投機的なプロバイダーlinkmeupは成長し、通常の通信事業者のすべてのサービスで静かに成長します。 今、私たちはIPTVに成長しました。
これは、マルチキャストルーティングを構成する必要性を意味し、まず、マルチキャストとは何かを理解する必要があります。
これは、IPネットワークの通常の原則からの最初の逸脱です。 それでも、マルチキャストパラダイムは、ウォームチューブユニキャストとは根本的に異なります。
これは、新しいアプローチを理解する上での心の柔軟性にある程度挑戦しているとさえ言えます。
この記事では、次のことに焦点を当てます。

従来のビデオチュートリアル:
エンジニアとしての結成の夜明けに、マルチキャストのトピックは私を信じられないほど怖がらせました。
「 だから、緊急に、正午までに、市内中心部の新しい建物にビデオストリームをストリーミングする必要があります。プロバイダーはここで2階でそれを提供します 」とある素晴らしい朝を聞きました。 その時点で私が知っていたのは、送信者が1人だけで、受信者が多く、IGMPプロトコルが何らかの形で関与していることだけでした。
その結果、正午までにすべてを開始しようとしました-最も一般的なVLANをエントリポイントから出口ポイントに転送しました。 しかし、信号は不安定でした-画像が凍結し、バラバラになり、中断されました。 私は、IGMPで何ができるか、スヌーピング、スヌーピング、マルチキャストルーティングのオン、IGMPスヌーピング、遅延と損失の確認を何千回も試みようとしてパニックに陥りましたが、何も助けにはなりませんでした。 そして、それはすべてうまくいきました。 もちろん、安定した、信頼できる。
これはマルチキャストに対するワクチンとして機能し、長い間私は彼に興味を示さなかった。
すでにかなり後で、私は次のルールに達しました:

そして今、私が離陸したケースの高さから、ネットワーク部分の設定に問題はないことを理解しています-最終機器にはバグがありました。
落ち着いて、私を信頼してください。 この記事の後、そのようなことはあなたを怖がらせません。
マルチキャストの一般的な理解
ご存じのとおり、次の種類のトラフィックが存在します。
ユニキャスト -
ユニキャスト-1人の送信者、1人の受信者。 (
例:WEBサーバーからHTTPページをリクエストする )。
ブロードキャスト -ブロードキャスト-1人の送信者、受信者-ブロードキャストセグメント内のすべてのデバイス。 (
例:ARP要求 )。
マルチキャスト -マルチキャスト-1人の送信者、多くの受信者。 (
例:IPTV )。
エニーキャスト -最も近いホストへのユニ
キャスト-1人の送信者、多くの受信者がいますが、実際にはデータは1人にのみ送信されます。 (
例:エニーキャストDNS )。
マルチキャストについて話すことにしたので、おそらくどこでどのように使用するかという質問からこの段落を始めます。
最初に思い浮かぶのはテレビ(IPTV)です。1つのソースサーバーが、一度に多くのクライアントを受信したいトラフィックを送信します。 これが、
マルチキャスト -マルチキャストブロードキャストという用語の定義です。 つまり、既に知っているブロードキャストが全員へのブロードキャストを意味する場合、マルチキャストは特定のグループへのブロードキャストを意味します。
2番目のアプリケーションは、たとえば、一度に多くのコンピューターにオペレーティングシステムを複製することです。 これは、1つのサーバーから大量のデータをダウンロードすることを意味します。
想定されるシナリオ:音声会議とビデオ会議(誰もが耳を傾けるという)、eコマース、オークション、交換。 しかし、これは理論上であり、実際には、マルチキャストはここではほとんど使用されません。
別のアプリケーションはプロトコルオーバーヘッドです。 たとえば、ブロードキャストドメインのOSPFは、メッセージをアドレス224.0.0.5および224.0.0.6に送信します。 そして、OSPFを実行するノードのみがそれらを処理します。
マルチキャストメーリングの2つの基本原則を策定します。
- 送信者は、受信者の数に関係なく、トラフィックのコピーを1つだけ送信します。
- トラフィックは、それに本当に興味がある人だけが受け取ります。
実践のためのこの記事では、最もわかりやすい例としてIPTVを取り上げます。
例I
最も単純なケースから始めましょう。
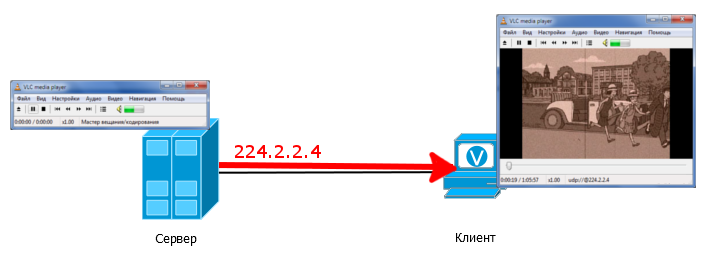
グループ224.2.2.4へのブロードキャストはソースサーバーで構成されます-これは、サーバーがIPアドレス224.2.2.4にトラフィックを送信することを意味します。 クライアントでは、ビデオプレーヤーはグループ224.2.2.4ストリームを受け入れるように構成されています。
同時に、クライアントとサーバーが同じサブネットからのアドレスを持ち、互いにpingを実行する必要がないことに注意してください-同じブロードキャストドメインにあれば十分です。
マルチキャストストリームはサーバーから単純に流れ込み、クライアントは単純にそれを受信します。 職場ですぐに試すことができます。2台のコンピューターをパッチコードで接続し、たとえばVLCを起動します。
マルチキャストでは、ソースからのシグナリングがないため、
「こんにちは、ソースです。少しマルチキャストする必要はありませんか?」送信元サーバーは、マルチキャストパケットのインターフェイスへのブロードキャストを開始するだけです。 この例では、彼らは直接クライアントに行き、実際、彼はすぐにそれらを受け入れます。
このリンクでパケットをキャッチすると、マルチキャストトラフィックはUDPパケットの海にすぎないことがわかります。

マルチキャストは特定のプロトコルに関連付けられていません。 実際、それを定義するのはアドレスだけです。 ただし、そのアプリケーションについて説明すると、ほとんどの場合、UDPが使用されます。 これは、ここで必要なデータが通常マルチキャストを使用して送信されるという事実によって簡単に説明されます。 たとえば、ビデオ。 フレームの一部が失われ、送信者がTCPで発生するように再度送信しようとすると、この部分が遅れる可能性が高く、どこに表示する必要がありますか? 列車は出発しました。 音についてもまったく同じです。
したがって、接続を確立する必要はないため、TCPはここでは役に立ちません。
マルチキャストとユニキャストの違いは何ですか? すでに仮定があると思います。 そしておそらくあなたは正しい。
通常の状況では、1人の受信者と1人の送信者がいます。それぞれに1つの一意のIPアドレスがあります。 送信者はパケットの送信先を正確に知っており、このアドレスをIPヘッダーに入れます。 各中間ノードは、ルーティングテーブルのおかげで、パケットの転送先を正確に把握しています。 2つのノード間のユニキャストトラフィックは、ネットワークをシームレスに流れます。 しかし、問題は、通常のパケットでは1つの受信者IPアドレスのみが示されることです。
同じトラフィックに複数の受信者がいる場合はどうなりますか? 原則として、ユニキャストアプローチをこのような状況に拡張できます。各クライアントにパッケージのコピーを送信します。 クライアントは違いに気付かないでしょう。たとえ違いがあったとしても、たとえ千があったとしても、その違いはデータ伝送チャネルにはっきりと見えます。

マルチキャストサーバーから1つのSDチャネルを転送するとします。 2 Mb / sを使用します。 このようなチャンネルは30あり、各チャンネルは一度に20人を視聴しています。 合計2 Mb / s * 30チャネル* 20人= 1200 Mb / sまたはユニキャスト配信の場合はテレビのみで1.2 Gb / s しかし、この数字に2を安全に掛けることができるHDチャンネルがまだあります。そして、急流の場所はどこですか?
これが、
クラスDアドレスブロックがIPv4で規定されている理由
です:224.0.0.0/4 (224.0.0.0-239.255.255.255)。 この範囲のアドレスにより、マルチキャストグループが決まります。 1つのアドレス-これは1つのグループで、通常は「
G 」という文字で示されます。
つまり、クライアントがグループ224.2.2.4に接続されているということは、宛先アドレス224.2.2.4のマルチキャストトラフィックを受信することを意味します。
例II
回線にスイッチといくつかのクライアントを追加します。
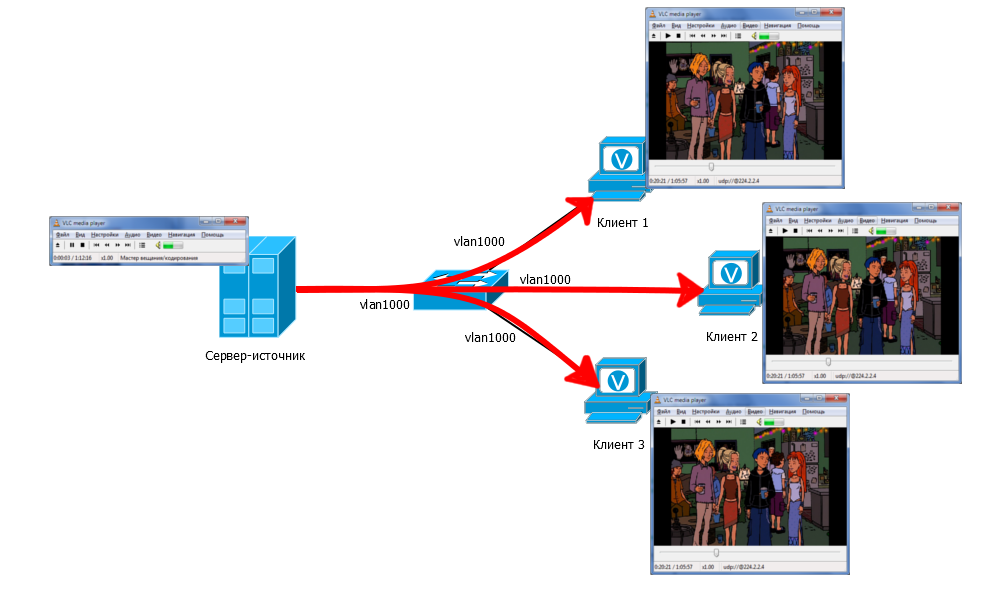
マルチキャストサーバーは、まだグループ22.2.2.2。4に対してブロードキャストしています。 スイッチでは、4つのポートすべてが同じVLANにある必要があります。 トラフィックはスイッチに到着し、デフォルトで同じVLANのすべてのポートに送信されます。 したがって、すべての顧客がこのトラフィックを受け取ります。 ビデオプレーヤー内のすべてのグループには、グループアドレス224.2.2.4もあります。
実際、これらのデバイスはすべてこのマルチキャストグループのメンバーになります。 そのメンバーシップは動的です:誰でも、いつでも、それを出入りできます。
この状況では、一般的に、プレーヤーも他の何も実行していない人もトラフィックを受信します。 ただし、同じVLAN内にある場合のみ。 後で対処する方法を考えます。
この場合、スイッチへのトラフィックのコピーはソースサーバーから1つだけであり、各クライアントの個別のコピーではないことに注意してください。 また、SDチャネルを使用した例では、ソースとスイッチ間のポート負荷は1.2 Gb / sではなく、60 Mb / s(2 Mb / s * 30チャネル)のみです。
実際のところ、このすべての巨大な範囲(224.0.0.0-239.255.255.255)を使用できます。
まあ、ほとんどすべて-最初のアドレス(224.0.0.0/23の範囲)はまだよく知られたプロトコル用に予約されています。
予約済みIPアドレスリスト| 住所 | 価値 |
|---|
| 224.0.0.0 | 未使用 |
| 224.0.0.1 | このセグメントのすべてのノード |
| 224.0.0.2 | このセグメント内のすべてのマルチキャストノード |
| 224.0.0.4 | このアドレスは後期DVMRPプロトコルに割り当てられました |
| 224.0.0.5 | すべてのセグメントOSPFルーター |
| 224.0.0.6 | すべてのDRセグメントルーター |
| 224.0.0.9 | すべてのセグメントRIPv2ルーター |
| 224.0.0.10 | すべてのセグメントEIGRPルーター |
| 224.0.0.13 | すべてのセグメントPIMルーター |
| 224.0.0.18 | すべてのセグメントVRRPルーター |
| 224.0.0.19-21 | すべてのIS-ISセグメントルーター |
| 224.0.0.22 | すべてのセグメントIGMPルーター(v2およびv3) |
| 224.0.0.102 | すべてのHSRPv2 / GLBPセグメントルーター |
| 224.0.0.107 | PTPv2-高精度時間プロトコル |
| 224.0.0.251 | mDNS |
| 224.0.0.252 | LLMNR |
| 224.0.0.253 | テレド |
| 224.0.1.1 | NTP |
| 224.0.1.39 | Cisco Auto-RP-アナウンス |
| 224.0.1.40 | Cisco Auto-RP-Discovery |
| 224.0.1.41 | H.323ゲートキーパー |
| 224.0.1.129-132 | PTPv1 / PTPv2 |
| 239.255.255.250 | SSDP |
224.0.0.0/24の範囲は、
リンクローカル通信用に予約されています。 このような宛先アドレスを持つマルチキャストパケットは、1つのブロードキャストセグメントの制限を超えることはできません。
224.0.1.0/24の範囲は、ネットワーク全体にマルチキャストを送信する必要があるプロトコル、つまりルーターを通過するプロトコル用に予約されています。
ここで、実際には、マルチキャストに関する最も基本的なこと。
ソースとレシーバーが同じネットワークセグメントにある単純な状況を考慮しました。 スイッチが受信したトラフィックは、スイッチによってすべてのポートに送信されます-魔法ではありません。
しかし、サーバーからのトラフィックがクライアントに到達する方法は完全に理解できませんが、それらの間にリンクマップの巨大なプロバイダーがある場合はどうでしょうか? そして、実際には、クライアントが誰であるかをどのようにして知るのでしょうか? クライアントがどこにいるかわからないという理由だけで、ルートを手動で登録することはできません。 従来のルーティングプロトコルもこの質問に答えません。 したがって、マルチキャスト配信は私たちにとってまったく新しいものであるという理解に至ります。
一般に、現時点ではソースから宛先にマルチキャストを配信する多くのプロトコルがあります-IGMP / MLD、PIM、MSDP、MBGP、MOSPF、DVMRP。
現在使用されているPIMとIGMPの2つに焦点を当てます。
IGMPを使用すると、最終的な宛先クライアントは、トラフィックを受信することを最も近いルーターに伝えます。 また、PIMは、ルーターを介して送信元から受信者へのマルチキャストトラフィックのパスを構築します。

IGMP
再びダンプに戻りましょう。 マルチキャストストリームが注がれた後のこのトップパケットを参照してください。

これは、Playをクリックしたときにクライアントが送信したIGMPプロトコルメッセージです。 これが、彼がグループ224.2.2.4のトラフィックを受信したいと報告する方法です。
IGMP-インターネットグループ管理プロトコル -マルチキャストトラフィッククライアントとそれらに最も近いルーターの相互作用のためのネットワークプロトコルです。
IPv6は、IGMPの代わりにMLD (Multicast Listener Discovery)を使用します。 それらはまったく同じように機能するため、IGMPをMLDに、IPをIPv6に安全に変更できます。
IGMPはどのように機能しますか?
おそらく、プロトコルには現在、IGMPv1、IGMPv2、IGMPv3の3つのバージョンがあるという事実から始める必要があります。 最もよく使用されるのは2番目で、1番目はほとんど忘れられているため、説明しません。3番目は2番目と非常によく似ています。
これまでのところ、最も示唆的なものと同様に、2番目に焦点を当て、グループを離れるまで、グループに接続しているクライアントからのすべてのイベントを検討します。
クライアントは、VLCプレーヤーを通じてグループ224.2.2.4も要求します。
IGMPの役割は非常に単純です。クライアントがない場合、マルチキャストトラフィックをセグメントに転送する必要はありません。 クライアントが到着すると、トラフィックを受信したいことをIGMP経由でルーターに通知します。
すべてがどのように発生するかを理解するには、次のネットワークを使用します。

マルチキャストトラフィックを受信および処理するようにルーターが既に構成されているとします。
 1.
1.クライアントでアプリケーションを実行し、グループ224.2.2.4を設定するとすぐに、
IGMPメンバーシップレポートパッケージがネットワークに送信されます。ノードは、このグループからトラフィックを受信することを「レポート」します。

IGMPv2では、レポートは目的のグループのアドレスに送信され、並行してパッケージ自体にも示されます。 これらのメッセージは、そのセグメント内でのみ存続し、ルーターによってどこにも転送されるべきではないため、TTL 1もあります。
多くの場合、文献ではIGMP Joinの記述に出くわすことがあります。 心配しないでください-これはIGMPメンバーシップレポートの別名です。
2.ルータはIGMPレポートを受信し、このインターフェイスの背後にクライアントが存在することを認識して、情報をテーブルに入力します

これはIGMP情報の出力です。 最初のグループはクライアントによって要求されます。 3番目と4番目は、Windowsに組み込まれている
SSDPプロトコルのサービスグループです。 2番目は、Ciscoルーターに常に存在する特別なグループです。これは、ルーターでデフォルトでアクティブにされる
Auto-RPプロトコルに使用されます。
FE0 / 0インターフェイスは、グループ224.2.2.4のトラフィックのダウンストリームになります-受信したトラフィックを送信する必要があります。
通常のユニキャストルーティングテーブルに加えて、マルチキャストもあります。

顧客の存在は、最初のエントリ
(*、224.2.2.4)で示されます。 レコード
(172.16.0.5、224.2.2.4)は、ルーターがこのグループのマルチキャストストリームのソースを認識していることを意味します。
出力から、グループ224.2.2.4のトラフィックがFE0 / 1を通過し、ポートFE0 / 0に送信する必要があることがわかります。
トラフィックを送信する必要のあるインターフェイスは、ダウンストリームインターフェイスのリスト
-OIL-Outbound Interface Listに含まれています。
show ip mrouteコマンド
の出力については、後で詳しく調べます。
上記のダンプでは、クライアントがIGMPレポートを送信するとすぐに、UDPがその直後に飛んだことがわかります。これはビデオストリームです。
3.クライアントはトラフィックを受信し始めました。 ルーターは、受信者がまだいることを時々確認する必要があるため、突然クライアントが残っていない場合に無駄にブロードキャストしないようにします。 これを行うには、すべてのダウンストリームインターフェイスに
IGMPクエリ要求を定期的に送信します。
* IGMPによってフィルタリングされたダンプ* 。

デフォルトでは、これは60秒ごとに発生します。 このようなパケットのTTLも1です。これらのパケットは、特定のグループを指定せずに、アドレス224.0.0.1-このセグメント内のすべてのノードに送信されます。 このようなクエリメッセージは、
一般クエリ -一般と呼ばれます。 したがって、ルーターは「みんな、他に誰が何を受け取りたいですか?」と尋ねます。
IGMP General Queryを受信すると、すべてのグループをリッスンするホストは、接続時と同様にIGMPレポートを送信する必要があります。 もちろん、レポートでは、関心のあるグループのアドレスを示す必要があります。
* IGMPによってフィルタリングされたダンプ* 。

クエリへの応答で、グループの少なくとも1つのレポートがルーターに届いた場合、さらにクライアントがあり、このレポートの発信元であるインターフェイス、このグループ自体のトラフィックにブロードキャストし続けます。
3つの連続したクエリに対して、どのグループのインターフェイスからも応答がなかった場合、ルーターはこのグループのマルチキャストルーティングテーブルからこのインターフェイスを削除します。そこでトラフィックの送信を停止します。
独自のイニシアチブでは、クライアントは通常、接続時にのみレポートを送信し、ルーターからのクエリに単に応答します。
クライアントの動作に関する興味深い詳細:Queryを受け取った後、彼はすぐにReportで応答します。 ノードは、0から最大応答時間までのタイムアウトを取ります。これは、次のクエリで指定されます。

デバッグ中またはダンプ中の場合、さまざまなレポートを受信するまでに数秒かかることがあります。
これは、何百もの顧客が一列になって、一般的なクエリを受け取って、レポートパッケージでネットワークをあふれさせないようにするためです。 また、通常、1つのクライアントのみがレポートを送信します。
実際、レポートはグループアドレスに送信されるため、すべてのクライアントに届きます。 同じグループの別のクライアントからレポートを受信すると、ノードは独自のレポートを送信しません。 ロジックは単純です。ルーターはこの同じレポートを既に受信しており、クライアントが存在することを知っているため、それはもう必要ありません。
このメカニズムはレポート抑制と呼ばれます。
この記事の後半で、このメカニズムが実際にほとんど機能しない理由について説明します。
4.これは、クライアントがグループを離れる(たとえば、プレーヤー/テレビの電源を切る)まで何世紀も続きます。 この場合、
IGMP Leaveをグループアドレスに送信します。

ルータはそれを受信し、理論的には切断する必要があります。 ただし、特定のクライアントを切断することはできません-ルーターはそれらを区別しません-ダウンストリームインターフェースを持っています。 また、インターフェースの背後には複数のクライアントが存在する場合があります。 つまり、ルーターがこのグループのOIL(送信インターフェイスリスト)からこのインターフェイスを削除すると、すべてのユーザーに対してビデオがオフになります。
しかし、まったく削除しないことも不可能です-突然最後のクライアントだったのに-なぜ無駄に放送されたのですか?
ダンプを調べると、Leaveを受信した後、ルーターがしばらくの間ストリームを送信し続けていることがわかります。 実際のところ、Leaveに応答するルーターは、このLeaveが来たグループのアドレスにIGMP Queryを送信し、それが来た場所からインターフェイスに来たということです。 このようなパッケージは、
Group Specific Queryと呼ばれます。 この特定のグループに接続されているクライアント
のみがそれに応答
します。
 ルーターは、グループの応答レポートを受信した場合、インターフェイスへのブロードキャストを継続します。受信しなかった場合、タイマーの期限切れ後に削除します。合計で、Leaveを受信した後、2つのGroup Specific Queryが送信されます-1つは必須で、もう1つはコントロールです。* IGMPによってフィルタリングされたダンプ*。
ルーターは、グループの応答レポートを受信した場合、インターフェイスへのブロードキャストを継続します。受信しなかった場合、タイマーの期限切れ後に削除します。合計で、Leaveを受信した後、2つのGroup Specific Queryが送信されます-1つは必須で、もう1つはコントロールです。* IGMPによってフィルタリングされたダンプ*。 次に、ルーターはフローを停止します。
次に、ルーターはフローを停止します。
クエリア
もう少し複雑なケースを考えてみましょう 。トラフィックをブロードキャストできる2つ(またはそれ以上)のルーターがクライアントセグメントに接続されています。何もしなければ、マルチキャストトラフィックが複製されます。両方のルーターがクライアントからレポートを受け取ります。これを回避するために、質問者であるクエリアを選択するメカニズムがあります。勝った人はクエリを送信し、レポートを監視し、脱退に応答し、それに応じて、彼はセグメントにトラフィックを送信します。敗者はReportのみを聞き、指をパルスに合わせます。選挙はかなりシンプルで直感的です。ルーターR1とR2が含まれる瞬間からの状況を考えてみましょう。1)インターフェイスでIGMPをアクティブにしました。2)最初は、デフォルトでは、それぞれが自身をクエリアと見なします。3)それぞれがIGMP General Queryをネットワークに送信します。主な目標は、顧客がいるかどうかを確認すると同時に、セグメント内の他のルーター(存在する場合)に選挙への参加意欲を伝えることです。4)一般クエリは、他のIGMPルーターを含む、セグメント内のすべてのデバイスを受信します。5)近隣からこのようなメッセージを受信すると、各ルーターは誰が価値があるかを評価します。6)より低いIPを持つルーターが勝ちます(IGMPクエリパケットのソースIPフィールドに示されます)。彼はクエリアになり、他のすべては非クエリアになります。7)非Querierは、より低いIPアドレスを持つクエリが到着するたびにリセットされるタイマーを開始します。タイマーが切れる前に(100秒以上:105-107)、ルーターがより低いアドレスのQueryを受信しない場合、ルーターはQuerierを宣言し、対応するすべての機能を引き継ぎます。8)クエリアがより低いアドレスでクエリを受信した場合、クエリアはこれらの職務を辞任します。クエリアは、IPが少ない別のルーターになります。そのまれなケース、測定すると、誰が少ない。クエリアを選択することは非常に重要なマルチキャスト手順ですが、RFCに準拠していない一部の陰湿なメーカーは、頑丈なスティックをホイールに挿入する場合があります。スイッチが生成できる送信元アドレスが0.0.0.0のIGMPクエリについて説明しています。そのようなメッセージは、クエリアの選択に関与すべきではありませんが、すべてに備える必要があります。非常に複雑で長期にわたる問題の例を次に示します。
。トラフィックをブロードキャストできる2つ(またはそれ以上)のルーターがクライアントセグメントに接続されています。何もしなければ、マルチキャストトラフィックが複製されます。両方のルーターがクライアントからレポートを受け取ります。これを回避するために、質問者であるクエリアを選択するメカニズムがあります。勝った人はクエリを送信し、レポートを監視し、脱退に応答し、それに応じて、彼はセグメントにトラフィックを送信します。敗者はReportのみを聞き、指をパルスに合わせます。選挙はかなりシンプルで直感的です。ルーターR1とR2が含まれる瞬間からの状況を考えてみましょう。1)インターフェイスでIGMPをアクティブにしました。2)最初は、デフォルトでは、それぞれが自身をクエリアと見なします。3)それぞれがIGMP General Queryをネットワークに送信します。主な目標は、顧客がいるかどうかを確認すると同時に、セグメント内の他のルーター(存在する場合)に選挙への参加意欲を伝えることです。4)一般クエリは、他のIGMPルーターを含む、セグメント内のすべてのデバイスを受信します。5)近隣からこのようなメッセージを受信すると、各ルーターは誰が価値があるかを評価します。6)より低いIPを持つルーターが勝ちます(IGMPクエリパケットのソースIPフィールドに示されます)。彼はクエリアになり、他のすべては非クエリアになります。7)非Querierは、より低いIPアドレスを持つクエリが到着するたびにリセットされるタイマーを開始します。タイマーが切れる前に(100秒以上:105-107)、ルーターがより低いアドレスのQueryを受信しない場合、ルーターはQuerierを宣言し、対応するすべての機能を引き継ぎます。8)クエリアがより低いアドレスでクエリを受信した場合、クエリアはこれらの職務を辞任します。クエリアは、IPが少ない別のルーターになります。そのまれなケース、測定すると、誰が少ない。クエリアを選択することは非常に重要なマルチキャスト手順ですが、RFCに準拠していない一部の陰湿なメーカーは、頑丈なスティックをホイールに挿入する場合があります。スイッチが生成できる送信元アドレスが0.0.0.0のIGMPクエリについて説明しています。そのようなメッセージは、クエリアの選択に関与すべきではありませんが、すべてに備える必要があります。非常に複雑で長期にわたる問題の例を次に示します。
IGMPの他のバージョンに関するいくつかの言葉
バージョン1は本質的に、Leaveメッセージがないという点でのみ異なります。クライアントがこのグループからトラフィックを受信する必要がなくなった場合、クエリへの応答としてレポートの送信を停止するだけです。クライアントが残っていない場合、ルーターはタイムアウトによってトラフィックを送信しなくなります。また、クエリア選択はサポートされていません。トラフィックの重複を避けるため、たとえばPIMなどの上位プロトコルが責任を負います。これについては後で説明します。バージョン3はIGMPv2がサポートするすべてをサポートしますが、いくつかの変更があります。まず、レポートはグループアドレスではなく、マルチキャストサービスアドレス224.0.0.22に送信されます。また、要求されたグループのアドレスは、パッケージ内でのみ示されます。これは、後で説明するIGMPスヌーピングの作業を簡素化するために行われます。第二に、さらに重要なことは、IGMPv3が純粋なSSMをサポートし始めたことです。これは、いわゆるSource Specific Multicastです。この場合、クライアントはグループを要求できるだけでなく、トラフィックを受信したい、または逆にしたくない送信元のリストを示すこともできます。 IGMPv2では、クライアントは送信元を気にせずにグループトラフィックを単に要求および受信します。 そのため、IGMPはクライアントとルーター間の対話用に設計されています。したがって、例IIに戻る、ルーターがない場合、正式に宣言できます-そこにIGMP-形式以外の何ものでもありません。ルーターはなく、クライアントにはマルチキャストストリームを要求する相手がいません。また、ビデオは、スイッチからフローがすでに注がれているという単純な理由で機能します-それを拾うだけです。IGMPはIPv6では機能しないことを思い出してください。MLDプロトコルがあります。
そのため、IGMPはクライアントとルーター間の対話用に設計されています。したがって、例IIに戻る、ルーターがない場合、正式に宣言できます-そこにIGMP-形式以外の何ものでもありません。ルーターはなく、クライアントにはマルチキャストストリームを要求する相手がいません。また、ビデオは、スイッチからフローがすでに注がれているという単純な理由で機能します-それを拾うだけです。IGMPはIPv6では機能しないことを思い出してください。MLDプロトコルがあります。
もう一度繰り返す
* IGMPによってフィルタリングされたダンプ*。 1.最初に、ルーターは、インターフェースでIGMPを有効にして、受信者がいるかどうかを確認し、クエリアへの希望を宣言した後、IGMP一般クエリを送信しました。当時、このグループには誰もいませんでした。2.次に、グループ224.2.2.4からトラフィックを受信したいクライアントが現れ、IGMPレポートを送信しました。その後、トラフィックはそこに行きましたが、ダンプからフィルタリングされました。3.その後、ルーターは何らかの理由でクライアントがまだ存在するかどうかを確認することを決定し、IGMP General Queryを再度送信しました。クライアントはこれに応答しました(4)。5。ルーターは定期的に(1分に1回)、IGMP General Queryを使用して受信者がまだいることを確認し、ノードはIGMPレポートを使用してこれを確認します。6.その後、彼は気が変わって、IGMP Leaveを送信してグループを放棄しました。7.ルーターはLeaveを受信し、他の受信者がいないことを確認するために、IGMP Group Specific Query ...を2回送信します。そしてタイマーが切れると、ここでトラフィックの送信を停止します。8.ただし、IGMP Queryをネットワークに送信し続けます。たとえば、プレーヤーの接続を解除せず、単に接続の問題が発生した場合。その後、接続は復元されますが、レポートクライアントはそれ自体では送信しません。しかし、クエリへの答え。したがって、人間の介入なしでフローを復元できます。
1.最初に、ルーターは、インターフェースでIGMPを有効にして、受信者がいるかどうかを確認し、クエリアへの希望を宣言した後、IGMP一般クエリを送信しました。当時、このグループには誰もいませんでした。2.次に、グループ224.2.2.4からトラフィックを受信したいクライアントが現れ、IGMPレポートを送信しました。その後、トラフィックはそこに行きましたが、ダンプからフィルタリングされました。3.その後、ルーターは何らかの理由でクライアントがまだ存在するかどうかを確認することを決定し、IGMP General Queryを再度送信しました。クライアントはこれに応答しました(4)。5。ルーターは定期的に(1分に1回)、IGMP General Queryを使用して受信者がまだいることを確認し、ノードはIGMPレポートを使用してこれを確認します。6.その後、彼は気が変わって、IGMP Leaveを送信してグループを放棄しました。7.ルーターはLeaveを受信し、他の受信者がいないことを確認するために、IGMP Group Specific Query ...を2回送信します。そしてタイマーが切れると、ここでトラフィックの送信を停止します。8.ただし、IGMP Queryをネットワークに送信し続けます。たとえば、プレーヤーの接続を解除せず、単に接続の問題が発生した場合。その後、接続は復元されますが、レポートクライアントはそれ自体では送信しません。しかし、クエリへの答え。したがって、人間の介入なしでフローを復元できます。
そしてもう一度
IGMPは、マルチキャストトラフィックの受信者の存在と切断についてルーターが学習するためのプロトコルです。IGMPレポート -接続時およびIGMPクエリへの応答時にクライアントによって送信されます。クライアントが特定のグループのトラフィックを受信したいことを意味します。IGMP General Query-現在必要なグループを確認するためにルーターによって定期的に送信されます。受信者のアドレスは224.0.0.1です。IGMP Group Sepcific Query-このグループに他の受信者がいるかどうかを調べるために、Leaveメッセージに応答してルーターによって送信されます。マルチキャストグループのアドレスは、受信者アドレスとして示されます。IGMP Leave-クライアントがグループから脱退するときに送信します。クエリア-1つのブロードキャストセグメントでブロードキャストできるルーターが複数ある場合、それらの中からメインの1つが選択されます-クエリア。彼は定期的にクエリを送信し、トラフィックを送信します。すべてのIGMP用語の詳細な説明。
PIM
そこで、クライアントが自分の意図を最も近いルーターに通知する方法を見つけました。ここで、大規模なネットワークを介して送信元から受信者にトラフィックを転送するとよいでしょう。あなたがそれについて考えると、私たちはかなり難しい問題に直面しています-ソースはグループにブロードキャストするだけであり、受信者がどこにいて何人いるのかについて何も知りません。受信者と自分に最も近いルーターは、特定のグループのトラフィックが必要であることのみを知っていますが、送信元がどこにあり、そのアドレスが何であるかはわかりません。この状況でトラフィックを配信する方法は?マルチキャストトラフィックをルーティングするためのプロトコルがいくつかあります。DVMRP、MOSPF、CBT-これらはすべて、さまざまな方法でこの問題を解決します。しかし、事実上の標準となったPIM-プロトコル独立マルチキャスト。他のアプローチは実行不可能であるため、開発者でさえ実際にこれを認識している場合があります。たとえば、CBT RFCプロトコルからの抜粋を次に示します。CBTバージョン2は、バージョン1との下位互換性を目的としていません。この段階でCBTが広く展開されているとは考えていないため、これが広範な互換性の問題を引き起こすとは考えていません。PIMには2つのバージョンがあり、2つの異なるプロトコルと呼ばれることもありますが、原理的には非常に異なります。- PIMデンスモード(DM)
- PIMスパースモード(SM)
特定のユニキャストトラフィックルーティングプロトコルに関連付けられていないため、独立しています。その理由は後で説明します。PIMデンスモード
PIM DMは、額にマルチアクトを配信する問題を解決しようとしています。彼は明らかに、ネットワークの隅々にいたるところに受信者がいると想定しています。したがって、最初はネットワーク全体をマルチキャストトラフィックでフラッディングします。つまり、送信元を除くすべてのポートに送信します。後で必要でないことが判明した場合、このブランチは特別なPIM Pruneメッセージを使用して「切断」され、トラフィックは送信されなくなります。しかし、しばらくすると、ルーターは再び同じブランチにマルチキャストを送信しようとします-突然受信者がいました。それらが表示されない場合、ブランチは一定期間再びカットされます。これらの2つのイベントの間にルーター上のクライアントが表示されると、Graftメッセージが送信されます。ルーターは、何かが通過するのを待たないように、カットブランチを要求します。ご覧のとおり、受信者へのパスを決定することには疑問がありません。トラフィックはどこにでもあるため、受信者に到達します。不要なブランチを削除した後、マルチキャストトラフィックが送信されるツリーが残ります。このツリーは、SPT-最短パスツリーと呼ばれます。ループがなく、受信者から送信元への最短パスを使用します。実際、ソースがルートであるSTPのスパニングツリーに非常に似ています。SPTは特定の種類のツリーであり、最短パスツリーです。一般に、マルチキャストツリーはMDT-Multicast Distribution Treeと呼ばれます。PIM DMは、その名前(高密度)を説明するマルチキャストクライアントが高密度のネットワークで使用されるべきであると想定されています。しかし、現実には、この状況はむしろ例外であり、多くの場合、PIM DMは実用的ではありません。今私たちにとって本当に重要なのは、ループ回避メカニズムです。このネットワークを想像してください 。1つのソース、1つの受信者、およびそれらの間の最も単純なIPネットワーク。すべてのルーターがPIM DMを実行しています。特別なループ回避メカニズムがない場合はどうなりますか?送信元はマルチキャストトラフィックを送信します。 R1はそれを受信し、PIMの原理に従って、DMはそれがどこから来たかを除いて、すべてのインターフェース、つまりR2とR3に送信します。R2はまったく同じことを行います。つまり、R3の側にトラフィックを送信します。 R3は、これがすでにR1から受信したものと同じトラフィックであると判断できないため、すべてのインターフェイスに転送します。 R1は、R3などからトラフィックのコピーを受信します。ここにあります-ループ。この状況でPIMは何を提供しますか?RPF-リバースパス転送。これは、マルチキャストトラフィックをPIM(あらゆる種類のDMおよびSMの両方)に送信する主な原則です。ソースからのトラフィックは、最短で到着する必要があります。つまり、受信した各マルチキャストパケットについて、ルーティングテーブルに基づいて、そこから来たかどうかをチェックします。1)ルーターはマルチキャストパケットの送信元アドレスを確認します。2)送信元アドレスが使用可能なインターフェイスを経由するルーティングテーブルを確認します。3)マルチキャストパケットが送信されたインターフェイスを確認します。4)インターフェイスが一致する場合-すべてが正常である場合、データが別のインターフェイスから来る場合、マルチキャストパケットはスキップされます-それらは破棄されます。この例では、R3は、ソースへの最短パスがR1(静的または動的ルート)を経由することを知っています。したがって、R1からのマルチキャストパケットはR3によってチェックおよび受け入れられ、R2からのマルチキャストパケットは破棄されます。
。1つのソース、1つの受信者、およびそれらの間の最も単純なIPネットワーク。すべてのルーターがPIM DMを実行しています。特別なループ回避メカニズムがない場合はどうなりますか?送信元はマルチキャストトラフィックを送信します。 R1はそれを受信し、PIMの原理に従って、DMはそれがどこから来たかを除いて、すべてのインターフェース、つまりR2とR3に送信します。R2はまったく同じことを行います。つまり、R3の側にトラフィックを送信します。 R3は、これがすでにR1から受信したものと同じトラフィックであると判断できないため、すべてのインターフェイスに転送します。 R1は、R3などからトラフィックのコピーを受信します。ここにあります-ループ。この状況でPIMは何を提供しますか?RPF-リバースパス転送。これは、マルチキャストトラフィックをPIM(あらゆる種類のDMおよびSMの両方)に送信する主な原則です。ソースからのトラフィックは、最短で到着する必要があります。つまり、受信した各マルチキャストパケットについて、ルーティングテーブルに基づいて、そこから来たかどうかをチェックします。1)ルーターはマルチキャストパケットの送信元アドレスを確認します。2)送信元アドレスが使用可能なインターフェイスを経由するルーティングテーブルを確認します。3)マルチキャストパケットが送信されたインターフェイスを確認します。4)インターフェイスが一致する場合-すべてが正常である場合、データが別のインターフェイスから来る場合、マルチキャストパケットはスキップされます-それらは破棄されます。この例では、R3は、ソースへの最短パスがR1(静的または動的ルート)を経由することを知っています。したがって、R1からのマルチキャストパケットはR3によってチェックおよび受け入れられ、R2からのマルチキャストパケットは破棄されます。 このようなチェックはRPFチェックと呼ばれ、そのおかげで、より複雑なネットワークでもMDTのループは発生しません。このメカニズムは、PIM-SMに関連し、同様に機能するため、私たちにとって重要です。ご覧のとおり、PIMはユニキャストルーティングテーブルに依存していますが、第1に、トラフィック自体をルーティングしません。第2に、テーブルに誰がどのように入力したかは関係ありません。ここで停止することはせず、PIM DMの動作を詳細に調べません。これは、多くの欠陥がある(まあ、RIPのような)古いプロトコルです。ただし、PIM DMが使用される場合があります。たとえば、マルチキャストストリームが小さい非常に小さなネットワークで。
このようなチェックはRPFチェックと呼ばれ、そのおかげで、より複雑なネットワークでもMDTのループは発生しません。このメカニズムは、PIM-SMに関連し、同様に機能するため、私たちにとって重要です。ご覧のとおり、PIMはユニキャストルーティングテーブルに依存していますが、第1に、トラフィック自体をルーティングしません。第2に、テーブルに誰がどのように入力したかは関係ありません。ここで停止することはせず、PIM DMの動作を詳細に調べません。これは、多くの欠陥がある(まあ、RIPのような)古いプロトコルです。ただし、PIM DMが使用される場合があります。たとえば、マルチキャストストリームが小さい非常に小さなネットワークで。
PIMスパースモード
まったく異なるアプローチで
は、PIM SMを使用します。 名前(スパースモード)にもかかわらず、少なくともPIM DMの効率よりも悪くない効率で、どのネットワークでも正常に使用できます。
ここで、彼らはマルチキャストネットワークでの無条件のフラッドという考えを捨てました。 関心のあるノードは、
PIM Joinメッセージを使用してツリーへの接続を個別に要求します。
ルーターがJoinを送信しなかった場合、トラフィックはルーターに送信されません。
PIMの仕組みを理解するために、1つのPIMルーターを備えた使い慣れたシンプルなネットワークから始めます。

R1の設定から、マルチキャスト、2つのインターフェイスのPIM SM(送信元とクライアントに向けて)、およびIGMPをクライアントに向けてルーティングする機能を有効にする必要があります。
もちろん、他の基本設定の中でも(IP、IGP)。これから、GNSを見つけてラボを構築できます。 この
記事で説明したマルチキャスト用のスタンドを組み立てる方法についての十分な詳細。
R1(config)
ここのCiscoは、いつものように、特別なアプローチが異なります。PIMがインターフェイスでアクティブになると、IGMPも自動的にアクティブになります。 PIMがアクティブになっているすべてのインターフェイスで、IGMPも機能します。
同時に、他のメーカーからの2つの異なるプロトコルが、2つの異なるコマンドによって有効になります:個別にIGMP、個別にPIM。
シスコにこの奇妙なことを許しますか? みんなと一緒に?
さらに、RPアドレスの構成が必要になる場合があります(たとえば、 ip pim rp-address 172.16.0.1 )。 これについては、後ほど、当たり前のこととして、それを和解してください。
グループ224.2.2.4のマルチキャストルーティングテーブルの現在の状態を確認します。

ソースでブロードキャストを開始した後、テーブルを再度確認する必要があります。
(S、G)")
この簡潔な結論を見てみましょう。
フォーム
(*、225.0.1.1)のレコードは
(*、G)と呼ばれ、/は
starcomage /によって読み取られ、受信者について
通知します。 また、1台のクライアントコンピューターについて話す必要はありません。一般的には、たとえば別のPIMルーターである可能性があります。 重要なことは、トラフィックを転送する必要があるインターフェイスです。
ダウンストリームインターフェイス(OIL)のリストが空(
Null )の場合、受信者はいないため、まだ開始していません。
レコード
(172.16.0.5、225.0.1.1)は
(S、G)と呼ばれ、/
eskomadzhiで読み取られ、ソースがわかっていると言われます。 この場合、アドレス172.16.0.5のソースは、グループ224.2.2.4のトラフィックをブロードキャストします。 マルチキャストトラフィックはFE0 / 1インターフェイスに着信します。これは
アップストリームインターフェイスです。
顧客はいません。 送信元からのトラフィックはルーターに到達し、これが彼の人生の終わりです。 ここで受信者を追加しましょう-PCでマルチキャスト受信を構成します。
PCはIGMPレポートを送信し、ルーターはクライアントが存在することを理解し、マルチキャストルーティングテーブルを更新します。
これは次のようになります。

下向きのインターフェースが登場しました:FE0 / 0、これはかなり期待されています。 さらに、彼は(*、G)と(S、G)の両方に登場しました。 ダウンストリームインターフェイスのリストは、
OIL-Outgoing Interface Listと呼ばれます。
FE1 / 0インターフェイスに別のクライアントを追加します。

結論を逐語的に読むと、次のようになります。
(*、G):FE0 / 0、FE1 / 0インターフェイスの背後にあるグループ224.2.2.4のマルチキャストトラフィック受信者がいます。 また、送信者が誰であるかは問題ではありません。これが「*」記号の意味です。
(S、G):ソース172.16.0.5からの宛先アドレス224.2.2.4のマルチキャストトラフィックがFE0 / 1に到着する場合、FE0 / 0およびFE1 / 0にコピーを送信する必要があります。
しかし、これは非常に単純な例です。1つのルーターが送信元アドレスと受信者の場所をすぐに認識します。 実際、ここには木さえありません。 しかし、PIMとIGMPの相互作用を理解するのに役立ちました。
PIMが何であるかを理解するために、ネットワークをもっと複雑にしましょう

すべてのIPアドレスが既にスキームに従って構成されていると仮定します。 IGPは、通常のユニキャストルーティングのためにネットワークで実行されています。
たとえば、
Client1はソースサーバーにpingを実行できます。
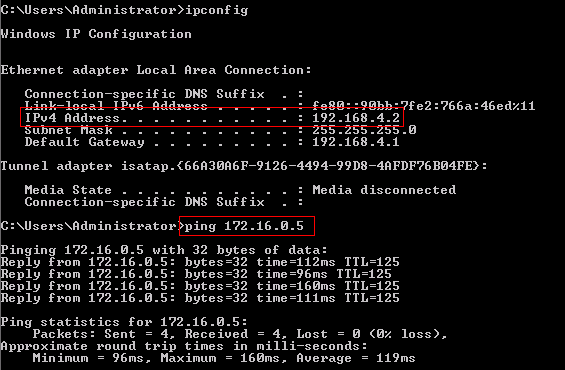
ただし、PIM、IGMPが開始されるまで、クライアントはチャネルを要求しません。
初期構成ファイル 。
したがって、時点は0です。
5つのルーターすべてでマルチキャストルーティングを有効にします。
RX(config)
PIMは、すべてのルーターのすべてのインターフェイスで直接有効になります(ソースサーバーおよびクライアントへのインターフェイスを含む)。
RX(config)
理論上、IGMPはクライアントの方向のインターフェイスで有効にする必要がありますが、前述のように、Cisco機器ではPIMとともに自動的に有効になります。
PIMが最初に行うことは、近隣を確立することです。
これには、PIM Helloメッセージが使用されます。 インターフェイスでPIMがアクティブになると、PIM HelloがTTL 1でアドレス
224.0.0.13に送信されます。これは、同じブロードキャストドメイン内のルーターのみがネイバーになることができることを意味します。

隣人が互いに挨拶を受け取ったらすぐに:

これで、マルチキャストグループのアプリケーションを受け入れる準備が整いました。
一方で鳥小屋でクライアントを起動し、他方でサーバーからのマルチキャストストリームを有効にすると、R1はトラフィックストリームを受信し、R4はクライアントが接続を試みるとIGMPレポートを受信します。 その結果、R1は受信者について何も知らず、R4は送信元について何も知りません。


ソースとグループの顧客に関する情報が1か所で収集されていれば便利です。 しかし、どの中に?
このミーティングポイントは、
ランデブーポイント-RPと呼ばれます。 これがPIM SMの中心的な概念です。 彼女なしでは何も機能しなかっただろう。 これは、ソースと受信者が出会う場所です。
すべてのPIMルーターは、RPがドメイン内にいること、つまりIPアドレスを知っている必要があります。
MDTツリーを構築するために、特定の中心点がネットワーク内のRPとして選択されます。
- ソースの研究を担当し、
- 興味のあるすべての人からの参加メッセージの魅力のポイントです。
RPを指定するには、静的と動的の2つの方法があります。 この記事では両方を見ていきますが、静的なものから始めましょう。静的なものよりも単純なものがあるからです。
R2がRPの役割を果たすようにします。
信頼性を高めるために、通常、ループバックインターフェイスのアドレスが選択されます。 したがって、コマンドは
すべてのルーターで実行さ
れます。
RX(config)
当然、このアドレスはすべてのポイントからルーティングテーブルからアクセスできる必要があります。
まあ、アドレス2.2.2.2はRP
なので 、R2の
Loopback 0インターフェイスでもPIMをアクティブにすることをお勧めします。
R2(config)
この直後、R4はグループ224.2.2.4のトラフィックソースについて学習します。

さらにトラフィックを送信します。

362000 bpsがFE0 / 1インターフェイスに到達し、FE0 / 0インターフェイスを介して送信されます。
私たちがやったすべて:
マルチキャストトラフィックをルーティングする機能を有効にしました(
ip multicast-routing )
インターフェイスでアクティブ化されたPIM(
ip pim sparse-mode )
指定されたRPアドレス(
ip pim rp-adress XXXX )
すべて、これはすでに動作中の構成であり、ステージ上で見ることができるよりもはるかに多くが舞台裏に隠れているため、分析を進めることができます。
PIMを使用して構成を完了します。
デブリーフィング
さて、最終的にはすべてがどのように機能しますか? RPは、ソースがどこにあるのか、顧客がどこにいるのか、どのようにして顧客間の接続を提供するのか?
すべては私たちの愛する顧客のために始められ、そしてそれらから始められるので、私たちは全体のプロセスを詳細に検討します。
1)クライアント1は、グループ224.2.2.4にIGMPレポートを送信します
 2)
2) R4はこの要求を受信し、FE0 / 0インターフェイスの背後にクライアントがあることを理解し、このインターフェイスをOILに追加して、レコード(*、G)を形成します。
")
アップストリームFE0 / 1インターフェイスはここで表示されますが、これはR4がグループ22.2.2.2.4のトラフィックを受信することを意味しません。 彼が今から得ることができる唯一の場所はFE0 / 1であるとしか言っていません。 ところで、 RPF-Check -R2:10.0.2.24に合格したネイバーもここに示されています。 期待。
R4と呼ばれる-LHR(ラストホップルーター)-ソースから数える場合、マルチキャストトラフィックのパス上の最後のルーター。 つまり、受信者に最も近いルーターです。
Client1の場合、これはR4、
Client2の場合、R5です。
3) R4にはまだマルチキャストストリームがないため(以前にリクエストしていません)、PIM Joinメッセージを生成してRPに送信します(2.2.2.2)。
")
PIM Joinはマルチキャストによりアドレス224.0.0.13に送信されます。 「RPへ」とは、パケット内で指定されたアドレスへの発信として、ルーティングテーブルで指定されたインターフェイスを経由することを意味します。 私たちの場合、これは2.2.2.2-RPのアドレスです。 このJoinは
Join(*、G)とも呼ばれ、「ソースが誰であっても、グループ22.2.2.2.4。からのトラフィックが必要です」と言います。
つまり、途中の各ルーターはそのような参加を処理し、必要に応じてRP側に新しい参加を送信する必要があります。 (このグループがルーターに既に存在する場合、上記のJoinを送信しないことを理解することが重要です。JoinがOILに到達したインターフェイスを追加し、トラフィックの送信を開始するだけです)。
私たちの場合、JoinはFE0 / 1に行きました。
 4)
4) Joinを受信したR2は、レコード(*、G)を形成し、FE0 / 0インターフェイスをOILに追加します。 しかし、Joinには送信先がありません-彼自身はすでにRPですが、ソースについてはまだ何もわかっていません。

このようにして、RPはクライアントの場所を学習します。
クライアント2も同じグループのマルチキャストトラフィックを受信する場合、R5はPIM JoinをFE0 / 1に送信します。これはRPの背後にあるため、R3はそれを受信した後、新しいPIM Joinを形成してFE1 / 1に送信します。
つまり、JoinはRPに到達するまでノードごとに移動するか、このグループのクライアントが既に存在する別のルーターに移動します。

したがって、R2-私たちのRP-は、FE0 / 0およびFE1 / 0のグループ224.2.2.4の受信者を持っていることを知っています。
また、インターフェイスの数に関係なく、インターフェイスごとに1つでも100でも、トラフィックフローはインターフェイスごとに1つです。
取得したものをグラフィカルに表示すると、次のようになります。

遠隔的に木に似ていますよね? したがって、
RPT-Rendezvous Point Treeと呼ばれます。 これはRPにルートを持つツリーであり、そのブランチは顧客にまで広がっています。
前述のように、より一般的な用語は
MDT-マルチキャスト配信ツリー -マルチキャストストリームが伝播するツリーです。 後で、MDTとRPTの違いがわかります。
5)サーバーを切断します。 上で説明したように、彼はPIM、RP、IGMPを心配しません。ただブロードキャストするだけです。 R1はこのストリームを受信します。 彼の仕事は、マルチキャストをRPに配信することです。
PIMには特別なタイプのメッセージ-
登録があります。 RPでマルチキャストのソースを登録するために必要です。
したがって、R1はグループ224.2.2.4のマルチキャストストリームを受信します。

")
R1は
FHR(ファーストホップルーター) -マルチキャストトラフィックのパス上またはソースに最も近い最初のルーターです。
6)次に、ソースから受信した各マルチキャストパケットをユニキャストPIMレジスタにカプセル化し、RPに直接送信します。

プロトコルスタックに注意してください。 ユニキャストIPおよびPIMヘッダーの上に、元のマルチキャストIP、UDP、およびデータがあります。
現在、PIMメッセージで知られている他のすべてとは異なり、受信者アドレスには2.2.2.2が含まれており、マルチキャストアドレスは含まれていません。
このようなパケットは、標準のユニキャストルーティングルールに従ってRPに配信され、最初のマルチキャストパケットを伝送します。つまり、トンネリングです!
======================
 タスク番号1
タスク番号1
スキームと初期設定 。
サーバー172.16.0.5で実行されているアプリケーションは、宛先ポートUDP 10999で、ブロードキャストアドレス255.255.255.255にのみパケットを送信できます。
このトラフィックは、クライアント1および2に配信する必要があります。
グループアドレス239.9.9.9のマルチキャストトラフィックの形式のクライアント1。
クライアントセグメント2では、アドレス255.255.255.255へのブロードキャストパケットの形式で。
タスクの詳細はこちらです。
======================
7) RPはPIMレジスタを受け取り、それをアンパックし、グループ22.2.2.2.4。のラッパーの下でトラフィックを検出します。
彼はすぐにこれに関する情報を自分のマルチキャストルーティングテーブルに入れます。
")
エントリ(S、G)-(172.16.0.5、224.2.2.4)が表示されました。
アンパックされたRPパケットは、RP0からFE0 / 0およびFE1 / 0インターフェイスに送信され、トラフィックはこれらを介してクライアントに到達します。
原則として、これは停止できたはずです。 すべてが機能します-顧客はトラフィックを獲得します。 しかし、2つの問題があります。
- カプセル化とカプセル化解除のプロセスは、ルーターにとって高価な操作です。 さらに、ヘッダーを追加するとパケットのサイズが大きくなり、中間ノードのどこかでMTUに忍び込まないことがあります(すべてのトンネリングの問題を思い出してください)。
- 突然ソースとRPの間のどこかにグループの受信者がまだいる場合、マルチキャストトラフィックは一方向に2回送らなければなりません。
たとえば、次のトポロジをご覧ください。

Registerメッセージ内のトラフィックは、最初にR1-R42-R2のラインに沿ってRPに到達し、次にR2-R42のラインに沿って純粋なマルチキャストが返されます。 したがって、同じトラフィックの2つのコピーは、反対方向ではありますが、R42-R2回線に送られます。

したがって、純粋なマルチキャストをソースからRPに転送する方が適切です。このためには、ツリー-
ソースツリーを構築する必要があります。
8)したがって、RPはPIM JoinメッセージをR1に送信します。 しかし今では、RPのアドレスではなく、Registerメッセージから学習したソースのアドレスをすでにグループに示しています。 このメッセージは、
Join(S、G)-Source Specific Joinと呼ばれます。

彼の目標は、PIM Join(*、G)の目標とまったく同じです。今回は、ソースからRPまでのツリーを構築します。
Join(S、G)は、通常のJoin(*、G)と同様に、ノードごとにノードを拡張します。 Join(*、G)のみがRPになり、Join(S、G)がS-ソースになります。 受信者アドレスは、サービスアドレス224.0.0.13およびTTL = 1でもあります。
たとえば、R42などの中間ノードが存在する場合、これらはレコード(S、G)およびこのグループのダウンストリームインターフェイスのリストも形成し、Joinをソースにさらに送信します。
JoinがRPからソースにたどったパスは、
ソースツリー -ソースからのツリーになります。 ただし、より一般的な名前は
SPT(最短パスツリー)です。これは、ソースからRPへのトラフィックが
最短パスを通過するためです。
9) R1はJoin(S、G)を受信し、パケットの送信元であるFE1 / 0インターフェイスをOILダウンストリームインターフェイスのリストに追加し、カプセル化によって整頓された純粋なマルチキャストトラフィックのブロードキャストを開始します。 R1のレコード(S、G)は、ソースサーバーから最初のマルチキャストパケットを受信するとすぐにそこにありました。
")
構築されたソースツリーによると、マルチキャストはRP(およびR42などのすべての中間クライアント(ある場合))に送信されます。
ただし、登録メッセージは常に送信されており、まだ送信されていることに注意してください。 つまり、実際には、R1はトラフィックの2つのコピーを送信します。1つは純粋なSPTマルチキャストで、もう1つはユニキャストレジスタにカプセル化されています。

最初に、R1はマルチキャストをRegister- パケット231に送信します。 次に、R2(RP)はツリーに接続したいので、Join- packet 232を送信します。 R2からのリクエストを処理している間、R1はマルチキャストをレジスタに送信します ( 233から238のパケット )。 さらに、トップダウンインターフェイスがR1のOILに追加されると、純粋なマルチキャストパケット239および242の送信を開始しますが、レジスタパケット241および243はまだ停止していません。 パッケージ240-このR2はそれに耐えられず、再びツリーを構築するよう要求されました。
10)したがって、クラウドされていないマルチキャストはRPに到達します。 同じグループアドレス、同じ送信元アドレス、および1つのインターフェイスからであるため、これはRegisterに到達するのと同じトラフィックであると彼女は理解しています。 2つのコピーを受信しないために、彼はユニキャスト
PIM Register-StopをR1に送信します。

Register-Stopは、R2がトラフィックを拒否したり、このソースを認識しなくなったりすることを意味するのではなく、
カプセル化されたトラフィックの送信を停止する必要があることを意味するだけです。
その後、激しい闘争があります。R1は、通常のマルチキャストおよび内部Registerメッセージを使用して、Register-Stopを処理する間、バッファに蓄積されたトラフィックを送信し続けます。

しかし、遅かれ早かれ、R1は純粋なマルチキャストトラフィックのみのブロードキャストを開始します。

準備中、私には思えたように、論理的な質問がありました。まあ、なぜこれらすべてのトンネル、PIM Register? PIM Joinのようにマルチキャストトラフィックを処理しないのはなぜですか?RPに向けてTTL = 1のホップバイホップホップを送信します-それは遅かれ早かれ来ますか? したがって、ツリーは不必要なジェスチャーなしで同時に構築されます。
ここにはいくつかのニュアンスがあります。
まず、PIM SMの主な原則に違反します-要求された場所にのみトラフィックを送信します。 参加不可-ツリーなし !
第二に、このグループにクライアントがいない場合、FHRはそれを認識せず、自身のツリーにトラフィックを送信し続けます。 帯域幅の無駄な使用とは何ですか? 通信の世界では、PIM DMやDVMRPが生き残らなかったように、このようなプロトコルは生き残れませんでした。
したがって、
ソースサーバーから
クライアント1および
クライアント2へのグループ224.2.2.4の1つの大きなMDTツリーがあり
ます 。 そして、このMDTは、互いに独立して構築された2つの部分で構成されています。ソースからRPへの
ソースツリーと、RPからクライアントへの
RPTです。 ここに、MDTとRPTおよびSPTの違いがあります。 MDTは、一般的なマルチキャスト送信ツリーを意味する非常に一般的な用語ですが、RPT / SPTは非常に具体的な外観です。
しかし、サーバーが既にブロードキャストしているが、クライアントが存在しない場合はどうなりますか? マルチキャストは、送信者とRPの間のエリアを詰まらせますか?
いいえ、この場合、PIM Register-Stopも役立ちます。 あるグループのRPに登録メッセージが到着し始めたが、まだ受信者がいない場合、RPはこのトラフィックの受信に関心がないため、PIM Join(S、G)
を送信せずに、RPはすぐにRegister-StopをR1に送信します。
Register-Stopを受信し、このグループのツリーがまだない(クライアントがない)ことを確認したR1は、サーバーからのマルチキャストトラフィックの破棄を開始します。
つまり、サーバー自体は完全にこのことを心配せず、ストリームの送信を続けますが、ルーターインターフェイスに到達すると、ストリームは破棄されます。
この場合、RPはレコード(S、G)の保存を続けます。 つまり、トラフィックを受信しませんが、グループのソースがどこにあるかを知っています。 グループに受信者が表示された場合、RPはそれらについて学習し、ツリーを構築するJoin(S、G)ソースに送信します。
さらに、R1は3分ごとに、RPでソースを再登録、つまり、登録パケットを送信しようとします。 これは、このソースがまだ生きていることをRPに通知するために必要です。
特に好奇心reader盛な読者は質問をしなければなりません-RPFはどうですか? このメカニズムは、結局、マルチキャストパケットの送信者アドレスをチェックし、トラフィックが正しいインターフェイスから送信されない場合、破棄されます。 この場合、RPとソースは異なるインターフェイスに配置できます。 したがって、R3 RPの例では-FE1 / 1の場合、ソースはFE1 / 0の場合です。
答えは予測可能です-この場合、チェックされるのは送信元アドレスではなく、RPです。 つまり、トラフィックはインターフェイスからRPに向かう必要があります。
しかし、後で見るように、これは不滅の規則でもありません。
RPは普遍的な磁石ではないことを理解することが重要です-各グループには独自のRPがあります。 つまり、ネットワークには2つ、3つ、および100が存在する可能性があります。1つのRPがグループのセットを担当し、もう1つのグループが他のグループを担当します。 さらに、
エニーキャストRPなどがあり、異なるグループが同じグループにサービスを提供できます。
======================
タスク番号2
スキームと初期設定 。
トポロジに関する注意 :このタスクでは、ルーターR1、R2、R3のみがネットワークの管理者によって管理されます。 つまり、構成はそれらでのみ変更できます。
サーバー172.16.0.5は、マルチキャストトラフィックをグループ239.1.1.1および239.2.2.2に送信します。
グループ239.1.1.1のトラフィックがR3とR5の間のセグメント、およびR5の下のすべてのセグメントに送信されないようにネットワークを構成します。
しかし同時に、グループ239.2.2.2のトラフィックは問題なく送信されるはずです。
タスクの詳細はこちらです。
======================
Occamのカミソリまたは不要なブランチの無効化
セグメント内の最後のクライアントがサブスクライブを解除した後、PIMは過剰なRPTブランチを遮断する必要があります。たとえば、R4の唯一のクライアントがコンピューターの電源を切ったとします。 IGMP Leaveメッセージによるルーター、または3つの未応答IGMPクエリの後、FE0 / 0の背後にクライアントがもうないことを理解し、PIM PruneメッセージをRP側に送信します。形式では、Joinとまったく同じですが、逆の機能を実行します。宛先アドレスも224.0.0.13で、TTLは1です。 しかし、PIM Pruneを受信したルーターは、サブスクリプションを削除する前にしばらく待機します(通常は3秒-Join Delay Timer)。これは、この状況で行われます。
しかし、PIM Pruneを受信したルーターは、サブスクリプションを削除する前にしばらく待機します(通常は3秒-Join Delay Timer)。これは、この状況で行われます。 1つのブロードキャストドメインに3つのルーターがあります。それらの1つはより高く、マルチキャストトラフィックをセグメントに転送するのは彼です。これがR1です。両方のルーター(R2およびR3)の場合、そのOILには1つのエントリのみが含まれます。R2が切断してPIM Pruneを送信することになった場合、彼は同僚のR3を置き換えることができます。R1はインターフェースへのブロードキャストをまったく停止します。そのため、これを防ぐために、R1は3秒のタイムアウトを設定します。この間、R3には反応する時間が必要です。ネットワークのブロードキャストを考慮して、彼はR2からプルーンも受信するため、トラフィックの受信を継続したい場合、通常のPIM Joinを即座にセグメントに送信し、インターフェースを削除する必要がないことをR1に通知します。このプロセスは、プルーンオーバーライドと呼ばれます。R2は、いわばR1を追い抜き、イニシアチブを奪取しました。
1つのブロードキャストドメインに3つのルーターがあります。それらの1つはより高く、マルチキャストトラフィックをセグメントに転送するのは彼です。これがR1です。両方のルーター(R2およびR3)の場合、そのOILには1つのエントリのみが含まれます。R2が切断してPIM Pruneを送信することになった場合、彼は同僚のR3を置き換えることができます。R1はインターフェースへのブロードキャストをまったく停止します。そのため、これを防ぐために、R1は3秒のタイムアウトを設定します。この間、R3には反応する時間が必要です。ネットワークのブロードキャストを考慮して、彼はR2からプルーンも受信するため、トラフィックの受信を継続したい場合、通常のPIM Joinを即座にセグメントに送信し、インターフェースを削除する必要がないことをR1に通知します。このプロセスは、プルーンオーバーライドと呼ばれます。R2は、いわばR1を追い抜き、イニシアチブを奪取しました。
SPTスイッチオーバー-RPT-SPTスイッチング
ここまでは、主にクライアント1のみを考慮してきました。次に、クライアント2を使用します。最初は、彼のすべてがクライアント1と同じです。彼はRPのRPTを使用します。ところで、クライアント1とクライアント2の両方が同じツリーを使用しているため、このようなツリーは共有ツリーと呼ばれます-これはかなり一般的な名前です。共有ツリー= RPT。ツリーを構築した直後のR5のマルチキャストルーティングテーブルは、最初は次のようになります。SPTスイッチオーバー") エントリ(S、G)はありませんが、これはマルチキャストトラフィックが送信されないという意味ではありません。 R5は送信者が誰であるかを気にしません。この場合、R1-R2-R3-R5のように、トラフィックが通過するパスに注意してください。パスR1-R3-R5は短いですが。
エントリ(S、G)はありませんが、これはマルチキャストトラフィックが送信されないという意味ではありません。 R5は送信者が誰であるかを気にしません。この場合、R1-R2-R3-R5のように、トラフィックが通過するパスに注意してください。パスR1-R3-R5は短いですが。 そして、ネットワークがより複雑な場合はどうなりますか?
そして、ネットワークがより複雑な場合はどうなりますか? どういうわけかずさん。事実、RPに接続している間は、RPTのルートであり、最初はだれかがどこにいるかを知っています。ただし、最初のマルチキャストパケットの後、IPヘッダーにリストされているため、トラフィックパスに沿ったすべてのルーターは送信元アドレスを知っています。
どういうわけかずさん。事実、RPに接続している間は、RPTのルートであり、最初はだれかがどこにいるかを知っています。ただし、最初のマルチキャストパケットの後、IPヘッダーにリストされているため、トラフィックパスに沿ったすべてのルーターは送信元アドレスを知っています。 Join自体をソース側に送信してルートを最適化しないのはなぜですか?ルートを見てください。そのようなスイッチはLHR(ラストホップルーター)を開始するかもしれません-R5。 R3から最初のマルチキャストパケットを受信した後、R5は既知のSource Specific Join(S、G)をFE0 / 1インターフェイスに送信します。これは、ルーティングテーブルでネットワーク172.16.0.0/24への発信として示されます。
Join自体をソース側に送信してルートを最適化しないのはなぜですか?ルートを見てください。そのようなスイッチはLHR(ラストホップルーター)を開始するかもしれません-R5。 R3から最初のマルチキャストパケットを受信した後、R5は既知のSource Specific Join(S、G)をFE0 / 1インターフェイスに送信します。これは、ルーティングテーブルでネットワーク172.16.0.0/24への発信として示されます。 このようなJoinを受信すると、R3は通常のJoin(*、G)の場合のようにRPに送信するのではなく、ソース側に(ルーティングテーブルに従ってインターフェイスを介して)送信します。つまり、この場合、R3はJoin(172.16.0.5、224.2.2.4)をFE1 / 0インターフェイスに送信します。
このようなJoinを受信すると、R3は通常のJoin(*、G)の場合のようにRPに送信するのではなく、ソース側に(ルーティングテーブルに従ってインターフェイスを介して)送信します。つまり、この場合、R3はJoin(172.16.0.5、224.2.2.4)をFE1 / 0インターフェイスに送信します。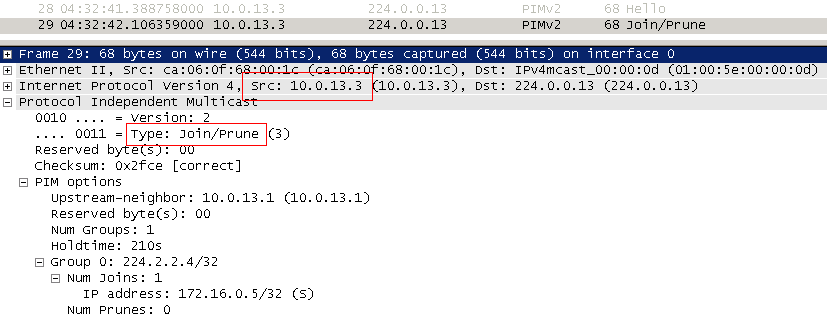 次に、この結合はR1に到達します。そして、一般的にR1は、送信者(RPまたは他の誰か)に関係なく、グループ22.2.2.2.4。のOILにFE1 / 1を追加するだけです。
次に、この結合はR1に到達します。そして、一般的にR1は、送信者(RPまたは他の誰か)に関係なく、グループ22.2.2.2.4。のOILにFE1 / 1を追加するだけです。 この時点で、ソースとレシーバーの間に2つのパスがあり、R3は2つのストリームを受信します。
この時点で、ソースとレシーバーの間に2つのパスがあり、R3は2つのストリームを受信します。 超過分をトリミングする選択をする時間です。さらに、R5はこれら2つのストリームを区別できなくなるため、R3がそれを作成します。これらは両方とも同じインターフェースを経由します。R3は、異なるインターフェイスからの2つの同一のフローを修正するとすぐに、ルーティングテーブルに従って優先フローを選択します。この場合、直接、RP経由よりも優れています。この時点で、R3はRP側にプルーン(S、G)を送信し、このRPTブランチを切断します。そして、その瞬間からソースから直接残るストリームは1つだけです。
超過分をトリミングする選択をする時間です。さらに、R5はこれら2つのストリームを区別できなくなるため、R3がそれを作成します。これらは両方とも同じインターフェースを経由します。R3は、異なるインターフェイスからの2つの同一のフローを修正するとすぐに、ルーティングテーブルに従って優先フローを選択します。この場合、直接、RP経由よりも優れています。この時点で、R3はRP側にプルーン(S、G)を送信し、このRPTブランチを切断します。そして、その瞬間からソースから直接残るストリームは1つだけです。 したがって、PIMはSPT-最短パスツリーを構築しました。同じソースツリーです。これは、クライアントからソースへの最短パスです。ところで、ソースからRPへのツリーは、すでに上で説明したとおり、本質的にまったく同じSPTです。表記法(S、G)が特徴です。ルータにそのようなエントリがある場合、SがグループGのソースであり、SPTツリーが構築されていることがわかります。
したがって、PIMはSPT-最短パスツリーを構築しました。同じソースツリーです。これは、クライアントからソースへの最短パスです。ところで、ソースからRPへのツリーは、すでに上で説明したとおり、本質的にまったく同じSPTです。表記法(S、G)が特徴です。ルータにそのようなエントリがある場合、SがグループGのソースであり、SPTツリーが構築されていることがわかります。SPTツリーのルートはソースであり、「ソースからクライアントへの最短パス」と言いたいです。ただし、ソースからクライアントへのパスとクライアントからソースへのパスが異なる場合があるため、これは技術的に間違っています。つまり、クライアントからツリーブランチの構築が開始されます。ルーターはソース/ RP側にPIM Joinを送信し、RPFはトラフィックを受信するためのインターフェイスもチェックします。
R5のこのセクションの冒頭にはレコード(*、G)しかありませんでしたが、これらすべてのイベントの後、2つのイベント(*、G)と(S、G)があることに注意してください。
ちなみに、VLCで[再生]をクリックしたのと同じ秒にR3マルチキャストルーティングテーブルを見ても、R1から直接トラフィックを受信していることがわかります。これは、エントリ(S、G)の存在によって示されます。つまり、SPTスイッチオーバーはすでに発生しています(これは多くのメーカーの機器でのデフォルトアクションです)-最初のマルチキャストパケットを受信した後にスイッチを開始します。一般的に、このような切り替えはいくつかの場合に発生する可能性があります。- まったく起こらない(ip pim spt-threshold infinityコマンド)。
- 特定の帯域幅使用率に到達すると(ip pim spt-threshold Xコマンド)。
- もちろん-最初のパケットを受信した直後(デフォルトアクションまたはno ip pim spt-threshold X)
原則として、「時間」はLHRによって決定されます。この場合、RPFの動作ルールは2回目に変更されます-ソースの場所を再度チェックします。つまり、マルチキャストの2つのストリーム-RPとソースから-ソースからのトラフィックが優先されます。
DR、アサート、フォワーダー
PIMを検討する際のいくつかの重要なポイント。DR指定ルーター。これは、RPへのサービスパケットの送信を担当する専用ルーターです。ソースDR-マルチキャストパケットをソースから直接受信し、RPに登録します。トポロジの例を次に示し ます。両方のルーターがRPにトラフィックを送信する必要はなく、互いに予約しておく必要がありますが、責任があるのは1つだけです。両方のルーターが同じブロードキャストネットワークに接続されているため、互いからPIM-Helloを受信します。それに基づいて、彼らは彼らの選択をします。PIM Helloは、このインターフェイスでこのルーターの優先度値を伝送します。
ます。両方のルーターがRPにトラフィックを送信する必要はなく、互いに予約しておく必要がありますが、責任があるのは1つだけです。両方のルーターが同じブロードキャストネットワークに接続されているため、互いからPIM-Helloを受信します。それに基づいて、彼らは彼らの選択をします。PIM Helloは、このインターフェイスでこのルーターの優先度値を伝送します。 値が大きいほど、優先度が高くなります。それらが同じ場合、最大のIPアドレスを持つノードが選択されます(Helloメッセージからも)。
値が大きいほど、優先度が高くなります。それらが同じ場合、最大のIPアドレスを持つノードが選択されます(Helloメッセージからも)。 Holdtime(デフォルト105秒)中に別のルーター(DRではない)がネイバーからHelloを受信しなかった場合、自動的にDRの役割を引き継ぎます。本質的に、ソースDRはFHR-First Hop Routerです。受信者DRはソースDRと同じですが、マルチキャストトラフィックの受信者-LHR(ラストホップルーター)のみです。トポロジの例:
Holdtime(デフォルト105秒)中に別のルーター(DRではない)がネイバーからHelloを受信しなかった場合、自動的にDRの役割を引き継ぎます。本質的に、ソースDRはFHR-First Hop Routerです。受信者DRはソースDRと同じですが、マルチキャストトラフィックの受信者-LHR(ラストホップルーター)のみです。トポロジの例: 受信者DRは、RP PIM Joinへの送信を担当します。上記のトポロジでは、両方のルーターがJoinを送信すると、両方がマルチキャストトラフィックを受信しますが、これは必須ではありません。 DRのみが参加を送信します。 2番目は単純にDRの可用性を監視します。DRはJoinを送信するため、トラフィックをLANにブロードキャストします。しかし、ここで論理的な疑問が生じます-PIM DRが1つになり、IGMP Querierが別のものになったらどうなるでしょうか?また、Quiererの場合はIPが低いほど良いのですが、DRの場合は逆なので、状況は非常に可能です。この場合、すでにQuerierであるルーターがDRによって選択され、この問題は発生しません。
受信者DRは、RP PIM Joinへの送信を担当します。上記のトポロジでは、両方のルーターがJoinを送信すると、両方がマルチキャストトラフィックを受信しますが、これは必須ではありません。 DRのみが参加を送信します。 2番目は単純にDRの可用性を監視します。DRはJoinを送信するため、トラフィックをLANにブロードキャストします。しかし、ここで論理的な疑問が生じます-PIM DRが1つになり、IGMP Querierが別のものになったらどうなるでしょうか?また、Quiererの場合はIPが低いほど良いのですが、DRの場合は逆なので、状況は非常に可能です。この場合、すでにQuerierであるルーターがDRによって選択され、この問題は発生しません。 レシーバーDRを選択するためのルールは、ソースDRとまったく同じです。アサートおよびPIMフォワーダー同時に送信する2つのルーターの問題は、ネットワークの中央で発生する可能性があります。ネットワークでは、エンドクライアントまたはソースがなく、ルーターのみです。この質問はPIM DMで非常に深刻でした。PIMDMでは、フラッドアンドプルーンメカニズムにより、まったく普通の状況でした。ただし、PIM SMでは除外されません。次のネットワークを検討してください。
レシーバーDRを選択するためのルールは、ソースDRとまったく同じです。アサートおよびPIMフォワーダー同時に送信する2つのルーターの問題は、ネットワークの中央で発生する可能性があります。ネットワークでは、エンドクライアントまたはソースがなく、ルーターのみです。この質問はPIM DMで非常に深刻でした。PIMDMでは、フラッドアンドプルーンメカニズムにより、まったく普通の状況でした。ただし、PIM SMでは除外されません。次のネットワークを検討してください。 ここでは、3つのルーターが同じネットワークセグメントにあり、したがってPIMネイバーです。 R1はRPとして機能します。R4はPIM JoinをRPに送信します。このパッケージはマルチキャストであるため、R2とR3の両方に該当し、処理後、両方ともOILにダウンストリームインターフェイスを追加します。ここで、DR選択メカニズムは機能するはずですが、R2とR3にはこのグループの他のクライアントがあり、どちらのルーターもとにかくPIM Joinを送信する必要があります。マルチキャストトラフィックがソースからR2およびR3に到着すると、両方のルーターによってセグメントに送信され、そこで倍になります。 PIMはこの状況を防ごうとしません-ここでは、犯罪の事実に基づいて行動します-ルーターが特定のグループ(OILリストから)のダウンストリームインターフェイスでこの同じグループのマルチキャストトラフィックを受信するとすぐに、何かが間違っていることを理解します-すでに別の送信者がいますこのセグメントで。
ここでは、3つのルーターが同じネットワークセグメントにあり、したがってPIMネイバーです。 R1はRPとして機能します。R4はPIM JoinをRPに送信します。このパッケージはマルチキャストであるため、R2とR3の両方に該当し、処理後、両方ともOILにダウンストリームインターフェイスを追加します。ここで、DR選択メカニズムは機能するはずですが、R2とR3にはこのグループの他のクライアントがあり、どちらのルーターもとにかくPIM Joinを送信する必要があります。マルチキャストトラフィックがソースからR2およびR3に到着すると、両方のルーターによってセグメントに送信され、そこで倍になります。 PIMはこの状況を防ごうとしません-ここでは、犯罪の事実に基づいて行動します-ルーターが特定のグループ(OILリストから)のダウンストリームインターフェイスでこの同じグループのマルチキャストトラフィックを受信するとすぐに、何かが間違っていることを理解します-すでに別の送信者がいますこのセグメントで。 次に、ルーターは特別なPIM Assertメッセージを送信します。このメッセージは、PIMフォワーダーの選択に役立ちます-このセグメントでブロードキャストする資格があるルーター。
次に、ルーターは特別なPIM Assertメッセージを送信します。このメッセージは、PIMフォワーダーの選択に役立ちます-このセグメントでブロードキャストする資格があるルーター。 PIM DRと混同しないでください。まず、PIM DRはPIM JoinおよびPruneメッセージの送信を担当し、PIM Forwarderはトラフィックの送信を担当します。2番目の違いは、近隣を確立するときはすべてのネットワークでPIM DRが常に選択され、必要な場合のみ-PIL ForwrderはOILリストからインターフェイスからマルチキャストトラフィックを受信することです。
PIM DRと混同しないでください。まず、PIM DRはPIM JoinおよびPruneメッセージの送信を担当し、PIM Forwarderはトラフィックの送信を担当します。2番目の違いは、近隣を確立するときはすべてのネットワークでPIM DRが常に選択され、必要な場合のみ-PIL ForwrderはOILリストからインターフェイスからマルチキャストトラフィックを受信することです。
RPの選択
上記では、簡単にするために、ip pim rp-address XXXXコマンドを使用してRPを手動で設定します。これがshow ip pim rpコマンドの外観です。 しかし、最近のネットワークでは完全に不可能な状況を想像してみましょう -R2は失敗しました。これですべて完了です。SPTスイッチオーバーがあったため、クライアント2は引き続き機能しますが、別の方法があったとしても、RPを通過した新しいものやすべてのものが壊れます。さて、ドメイン管理者の負荷。想像してください:50台のルーターで、少なくとも1つのコマンドを手動で強制終了します(グループごとに異なるRPが存在する可能性があります)。RPを動的に選択することで、手作業を回避し、信頼性を確保できます。1つのRPが使用できなくなった場合、すぐに別のRPが戦闘に入ります。現時点では、これを行うことができる一般的に認められているプロトコルが1つあります-Bootstrapです。昔のTsiskaはやや不器用なAuto-RPを推進していましたが、現在ではほとんど使用されていませんが、tsiskaはこれを認識しません。showip mrouteには、グループ224.0.1.40の形式で迷惑な基本があります。
しかし、最近のネットワークでは完全に不可能な状況を想像してみましょう -R2は失敗しました。これですべて完了です。SPTスイッチオーバーがあったため、クライアント2は引き続き機能しますが、別の方法があったとしても、RPを通過した新しいものやすべてのものが壊れます。さて、ドメイン管理者の負荷。想像してください:50台のルーターで、少なくとも1つのコマンドを手動で強制終了します(グループごとに異なるRPが存在する可能性があります)。RPを動的に選択することで、手作業を回避し、信頼性を確保できます。1つのRPが使用できなくなった場合、すぐに別のRPが戦闘に入ります。現時点では、これを行うことができる一般的に認められているプロトコルが1つあります-Bootstrapです。昔のTsiskaはやや不器用なAuto-RPを推進していましたが、現在ではほとんど使用されていませんが、tsiskaはこれを認識しません。showip mrouteには、グループ224.0.1.40の形式で迷惑な基本があります。実際、Auto-RPプロトコルに敬意を表さなければなりません。彼は昔は救いでした。しかし、オープンで柔軟なBootstrapの登場により、自然に道を譲りました。
したがって、ネットワークで、R2に障害が発生した場合にR3にRPの機能を選択させたいとします。R2とR3はRPの役割の候補として定義されているため、C-RPと呼ばれます。これらのルーターでは、以下を構成します。 RX(config)interface Loopback 0 RX(config-if)ip pim sparse-mode RX(config-if)exit RX(config)
しかし、何も起こらない間、候補者はまだ自分自身について全員に通知する方法を知りません。既存のRPについてすべてのマルチキャストドメインルータに通知するために、BSRメカニズムであるBootStrap Routerが導入されています。 C-RPだけでなく、複数の申請者が存在する可能性があります。それらは、それぞれC-BSRと呼ばれます。それらは同様の方法で構成されます。1つのBSRがあり、テストでは(排他的に)R1になります。 R1(config)interface Loopback 0 R1(config-if)ip pim sparse-mode R1(config-if)exit R1(config)
最初に、すべてのC-BSRから1つのメインBSRが選択され、すべてが管理されます。これを行うには、各C-BSRがマルチキャストブートストラップメッセージ(BSM)をアドレス224.0.0.13のネットワークに送信します-これもPIMプロトコルパケットです。すべてのマルチキャストルーターで受け入れて処理し、PIMがアクティブになっているすべてのポートに送信する必要があります。 BSMは、PIM Joinとは異なり、何か(RPまたはソース)の方向ではなく、すべての方向に送信されます。このファン分布は、BSMがすべてのC-BSRおよびすべてのC-RPを含むネットワークのすべてのコーナーに到達するのに役立ちます。 BSMが無期限にネットワークをさまようことを防ぐために、同じRPFメカニズムが適用されます-BSMがこのメッセージの送信者のネットワークの背後の間違ったインターフェースから来た場合、このメッセージは破棄されます。 これらのBSMを使用して、すべてのマルチキャストルーターは優先順位に基づいて最も価値のある候補を決定します。 C-BSRは、優先度の高い別のルーターからBSMを受信するとすぐに、メッセージの送信を停止します。その結果、誰もが同じ情報を持っています。
これらのBSMを使用して、すべてのマルチキャストルーターは優先順位に基づいて最も価値のある候補を決定します。 C-BSRは、優先度の高い別のルーターからBSMを受信するとすぐに、メッセージの送信を停止します。その結果、誰もが同じ情報を持っています。 BSRを選択したときにそのBSMのネットワークを介して分岐しているので、この段階では、、、C-RPは、彼の住所を知っているし、彼にメッセージを送るユニキャストCandidte-RP-広告彼らが仕えるというグループのリストである、を、 -それはgroup-to-RP mappingと呼ばれます。 BSRはこれらすべてのメッセージを集約し、RPセット(情報テーブル:各グループにサービスを提供するRP)を作成します。
BSRを選択したときにそのBSMのネットワークを介して分岐しているので、この段階では、、、C-RPは、彼の住所を知っているし、彼にメッセージを送るユニキャストCandidte-RP-広告彼らが仕えるというグループのリストである、を、 -それはgroup-to-RP mappingと呼ばれます。 BSRはこれらすべてのメッセージを集約し、RPセット(情報テーブル:各グループにサービスを提供するRP)を作成します。 次に、BSRは同じファン方式で同じBootStrapメッセージを送信しますが、今回はRPセットが含まれています。これらのメッセージは、すべてのマルチキャストルーターに正常に到達し、それぞれが特定のグループごとに使用するRPを個別に選択します。
次に、BSRは同じファン方式で同じBootStrapメッセージを送信しますが、今回はRPセットが含まれています。これらのメッセージは、すべてのマルチキャストルーターに正常に到達し、それぞれが特定のグループごとに使用するRPを個別に選択します。 BSRは定期的にこのようなメールを送信するため、一方ではRPの情報がまだ関連していることを誰もが知っており、もう一方のC-BSRではメインBSR自体がまだ生きていることを認識しています。ところで、RPは定期的にCandidate-RP-AdvertisementアナウンスメントをBSRに送信します。実際、自動RP選択を構成するために必要なことは、C-RPを指定し、C-BSRを指定するだけで、それほど作業は必要ありません。PIMが残りを行います。いつものように、信頼性を高めるために、ループバックインターフェイスを候補として指定することをお勧めします。
BSRは定期的にこのようなメールを送信するため、一方ではRPの情報がまだ関連していることを誰もが知っており、もう一方のC-BSRではメインBSR自体がまだ生きていることを認識しています。ところで、RPは定期的にCandidate-RP-AdvertisementアナウンスメントをBSRに送信します。実際、自動RP選択を構成するために必要なことは、C-RPを指定し、C-BSRを指定するだけで、それほど作業は必要ありません。PIMが残りを行います。いつものように、信頼性を高めるために、ループバックインターフェイスを候補として指定することをお勧めします。
PIM SMに関する章を締めくくり、最も重要なポイントをもう一度強調しましょう
- IGPまたは静的ルートを使用した通常のユニキャスト接続を提供する必要があります。これがRPFアルゴリズムの基礎です。
- ツリーは、クライアントが表示された後にのみ構築されます。ツリーの構築を開始するのはクライアントです。顧客なし-ツリーなし。
- RPFはループの回避に役立ちます。
- すべてのルーターは、RPが誰であるかを知っている必要があります。その助けがなければツリーを構築できません。
- RPポイントは静的に指定することも、BootStrapプロトコルを使用して自動的に選択することもできます。
- RPT — RP — Source Tree — RP. RPT SPT — .
また、現在わかっているすべての種類のツリーとメッセージもリストします。MDT-マルチキャスト配信ツリー。マルチキャスト伝送ツリーを表す一般的な用語。SPT-最短パスツリー。クライアントまたはRPからソースへの最短パスを持つツリー。 PIM DMには、SPTのみがあります。 PIM SMでは、SPTはソースからRPに、またはSPTスイッチオーバーが発生した後にソースから宛先になります。エントリ(S、G)で示されます-グループのソースは既知です。ソースツリーはSPTと同じです。RPT-ランデブーポイントツリー。 RPから受信者へのツリー。 PIM SMでのみ使用されます。エントリ(*、G)で示されます。共有ツリー-RPTと同じ。すべてのクライアントがRPのルートを持つ同じ共有ツリーに接続されているため、そう呼ばれます。メッセージタイプのSM PIM:こんにちは -近所を確立し、これらの関係を維持します。 DRを選択するためにも必要です。Join(*、G) -グループGツリーへの接続要求。ソースが誰であっても。 RPに送信されます。彼らの助けを借りて、RPTツリーが構築されます。結合(S、G) -ソース固有の結合。これは、特定のソース-SでグループGのツリーに接続する要求です。ソース側に送信されます-S。彼らの助けを借りて、SPTツリーが構築されます。プルーン(*、G) -ソースが何であれ、グループGをツリーから切断する要求。 RPに送信されます。これにより、RPTブランチが切り捨てられます。プルーン(S、G)-ルートがソースSであるグループGのツリーから切断する要求。ソース側に送信されます。これにより、SPTブランチが切断されます。Register -SPTがソースからRPに構築されるまでマルチキャストがRPに送信される特別なメッセージ。 FHRからRPへのユニキャスト。Register-Stop -RPからFHRにユニキャストで送信され、Registerにカプセル化されたマルチキャストトラフィックの送信を停止するように命令します。ブートストラップはBSRエンジンパッケージであり、これを使用すると、BSRロール用のルーターを選択したり、既存のRPおよびグループに関する情報を送信したりできます。アサート-2つのルーターが1つのセグメントにトラフィックを送信しないようにPIMフォワーダーを選択するメッセージ。Candidate-RP-Advertisement-RPがサービスを提供するグループに関する情報をBSRに送信するメッセージ。RP-Reachable -RPからのメッセージ。すべてのユーザーにその可用性を通知します。* PIMには他のタイプのメッセージもありますが、これらは詳細です*
プロトコルの詳細を無視してみましょうか?そして、その複雑さが明らかになります。1)RPの定義、2)RP でのソースの登録、3)SPTツリーへの切り替え。多くのプロトコル状態、マルチキャストルーティングテーブルの多くのエントリ。これについてできることはありますか?今日、PIMを単純化するための2つの正反対のアプローチがあります。SSMとBIDIR PIMです。SSM
これまで説明してきたのは、ASM-Any Source Multicastだけです。グループのトラフィックのソースである顧客に違いはありません-主なことは、彼らがそれを受け取ることです。思い出すと、IGMPv2レポートメッセージはグループへの接続を要求するだけです。SSM-ソース固有のマルチキャスト -代替アプローチ。この場合、クライアントは接続時にグループとソースを示します。それは何を与えますか?多かれ少なかれ:RPを完全に取り除く能力。LHRは送信元アドレスをすぐに認識します。JoinをRPに送信する必要はありません。ルーターはすぐに送信元の方向にJoin(S、G)を送信し、SPTを構築できます。だから私たちは取り除く- 検索RP(ブートストラップおよび自動RPプロトコル)、
- ( , )
- SPT.
RPが存在しないため、RPTは存在しないため、どのルーターにもエントリ(*、G)はなく、(S、G)のみが存在します。SSMを使用して解決できる別の問題は、いくつかのソースの存在です。 ASMは、マルチキャストグループのアドレスが一意であり、複数のストリームがRPTツリーでマージされ、異なるソースから2つのストリームを受信するクライアントはおそらく解析できないため、1つのソースのみがブロードキャストすることを推奨します。SSMでは、さまざまなソースからのトラフィックがそれぞれ独自のSPTツリーで個別に分散され、これはもはや問題になりませんが、利点です-複数のサーバーが同時にブロードキャストできます。クライアントが突然メインソースから損失を記録し始めた場合、彼はそれを再要求することなくバックアップのものに切り替えることができます-彼はすでに2つのストリームを受信しました。さらに、マルチキャストルーティングがアクティブになっているネットワークで考えられる攻撃ベクトルは、攻撃者がソースに接続し、ネットワークを過負荷にする大量のマルチキャストトラフィックを生成することです。SSMでは、これは事実上不可能です。IPアドレスの特別な範囲がSSMに割り当てられます:232.0.0.0/8。ルータでは、SSMをサポートするためにPIM SSMモードが有効になっています。 Router(config)
IGMPv3およびMLDv2は、純粋なSSMをサポートします。それらを使用する場合、クライアントは- ソースを指定せずに、グループのみへの接続を要求します。つまり、典型的なASMのように機能します。
- 特定のソースを持つグループへの接続を要求します。複数のソースを指定できます-それぞれのソースの前にツリーが構築されます。
- グループへの接続を要求し、クライアントがトラフィックを受信したくないソースのリストを指定します
IGMPv1 / v2、MLDv1はSSMをサポートしていませんが、SSM Mappingなどがあります。クライアント(LHR)に最も近いルーターでは、各グループに送信元アドレス(または複数)が割り当てられます。したがって、ネットワーク上にIGMPv3 / MLDv2をサポートしないクライアントが存在する場合、送信元アドレスがまだわかっているため、RPTではなくSPTも構築されます。SHRマッピングは、LHRの静的構成とDNSサーバーへのアクセスの両方によって実装できます。SSMの問題は、クライアントが送信元アドレスを事前に知っている必要があることです。つまり、シグナリングは通知されません。したがって、SSMは、ネットワークに特定のソースセットがあり、そのアドレスが既知であり、変更されない場合に適しています。そして、クライアント端末またはアプリケーションはそれらにしっかりと接続されています。つまり、IPTVはSSMの実装に非常に適した環境です。これは、1対多の概念をよく説明しています-1つのソース、多くの受信者。
BIDIR PIM
しかし、ネットワーク上のソースがその場で自発的に現れ、同じグループにブロードキャストし、すぐに送信を停止して消滅した場合はどうでしょうか?たとえば、この状況は、ネットワークゲームやデータが異なるサーバー間で複製されるデータセンターで発生する可能性があります。これは多対多の概念です-多くのソース、多くの顧客。通常のPIM SMはそれをどのように見ますか?ここで不活性PIM SSMがまったく適切でないことは明らかですか?どんな種類のカオスが始まるのかを考えてみてください:無限のソースの登録、ツリーの再構築、プロトコルタイマーのために数分間生き続ける膨大な数のレコード(S、G)。双方向PIM(BIDIR PIM、BIDIR PIM)が助けになります)反対に、SSMとは異なり、SPTとレコード(S、G)を完全に拒否します。RPにルートを持つ共有ツリーのみが残ります。通常のPIMの場合、ツリーは一方向です-トラフィックは常にソースからSPTおよびRPからRPTに送信されます-ソースがクライアントのある明確な区分があり、ソースからRPへの双方向トラフィックでは共有ツリーに送信されます-同じ理由で、トラフィックは顧客に流れます。これにより、RPでのソースの登録を拒否できます。トラフィックは、シグナリングや状態の変更なしで無条件に送信されます。 SPTツリーがまったくないため、SPTスイッチオーバーも発生しません。以下に例を示します。
 Istochnik1はグループ224.2.2.4と同時にネットワークトラフィックを放映開始したIstochnikom2。それらからのストリームは、単にRPに注がれました。ルーターにエントリ(*、G)があるため、近くにいる一部のクライアントはすぐにトラフィックを受信し始めました(クライアントがあります)。もう1つの部分は、RPから共有ツリートラフィックを受信します。さらに、両方のソースから同時にトラフィックを受信します。つまり、たとえば投機的なネットワークゲームを使用する場合、Source1はシューティングゲームで最初に射撃したプレーヤーであり、Source2は他のプレイヤーが側に一歩進んだプレーヤーです。これらの2つのイベントに関する情報は、ネットワーク全体に広がります。そして、他のすべてのプレーヤー(受信者 )これらのイベントの両方について学習する必要があります。
Istochnik1はグループ224.2.2.4と同時にネットワークトラフィックを放映開始したIstochnikom2。それらからのストリームは、単にRPに注がれました。ルーターにエントリ(*、G)があるため、近くにいる一部のクライアントはすぐにトラフィックを受信し始めました(クライアントがあります)。もう1つの部分は、RPから共有ツリートラフィックを受信します。さらに、両方のソースから同時にトラフィックを受信します。つまり、たとえば投機的なネットワークゲームを使用する場合、Source1はシューティングゲームで最初に射撃したプレーヤーであり、Source2は他のプレイヤーが側に一歩進んだプレーヤーです。これらの2つのイベントに関する情報は、ネットワーク全体に広がります。そして、他のすべてのプレーヤー(受信者 )これらのイベントの両方について学習する必要があります。, , RP — , , RP . ? : BIDIR PIM , , , , . RP .
上記の画像では、R5とR7の間に、RPを通るパスよりもはるかに短い直線がありますが、Joinはルーティングテーブルに従ってRPに向かって進むため、このパスは最適ではないことに注意してください。それは非常に単純に見えます-RPの方向にマルチキャストパケットを送信する必要がありますが、すべてを台無しにする1つの警告があります-RPF。 RPTツリーでは、トラフィックがRPから来ることが必要であり、そうでない場合は必要ありません。そして、ここで彼はどこからでも来ることができます。もちろん、RPFを受け取って拒否することはできません。これは、ループの形成を回避する唯一のメカニズムです。したがって、DFの概念はBIDIR PIM -Designated Forwarderで導入されています。。各ネットワークセグメントの各回線で、RPへのルートがより適切なルーターがこの役割に選択されます。これを含めることは、クライアントが直接接続されている回線で行われます。BIDIR PIM DFは自動的にDRです。 OILリストは、DFロール用にルーターが選択されたインターフェイスからのみ形成されます。ルールは非常に透明です:
OILリストは、DFロール用にルーターが選択されたインターフェイスからのみ形成されます。ルールは非常に透明です:- PIM Join / Leave要求がこのセグメントのDFであるインターフェイスに到着した場合、標準ルールに従ってRP側に送信されます。
ここで、たとえば、R3です。要求が赤丸でマークされたDFインターフェイスに到達した場合、RPに(ルーティングテーブルに応じてR1またはR2を介して)要求を送信します。 - PIM Join/Leave DF , .
, , R1 R3, IGMP Report. R1 , DF ( ), . R3 , DF. R3 , , . - DF , OIL RP.
, 1 . R4 DF DF- — RP, — , RP . R3 — OIL — R5, - RPF, — RP. - DF , OIL, RP.
, 2 , RP RPT. R3 R1, R2 — R4 R5.
このようにして、DFはマルチキャストパケットの1つのコピーのみが最終的にRPに送信され、ループが除外されるようにします。この場合、ソースが配置されている一般的なツリーは、もちろん、RPに到達する前であってもこのトラフィックを受信します。 RPは、通常のルールに従って、トラフィックの送信元を除き、すべてのOILポートにトラフィックを送信します。ところで、DFは各セグメントで選択されているため、メッセージをアサートする必要はもうありません。 DRとは異なり、彼はRPへのJoinの送信だけでなく、セグメントへのトラフィックの送信も担当します。つまり、2つのルーターが同じサブネットにトラフィックを送信する状況はBIDIR PIMで除外されます。おそらく、双方向PIMについて最後に言うことは、RPの仕組みです。 PIM SM RPがソースの登録という非常に特定の機能を実行した場合、BIDIRでは、PIM RPは、一方のトラフィックが他方のクライアントからシークして参加する非常に条件的なポイントです。誰もカプセル化を解除して、SPTツリーの構築を要求しないでください。一部のルーターでは、ソースからのトラフィックが突然共有ツリーに送信され始めます。 「なぜ」と言っているのですか?実際、BIDIR PIM RPは特定のルーターではなく抽象的なポイントであり、存在しないIPアドレスは一般にRPアドレスとして機能します。主なことは、ルーティング可能であることです(このようなRPはPhantom RPと呼ばれます)。PIMに関連するすべての用語は、用語集にあります。
チャネルレベルでのマルチキャスト
そのため、睡眠不足、処理不足、テスト不足の長い1週間の作業の後、マルチキャストと顧客、ディレクター、販売部門の満足を実現できました。金曜日は、創造物を調査し、あなた自身が快適な休息をとることができる悪い日ではありません。しかし、あなたの午後の昼寝は突然技術サポートの呼び出しを邪魔し、次々に-何も機能せず、すべてが壊れました。チェック-損失、休憩があります。すべてが複数のスイッチの1つのセグメントに収束します。SSHを明らかにし、CPUを確認し、インターフェイスの使用率とエンドのヘアを確認しました。同じVLANのすべてのインターフェイスでほぼ100%の負荷がかかっています。ループ!しかし、仕事が行われなかった場合、彼女はどこから来たのでしょうか? 10分間のテストで、カーネルへのアップストリームインターフェイスには大量の着信トラフィックがあり、クライアントへのダウンストリームにはすべて発信トラフィックがあることがわかりました。これはループの特徴でもありますが、なんらかの疑いがあります。マルチキャストを導入し、切り替え作業を行わず、一方向にのみ跳躍しました。ルーター上のマルチキャストグループのリストを確認しました-すべての可能なチャネルとすべて1つのポートへのサブスクリプションがあります-当然、このセグメントにつながるものです。徹底的な調査により、クライアントのコンピューターが感染し、IGMPクエリがすべてのマルチキャストアドレスに連続して送信されることが明らかになりました。スイッチが膨大な量のトラフィックを通過しなければならなかったため、パケット損失が始まりました。これにより、インターフェイスバッファがオーバーフローしました。主な質問は、1つのクライアントのトラフィックがすべてのポートにコピーされ始めた理由です。この理由は、マルチキャストMACアドレスの性質にあります。実際、マルチキャストIPアドレス空間は特別な方法でマルチキャストMACアドレス空間にマッピングされます。そして、問題は、送信元MACアドレスとして使用されないため、スイッチによって学習されず、MACアドレステーブルに入力されないことです。しかし、宛先アドレスが調査されていないフレームを持つスイッチはどうでしょうか?彼はそれらをすべてのポートに送信します。それが何が起こったのかです。
これがデフォルトのアクションです。
マルチキャストMACアドレス
では、そのようなパケットのイーサネットヘッダーに挿入される受信者のMACアドレスは何ですか?放送?いや
マルチキャストIPアドレスを表示する特別な範囲のMACアドレスがあります。これらの特別なアドレスは次のように始まります:0x01005eで、次の25番目のビットは0でなければなりません(なぜそうなのか答えてみてください)。残りの23ビット(思い出してください、MACアドレス48のすべて)は、IPアドレスから転送されます。ここには、それほど深刻ではないが、問題があります。マルチキャストアドレスの範囲は、マスク224.0.0.0/4によって決定されます。つまり、最初の4ビットは予約されており、1110であり、残りの28ビットは変更可能です。つまり、2 ^ 28個のマルチキャストIPアドレスと2 ^ 23個のMACアドレスしかありません。5ビットでは1分の1を表示するには不十分です。したがって、IPアドレスの最後の23ビットだけが取得され、1対1がMACアドレスに転送され、残りの5ビットは破棄されます。 実際、これは1つのマルチキャストMACアドレスに2 ^ 5 = 32個のIPアドレスが表示されることを意味します。たとえば、グループ224.0.0.1、224.128.0.1、225.0.0.1などから239.128.0.1までは、すべて単一のMACアドレス0100:5e00:0001にマッピングされます。ストリーミングビデオダンプの例を見ると、
実際、これは1つのマルチキャストMACアドレスに2 ^ 5 = 32個のIPアドレスが表示されることを意味します。たとえば、グループ224.0.0.1、224.128.0.1、225.0.0.1などから239.128.0.1までは、すべて単一のMACアドレス0100:5e00:0001にマッピングされます。ストリーミングビデオダンプの例を見ると、 IPアドレス-224.2.2.4、MACアドレス:01:00:5E:02:02:04が表示されます。IPv4マルチキャストとは関係のない他のマルチキャストMACアドレスもあります(クリック)。ちなみに、それらはすべて、最初のオクテットの最後のビットが1であるという事実によって特徴付けられます。当然、このようなMACアドレスはどのネットワークカードにも設定できないため、イーサネットフレームの送信元MACフィールドには決して入りません。 MACアドレス表したがって、そのようなフレームは、すべてのVLANポートへの不明なユニキャスト。以前に検討したことはすべて、ストリーミングビデオから株価へのマルチキャストトラフィックの完全な転送に十分です。しかし、私たちは、選挙に引き継ぐことができるものの放送送信として、ほぼ完璧な世界でそのような怒りを本当に我慢しようとしていますか?
IPアドレス-224.2.2.4、MACアドレス:01:00:5E:02:02:04が表示されます。IPv4マルチキャストとは関係のない他のマルチキャストMACアドレスもあります(クリック)。ちなみに、それらはすべて、最初のオクテットの最後のビットが1であるという事実によって特徴付けられます。当然、このようなMACアドレスはどのネットワークカードにも設定できないため、イーサネットフレームの送信元MACフィールドには決して入りません。 MACアドレス表したがって、そのようなフレームは、すべてのVLANポートへの不明なユニキャスト。以前に検討したことはすべて、ストリーミングビデオから株価へのマルチキャストトラフィックの完全な転送に十分です。しかし、私たちは、選挙に引き継ぐことができるものの放送送信として、ほぼ完璧な世界でそのような怒りを本当に我慢しようとしていますか?まったくありません。
特に完璧主義者のために、IGMPスヌーピングメカニズムが発明されました。
IGMPスヌーピング
アイデアは非常に単純です。スイッチは、通過するIGMPパケットを「リッスン」します。グループごとに、アップストリームポートとダウンストリームポートのテーブルを個別に保持します。グループのIGMPレポートがポートから送信された場合、クライアントが存在することを意味し、スイッチはこのレポートをこのグループのダウンストリームのリストに追加します。グループのIGMPクエリがポートから送信された場合、ルーターがあり、スイッチはそれをアップストリームのリストに追加します。したがって、チャネルレベルでのマルチキャストトラフィックの送信テーブルが形成されます。その結果、マルチキャストストリームが上から来ると、ダウンストリームインターフェイスにのみコピーされます。 16ポートスイッチにクライアントが2つしかない場合、トラフィックのみを受信します。 このアイデアの天才は、その性質を考えると終わります。このメカニズムは、スイッチが3番目のレベルでトラフィックをリッスンする必要があると想定しています。ただし、IGMPスヌーピングは、ネットワークの相互作用の原則を無視する程度ではNATと比較できません。さらに、リソースの節約に加えて、あまり目立たない機能がたくさんあります。そして一般的に、現代の世界では、IPの内部を見ることができるスイッチは例外的な現象ではありません。
このアイデアの天才は、その性質を考えると終わります。このメカニズムは、スイッチが3番目のレベルでトラフィックをリッスンする必要があると想定しています。ただし、IGMPスヌーピングは、ネットワークの相互作用の原則を無視する程度ではNATと比較できません。さらに、リソースの節約に加えて、あまり目立たない機能がたくさんあります。そして一般的に、現代の世界では、IPの内部を見ることができるスイッチは例外的な現象ではありません。======================
タスク番号3
.
172.16.0.5 239.1.1.1, 239.2.2.2 239.0.0.x.
, :
— 1 239.2.2.2. 239.0.0.x.
— 2 239.1.1.1. 239.0.0.x.
タスクの詳細はこちらです。
======================
IGMP Snooping Proxy
好奇心fastest盛な読者は、上で述べたように、IGMPクエリに応答する最速のクライアントは1つだけであるため、IGMPスヌーピングがすべてのクライアントポートを認識する方法を尋ねることがあります。また、非常に簡単です。IGMPスヌーピングは、レポートメッセージがクライアント間を通過することを許可しません。それらはルーターへのアップストリームポートにのみ送信されます。このグループの他の受信者からのレポートを見ることなく、クライアントはこのクエリで指定された最大応答時間内にクエリに応答する必要があります。その結果、IGMPクエリごとに1000ノードのネットワークでは、1000秒以内に、通常の最大応答時間内に1000のレポートがルーターに届きます。それは彼とグループごとに1つで十分でしょうが。そして、それは毎分起こります。この場合、IGMP要求のプロキシを構成できます。その後、スイッチは通過するパケットを「聞く」だけでなく、それらを傍受します。IGMPスヌーピングポリシーはメーカーによって異なる場合があります。したがって、それらを概念的に検討します。1)グループへの最初のレポート要求がスイッチに到着すると、それはルーターまで送信され、インターフェイスはトップダウンリストにリストされます。そのようなグループがすでに存在する場合、インターフェイスは降順リストに追加され、レポートは破棄されます。2)最新の脱退がスイッチに到着した場合、つまり他のクライアントがない場合、この脱退はルータに送信され、インターフェイスはダウンストリームのもののリストから削除されます。それ以外の場合、インターフェイスは単に削除され、休暇は破棄されます。3)IGMPクエリがルーターから送信された場合、スイッチはそれをインターセプトし、現在受信者がいるすべてのグループに応答してIGMPレポートを送信します。そして、設定とメーカーに応じて、同じクエリがすべてのクライアントポートに送信されるか、スイッチがルーターからのリクエストをブロックし、それ自体がクエリアとして機能し、すべての受信者を定期的にポーリングします。したがって、ネットワーク内の不必要なオーバーヘッドトラフィックのシェアとルーターの負荷が削減されます。マルチキャストVLANレプリケーション
MVRの略。これは、たとえば、ユーザーごとのVLANを実践するプロバイダー向けのメカニズムです。MVRが不可欠なネットワークの典型的な例を次に示し ます。異なるVLANに5つのクライアントがあり、全員が1つのグループからマルチキャストトラフィックを受信することを望んでいます。同時に、顧客はお互いから隔離されたままでなければなりません。IGMPスヌーピングでは、もちろんVLANも考慮されます。異なるVLANの5つのクライアントが1つのグループを要求する場合、5つの異なるテーブルになります。したがって、グループに接続するための5つの要求はルーターに送られます。また、ルータ上の5つのサブインターフェイスはそれぞれ、OILに個別に追加されます。つまり、グループ224.2.2.4の1つのストリームを受信すると、すべて1つのセグメントに移動するという事実にもかかわらず、5つのコピーを送信します。
ます。異なるVLANに5つのクライアントがあり、全員が1つのグループからマルチキャストトラフィックを受信することを望んでいます。同時に、顧客はお互いから隔離されたままでなければなりません。IGMPスヌーピングでは、もちろんVLANも考慮されます。異なるVLANの5つのクライアントが1つのグループを要求する場合、5つの異なるテーブルになります。したがって、グループに接続するための5つの要求はルーターに送られます。また、ルータ上の5つのサブインターフェイスはそれぞれ、OILに個別に追加されます。つまり、グループ224.2.2.4の1つのストリームを受信すると、すべて1つのセグメントに移動するという事実にもかかわらず、5つのコピーを送信します。 この問題を解決するために、マルチキャストVLANレプリケーションのメカニズムが開発されました。追加のVLAN(マルチキャスト VLAN)が導入され、それに応じてマルチキャストストリームが送信されます。これは、最後のスイッチに直接「転送」され、そこからのトラフィックは、このトラフィックを受信するすべてのクライアントインターフェイスにコピーされます。これがレプリケーションです。実装に応じて、マルチキャストVLANからの複製は、ユーザーVLANまたは特定の物理インターフェースで実行できます。
この問題を解決するために、マルチキャストVLANレプリケーションのメカニズムが開発されました。追加のVLAN(マルチキャスト VLAN)が導入され、それに応じてマルチキャストストリームが送信されます。これは、最後のスイッチに直接「転送」され、そこからのトラフィックは、このトラフィックを受信するすべてのクライアントインターフェイスにコピーされます。これがレプリケーションです。実装に応じて、マルチキャストVLANからの複製は、ユーザーVLANまたは特定の物理インターフェースで実行できます。 IGMPメッセージはどうですか?もちろん、ルーターからのクエリはマルチキャストVLANを介して送信されます。スイッチはそれらをクライアントポートに送信します。クライアントからレポートまたはリーブが到着すると、スイッチはそれがどこから来たか(VLAN、インターフェイス)をチェックし、必要に応じてマルチキャストVLANにリダイレクトします。したがって、通常のトラフィックは分離され、引き続きユーザーVLANのルーターに送られます。マルチキャストトラフィックとIGMPパケットは、マルチキャストVLANで送信されます。
IGMPメッセージはどうですか?もちろん、ルーターからのクエリはマルチキャストVLANを介して送信されます。スイッチはそれらをクライアントポートに送信します。クライアントからレポートまたはリーブが到着すると、スイッチはそれがどこから来たか(VLAN、インターフェイス)をチェックし、必要に応じてマルチキャストVLANにリダイレクトします。したがって、通常のトラフィックは分離され、引き続きユーザーVLANのルーターに送られます。マルチキャストトラフィックとIGMPパケットは、マルチキャストVLANで送信されます。シスコ機器では、MVRとIGMPスヌーピングは個別に設定されます。つまり、1つを無効にすると、2つ目が機能します。一般に、MVRはIGMPスヌーピングに基づいており、MVRがMVRスイッチで動作するためにはIGMPスヌーピングが必須です。
さらに、IGMPスヌーピングにより、スイッチ上のトラフィックのフィルタリング、ユーザーが使用できるグループ数の制限、IGMPクエリアの有効化、アップストリームポートの静的構成、任意のグループへの永続的な接続(このシナリオは付属のビデオにあります)、およびトポロジの変更に対する迅速な対応が可能です追加のクエリ、IGMPv2のSSMマッピングなどを送信します。IGMPスヌーピングについての話を締めくくりたいと思います。これはオプションの機能です。すべて機能します。しかし、これによりネットワークがより予測可能になり、エンジニアの生活は穏やかになります。ただし、IGMPスヌーピングのすべての利点は自分自身に反することができます。ここでそのようなすばらしいケースを読むことができます。ちなみに、同じCiscoにはCGMPプロトコルがあります。IGMPの類似物で、スイッチの原理に違反しませんが、独自のものであり、広く普及しているとは言えません。
ですから、疲れを知らない読者の皆さん、リリースの終わりに近づいています。最後に、クライアント側でIPTVサービスを実装する方法を示したいと思います。この記事で何度も取り上げた最も簡単な方法は、ネットワークからマルチキャストストリームを受信できるプレーヤーを起動することです。その上で、グループのIPアドレスを手動で設定し、ビデオを楽しむことができます。プロバイダーがよく使用する別のソフトウェアオプションは、通常非常にカスタムな特別なアプリケーションで、プロバイダーのネットワークで使用される一連のチャネルが配線されています。手動で何かを設定する必要はありません-ボタンでチャンネルを切り替えるだけです。どちらの方法でも、コンピューターでのみストリーミングビデオを視聴できます。3番目のオプションでは、TVを使用できますが、原則としてanyを使用できます。これを行うために、いわゆるセットトップボックス(STB)がクライアントの家(テレビに設置されたボックス)に置かれます。これは加入者線に含まれ、トラフィックを共有するスロットです:通常のユニキャストをイーサネットまたはWiFiに送信して、クライアントがインターネットにアクセスできるようにし、マルチキャストストリームがケーブル(DVI、RGB、アンテナなど)を介してテレビに送信されます。ちなみに、多くの場合、プロバイダーはテレビを接続するためのセットトップボックスを提供する広告を見ることができます-これらはまさにSTBです======================
№ 4
( , ).
:

-, — , .
.
, :
1. , ?
2. , , , ?
, .
タスクの詳細はこちらです。
======================
マルチキャストトラフィック(MSDP、MBGP、BGMP)のマルチキャストルーティング、RP(エニーキャストRP)、PGM、および独自プロトコル間の負荷分散は影響を受けませんでした。しかし、この記事を出発点として、残りを理解することは難しくないと思います。すべてのマルチキャスト用語は、lookmeupテレコミュニケーション用語集で見つけることができます。記事の準備にご協力いただきありがとうございます。JDimaに感謝します ...技術サポート、Natasha Samoilenkoに感謝します。KDPVは、プロジェクトの素晴らしいアーティストであり友人であるNina Dolgopolovaによって描かれました。SDSMの記事プールにはまだ多くの興味深いものがあります。そのため、リリースが長くないためにサイクルを埋める必要はありません。新しい記事が追加されるたびに、複雑さが大幅に増加します。ほとんどすべてのMPLS、IPv6、QoS、およびネットワーク設計に先立ちます。既にお気づきかもしれませんが、linkmeupには新しいプロジェクトがあります-lookmeup用語集(はい、それは私たちの想像から遠くないです)。この用語集がコミュニケーションの分野における用語の最も包括的な参考になることを願っていますので、私たちはそれを記入するのにどんな助けでも喜んでいるでしょう。でお問い合わせinfo@linkmeup.ruのと一緒たち。