Colossus (またはGFS2)は、2009年に
運用サーバーで発売されたGoogle独自の
分散ファイルシステムです。 コロッサスは、GFSの進化的開発です。 その前身であるGFSと同様に、Colossusは
大規模なデータセットでの作業に最適化されており、完全に拡張可能で、アクセスしやすく耐障害性のあるシステムであり、データを確実に保存することもできます。
同時に、ColossusはGFSが対処できなかった問題の一部を解決し、前身のボトルネックの一部を除去します。

なぜGFS2が必要なのですか? GFSの制限
GFS +
Google MapReduceバンドルの基本的な制限の1つ、および類似の
HDFS +
Hadoop MapReduce(クラシック)バンドル(
YARNの前)は、
バッチ処理のみに焦点を合わせていました。 ソーシャルサービス、クラウドストレージ、マップサービスなどのGoogleサービスでは、通常のバッチ処理に比べて遅延が大幅に少なくなりました。
したがって、Googleは、いくつかの種類のリクエスト
に対してほぼリアルタイムの応答をサポートする必要に直面しています。
さらに、GFSでは、チャンクのサイズは64 MBです(ただし、チャンクサイズは構成可能です)。これは一般に、Gmail、Google Docs、Google Cloud Storageサービスには適していません-チャンクに割り当てられたスペースのほとんどは
未使用のままです。
チャンクのサイズを小さくすると
、ファイルからチャンクへのマッピングが保存される
メタデータテーブルが自動的に
増加します。 そして以来:
- アクセス、関連性のサポート、およびメタデータの複製は、マスターサーバーの責任です。
- GFSでは、HDFSと同様に、メタデータはサーバーのRAMに完全にロードされ、
GFSクラスターごとに1つのマスターが、多数のチャンクを持つ分散ファイルシステムの
潜在的なボトルネックであることは明らかです。
さらに、最新のサービスは地理的に分散しています。 地理的分布により、不可抗力時にサービスが引き続き利用できるようにし、コンテンツを要求したユーザーへのコンテンツの配信時間を短縮できます。 しかし、[1]で説明されているGFSアーキテクチャは、古典的な「マスター-スレーブ」アーキテクチャとして、地理的な分布の実装を意味しません(少なくとも大きなコストはありません)。
建築
(免責事項:Colossusアーキテクチャを完全に説明する単一の信頼できるソースは見つかりませんでした。そのため、アーキテクチャの説明にはギャップと仮定の両方があります。)
Colossusは、上記のGFSの問題を解決するために設計されました。 そのため
、チャンクの
サイズは 1 MB(デフォルト)
に縮小されましたが、構成可能なままでした。 メタデータテーブルを維持するために必要なRAMの量に対するマスターサーバーの増加する要件は、新しい
「マルチセル」指向の Colossus
アーキテクチャによって満たされました。
そのため、コロッサスには、論理
サーバーに分割された
マスターサーバーの
プールとチャンクサーバーのプールがあります 。 マスターサーバーセル(セル内の最大8つのマスターサーバー)とチャンクサーバーのセルの比率は1対多です。つまり、マスターサーバーの1つのセルがチャンクサーバーの1つ以上のセルにサービスを提供します。
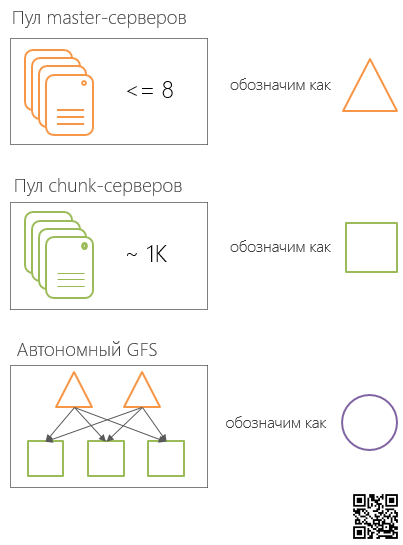
データセンター内では、グループ、マスターサーバーセル、およびそれによって制御されるチャンクサーバーセルが、(このタイプの他のグループとは独立した)
自律ファイルシステムを形成します(以下、SCI、
スタンドアロンColossusインスタンスと呼びます)。 このようなSCIは複数のGoogleデータセンターにあり、特別に設計されたプロトコルを介して相互に作用します。
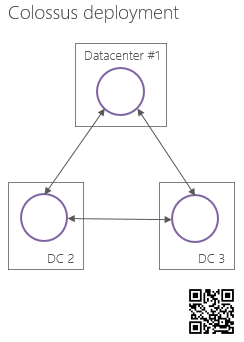
なぜなら Googleのエンジニアによるオープンアクセスの詳細なColossus内部デバイスはないため
、 SCIとマスターサーバーセル内の両方で
競合問題を解決する方法は明確ではありません。
同輩の間の闘争を解決する伝統的な方法の1つは
サーバの定足数です 。 しかし、クォーラムに偶数の参加者がいる場合、クォーラムが何にも到達しない場合、状況は除外されません。半分は「賛成」、半分は「反対」です。 また、巨像に関する情報では、マスターサーバーセルに最大8つのノードが存在する可能性が非常に高いため、クォーラムの助けを借りて競合を解決することが問題になります。
また
、あるSCIが別のSCIがどのデータを処理するかをどのように知るかは完全に不明です。 SCIにそのようなタイトルがないと仮定した場合、これはこの知識が持つべきであることを意味します。
- クライアント(より可能性は低い);
- (条件付き)スーパーマスター(これも単一障害点です);
- または、この情報(本質的に重要な状態 )は、すべてのSCIによって共有されるストレージに配置する必要があります。 ここでは、予想どおり、ロック、トランザクション、レプリケーションの問題があります。 後者は、PaxosDB、またはPaxosアルゴリズム(または同様の)を実装するリポジトリによって正常に処理されます。
一般に、巨像は全体として、ペタバイトのデータで動作する地理的に分散したファイルシステムを構築するための「明確なアーキテクチャ」よりも「ブラックボックス」である可能性が高くなります。
おわりに
ご覧のとおり、Colossusの変更は、チャンクからクラスター構成まで、前身のファイルシステム(GFS)のほとんどすべての要素に影響しました。 同時に、GFSで具現化されたアイデアと概念の連続性は維持されます。Colossusの最も優れた顧客の1つは、Googleの最新の検索エンジンインフラストラクチャであるCaffeineです。
ソースのリスト*
[1] Sanjay Ghemawat、Howard Gobioff、Shun-Tak Leung。 Googleファイルシステム。 ACM SIGOPSオペレーティングシステムレビュー、2003。
[10] Andrew Fikes。 ストレージアーキテクチャと課題。 Googleファカルティサミット、2010年。
*サイクルの準備に使用される
ソースの完全なリスト 。
ドミトリーペトホフ、
MCP、
博士課程学生 、ITゾンビ、
赤血球の代わりにカフェインを持つ人。