こんにちは、Habr!
私たちの会社
DM Labsが教育活動に加えてデータ分析の分野で何をしているのかを話す時が
来ました (すでにそれについて書いています
1 )。
過去1年にわたり、
ミュンヘン工科大学(TUM)の
Fortiss Institute of Roboticsと緊密に連携し
(人を殺さないようロボットに教える)、不正防止システムのプロトタイプをリリースし、国際的な機械学習会議に参加し、最も重要なことには、強力なアナリストチームを結成しました。
現在、DM Labsはすでに3つの領域を組み合わせています。研究室、既製の商用ソリューションの開発、およびトレーニングです。 本日の投稿では、それらについて詳しく説明し、過去1年間をまとめ、将来の目標を共有します。
トレーニング
教育の方向性を開始するために、私たちは若い専門家と専門家の間で知識を交換するプログラムを作成し、すでに述べたように、ロシアのデータサイエンスコミュニティの形成を支援したいと考えました。
今年、私たちは何とか学生の最初のストリームをリリースすることができました。
| 2013 | 2013/2014 |
|---|
| 学生 | 18 | 25 |
|---|
| 専門家 | 19 | 30+ |
|---|
プログラム  | 業界のデータマイニング | 業界のデータマイニング+ R、機械学習、ビッグデータの個別コース |
|---|
| 講義 | 60時間 | 業界のデータマイニング:70時間以上、コース:80時間以上 |
|---|
| 企業 | IBM、EMC、シーメンス、フォルティスなど | すべて同じ+デロイト、アクセンチュア、クラスメートなど |
|---|
カリキュラムは大きく変わりましたが、私たちの教育の哲学の根底にある3つの要素は変わらないことに気付きました。
- 専門家とのコミュニケーション。
- 練習。 学生はカグル競技に参加し、さまざまな分野の専門家が提起した問題を解決します( 1、2および3 )。
- プロアクティブ。 私たちは、学生が互いに知識を共有し、データ分析だけでなく、さまざまなトピックに関する内部セミナーを開催することに興味を持っています。
カリキュラムの継続に加えて、2014年にはさらに多くの教育イニシアチブを実施します。
- データマイニングサウナ-クリスマス休暇のために、学生と専門家をサンクトペテルブルク近郊のプライベートコンタクト動物園に招待し、非公式にアイデアを共有し、研究について話し合いました(このイベントについては後ほど詳しく説明します)。
- 現在、サンクトペテルブルクのソーシャルネットワークの分析のためのハッカソンを準備しています。
- 来年には、データマイニングに関する会議も開催したいと思います。
プロジェクト
トレーニングエリアの開始後、プロジェクトアクティビティとデータマイニングプロジェクトの新しい方向性は論理的な継続になりました。機械学習の助けを借りて、さまざまな分野で多くの興味深い問題を解決できるからです。
現在、私たちのチームは、金融取引トラフィックの分析、Webサービスのログファイルに基づく異常の検出、ユーザーリターンの予測などのさまざまな商業プロジェクトに取り組んでいます。
TechCrunch Moscowでは、企業がデータ駆動型になるのをどのように支援できるかを概説しました。
以下の記事では、プロジェクトの特定のケースと製品、詐欺防止システムについて記述します。
リサーチ
設計作業は優れていますが、データサイエンティストの魂は常により多くのことを求めています。モデルをより正確にし、アルゴリズムをより高速に動作させ、アプリケーションの分野を拡大したいのです。 そこで、第3の方向-データマイニングR&Dが作成されました。
現在、勾配ブースティングマシンに関連するさまざまなタスクに取り組んでいます[
1、2、3 ]。 これらのアルゴリズムは、Yahoo!、MatrixnetのYandex、Microsoftなどの企業で積極的に使用されて
います。 「指で」説明する場合、アルゴリズムの主なアイデアは、新しいツリーごとにアルゴリズムの合計出力がますます正確になるように一連の決定ツリーを構築することです。 たとえば、次の図のように:
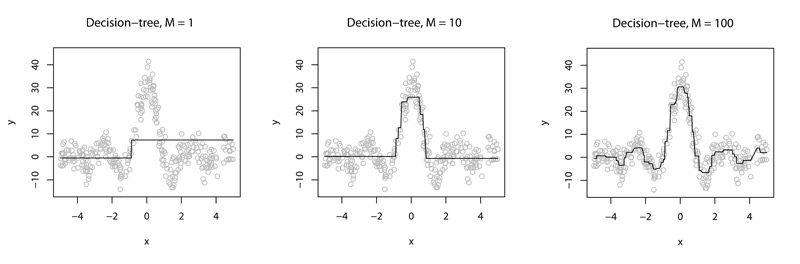
すべては単純に思えますが、創造性には大きなスコープがあります。同じ精度を達成するために必要なツリーの数を減らす方法(その数を減らす方法)。 「深い」アンサンブルを作るとどうなりますか? それとも、準「深い」ギズモのアンサンブルですか?」
作業の2番目の重要な領域は、データ融合メソッドです。 アイデアは、1つの問題を解決するフレームワーク内のさまざまな領域からのデータを使用することです:テキスト、ビデオ、オーディオ、グラフ、センサー、およびそれらのさまざまな組み合わせ。 すべてのデータに対して同じGBMアルゴリズムを「正面から」実行すると、分布が大きくなりすぎ、符号の数が不当に大きくなります。 一般に、これが機能しない理由の説明は、別の記事に値するトピックです。
この分野で私たちが遭遇した例は、金融リスクを決定するタスクでした。 このタスクでは、通常、取引所からの相場に関する定量的な情報を使用します。会社の株価のボラティリティを調べることにより、翌年のリスクをかなり正確に予測できます。 ただし、企業の年次財務諸表からの情報を考慮すると、この精度は向上する可能性があります。
主な質問は、データに含まれるすべての情報を使用するためにこれを最も効率的に行う方法ですか? 異なるデータ部分空間に構築されたモデルをステッチする方法は?
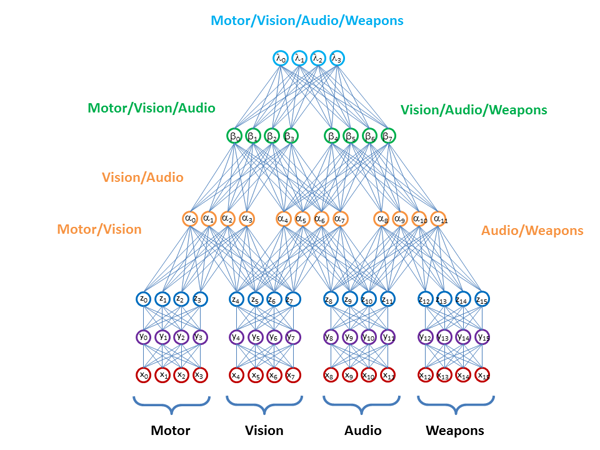
D-Waveが提案するものと同様に、ステッチモデルまたはリプレゼンテーション付きの中間層のみ
:
私たちの研究はこれで終わりではありません。 たとえば、私たちは質問について非常に心配しています。
- それらがたくさんあるときに重要な標識を選択する方法:数万と数十万?
- 大規模な異常を検索する方法は?
- 10億ポイントでGBMアルゴリズムを実行する方法は? そして、何兆? これは、SGDとミニバッチが適用されない勾配法の一般的な質問です( ICAと同様の話)
結論として
イベント、新しい善良な人々、興味深い仕事が豊富にありました。 2014年に多くの素晴らしいアイデアがもたらされ、さらに強力になり、Habrの各記事について書かれることを期待しています。 はい、すでに多くのことを伝えたいので、小規模な調査を行うことにしました