 71.2833 | C |
| 1 | 3 | 女性 | 28 | 0 | 0 | 7.9250 | S |
| 1 | 1 | 女性 | 28 | 1 | 0 | 53.1000 | S |
| 0 | 3 | 男性 | 28 | 0 | 0 | 8.0500 | S |
入力前処理
データの予備分析が完了し、その結果によると、いくつかのフィールドを含む特定のサンプルが得られました。1つの「しかし」ではない場合、モデルの構築を進めることができるようです。データには数値データだけでなくテキストデータも含まれています。
したがって、モデルを構築する前に、すべてのテキスト値をエンコードする必要があります。
これは手動で行うことも、
sklearn.preprocessingモジュールを使用することもできます。 2番目のオプションを使用しましょう。
LabelEncoder()オブジェクトを使用して、固定値でリストをエンコードできます。 この関数の本質は、入力でエンコードする必要のある値のリストを受け取り、出力でインデックスが入力に与えられたリストの要素のコードであるクラスのリストがあることです。
from sklearn.preprocessing import LabelEncoder label = LabelEncoder() dicts = {} label.fit(data.Sex.drop_duplicates())
その結果、初期データは次のようになります。
| 生き残った | Pclass | 性別 | 年齢 | シブス | パーチ | 遠い | 乗船 |
|---|
| 0 | 3 | 1 | 28 | 1 | 0 | 7.2500 | 2 |
| 1 | 1 | 0 | 28 | 1 | 0 | 71.2833 | 0 |
| 1 | 3 | 0 | 28 | 0 | 0 | 7.9250 | 2 |
| 1 | 1 | 0 | 28 | 1 | 0 | 53.1000 | 2 |
| 0 | 3 | 1 | 28 | 0 | 0 | 8.0500 | 2 |
次に、検証ファイルを必要なフォームに取り込むためのコードを記述する必要があります。 これを行うには、上記のコードを単純にコピーします(または単に入力ファイルを処理する関数を作成します)。
test = read_csv('Kaggle_Titanic/Data/test.csv') test.Age[test.Age.isnull()] = test.Age.mean() test.Fare[test.Fare.isnull()] = test.Fare.median()
上記のコードは、トレーニングサンプルで実行した操作とほぼ同じ操作を実行します。 違いは、
運賃フィールドが突然満たされなかった場合に、
運賃フィールドを処理するために行が追加されたことです。
| Pclass | 性別 | 年齢 | シブス | パーチ | 遠い | 乗船 |
|---|
| 3 | 1 | 34.5 | 0 | 0 | 7.8292 | 1 |
| 3 | 0 | 47.0 | 1 | 0 | 7.0000 | 2 |
| 2 | 1 | 62.0 | 0 | 0 | 9.6875 | 1 |
| 3 | 1 | 27.0 | 0 | 0 | 8.6625 | 2 |
| 3 | 0 | 22.0 | 1 | 1 | 12.2875 | 2 |
分類モデルの構築とその分析
さて、データは処理され、モデルの構築を開始できますが、最初に、結果のモデルの精度を確認する方法を決定する必要があります。 このテストでは、
スライドコントロールと
ROC曲線を使用し
ます 。 トレーニングサンプルで検証を実行した後、テストサンプルに適用します。
それでは、いくつかの機械学習アルゴリズムを見てみましょう。
必要なライブラリをダウンロードします。
from sklearn import cross_validation, svm from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve, auc import pylab as pl
まず、トレーニングサンプルを、調査中のインジケーターとその定義サインに分割する必要があります。
target = data.Survived train = data.drop(['Survived'], axis=1)
これで、トレーニングセットは次のようになります。
| Pclass | 性別 | 年齢 | シブス | パーチ | 遠い | 乗船 |
|---|
| 3 | 1 | 28 | 1 | 0 | 7.2500 | 2 |
| 1 | 0 | 28 | 1 | 0 | 71.2833 | 0 |
| 3 | 0 | 28 | 0 | 0 | 7.9250 | 2 |
| 1 | 0 | 28 | 1 | 0 | 53.1000 | 2 |
| 3 | 1 | 28 | 0 | 0 | 8.0500 | 2 |
ROC曲線を計算するために、以前に取得したインジケーターを2つのサブサンプル(トレーニングとテスト)に分割します(検証関数がこれを行うため、ローリング制御にこれを行う必要はありません
。cross_validationモジュールの
train_test_split関数がこれに
役立ちます:
ROCtrainTRN, ROCtestTRN, ROCtrainTRG, ROCtestTRG = cross_validation.train_test_split(train, target, test_size=0.25)
次のパラメーターが渡されます。
- パラメータの配列
- インジケーター値の配列
- トレーニングサンプルが分割される比率(この場合、初期トレーニングサンプルのデータの1/4がテストセットに割り当てられます)
出力では、関数は4つの配列を返します。
- 新しいトレーニングパラメーター配列
- パラメータのテスト配列
- インジケーターの新しい配列
- インジケーターのテスト配列
以下は、実験的に選択された最適なパラメーターを使用してリストされたメソッドです。
model_rfc = RandomForestClassifier(n_estimators = 70)
次に、スライディングコントロールを使用して、取得したモデルを確認します。 これを行うには、cross_val_score関数を使用する必要があります
scores = cross_validation.cross_val_score(model_rfc, train, target, cv = kfold) itog_val['RandomForestClassifier'] = scores.mean() scores = cross_validation.cross_val_score(model_knc, train, target, cv = kfold) itog_val['KNeighborsClassifier'] = scores.mean() scores = cross_validation.cross_val_score(model_lr, train, target, cv = kfold) itog_val['LogisticRegression'] = scores.mean() scores = cross_validation.cross_val_score(model_svc, train, target, cv = kfold) itog_val['SVC'] = scores.mean()
各モデルの平均交差検定テストスコアのグラフを見てみましょう。
DataFrame.from_dict(data = itog_val, orient='index').plot(kind='bar', legend=False)
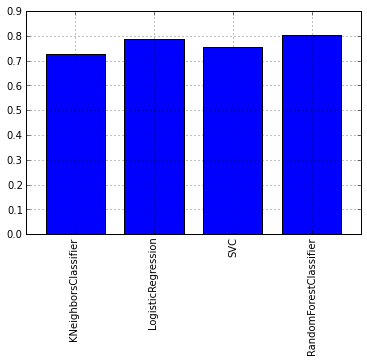
グラフからわかるように、RandomForestアルゴリズムは最高の結果を示しました。 次に、ROC曲線のグラフを見て、分類器の精度を評価しましょう。
matplotlibライブラリを使用してグラフを描画します。
pl.clf() plt.figure(figsize=(8,6))
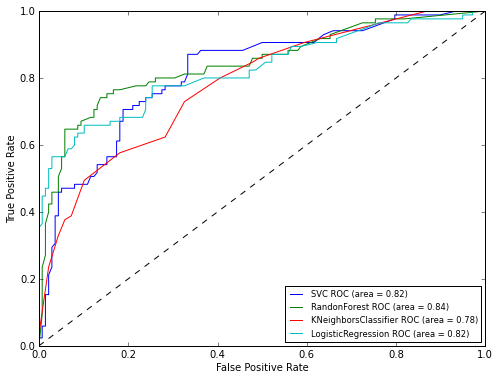
ROC分析の結果からわかるように、RandomForestによって再び最高の結果が示されました。 これで、モデルをテストサンプルに適用するだけになります。
model_rfc.fit(train, target) result.insert(1,'Survived', model_rfc.predict(test)) result.to_csv('Kaggle_Titanic/Result/test.csv', index=False)
おわりに
この記事では、
sklearn機械学習
パッケージと一緒に
pandasパッケージを使用する方法を示しました。 Kaggleで提出された結果のモデルは、0.77033の精度を示しました。 この記事では、たとえば
このシリーズの記事のように、詳細なアルゴリズムを構築するのではなく、ツールと研究の進行状況をより正確に示したいと思いました。