エントリー
RabbitMQクラスター内の多数のメトリックを監視するタスクに直面して、JSONデータ用のユニバーサルパーサーを作成したいという要望がありました。 クラスターの操作中にメトリックが動的に表示および非表示になり、開発者が常に何か新しいものを収集/カウントしたいという事実により、タスクは複雑でした。 残念ながら、Zabbixでは、この形式でボックスからデータを収集する方法はありません。 ただし、zabbix_trapperなどの便利な機能があり、柔軟なカスタマイズを行うことができます。 この記事では、zabbix_trapperアイテムの非標準的な使用方法について説明します。 開発者から新しいメトリックの追加、データを収集してzabbixに送信するスクリプトの変更を求められるたびに望みませんでした。 ここから、新しいメトリックを収集するための指示としてzabbixキー自体を使用するというアイデアが生まれました。 一番下の行は、定義済みの構文で、zabbixキーをコマンドとして使用します。 つまり、この場合のzabbixキーは、zabbix_agentタイプのキーと同様の命令として機能します。
Zabbixの公式ドキュメントによると、アイテムキーには有効な文字に関する制限があります。 zabbix trapperのようなキーの作成で少し遊んだ後、たとえば次の形式のキーを見つけました。
some.thing.here [one:two:three] [foo = x、bar = y]zabbixでエラーなしで作成されます。 つまり、制限は、[]ブラケットの外側に、ブラケットの前に少なくとも1つの[az] [AZ]文字が存在する必要があるという事実に対してのみ機能します。 そのようなキーを作成する機能を備えているため、独自のキー構文を作成し、その中に非常に柔軟なロジックをプログラムできます。 さらに、すべての主要な作業を実行する発明された構文のハンドラーを記述するだけです。 そして最後に、このハンドラーでドックを作成し、コードを公開することで、Zabbixコミュニティ全体がそのような「似た」プラグインを交換する機会を得ます。
一般的に、この記事は理解するのが少し難しいことがわかったので、コンセプトをよりよく理解するために、まずはRabbitMQ APIに精通することをお勧めします。少なくともデータの外観とAPIが提供するものを見てください(オフサイトを参照)。
コードへのリンクは、記事の最後に記載されています。
仕組み
最初に、開発された構文に従って、zabbix_trapperタイプのフロントエンドアイテムをZabbixで作成します(構文については以下で説明します)。 次に、クラウンでハンドラー(rmq_data_collect.pl-以下コレクター)を情報収集の頻度(1分など)で実行します。 これで、コレクターは、図に示すように、ZabbixサーバーおよびRabbitMQサーバーと対話します。
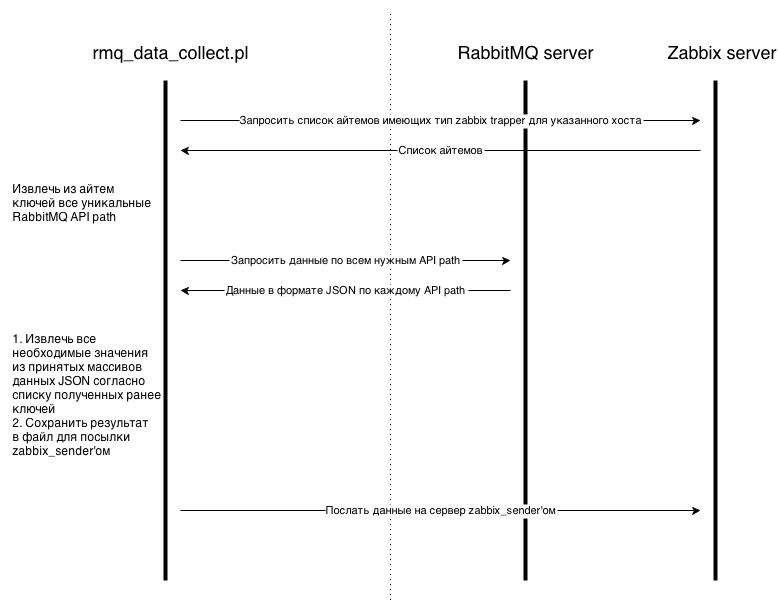
つまり スクリプトは、3つの主要なステップを取ります。
1)Zabbixサーバーから収集するアイテムのリストを要求します。
2)上記の項目のリストに従って、RabbitMQから必要なすべてのデータを取得します。
3)収集されたすべてのデータをZabbixサーバー/プロキシに対応するアイテムに送信します。
最初の通信で、ハンドラーはZabbix APIを介して、およびデータベースと直接やり取りできます。 私の実装では、Zabbixプロキシベースとの相互作用が発生します。 このアプローチは、多くのZabbixプロキシで分散監視を使用する場合により便利です。 この場合、スクリプトをzabbixプロキシサーバーにインストールし、同じプロキシのデータベースに接続するためのデータをスクリプト構成に登録する必要があります。
ハンドラーに加えて、低レベルのディスカバリーに使用される別のディスカバリーも検討します。 次に、RabbitMQの現在の監視実装、理論と構成の例について説明します。
実装されているもの
RabbitMQ APIのドキュメントには、9つのAPIのURLが記載されており、フェデレーションリンクもあります。これは、rebbitの別個のプラグインとして配置されます。 おそらく何か他のものがあります。 スクリプトの現在の実装では、次のAPIパスを監視できます。
-ノード
-接続
-キュー
-バインディング
-連携リンク
私のタスクにはこれで十分でした。さらにAPIパスが必要な場合は、それらをmap_rmq_elementsに追加する必要があります(コードに関するコメントを参照)。
スクリプトをインストールして構成する
RabbitMQを監視するには、2つのスクリプト(CollectorとDiscoverer)+ ZabbixProxyDB.pmをインストールして構成する必要があります。 Zabbixの設定に応じて、Zabbixサーバーとプロキシの両方にスクリプトをインストールできます。
コレクター
rmq_data_collect.pl -zabbiksキーを処理し、rabbitmqからデータを収集するために使用されます。
使用する入力パラメーターが1つあります
$ 1-RabbitMQがクラスターとして実行されていない場合、ZabbixのRabbitMQホストのフルネーム。 rebbitがクラスターとして機能する場合、$ 1はクラスター内のホスト名の一般的な部分です。 クラスター内のホスト名は、特定のルールで指定する必要があります。 たとえば、クラスター内のホスト名:
-rmq-host1
-rmq-host2
-rmq-host3
この場合、$ 1は「rmq-host」である必要があります。スクリプトは、Zabbixサーバー/プロキシに「rmq-host」を含む名前のすべてのホストのリストを要求し、その後このリストを調べて、RabbitMQ APIに必要なデータを要求します。いずれかのホストからデータが収集され、zabbix_senderによる送信のためにファイルに書き込まれます執筆時点で、RabbitMQクラスターの複数のホストが応答しない場合、何も起こりませんコードに欠陥があります。現在の実装では、ホスト名の要件は関連していますこれまでのデータベースへのSQLクエリのみ。
コレクターは、rebbitからのデータ収集の頻度に等しい頻度でcrontabに登録する必要があります。 必要なモジュールのリストは、スクリプト自体に記載されています。
Discoverer
rmq_data_discover.pl -Zabbixでの低レベル検出(低レベル検出またはLLD)に使用されます。
使用する3つの必須入力パラメーターがあります。
$ 1-RabbitMQがクラスターとして実行されていない場合、ZabbixのRabbitMQホストのフルネーム。 クラスターの場合、原則はコレクターの場合と同じです。 最初の成功した応答の後、リストは停止し、低レベルのディスカバリーのためのメッセージのコンパイルが開始されます。
$ 2-スクリプトの実行時にメトリックが選択される正規表現。 LLD設定のZabbix側の正規表現フィルターと混同しないでください。 この分離は、場合によっては便利です。
$ 3-RabbitMQ APIパス、サポートされているもののリスト(p。実装内容を参照)。
スクリプトは、Zabbixプロキシ/サーバー設定で指定されたexternalscriptsフォルダーにインストールする必要があります。 LLDルールの設定例は、記事の最後に記載されています。
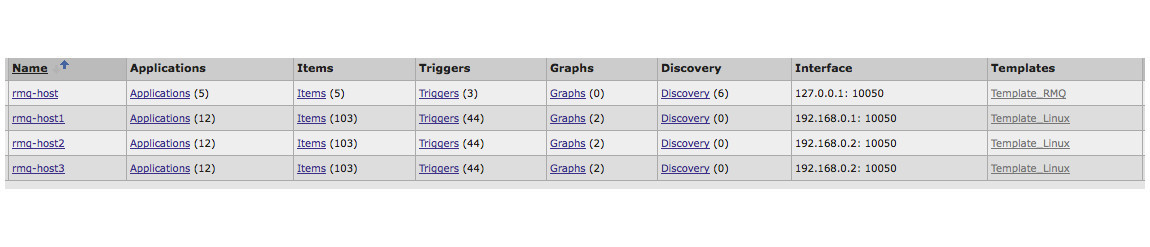
Zabbixのホスト構成の例
3つのホストで構成されるrabbitmqクラスターがあります。 ホスト自体は、CPU、メモリなどの標準的なメトリックを含むzabbixエージェント、Template_Linuxテンプレートによって個別に監視されます クラスターメトリック用に別のホスト「rmq-host」が作成されました。 クラスター全体のホスト名は、クラスター内のホスト名の共通部分です。 これは現在の実装の前提条件です。そうしないと、データベースからの選択が正しく機能しません。
キー構文
次に、rebbit用に開発した構文について説明します。 前述のように、Zabbixでは、アイテムはzabbix trapperタイプである必要があります。
rebitを監視するために、シンプルと集約の2種類のアイテムがあり、それらの構文はわずかに異なります。 単純なアイテムを使用して、個々のパラメーター値を取得します。 集計項目は、特定の条件に従って値の配列を選択して集計するために使用されます。 どちらの場合も、条件は指定できません(オプション)。
単純な値
構文 :<path.to.value.inside.json> [$ type:$ api_path:$ element_name]
<path.to.value.inside.json>-配列の各要素内の値へのパス。
$ type-名前はVHOSTまたは「general」です。VHOSTの場合、指定されたVHOSTによって値が検索されます。「general」は、VHOSTに固有ではない値に必要なキーワードです。
$ api_path-RabbitMQ APIパス、サポートされているもの(p。実装内容を参照)。
$ element_nameは、指定された$ api_pathの配列要素の一意の識別子です。フェデレーションリンクの場合は交換、バインディングの場合は宛先、残りの名前の場合は。
集計値
一般的な構文: <path.to.value.inside.json | rmq> [集計:$ api_path:$ func] [$条件]
aggregated-キーワードの後に、コレクター(rmq_data_collect.pl)が集約されたタイプの値に関してキー構文を解析する必要があることを理解します。
$ api_path-APIへのパス、サポートされているもの(p。実装内容を参照)。
$ func-合計とカウントの2つの関数が実装されています。
$条件-オプションのパラメーター(指定されている場合)は、条件に適合するデータ配列内の要素のみが集計時に考慮されます。 条件の構文は次のとおりです。[condition1 =“ cond1”、condition2 =“ cond2”、condition3 =“ cond3”など)。 引用符が必要です。 条件自体はPerl正規表現です。
和関数構文:<path.to.value.inside.json> [集計:$ api_path:sum] [$条件]
sum関数は、$ api_pathによって取得され、条件$ conditionに一致する配列の各要素内の指定されたパス<path.to.value.inside.json>にある値を合計します。
<path.to.value.inside.json>-RabbitMQ APIパスによって取得された配列の各要素内の値へのパス。
カウント機能構文:rmq [集計:$ api_path:カウント] [$条件]
count関数は、条件に一致する$ api_pathによって取得された配列内の要素の数をカウントします。
rmq-必須の単語ですが、どのような方法でも使用されていません(絶対に任意の文字セットを使用できます)。 これは、タイプ「zabbix_trapper」のアイテムキーに対するZabbixの制限によるものです。アイテムは角括弧で始めることはできません。
例
集計値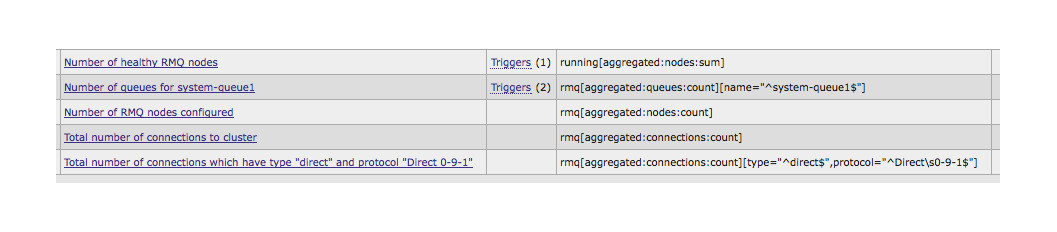
1)ノード配列内の実行中の要素の合計をカウントします。 注:ノードがrabbitmqで動作している場合、実行するとそれぞれ1が返され、出力で動作中のノードの数が取得されます。
2)キュー配列の要素数をカウントします。名前= ^ system-queue1 $。 なぜなら 条件の値は常に正規表現と見なされます;他の何かが正規表現に該当する場合にエラーを回避するために、行の先頭と末尾を設定する必要があります(^ $)。 出力は、system-queues1という名前のキューの数です。
3)ノード配列内の要素の総数をカウントします。 つまり クラスター内の構成済みノードの数。
4)接続配列内の要素の総数をカウントします。 つまり 現時点でのクラスターへの接続数。
5)type =“ ^ direct $”およびprotocol =” ^ Direct \ s0-9-1 $”の接続配列の要素数をカウントします。
単純な値の例は、後のLLDで提供されます。 なぜなら それらを静的に設定することは便利ではありません;ほとんどのキューは絶えず現れたり消えたりします。
低レベルの発見
大規模なrabbitmqクラスター構成の場合、低レベルのZabbixディスカバリーを使用するのが賢明です。 rmq_data_discover.plの使用については上記で説明しています。 ここでは、スクリプトによって返される例と値を示します。
スクリプトによって返され、LLDで使用できる値:
接続
"{#VHOST}" => $ vhost、
「{#NAME}」=> $ name、
「{#NODE}」=> $ノード、
ノード
「{#NODENAME}」=> $ name、
バインディング
"{#SOURCE}" => $ queueSource、
"{#VHOST}" => $ vhost、
「{#DESTINATION}」=> $ queueDest、
「{#THRESHOLD}」=> $しきい値、
注:空のソースを持つすべての要素は無視されます。
キュー
"{#VHOST}" => $ vhost、
「{#QUEUE}」=> $ queueName、
連盟
「{#VHOST」} => $ vhost、
「{#EXCHANGE} => $ name
LLDの例
各パスAPIの実行ルールの例:

試作品の例
パスキューAPIでは、キューの数を気にすることなく、処理されたメッセージの統計を収集できます。
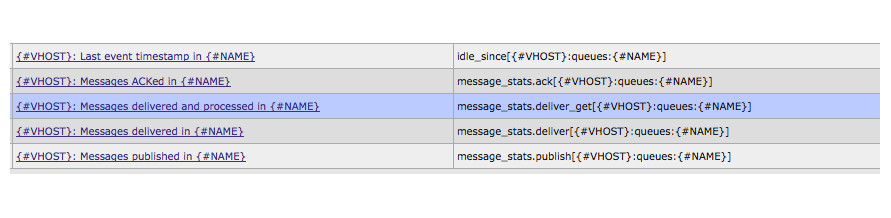
1)idle_sinceフィールドの値。 rmq_data_collector.pl内で処理を行う唯一のフィールド。 その結果、キューが非アクティブになるタイムスタンプを取得します。
2)message_stats要素内のack値。
3)残りの値は、アイテム2と同様にmessage_statsで機能します
接続の例

アイテムは、指定されたタイプ(各{#VHOST}のプロトコル)を持つ接続配列内の要素の数をカウントします。
ノードの例

1)各ノードへの接続数をカウントします。
2)ノード配列の各要素の実行フィールドの値を返します。 出力は、各ノードのヘルスステータスです。
まとめると
混乱しすぎないことを願っています。 不明な点がある場合は、コメントのすべての質問に答えます。
特定のソフトウェアに特化したカスタムキーを作成する上で説明したアプローチの利点は明らかです。 Zabbix自体のコードを変更する必要はありません。 すでに、そのようなプラグインを作成し、それらのドキュメントを作成し、インターネット上で既製のソリューションを交換できます。 Zabbixでカスタマイズされたキーを作成するというアイデアをさらに発展させたら、理想的には、おそらく新しい機能の形でこれを見たいと思います。 現在、同様のプラグインを使用して、新しいRabbitMQメトリックを追加する必要がある場合、zabbix_agentの場合と同様に、適切なアイテムを作成するだけです。
スクリプトコードはこちら:
github.com/mfocuz/zabbix_plugins