この質問をハブロフスク市民にお願いしたいです。
最新の情報システムはさまざまなタイプの
DBMSで構築されていますが、
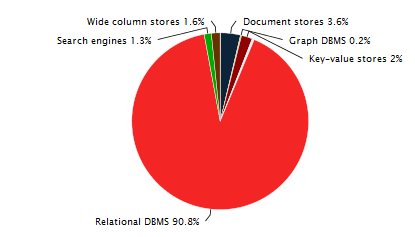
リレーショナルDBMSは依然として最も一般的で使用されています。 このトピックに関する興味深い統計は
こちらと
こちら 。
システムの開発および変更中、
アナリストおよび開発者の知識の形式化のレベルは低く (スマートクエリの作成またはいくつかの明確なルールの考慮の自動化)ままであり、ほとんどの場合、結果のSQLクエリは「通常」、「通常」、「当社で記述」、最適化の問題は、DBMSのクエリ実行の段階と、その後の最適化の段階に残ります(最悪の場合、すべてが遅くなり始めるまで待機します)。
たとえ
手動コードの量が多くても
手動での記述を回避するための多数の便利なツールの存在(ORMを含む)。 また、特に複雑なデータ分析などの非常に複雑な分析クエリに関しては、こうしたツールを常に使用できるとは限りません。 また、ORMなどのツールは、多少なりとも最近のプロジェクトで、些細なクエリにのみ使用されます。
いずれにせよ、
クエリを最適化する
必要性と、おそらくDBMSの構造は 、産業ベースで
一定です。 「完璧な」設計であっても、これを避けることはできません。 環境は変化しており、顧客自身が明日何が起こるか(法律、市場、顧客、新しいアイデアがどのように現れるかなど)を常に把握しているわけではありません。

DBMSで最適化する場合、共通のプログラミング言語のコードを最適化するとき
と同じ問題がいくつかあります。同じコードを検索および追跡し、すべての場所で新しいコード、最適化コードなどに置き換えます。そして、すべてのSQLクエリが同じであると便利です簡単な検索を行って置き換えることができます)))しかし、歴史的に、ほとんどの技術はクエリ層を別々の構造/オブジェクト/ファイル/などに分離していませんでした 最良の場合、要求は実際には別々のファイルに割り当てられます。
すべてのクエリを取得するオプションは、たとえば、SQLロガーにすることができます(ほとんどすべてのDBMSには、ビルトイン機能があるか、ネジ止めすることができます)。 ただし、この場合、すべての要求を受信する期間を選択する必要があります(たとえば、1年)。これには長い時間がかかります(通常の企業では、ほぼすべての基本操作が1年で行われます)。パラメーターを決定する問題は未解決のままです。
ここ、Habré、およびロシア語のインターネット。 と英語。 言語にはクエリの最適化とDBMS構造に関する情報が多数ありますが、その後の最適化のためにすべてのクエリを分析するというトピックに関する資料は実際には十分ではありません。 そして、このための分析的で自動化されたツールのより多くの推奨事項については、私は見つけませんでした...
Khabrovskの住人である私に、アプリケーションSQLクエリの全集団の包括的な分析に会ったことがありますか?私の意見では
、SQLクエリの構造を包括的に分析する主な理由は
3つあります 。
1.
コードの最適化 :重複コードを強調表示し、最適化中に重複コードを置き換え、コード構造を改善するためのさまざまな自動ヒントを発行します。
2.
コードのリファクタリング (この場合の最適化は必須の効果ではありません)。
3.
科学的関心 、たとえば、後続の研究のための産業システムのSQLフォレストの分析、たとえば、DBMSの動作を最適化するための新しいアルゴリズムを分析するSQLクエリフォレストのシミュレーション。
私の意見では、このような分析を利用できると、DBMSの最適化アルゴリズムに取り組んでいる多くのプログラマーと一部の科学者の作業が大幅に簡素化されます。