注釈
この記事では、グラフィックアクセラレータを使用したグラフでの幅検索-BFSアルゴリズムを効率的に並列化する方法を説明します。 この記事では、結果のアルゴリズムの詳細な分析を提供します。 計算は、単一のGPU GTX Titanアーキテクチャケプラーで実行されました。
はじめに
最近、グラフィックアクセラレータ(GPU)は、非グラフィックコンピューティングでますます重要な役割を果たしています。 それらの使用の必要性は、それらの比較的高い生産性と低コストによるものです。 ご存じのように、GPUでは、構造グリッドの問題は十分に解決されており、並列処理は簡単に区別できます。 ただし、大容量を必要とし、非構造グリッドを使用するタスクがあります。 このような問題の例は、単一の最短ソースパス問題(SSSP)です。これは、重み付きグラフ内の特定の頂点から他のすべての頂点までの最短パスを見つけるタスクです。
この記事では、この問題の解決策を検討しました。 非構造グリッドの問題の2番目の例は、幅優先検索(BFS)タスク-無向グラフでの幅優先検索です。 このタスクは、多くのグラフアルゴリズムの主要なタスクです。 また、最短経路を見つけるよりも少し簡単です。 現時点では、BFSアルゴリズムが
Graph500レーティングのメインテストとして使用されています。 次に、BFS問題でSSSP問題を解決するためのアイデアをどのように使用できるかを調べます。 Nvidia GPUのアーキテクチャと言及されているアルゴリズムについてはすでに多くのことが書かれているため、この記事ではこれについては追加しません。 また、ワープ、キューダブロック、SMX、およびCUDAに関連するその他の基本的な概念が読者になじみのあるものであることを願っています。
使用されるデータの形式
SSSPタスクと同様に、1つのSMXの負荷を増やし、GPUのグローバルメモリ内の同一データの量を減らすために、同じ変換を使用します。 主な違いは、BFSアルゴリズムはグラフの重みを必要としないことです。 また、最短距離ではなく、この頂点が位置するレベルの番号を保存する必要があることにも注意してください。
テスト実行後、平均接続度が32のRMATグラフのレベル数は10を超えないことがわかりました。したがって、これらの値を格納するにはunsigned charで十分です。 したがって、レベルの配列は、距離の配列よりも8倍少ないスペースを占有します。これは、ケプラーアーキテクチャのキャッシュサイズが1.5 MBしかないため、非常に重要です。
CPUでのアルゴリズムの実装
CPUでは、ネイティブバージョンの幅トラバーサルアルゴリズム、つまり、まだ見られないピークのキューの作成が実装されました。 実装CPUコードは次のとおりです。
queue<vertex_id_t> q; bool *used = new bool[G->n]; for (unsigned i = 0; i < G->n; ++i) used[i] = false; used[root] = true; q.push(root); dist[root] = 0; while (!q.empty()) { vertex_id_t nextV = q.front(); q.pop(); for (unsigned k = G->rowsIndices[nextV]; k < G->rowsIndices[nextV + 1]; ++k) { if (used[G->endV[k]] == false) { used[G->endV[k]] = true; q.push(G->endV[k]); dist[G->endV[k]] = dist[nextV] + 1; } } }
このコードは非常に単純であり、おそらく最適ではありません。 GPUでのアルゴリズムの正しい動作を検証するために使用されました。 CPUに最適なアルゴリズムを書き込むという目標はなかったため、CPUのパフォーマンスはこのアルゴリズムによって取得されます。 現時点では、多くの最適なCPU実装があり、それらは簡単に見つけることができます。 BFSアルゴリズムを実装するための他の多くのアプローチとアイデアも提案されています。
アルゴリズムのGPU実装
実装は、同じFord-Bellmanアルゴリズムに基づいており、SSSP問題のコアが考慮されました。 BFSのコアコンピューティングコアは次のようになります。
if(k < maxV) { unsigned en = endV[k]; unsigned st = startV[k]; if(levels[st] == iter) { if(levels[en] > iter) { levels_NR[en] = iter + 1; modif[0] = iter; } } else if(levels[en] == iter) { if(levels[st] > iter) { levels_NR[st] = iter + 1; modif[0] = iter; } } }
アルゴリズムの考え方は次のとおりです。 最初に、選択したタイプの最大値(unsigned charの場合は255)をレベルの配列に入力します。 現在の反復番号をカーネル-iterに渡します。 次に、すべてのエッジを調べて、開始頂点または終了頂点が現在の親であるかどうか、つまりiterレベルに属しているかどうかを確認する必要があります。 そうである場合、次の反復で親のリストにこの頂点を「含める」ために、表示されているアークの反対側の頂点にもう1つの値をマークする必要があります。 SSSPの場合と同様に、modif変数は残り、グラフのマークアップを継続する必要があることを示します。
このコードには、SSSPタスクに適用された最適化が既に含まれています。levels配列にconst __restrictを使用し、書き込みに必要な同じメモリ位置を指す別のlevels_NRリンクを使用します。 キャッシュ内のデータのローカリゼーションを改善するための2番目の順列形式の最適化も使用されました。 BFSアルゴリズムの場合、最適なラインキャッシュの長さは、グラフのサイズに関係なく、1024KB、またはレベルの配列の要素に対して約1mln(1024 * 1024)です。
結果の分析
テストには、非指向性の合成RMATグラフを使用しました。これは、ソーシャルネットワークとインターネットからの実際のグラフをうまくモデル化したものです。 グラフの平均接続性は32で、頂点の数は2の累乗です。 次の表に、テストされたグラフを示します。
| 頂点の数2 ^ N | 頂点の数 | アークの数 | レベル配列のサイズ(MB) | リブ配列サイズMB |
| 14 | 16 384 | 524,288 | > 0.125 | 2 |
| 15 | 32,768 | 1,048,576 | > 0.125 | 4 |
| 16 | 65,536 | 2,097 152 | > 0.125 | 8 |
| 17 | 131 072 | 4 194 304 | 0.125 | 16 |
| 18 | 262 144 | 8 388 608 | 0.250 | 32 |
| 19 | 524,288 | 16 777 216 | 0.5 | 64 |
| 20 | 1,048,576 | 33554432 | 1 | 128 |
| 21 | 2,097 152 | 67108864 | 2 | 256 |
| 22 | 4 194 304 | 134 217 728 | 4 | 512 |
| 23 | 8 388 608 | 268 435 456 | 8 | 1024 |
| 24 | 16 777 216 | 536 870 912 | 16 | 2048 |
レベル値を保存するために最小のデータ型を使用するため、頂点数が2
20のグラフでは、レベル配列をキャッシュするために1 MBが必要ですが、SSSPタスクの同じグラフでは、8 MBが必要です。 テストは、14個のSMXコアと2688個のCUDAコアを備えたNVidia GTX Titan GPU、および周波数3.4GHzおよび8MBキャッシュを備えた第3世代Intelコアi7プロセッサーで実行されました。 CPUのパフォーマンスを比較するために、幅優先検索アルゴリズムのネイティブ実装が使用されました。 CPUで作業する前のデータ置換の形での最適化は行われませんでした。 時間ではなく、パフォーマンスインジケータは、1秒あたりに処理されるアークの数です。 この場合、取得した時間をグラフ内のアークの数で割る必要があります。 最終結果として、平均32ポイントが取得されました。 最大値と最小値も計算されました。 コンパイルには、13番目のバージョンのIntelコンパイラと、フラグ–O3 –arch = sm_35を使用したNVCC CUDA 5.5が使用されました。
GPUおよびCPUのさまざまなオプションの平均パフォーマンスのグラフは次のとおりです。
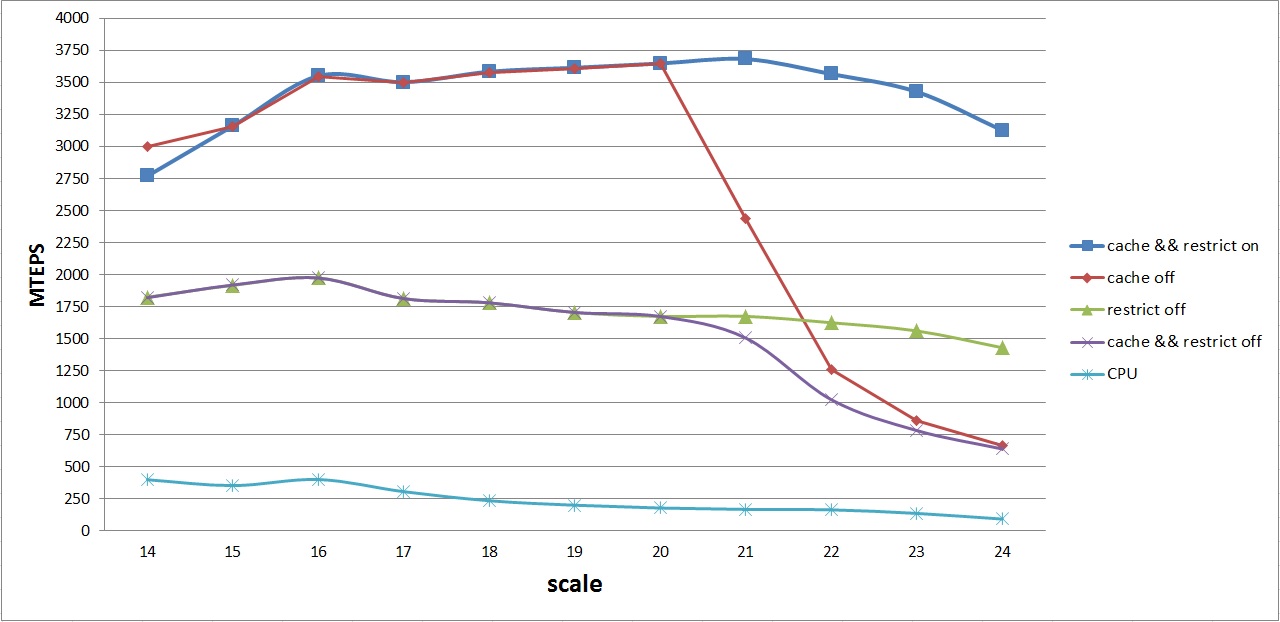
このグラフは、次のアルゴリズムの平均パフォーマンス曲線を示しています。
- キャッシュ&&制限-GPUアルゴリズムとすべての最適化(1)
- キャッシュオフ-キャッシュを改善するために順列を最適化しないGPUアルゴリズム(2)
- 制限オフ-テクスチャキャッシュの最適化なしのGPUアルゴリズム(3)
- キャッシュ&&制限オフ-最適化なしの基本的なGPUアルゴリズム(4)
- CPU-CPUの基本アルゴリズム
最初に目を引くのは、アルゴリズム(1)-(2)および(3)-(4)の同一の動作です。 上記のように、これは、最大2
20の頂点数を持つグラフのレベル配列がL2キャッシュに配置されるという事実によるものです。 したがって、アルゴリズム(1)および(2)を考慮し、(3)および(4)の場合にテクスチャキャッシュを使用しない場合、アークの順列を行うことはできません。
さらに、レベルの配列がL2キャッシュに収まらない場合、const __restrictが使用されているにもかかわらず、順列を無効にするとパフォーマンスが大幅に低下することに気付くかもしれません。 これは主に、levels配列へのランダムアクセスが原因です。 const __restirictオプションが無効になっている場合にも、同様の画像が観察されます。
最適なアルゴリズムの15-16-17度の領域の非平滑グラフは、別の小さな最適化の結果です。1つのアークの2つの頂点を符号なしint型の1つの変数にパッキングします。 最大頂点数は16ビットで、unsigned intは32ビットであるため、エッジデータを事前に1つのunsigned intにパックし、グローバルGPUメモリからデータの半分を読み取りながらカーネルでアンパックできます。
その結果、3.6 GTEPSの平均パフォーマンスを達成することができました。 頂点の数が2 16-2
23のグラフでは、ほぼ平均ピークパフォーマンスが達成されます。これは、このアーキテクチャに適しています。 最大パフォーマンスは、頂点数2 19-4,2 GTEPSのグラフで得られました。
CPUのネイティブ実装と比較した結果の加速は、非常に曖昧であることが判明しました。
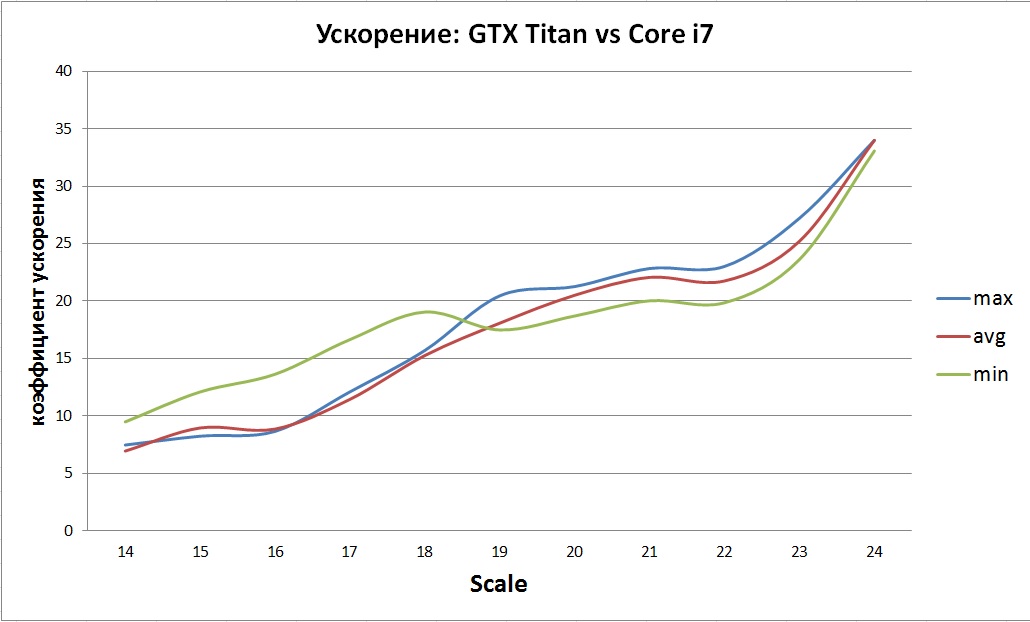
一般的な傾向が見えます-加速が徐々に増加します。 これは、非効率的な実装とCPUキャッシュのサイズの制限が原因である可能性があります。
実装されたカーネルの詳細な分析
結論として、GPUリソースの使用に関して、このアプローチがどれほど効果的かを示したいと思います。 このセクションは、興味がある場合にのみ表示されます。おそらく、将来、自分のアルゴリズムをこの記事で説明するものと比較したい人のために表示されます。 NVVPプロファイラーが2つのグラフ-2
19と2
22について表示するすべてを詳細に検討してみましょう。 最初のグラフではレベル配列をL2キャッシュに完全に配置しますが、2番目のグラフでは配置しないため、このようなグラフを選択しました。 まず、一般的な情報を考慮します。
| スケール | 実行された反復の数 | 共有メモリ使用量 | 使用されるレジスタの数 | 合計カーネルカウント時間(ミリ秒) | 配列のコピー時間(ミリ秒) |
| 2 19 | 7 | いや | 12 | 4,512 | 10.97 |
| 2 22 | 8 | いや | 12 | 41.1 | 86.66 |
カウントの開始前にGPUで頂点配列をコピーし、終了後にCPUで結果をコピーすることを考慮しました。 この表から、コピーにはアカウント全体の約2倍の時間がかかることがわかります。 次に、各グラフの反復を検討します。
カウント2 19
| 反復 | ミリ秒単位の時間 | GL Eff、% | GS Eff、% | WE Eff、% | NP WE Eff、% | 占有率、% | L2読み取り、GB / s | L2書き込み、GB / s | グローバル読み取り、GB / s | グローバル書き込み、GB / s |
| 1 | 0.577 | 100 | 10 | 100 | 94.6 | 89.3 | 551 | 0.0002 | 110 | 0.0002 |
| 2 | 0.572 | 100 | 8.1 | 99.9 | 94.5 | 89.2 | 551 | 0.0986 | 110 | 0.0498 |
| 3 | 0.58 | 100 | 11.9 | 93.5 | 88.5 | 88.1 | 545 | 14 | 109 | 6 |
| 4 | 1.062 | 100 | 24.3 | 85.1 | 77.7 | 78.2 | 289 | 71 | 58 | 51 |
| 5 | 0.576 | 100 | 9.5 | 91.1 | 86.8 | 88.8 | 549 | 1.37 | 110 | 0.5576 |
| 6 | 0.576 | 100 | 7.8 | 99.6 | 94.2 | 89.2 | 551 | 0.0017 | 110 | 0.0010 |
| 7 | 0.572 | 100 | 0 | 100 | 94.6 | 89.3 | 551 | 0.000 | 110 | 0.000 |
デコード:
- GL Eff-グローバルな負荷効率
- GS Eff-グローバルストアの効率
- WE Eff-ワープ実行効率
- NP WE Eff-非予測のワープ実行効率
- 占有-実際にアクティブなワープの数/ SMXのワープの最大数
この表は、3および4回の反復で最大数の頂点が処理されることを示しています。 このため、4回目の反復で、L2帯域幅とグローバルGPUメモリの使用の減少が見られます。 アルゴリズムの仕様に従って、最後の反復でエントリが発生しないことに注意してください。 グラフのマークアップの完全性を判断する必要があります。 ワープの実行効率は、最も「ロードされた」反復で93〜100%〜85%です。
比較のために、以下の表は2
22の頂点を持つグラフで、そのレベルの配列のサイズはGPUのL2キャッシュに完全には収まりません。
カウント2 22
| 反復 | ミリ秒単位の時間 | GL Eff、% | GS Eff、% | WE Eff、% | NP WE Eff、% | 占有率、% | L2読み取り、GB / s | L2書き込み、GB / s | グローバル読み取り、GB / s | グローバル書き込み、GB / s |
| 1 | 4.66 | 100 | 10,4 | 100 | 94.6 | 89.1 | 556 | 0.0001 | 113 | 0.00001 |
| 2 | 4.60 | 100 | 11.8 | 100 | 94.6 | 89.1 | 556 | 0.0014 | 113.2 | 0.0011 |
| 3 | 4.61 | 100 | 11.2 | 99.8 | 94.4 | 89.1 | 555 | 0.5547 | 117 | 0.3750 |
| 4 | 6,405 | 100 | 17.8 | 83.7 | 79.1 | 82.2 | 399 | 46 | 81 | 28 |
| 5 | 7,016 | 100 | 15.8 | 83.6 | 74.1 | 79.8 | 364 | 34 | 74 | 19 |
| 6 | 4.62 | 100 | 7.9 | 90.2 | 85.5 | 89.1 | 555 | 0.0967 | 117 | 0.0469 |
| 7 | 4.60 | 100 | 7.8 | 100 | 94.6 | 89 | 556 | 0.0002 | 113 | 0.0001 |
| 8 | 4.60 | 100 | 0 | 100 | 94.6 | 89.1 | 556 | 0.000 | 113 | 0.000 |
デコードは上記のとおりです。 このグラフでは、2
19とほぼ同じ写真が観察されます。 ピークは4〜5回繰り返されます。 NVVPプロファイラーによると、560 GB / s L2キャッシュのスループットは高く(低、中、高、最大あり)、117 GB / sのグローバルメモリ容量は平均です(低、中、高、最大あり)。
おわりに
完了した作業の結果として、幅優先探索アルゴリズムが実装され、RMATグラフで最適化されました。頂点接続の平均度は32です。4.2GTEPSのピークパフォーマンスと3.6 GTEPSの平均が達成されました。 ご存知のように、パフォーマンスだけでなく、エネルギー効率も重要です。 Graph500の評価に加えて、エネルギー効率を示すGreen Graph500の評価があります。 BlueGene / Q、Power BQC 16C 1.60 GHz(1048576コア、65536ノード、15363 GTEPS)、2014年3月のGraph500パフォーマンス評価で1位。 このようなシステムの消費電力は340kWです(上位500の定格から取得)。 BlueGene / Qで得られたGTEPS / kWの結果の効率は45です。実装したアルゴリズムの場合、約18であることがわかります(計算に合計電力200 W、平均パフォーマンス3.6 GTEPSを使用しました。 GPU上では実現されません)。
Graph500のランキングには、同様のシステムXeon E5-2650 v2、GeForce GTX TITANがあり、グラフ2
25で17 GTEPSのパフォーマンスを得たことにも注意してください。 残念ながら、どのグラフが使用されたかに関する情報は提供されていません。 2014年3月現在、このシステムはランキングで58の位置にあります。