Photonは、スケーラブルで復元力があり、地理的に分散された
リアルタイムストリーミング処理システムです。 このシステムはGoogleの内部製品であり、Google Advertising Systemで使用されています。 Photonの基本原理とアーキテクチャを説明する研究論文[5]が2013 ACM SIGMOD科学会議で発表されました。
論文[5]は、システムの
ピーク負荷は
1分間に数百万のイベントであり、平均エンドツーエンド遅延は10秒未満であると述べてい
ます 。
*タイトルの「光の速度」
は、誇張の
あからさまな嘘です 。

Photonは非常に具体的な問題を解決し
ます。2つの連続したデータストリームをリアルタイムで接続(結合操作を実行)する必要があります。 したがって、すでに述べたGoogle Advertising Systemでは、これらのストリームの1つは検索クエリのストリームであり、もう1つは広告のクリックのストリームです。
Photonは
地理的に分散したシステムであり
、インフラストラクチャの劣化のケースを自動的に処理できます。 データセンターの障害。 地理的に分散したシステムでは、メッセージの配信時間を保証することは非常に困難です(主にネットワークの遅延のため)。Photonは、処理されたストリーミングデータが時間順でない可能性があると想定します。
使用されるサービス: Googleファイルシステム 、PaxosDB、TrueTime。
基本原則
[5]では、Photonの原理が次のコンテキストで説明されています。ユーザーが時間t1で検索
クエリを入力し、時間t2で広告をクリック(
クリック )し
ます 。 同じ文脈で、特に明記しない限り、この記事ではPhotonの仕組みを説明します。
結合スレッド(
join )の原理は、RDBMSの世界から採用されてい
ます。クエリストリームには一意の識別子
query_id (条件付きプライマリキー)があり、
クリックストリームには一意の識別子
click_idがあり、query_id(条件付き外部キー)が含まれます。 スレッドの結合はquery_idによって行われます。
次の重要なポイント:1回のクリックイベントが2回カウントされる、または逆にカウントされない状況は、それぞれ広告主による訴訟またはGoogleからの利益の損失につながります。 ここから、
最大1回のイベント処理セマンティクスを提供することが重要です。
もう1つの要件は、
ほぼ正確なセマンティクスを提供することです。 そのため、ほとんどのイベントはクローズリアルタイムモードでカウントされます。 リアルタイムでカウントされないイベントは、カウントする必要があります-
正確に1回のセマンティクス。
さらに、異なるデータセンターで動作するPhotonインスタンスには、
同期状態が必要です(より正確には、DC間では状態全体が複製するには「高すぎる」ため、重要な状態のみです)。 そのため、同期された
クリティカル状態が event_id (実際にはclick_id)
に選択されました。 クリティカルな状態は
IdRegistry構造(
PaxosDBに基づくメモリ内のキーと値のストレージ)に保存され
ます 。
後者のPaxosDB
は、Paxosアルゴリズムを実装して
、フォールトトレランスとデータの一貫性をサポートします 。
顧客とのやり取り
ワーカーノードは、
クライアントサーバーモデルでIdRegistryと対話し
ます 。 アーキテクチャ上、WorkerノードとIdRegistryの
相互作用は、非同期メッセージのキューとのネットワーク相互作用です。
クライアント-ワーカーノード-IdRegistryのみに送信します1)event_idを検索する要求(event_idが見つかった場合、それは既に処理されています)および2)event_idを挿入する要求(手順1でevent_idが見つからなかった場合) サーバー側では、要求はRPCハンドラーによって受信されます。RPCハンドラーの目的は、要求をキューに入れることです。 要求のキューから、特別な
レジストリスレッドプロセス(シングルトン)がそれを取得し、PaxosDBに書き込み
、クライアント
へのコールバックを開始
します。
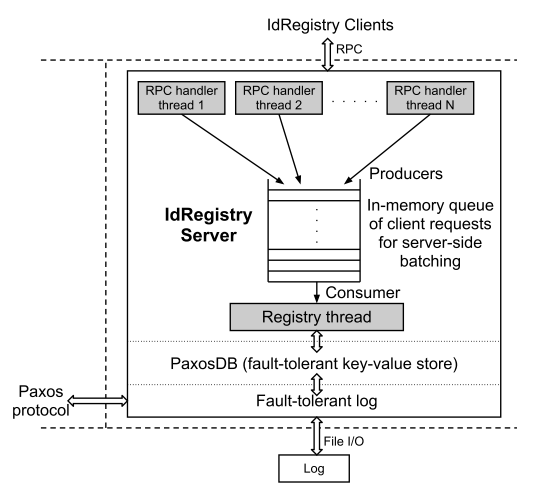
イラストのソース[5、図3]
拡張性
なぜなら IdRegistryレプリカは地理的領域間で発生し、
ネットワーク遅延は100ミリ秒に達する可能性があります [5]。これにより、IdRegistryのスループットは1秒あたり10連続トランザクション(event_idコミット)に自動的に制限されますが、IdRegistryの要件は1秒あたり10Kトランザクションでした。 しかし、定足数での競合解決をサポートして、地理的分布および/または同期的にクリティカルな状態のレプリケーションを拒否することもできません。
次に、Googleのエンジニアは、DBMSの世界の多くの人に馴染みのある2つのプラクティスを紹介しました。
- リクエストの バッチ処理 (「 バッチ処理 」) -event_idの 「有用な」情報は100バイト未満です。 要求は、バッチでIdRegistryクライアントに送信されます。 そこで、それらはインメモリキューに分類され、レジストリスレッドプロセスが解析し、キュー内に同じevent_idを持つ複数の要素が存在する可能性があるという事実に関連する競合を解決します。
- タイムスタンプベースのシャーディング (+ 動的リ シャーディング )-すべてのevent_idは範囲で分割されます。 各範囲のトランザクションは、特定のIdRegistryに送信されます。
バッチ送信リクエストにはマイナス面があります:セマンティクスの混合(Photonは
リアルタイムデータを処理し、その一部は
バッチモードで動作します)に加えて、バッチスクリプトは少数のイベントを持つシステムには適していません-完全なパケットの収集時間はかなりの間隔を取ることができます時間。
コンポーネント
1つのDCのフレームワーク内で、次のコンポーネントが区別されます。
- EventStore-クエリ(検索エンジンの検索クエリのストリーム)で効果的な検索を提供します。
- ディスパッチャー -広告のクリックのフローを読み取り(クリック)、読み取ったジョイナーを転送(フィード)します。
- Joinerは、Dispatcherからの要求を受け入れ、処理し、クエリに参加し、ストリームをクリックするステートレスRPCサーバーです。
レコードを追加するためのアルゴリズムは次のとおりです。
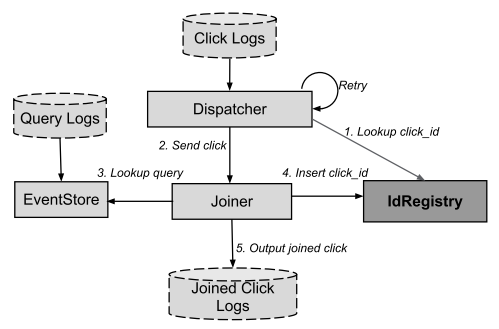
イラストのソース[5、図5]
DC間の相互作用:

イラストのソース[5、図6]
Joined Click Logsにエントリを追加するアルゴリズムを省略します。これは、ネットワーク操作が頻繁に発生するシステムの操作で
再試行ポリシーと
非同期呼び出しを使用することは、一般的な操作アルゴリズムを複雑にすることなく、それぞれシステムの信頼性とスケーラビリティを高める非常に効果的な方法であることに注意して
ください 。
Photonの作成者は、同じ手法(再試行ポリシーと非同期呼び出し)を使用しました。
クエリ再試行ロジック前述したように、click_idが処理のために受信され、それに関連付けられたquery_idが存在しない状況は例外ではありません。 これは、コードがコンテキスト広告のクリックのフローの処理を開始するまでに、検索クエリのフローが必ずしも処理されないためです。
すべてのclick_idに対して少なくとも1回の処理セマンティクスを確実に提供するために、上記のケースの繰り返しロジックを使用するロジックが導入されました。 システム自体のスロットルを回避するために、失敗したリクエスト間の時間は指数関数的に増加します-指数バックオフアルゴリズム。 多数のリクエストが失敗した後、または特定の時間が経過すると、クリックは「参加不可」としてマークされます。
ディスパッチャー
Dispatcher-クリックログの読み取りを担当するプロセス-クリック。 これらのログはGFSに保存され、時間とともに継続的に増加します。
それらを効果的に読み取るために、Dispatcherは定期的にログでディレクトリをスキャンし、新しいファイルや変更されたファイルを識別し、各ファイルの状態をローカルGFSセルに保存します。 この状態には、
ファイルのリストと、すでに処理されたデータ
のファイルの先頭からのシフト が含まれます。 したがって、ファイルが変更されると、ファイルは最初からではなく、最後の読み取りで処理が終了した瞬間から減算されます。
新しいデータの処理は、それぞれが状態を共有する複数のプロセスによって並行して実行され
ます 。これにより、異なるプロセス
が同じファイルの異なる部分でシームレスに動作できるようになり
ます 。
ジョイナー
Joinerは、Dispatcherからの要求を受け入れるステートレスRPCサーバーの実装です。 Dispatcherからのリクエストを受け入れると、Joinerはそこからclick_idとquery_idを抽出します。 次に、query_idによって、EventStoreから情報を取得しようとします。
成功した場合、EventStoreは、処理するクリックに一致する検索クエリを返します。
次に、Joinerは(IdRegistryを使用して)重複を削除し、結合された値(結合されたクリックログ)を含む出力ログを生成します。
Dispatcherが再試行ロジックを使用して障害を処理した場合、GoogleエンジニアはJoinerに別のトリックを追加しました。 JoinerがIdRegistryにリクエストを送信すると、受信が機能します。 後者はclick_idを正常に登録しましたが、ネットワークの問題またはタイムアウトにより、JoinerはIdRegistryから成功応答を受信しませんでした。
これを行うには、JoinerがIdRegistryに送信する各click_idコミットリクエストに特別なトークンが関連付けられます。 トークンはIdRegistryに保存されます。 IdRegistryから応答を受信しなかった場合、Joinerは前の要求と同じトークンを使用して要求を繰り返し、IdRegistryは着信要求が既に処理されたことを簡単に「理解」します。
一意のトークン生成/ Event_Id注目すべき別の興味深いトリックは、一意のevent_idを生成する方法です。
明らかに、event_idの一意性の保証は、Photonが機能するために不可欠な要件です。 同時に、複数のDC内で一意の値を生成するアルゴリズムは、非常に多くの時間とCPUリソースを消費します。
Googleのエンジニアは、エレガントなソリューションを見つけました。このイベントが生成されたホストのホストIP(ServerIP)、プロセスId(ProcessId)、およびタイムスタンプ(Timestamp)を使用してevent_idを一意に識別できます。
Spannerと同様に、異なるノードでのタイムスタンプの不整合を最小限に抑えるためにTrueTime APIが使用されます。
イベントストア
EventStoreは、query_idを入力として受け取り、対応するクエリ(検索クエリに関する情報)を返すサービスです。
PhotonにはEventStoreの2つの実装があります。
- CacheEventStore-分散[ハッシュ(query_id)によるシャーディング]メモリ内ストレージ。クエリに関する完全な情報が保存されます。 したがって、要求への応答にはディスクからの読み取りは必要ありません。
- LogsEventStoreはキーと値のストレージです。キーはquery_idで、値は対応するクエリに関する情報とこのファイルのバイトオフセットを格納するログファイルの名前です。
Photonはほぼリアルタイムモードで動作するため、CacheEventStoreでクエリを見つける可能性(最小限の遅延でクエリに入る場合)が非常に高く、CacheEventStore自体が比較的小さなイベントを保存できることを確信できます。時間の経過。
研究論文[5]では、リクエストの10%のみがメモリ内キャッシュを「通過」し、それに応じてLogsEventStoreによって処理されるという統計を提供しています。
結果
構成
出版時点[5]、すなわち 2013年、IdRegistryレプリカは
3つの地理的地域 (東、西海岸、北米中西部)の
5つのデータセンターに展開さ
れ 、地域間のネットワーク遅延は
100ミリ秒を超えました 。 Photonの他のコンポーネントは、Dispatcher、Joinerなどです。 -米国の西海岸と東海岸の2つの地理的地域に展開されています。
各DCでは、IdRegistryシャードの数が100を超え、DispatcherおよびJoinerプロセスのインスタンスの数が数千を超えています。
性能
Photonは、ピーク時に
1分あたり数百万のイベントを含め、1日あたり数十億のイベントを処理します。 24時間で処理されるクリックログの量はテラバイトを超え、毎日のクエリログの量は数十テラバイトで計算されます。
すべてのイベントの90%は 、発生後
最初の7秒間に
処理されます(1つのストリームに参加します) 。
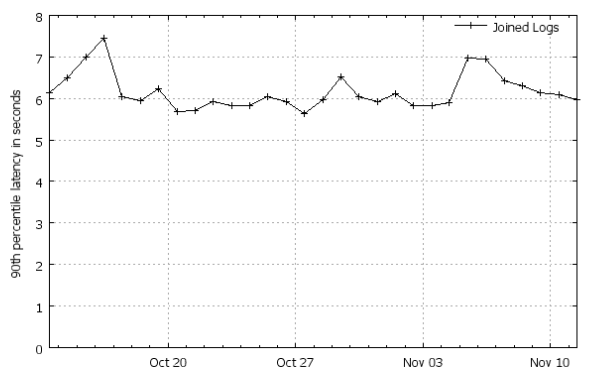
イラストのソース[5、図7]。
統計付きのその他のグラフ (スライド24〜30)。
複雑なシステムの単純な原則
「基本原則」のセクションで、Photonが1回(最低1回と1回)およびほぼ正確なセマンティクスをサポートするシステムであることを既に述べました。 ログに記録されたイベントは、リアルタイムモードに近い確率で1回だけ処理されるようにします。
PaxosDBはat-most-onceセマンティクスを実装し ますが、Dispatcher再試行ポリシーはat-least-onceセマンティクスを提供します。
ほぼリアルタイムモード(ほぼ正確なセマンティクス)でイベントを処理するために、Photonアーキテクチャでは次の原則が定められています。
- スケーラビリティ:
- 非リレーショナルストレージの必須シャーディング。
- すべてのワーカーノードはステートレスです。
- レイテンシー:
- 可能な限りRPC通信。
- 可能な限りRAMにデータを転送します。
結論として
調査論文[5]の結論として、Googleのエンジニアは優れた実践と将来の計画を共有しました。
原則は新しいものではありませんが、記事の完全性と完全性のために、それらをリストします。
- ディスクに書き込む代わりにRPC通信を使用します。 ノードの物理的な境界を越える要求は非同期で実行する必要があり、クライアントは常に、タイムアウトまたはネットワークの問題により応答を受け取らないことを期待する必要があります。
- システムの重大な状態を最小限に抑えます。 通常、同期的に複製する必要があります。 理想的には、システムのクリティカルクリティカル状態には、システムメタデータのみを含める必要があります。
- シャーディングはスケーラビリティの友人です :)しかし、Googleのエンジニアは時間ベースのシャーディングを行うことでこのアイデアを改善しました。
Photonの作成者の計画
世界を引き継ぐ クリックとクエリを生成するサーバーがRPCリクエストをJoinerに直接送信するため、エンドツーエンドの遅延を減らします(Dispatcherはこれらのイベントを「待機」しています)。 また、複数のデータストリームを結合するようにPhotonを「教える」ことも計画されています(現在の実装では、Photonは2つのストリームのみを結合できます)。
Photonの作成者の皆さんが彼らの計画を実行できることを願っています! そして、新しい研究論文を楽しみにしています!
ソースのリスト**
[5] Rajagopal Ananthanarayanan、Venkatesh Basker、Sumit Das、Ashish Gupta、Haifeng Jiang、Tianhao Qiuなど
Photon:連続データストリームのフォールトトレラントでスケーラブルな結合 、2013年。
**サイクルの準備に使用される
ソースの完全なリスト 。
変更履歴を投稿Chanset 01 [
2013/12/27 ]。
記事のイラストを変更しました。 新しいイラストをくれた
TheRavenに感謝し
ます。 オフトピック
これは、
Googleプラットフォームに関する一連の記事の最後の記事
です 。
 明けましておめでとうございます! 頑張って頑張ってください!ドミトリーペトホフ
明けましておめでとうございます! 頑張って頑張ってください!ドミトリーペトホフ 、
MCP、
博士課程学生 、ITゾンビ、
赤血球の代わりにカフェインを持つ人。