この記事は、Cassandraデータベースに最初の「テーブル」を作成しようとする人々を対象としています。Cassandraのいくつかのリリースを投稿するために、開発者はこのデータベースの使いやすさを目的とした適切なベクトルを採用しました。 速度やフォールトトレランスなどの利点を考えると、管理と書き込みを行うことは困難でした。 開発を開始して開始する前に行う必要のあるタンバリンとのダンスの数が最小限に抑えられました-bashのいくつかのコマンドまたはWindowsの1つの.msi。
さらに、最近更新されたCQL(クエリ言語)により、開発者は作業が楽になり、バイナリのやや複雑な言語のThriftに取って代わりました。
個人的には、カッサンドラに関するロシア語のガイドラインがないという問題に直面しました。 私の意見では、この記事で取り上げたい最も難しいトピックです。
データベースを設計する方法は?免責事項
- この記事は、カサンドラという言葉を最初に目にした人を対象としていません。
- この記事は、特定の技術の広告資料としては機能しません。
- この記事は、誰にも何も証明しようとはしていません。
- 書き込み/読み取り速度がそれほど重要ではなく、「100%の稼働時間」が本当に必要ない場合、そして数百万のレコードしかない場合、おそらくこの記事とCassandra全体があなたのものではないでしょう。する必要があります。
教育プログラム
- Cassandra (以降、 C * )は分散NoSQLデータベースです。したがって、「なぜ、そうではないのか」というすべての決定は、常にクラスタリングを考慮して行われます。
- CQLはSQLに似た言語です。 C assandra Q uery L anguageの略語。
- ノードはC *インスタンス、またはオペレーティングシステムの観点からはJavaプロセスです。 たとえば、同じマシン上で複数のノードを実行できます。
- 基本的なストレージユニットは文字列です。 文字列全体がノードに保存されます。 半分の行が1つのノードにあり、半分の行が別のノードにあるという状況はありません。 行は20億列に動的に拡張できます。 これは重要です。
- cqlsh -CQLのコマンドライン。 以下のすべての例が実行されます。 C *ディストリビューションの一部です。
Cの基本的なデータモデリングルール*
Kassandraは、最大の書き込みおよび読み取り速度を重視した分散データベースとして作成されました。
アプリケーションのSELECTクエリに応じて「テーブル」をモデル化する必要があります 。
SQLでは、テーブル、テーブル間の関係、および
SELECT ... JOIN ...して、必要なものと方法をスローすることに慣れています。 結合は、RDBMSのパフォーマンスに関する主な問題です。 CQLにはありません。
最初の例。
ある会社の従業員がいます。 CQLでテーブル(実際には列ファミリと呼ばれますが、SQLからCQLへの移行を簡単にするためにwordテーブルを使用)を作成し、データを入力します。
CREATE TABLE employees ( name text,
C *のテーブルには、PRIMARY KEYが必要です。 目的の文字列が保存されているノードを検索するために使用されます。
データを読み取ります。
SELECT * FROM employees;
この写真は、手で装飾されたcqlsh出力です。

リレーショナルデータベースからの通常のテーブルのように見えます。 C *は2行を作成します。

注意! これらはテーブルではなく、2つの
内部行構造です。 少しcな場合、各行は小さなテーブルのようなものであると言えます。 さらに明確。
2番目の例。
複雑です。 会社名を追加します。
CREATE TABLE employees ( company text, name text, age int, role text, PRIMARY KEY (company,name)
データを読む:
SELECT * FROM employees;

主キーに注意してください。
最初のパラメータ-
company -は
配布キーであり、それ以降はノードの検索に使用されます。 2番目の
name キーはクラスタリングキーです。 彼は柱になります。 つまり データを列名に変換します。 通常の4バイトでは「エリック」で、列名の一部になりました。
これが、
内部構造の外観です。

ご覧のとおり:
OSCとRKG 2社。 ここでは2行のみが作成されました。- グリーン
ericは、2つのセルでその年齢と役割を保存します。 同様に、他の皆。 - このような構造では、各企業(行)に10億人の従業員を格納できます。 列数の制限は20億であることを覚えていますか?
- 再び同じデータを保存しているように見えるかもしれません。 これは事実ですが、C *では、そのような設計は正しいモデリングパターンです。
- C *でモデリングするときの主な機能は、文字列の展開です。
3番目の例。
さらに難しい。 大文字は列の名前です。 小文字-データ。
CREATE TABLE example ( A text, B text, C text, D text, E text, F text, PRIMARY KEY ((A,B), C, D));
データを読み取ります。
SELECT * FROM example;
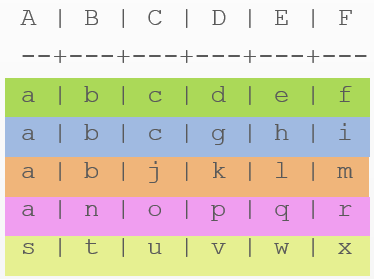
これで、
配布キーはcomposite-
(A,B)です。 クラスターキーもコンポジット-C、Dです。
内部構造はより複雑になりました。
c, d, g, k, o, p, u, vなどのデータは、EおよびFとともに列名に含まれます。
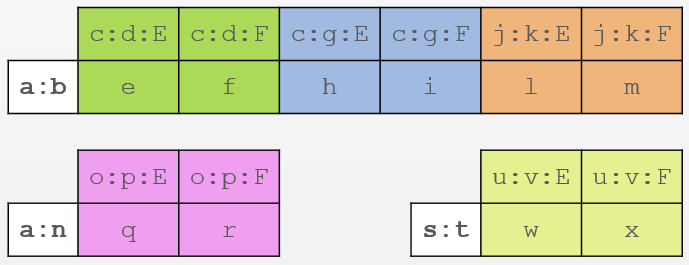
- ご覧のとおり、AとBの一意の組み合わせがそれぞれ文字列のキーになっています。
- 唯一の3つの固有の配布キー-a
a:b 、 a:nおよびs:tます。 - クラスターキーのおかげで列が増えました。 行
a:bには、 c:d 、 c:g 、 j:k 3つの固有の組み合わせがあり、列EおよびFに実際のデータを格納しますeおよびf 、 hおよびi 、 lおよびm 。 - 同様に、他の2行。
なぜそんなに複雑なのですか?
これは、分散データベースに無限量のデータを記録および保存するための最速の方法です。 C *は、書き込み/読み取り速度に重点を置いて設計されました。 ここでは、たとえば、
MongoDB、HBase、およびC *速度を比較します 。
実生活の例
1秒間に1000回発生するイベントがいくつかあります。 たとえば、インジケータはノイズレベルセンサーから取得されます。 10個のセンサー。 それぞれが1秒間に100回データを送信します。 3つのタスクがあります。
- データベースサーバー(ノード)が作業を停止した場合は、書き込みを続けます。
- 何であれ、1000の新しいレコードを数秒で記録する時間。
- 数ミリ秒で任意の日のセンサーのグラフを提供します。
- 可能な限り迅速に、任意の期間の任意のセンサーのグラフを提供します。
最初と2番目のポイントは簡単です。
複数のノードをインストールし、それぞれを自律的にする必要があります。 それらの1つをクラウドに取り込むこともできます。
3番目のポイントは主要なトリックです。
1日のデータを1行で保存します。
CREATE TABLE temperature_events_by_day ( day text,
配布キーは日+センサーの一意の組み合わせであるため、1日のデータはセンサーごとに個別の行に保存されます。 文字列内の逆ソートのおかげで、「指先で」最も重要な(最後の)データを取得できます。
配布キー(日)の検索はC *では非常に高速な操作であるため、3番目のポイントは完了したと見なすことができます。
第四ポイント
もちろん、日/日検索を行うことができますが、日中はタイムスタンプを比較できます。 しかし、多くの日があります。
結局のところ、センサーは10個しかありません。 これは使用できますか? 1つのセンサーが1行であると想像するなら可能です。 この場合、C *はディスク上の10行すべての場所をメモリにキャッシュします。
2番目のテーブルを作成して、同じデータを保存しますが、日は除外します。
CREATE TABLE temperature_events ( sensor_id uuid, event_time timestamp, temperature double, PRIMARY KEY (sensor_id, event_time)
そして、データを挿入するとき、20億列に慣れないように各セルの寿命を制限します。 弊社では、各センサーが毎秒100個以下の読み取り値を提供します。 ここから:
2**31 / (24 * 60 * 60 * 100 /) = 2147483648 / (24 * 60 * 60 * 100) = 248.55248日後、最も古いデータを静かに削除する必要があります。
INSERT INTO temperature_events (sensor_id, event_time, temperature) VALUES ('12341234-1234-1234-123412', 2535726623061, 36.6) TTL 21427200;
アプリケーションコードでは、要求されたデータが過去248日間を超えた場合に
temperature_events_by_dayテーブルを使用し、そうでない場合は
temperature_events_by_dayを使用するという条件を設定する必要があります。 後者の検索は数ミリ秒高速になります。
「なんてナンセンスだ! なぜ2番目のテーブルですか?」と思うでしょう。 私は繰り返します:C *データベースでは、同じ値を数回保存するのが標準であり、正しいモデルです。 賞金は次のとおりです。
- 2番目のテーブルへのデータの書き込みは、最初のテーブルよりも高速です。 Cassandraは、新しい値を追加するノードを探す必要はありません。 彼女は事前に知っています。
- データの読み取りも非常に高速です。 たとえば、通常のインデックス付きの正規化されたSQLデータベースよりも何倍も優れています。
ソース
この順序で表示することをお勧めします。
- ウェビナー-CQL3がCassandraの内部データ構造にどのようにマッピングされるかを理解します。
- ウェビナー- データモデルは死んでいます、データモデルは長く生きています
- ウェビナー- スーパーモデラーになる
- ウェビナー- 世界の次なるトップデータモデル
- 完全なCQL3ドキュメント-Cassandra Query Language(CQL)v3
シリーズの次の記事 。
UPD:用語の修正。 適切な場所で「マスターキー」という単語を「配布キー」に置き換えました。 いくつかの場所に「クラスターキー」の概念を追加しました。